AI音頻“扛把子”剛上谷歌V2A!第一個視頻+音頻全自動AI工具,完全開源免費_風聞
乌鸦智能说-1小时前
這幾天的視頻生成AI一經推出就好評不斷。無論是Runaway新模型Gen-3 Alpha,還是Luma AI推出的Dream Machine,都有着逼真的畫面、多樣的電影敍事手法,藝術氣息拉滿。
目前最頂尖的工具如Sora生成的視頻都是沒有聲音的,而聲音是讓AI視頻變得更為真實的重要一步。如果AI能完成從腳本/圖片-視頻-配音的工作流,那才是真的完美。
昨日凌晨,谷歌DeepMind悄悄發佈了V2A(Video-to-Audio)系統。這個系統能根據畫面內容或者手動輸入的提示詞直接為視頻配音。
沒過幾小時,另一個AI音頻克隆“扛把子”ElevenLabs就發佈了文字到音頻模型的API,並基於這一API做了一個Demo應用。這是當前唯一一個全自動將視頻與音頻相結合的AI工具,且完全開源、免費在線使用。
花開兩朵,各表一枝。由於谷歌並不打算向公眾開放V2A系統,那我們就先試用一下ElevenLabs的這個版本~
/ 01 / 看懂+對齊,生成全自動,但不能理解複雜畫面
AI視頻告別無聲,ElevenLabs為“徒手”製作大片的AI工作流補上最後一筆,我已經迫不及待,馬上就要為前幾天做出來的AI生產視頻加上配音了。(工具體驗:https://www.videotosoundeffects.com/)
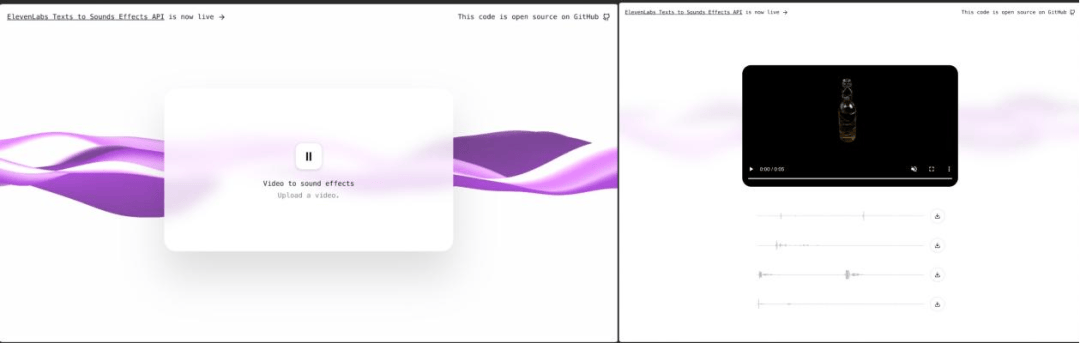 ▲ElevenLabs生成配音視頻step1→step2
▲ElevenLabs生成配音視頻step1→step2
我將luma生成的着火meme視頻、OpenAI成員暴走視頻、電影《閃靈》視頻等,以及Gen-3的示例視頻都投餵給了ElevenLabs,看看它會為這些畫面配上什麼聲音。
效果還不錯呀!其中,“某個歌手在獨唱”、“一個女人奔向正在發射的火箭”、“白頭髮女人大笑”等等配音跟場景很契合,“水下呼吸的女人”、“一個男人身後燃起大火”的視頻配音逼真細膩,非常有大片感。
經過約20個視頻的試煉,ElevenLabs能自動生成與視頻內容同步的音軌,而且生成配音基本已覆蓋影視配音的全部類型:
- 環境聲,例如水下呼吸聲、燃燒聲、滾輪聲、爆竹聲、樂器演奏、白噪音、嘈雜人聲等;
- 人聲,哭聲/笑聲、對白/獨白和歌聲等,但不能生成旁白;
- 音樂,比如馬戲團插畫的歡樂音樂、閃靈雙胞胎鏡頭的恐怖音樂等;
- 音效,例如槍聲、喜劇效果的搓碟聲、“OpneAI成員打架”時的機械崩壞聲等。
對比其他AI配音工具,ElevenLabs是第一個做到全自動為視頻結合生成式配音的工具,無需人工輸入提示詞也可以為視頻配音,且使用AI創建4個音軌供選擇,無需人工對齊音頻與視頻。
ElevenLabs能理解視頻的畫面,讀懂裏面的元素,知道畫面里正在發生什麼,應該出現什麼聲音,自動匹配上環境音、人聲、音樂和音效,在口型同步上表現也不錯。
再從聲音本身來説,烏鴉君發現ElevenLabs在聲音保真度方面表現不錯,水下呼吸聲、燃燒聲、滾輪聲、爆竹聲,甚至白噪音、嘈雜人聲等聲音都非常逼真,且音源豐富、音質尚可。
令人最想吐槽的一點是,ElevenLabs的音軌選擇較少(只有4條),我用同一個視頻多次投餵給ElevenLabs,始終只能得到相同的4個音軌。
音軌選擇少意味着使用者的控制範圍小、創作靈活度低,這使得ElevenLabs在一致性和運動性方面不穩定的缺陷被暴露無疑。理解簡單的畫面對ElevenLabs來説不是難題,但一旦畫面元素有了動態,配音時常出現節奏韻律不對、不能貼合畫面內容的情況,例如腳步聲不能符合人物走動的節奏等。
不過,這還只是ElevenLabs做視頻配音的一個Demo程序,期待它後續增加可選擇的音軌條數,提高理解複雜畫面的能力。
/ 02 / 完全開源,理解畫面能力弱於V2A
不到一天,ElevenLabs研究人員説這是他們的視頻到聲音應用的開發用時。這個敢直接硬剛谷歌的AI語音公司由前Google機器學習工程師Piotr Dabkowski和前Palantir策略分析師Staniszewski於2022年1月共同創立,自2022年以來一直從事生成AI語音。
對比谷歌V2A示例視頻和**ElevenLabs的生成視頻,我們發現後者要遜色前者不少,這可能是由於二者的工作原理存在的本質的差別。**Demo是基於公司在5月底發佈的文字到音頻模型打造的,工作原理如下:
- 以1秒鐘的間隔從視頻中提取4幀圖像(全部在客户端提取)
- 將幀和提示發送到 GPT-4o,以創建自定義的文本音效提示
- 使用 ElevenLabs 文本轉聲音特效API創建提示音效
- 在客户端使用 ffmpeg.wasm 將視頻和音頻合併為一個文件供下載
- 託管於vercel
ElevenLabs並不能直接實現畫面到音頻的轉換,而是利用了GPT-4o將視頻截圖轉換為文字提示詞,之後再輸入文字轉在幾秒內生成多條與畫面內容匹配的音頻。而DeepMind在博客中稱V2A能依靠自己的視覺能力理解視頻中的像素,這意味着ElevenLabs理解視頻的能力可能會弱於V2A。
另外,在API使用過程中,Elevenlabs按每次生成100個字符收費,在設置持續時間時按每秒生成25個字符收費。(開源地址:https://github.com/elevenlabs/elevenlabs-examples/tree/main/examples/sound-effects/video-to-sfx)
/ 03 / 結語:視頻生成帶飛音頻生成,深度偽造技術帶來自檢挑戰
一方面,OpenAI不斷推出高品質AI視頻生成模型Sora的新演示,另一方面目前這項技術對公眾仍然不可見,包括谷歌V2A。然而為了解決視頻配音這個問題,競爭對手Pika研究名叫“Lip Sync”的對口型功能。
AI視頻賽道在“百團大戰”的同時,AI音頻生成企業也正在扶搖直上。
ElevenLabs今年2月獲得了8000萬美元的B輪融資,估值超過10億美元,躋身獨角獸行列,估值在半年多的時間暴增10倍,包括像網易等遊戲開發商、《華盛頓郵報》等傳統媒體,都已經在大量使用ElevenLabs的文生語音技術。
聲音是影視作品給人以身臨其境之感的元素,未來,AI音頻生成可能會細化到人聲模擬、對口型、方言等各個部分,無限逼近真實世界。
與此同時,企業需要研究更多類似生物指紋嵌入應用的技術,來防範Deepfake(深度偽造)技術被用作不法用途。ElevenLabs曾表示將會推出新的措施,克隆聲音僅供付費用户使用,禁止多次違反平台協議的用户使用這種功能,將會推出一種新的AI檢測工具。
