最像真人的中文TTS,斬獲2w+收藏!一夜爆火的ChatTTS 實測_風聞
乌鸦智能说-28分钟前
最像人聲的AI來了!語音開源天花板ChatTTS火速出圈,3天就斬獲9k個star。
截至發稿前,已經20.3k個star了。這是專門為對話場景設計的語音生成模型,用於LLM助手對話任務、對話語音、視頻介紹等,僅支持中英文。(項目地址:https://github.com/2noise/ChatTTS)
從宣傳視頻以及其他愛好者的試用情況來看,4w小時訓練的版本效果已經非常不錯了,生成語音的效果真假難辨,還會自動加入“emm……”“然後”等語氣詞,韻律和情感邏輯的效果吊打Google TTS,要説一句“同比最強”毫不誇張。
 強者可能也承受着更挑剔的目光,以列文虎克般的眼光,我也發現了ChatTTS有待改進的穩定性、生成速度等問題,這也讓人萌生了一絲期待。
強者可能也承受着更挑剔的目光,以列文虎克般的眼光,我也發現了ChatTTS有待改進的穩定性、生成速度等問題,這也讓人萌生了一絲期待。
/ 01 / 實測:韻律和情感邏輯超能打,基本錯誤也挺多
ChatTTS可以本地部署,官網也提供了在線合成語音試用的地址(http://www.chattts.com),我們就在線試用版本來和大家分享一下體驗感受。
TTS全寫是Text To Speech,即文本轉語音,我們在ChatTTS網頁的文本框輸入一段文字,隨機抽選音色,並使用IPython.display庫中的Audio函數來播放生成的音頻,音頻可保存為WAV文件。
▲測試語音“從油管、B站的眾多視頻博主以及我自己的試用情況來看……”
頗有趣味的是,抽卡過程像是開盲盒一樣,從預訓練的説話者模型中隨機選擇一個説話者,不知道是會開出“天津大爺”還是“嚴肅的女教師”。而同一段文本,同一個音色卡,多輪生成的結果都是不一樣的,這增加了模型的可玩性。
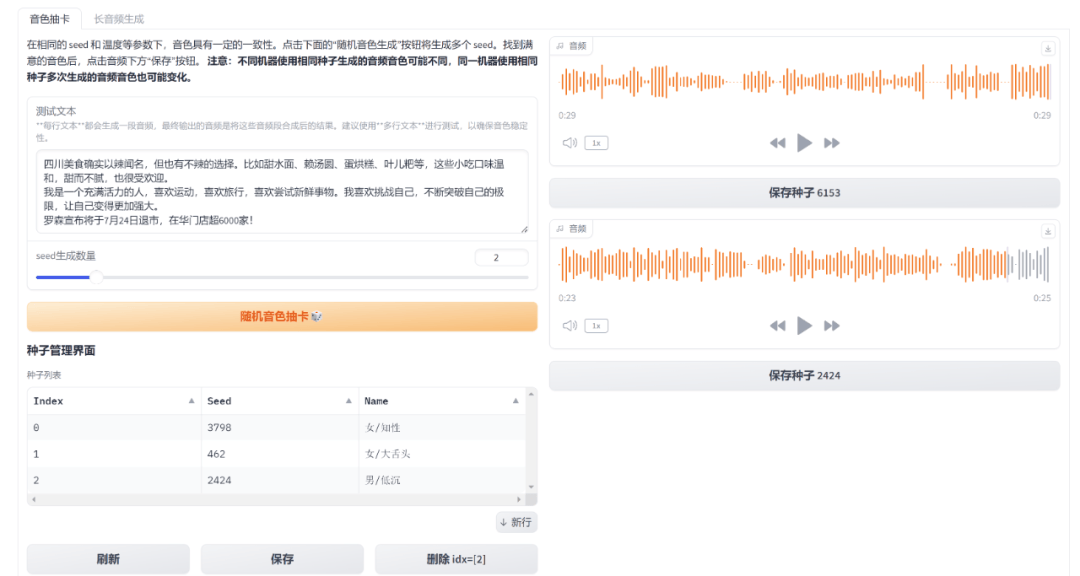 ▲ChatTTS的音色抽卡
▲ChatTTS的音色抽卡
比較幾次生成的語音,我發現生成速度實在是有點慢,一段50字的文本AI生成語音約用時18s,如果是長文本,那用時也是等比增加的。另外,這個4w小時訓練的版本生成的語音音質比較差,句頭有明顯的雜音、重讀。看來,想直接把這麼強的AI模型生成的音頻直接拿去用,還不行。
如果提供的文本中有數字、英文,模型推理越來越容易產生問題,比如讀不對、吞字之類的,像是“ChatTTS”中的“TTS”,模型根本讀不出來。
然而這些氣口加得有點猛,在歸音的地方有氣口顯得並不適宜;有多個語氣詞的時候,比如“你幹嘛,哼哼哎呦”這句,ChatTTS生成語音展現的情感也比較割裂!這也是模型在情感邏輯表現上的雙面性。
總的來看,ChatTTS最具殺手優勢的便是韻律表現力和情感邏輯了。而模型在細粒度控制上生動但有贅餘,存在着兩面性。此外,穩定性在固定音色、固定語速等方面有很大的提升空間,基本發音很容易出現各種各樣的錯誤。我的總結和各維度的評星如下:
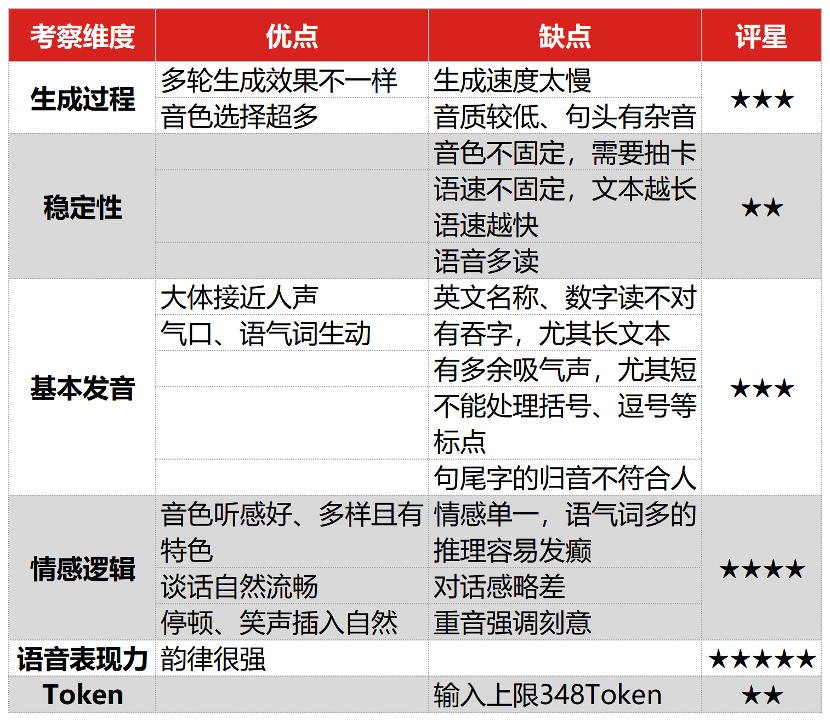 ▲在線版本試用總結
▲在線版本試用總結
據瞭解,ChatTTS主要是從細粒度和韻律上尋求突破升級。如果用上本地部署版本,該模型能夠預測和控制細粒度的韻律特徵,包括笑聲、停頓和插入詞等,我們還可以在文本中加入 [laugh] 和 [uv_break]之類的“笑果”,來增加生動感。
/ 02 / “4w小時版本夠好了”,預計推出“對話”版本
ChatTTS模型經過超過10w小時的訓練,並在B站上展示,在HuggingFace上提供了一個4w小時預訓練的公開版本模型。從這個10w小時版本的視頻中,還是能看出,TTS普遍存在的數據缺失情況,ChatTTS並沒有解決,於是出現了不能處理括號和逗號等標點、吞字等情況,因此後續還需要關鍵詞助手。
不過,滿血狀態的10w小時版本的模型是不開源的。“4w小時的版本效果已經很好,只是網絡小一些,穩定性差一些。”創作團隊2Noise表示,他們保留了10w小時訓練數據的版本模型。
後續工作,他們將繼續從4w小時版本的底模開始,保證生成的語音能被開源的安全模型或Resemble.AI等語音生成工具檢測出來,將工作重心放在高可控、水印以及與LLM的對接上。同時,2Noise在內部訓練了檢測模型,並計劃在未來開放。
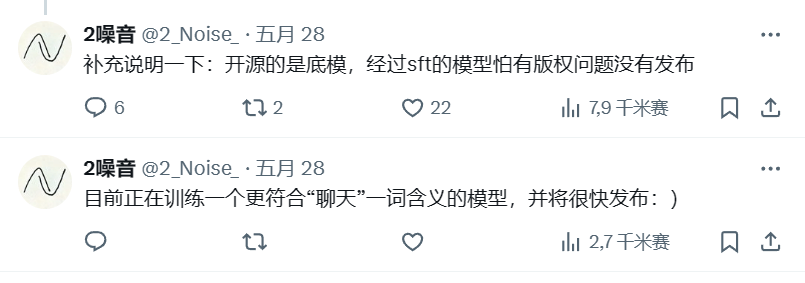 ▲2Noise表示僅開源4w小時的底模,並預告了“對話”模型(來源:X)
▲2Noise表示僅開源4w小時的底模,並預告了“對話”模型(來源:X)
對於2Noise來説,後續除了需要對模型改善音質、氣口和停頓外,還可以在音色克隆上有更多嘗試,以滿足AI遊戲陪聊、AI語音電話、AI配音生成、AI明星伴侶、AI克隆等多種場景。2Noise稱,目前支持音色克隆,但需要更大的數據量。
瑕不掩瑜,ChatTTS在韻律方面超越了大部分開源TTS模型,這一點是顯而易見的。這個最像人聲的AI項目讓我興奮起來,一鍵關注並star!後續會關注一下項目的穩定性、推理速度、訓練難易度和訓練用的數據集。
/ 03 / 以防用户犯罪?壓低音質、摻入明顯錯誤
有一個問題是不能忽略的,ChatTTS開源的4w小時版本模型音質很低,包括在話頭摻入了雜音。
2Noise團隊對這個聲音深度偽造的問題表現出謹慎的態度,團隊稱為了限制ChatTTS的使用,在4w小時模型的訓練過程中添加了少量額外的高頻噪音,並用mp3格式儘可能壓低了音質,以防不法分子用於潛在的犯罪可能。
這邏輯好似在煤氣里加入難聞氣味的氣體,以預警人們注意。
10w小時版本模型的表現讓看客心癢,2Noise卻表示暫時不會公開該版本10w小時的版本。10w小時訓練的ChatTTS模型使用了大量的互聯網數據,並進行了監督微調(SFT),在法律上有一定的風險。
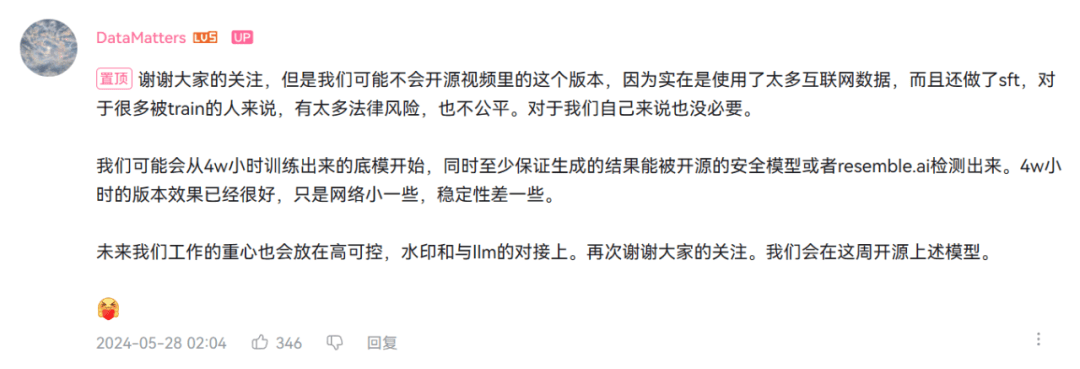 ▲官方在B站展示視頻下的置頂評論
▲官方在B站展示視頻下的置頂評論
誠然,AI語音合成軟件總是伴隨着深度偽造的爭議。不論是寂寂無名的配音演員,還是赫赫有名的明星,都有可能在互聯網環境裏被擅自拿取聲音用作train。
例如,著名演員“寡婦姐”Scarlett Johansson曾拒絕Sam Altman請她配音的請求,而OpenAI為GPT-4o創造了一個與她極其相似的聲音“Sky”。Scarlett在上月末向OpenAI發送律師函後,Open AI才關閉了Sky的語音使用。
一輪又一輪的融資仍佐證了資本市場對AI語音產業的看好。例如2024年1月,ElevenLabs躋身獨角獸,該公司從估值1億美元到估值10億美元,也只過去了半年時間。ChatTTS引發巨量的討論,足以見得人們對於表現亮眼的AI語音產品充滿了好奇與期待,讓我們繼續關注ChatTTS在技術與商業化上的進展。
