“一家供應鏈公司的市值, 怎麼就超過了德國公司的總和?”|文化縱橫_風聞
文化纵横-《文化纵横》杂志官方账号-2小时前
Jai Vipra & Sarah Myers West
AI Now Institute
✪ 慧諾 (編譯) | 文化縱橫新媒體
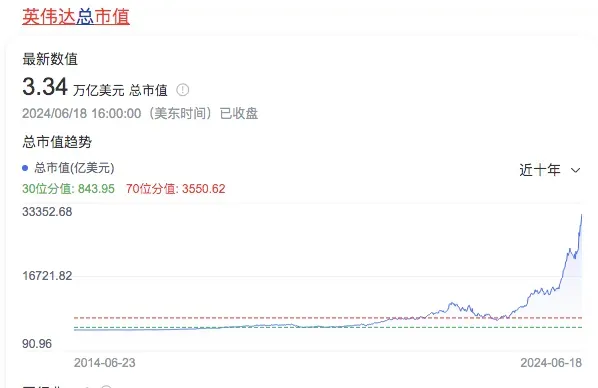
【導讀】英偉達公司股價在2023年飆升240%後,2024年又大幅上漲170%,並在本週首次成為全球市值最高的上市公司。這一股價的狂飆突顯了近年來人工智能領域的投資熱潮。自2024年起,人工智能(AI)應用如ChatGPT、Claude和Sora等對算力的需求,以及AI大模型迭代訓練所需的算力,都在急劇增加,這不僅推動了全球AI數據中心的快速發展,也極大地提升了對英偉達GPU等AI服務器芯片的需求。在芯片製造的緊張情緒之後,GPU的角色究竟是什麼?在當前硬件投資的熱潮中,人工智能的政治經濟格局預計會如何變化?
本文指出,“算力”作為現代AI的物質基礎,它決定了誰能開發AI、開發何種AI,以及誰能從中獲利。如今,全球“算力”面臨兩大可持續性問題:一是稀缺性,特別是高效訓練大規模AI模型所需的頂級芯片(如英偉達公司的H100和A100型號GPU);另一個是對環境的影響(芯片生產和數據/“算力”中心的高能耗)。隨着AI對算力的巨大需求(硬件、能源和資金),行業門檻與行業集中度已顯著提升。
**通過分析“算力”產業的全供應鏈,**作者分析,**AI的“大模型”路線短期難以改變:**其不僅與現有硬件兼容,還能回報在硬件上投資巨大的雲服務提供商(亞馬遜、微軟和谷歌等)及供應商(台積電、英偉達和AMD等)。為實現公司利益最大化,“大廠”有強烈動機通過推動大規模的AI項目,延續企業主導的“生態系統”,並鞏固雲計算基礎設施的主導地位。此外,面對英偉達在人工智能芯片領域的優勢,雲服務商也在加大自研力度,實現補充與替代。
作者指出,在行業和地緣競爭背景下,供應鏈格局也可能改變。首先,出於被雲服務“大廠”鎖死的擔憂,許多人工智能公司開始拒絕使用其提供的芯片,而英偉達也在產業鏈上下游投資以搭建獨立的服務體系;其次,由於“算力”已成為國家競爭的戰略資產,歐美主要國家也計劃出台相關法案,(通過反壟斷等手段)推動企業互相開放數據和計算資源,扶持更多新興企業。
本文為文化縱橫新媒體原創編譯系列“關鍵產業與關鍵資源之變”之八,摘譯自美國人工智能研究機構AI Now Institute專題報告《算力與人工智能》(Computational Power and AI)。小標題為編者自擬,文章僅代表作者觀點,供讀者參考辨析。
文化縱橫新媒體·國際觀察
2023年第21期 總第193期
算力與人工智能
計算能力(“算力”)是構建大規模人工智能的核心要素。隨着人工智能的快速發展,算力(以及數據和熟練勞動力)成為關鍵資源。然而,算力的供應鏈被少數幾家公司嚴重壟斷。

行業集中度影響技術開發人員如何製造和使用算力。我們將展示,即使是最大的人工智能公司,在算力稀缺時也會受到影響。硅谷頂級風投公司a16z的一份報告稱,**算力是“當今推動行業發展的主導因素”,**公司已將“超過80%的總資本用於計算資源”。
這種集中度還促使雲基礎設施提供商採取措施保護其市場主導地位,爭先發布尚未準備好廣泛使用的產品,並鼓勵客户鎖定在其雲生態系統中。
理解算力基礎設施對人工智能政治經濟的影響至關重要:它決定了誰能開發人工智能、開發何種人工智能以及誰能從中獲利。它勾勒了科技行業的集中度,激發了人工智能公司間的激烈競爭,並深刻影響了人工智能的環境足跡。主導公司能夠從依賴其服務的消費者和小企業那裏獲取租金,並在系統因單點故障而失靈時造成系統性危害。最令人擔憂的是,它擴大了這些公司在經濟和政治上的權力,鞏固了其對科技行業的控制。
此外,政策干預(如產業政策、出口管制和反壟斷執法)也對誰有權使用算力、以何種成本和條件使用算力產生深遠影響。但無論如何,瞭解人工智能對公眾究竟有何影響,物質基礎是重要的切入點。本文則提供了一個關鍵維度的入門知識:算力。
**▍**什麼是“算力”?它為什麼重要?
“算力”一詞有時指執行特定任務(如訓練人工智能AI模型)所需的計算次數,有時僅指代硬件(如芯片)。通常,我們用“算力”來指包含硬件和軟件的整體系統。
AI模型的最新進展得益於深度學習,這是一種利用大量數據構建理解層的機器學習技術。深度學習通過使用能快速並行執行大量計算的高端計算資源,推動了功能強大的模型開發。AI研究人員普遍認為,擴大規模是提高深度學習模型訓練準確性和性能的關鍵。這導致對計算能力的需求呈指數級增長,人們擔心這種增長速度難以持續。
這一趨勢已有歷史驗證:在深度學習(Deep Learning)時代前,AI模型使用的計算量大約每21.3個月翻一番;自2010年深度學習流行以來,這一時間縮短至5.7個月。自2015年以來,大規模模型的計算量約每9.9個月翻一番,而常規模型則每5.7個月翻一番。
計算資源的可持續性面臨兩大問題:一是稀缺性,特別是高效訓練大規模AI模型所需的頂級芯片(如英偉達的H100和A100)。由於供應有限,企業採用非常規手段,如抵押GPU籌資、成立GPU租賃組織,甚至國家購買GPU以獲得競爭優勢。計算能力的稀缺性不僅是公共政策的產物,也是影響該領域發展的重要因素,使雲基礎設施公司(如亞馬遜雲、谷歌雲、微軟雲)以及芯片公司(如英偉達、台積電)佔據主導地位。
**二是大規模計算對環境的影響。**芯片生產的污染和耗能巨大。例如,台積電一家公司就佔台灣能耗的4.8%,**超過台北市的能耗。**此外,運行數據中心對環境的成本同樣高,據估計,每次向ChatGPT提問都消耗相當於一瓶水的資源。
未來的研究方向是否會轉向更小的模型?要回答這個問題,需要了解為何大模型流行以及受益者。“硬件彩票”概念描述了某研究想法因最適合現有硬件和軟件而獲勝的現象。硬件和軟件決定了研究方向,而非相反。深度學習的神經網絡最初在硬件方面過於超前,因此長期被忽視。只有當神經網絡研究與海量數據、大型科技公司積累的計算資源及商業監控引入的激勵結構結合,AI系統的興趣才激增。隨着計算專業化程度提高,偏離主流硬件兼容理念的成本也會增加。
換句話説,如今的“大模型”不僅與現有硬件兼容,還能回報在硬件上投資巨大的雲基礎設施提供商。由於獲取GPU和網絡及建設數據中心基礎設施的前期成本高昂,超大規模提供商(如谷歌雲、微軟雲和亞馬遜雲)有強烈動機通過支持大規模AI、延續企業生態系統並鞏固雲計算領域的主導地位,最大化自己的投資。
**▍**算力需求如何影響人工智能發展?
計算資源的稀缺性已經成為大規模AI模型訓練和產品部署的主要瓶頸。馬斯克在2023年5月曾公開發言,“目前,GPU的獲取難度比毒品還高。”這種稀缺使得掌握這些資源的公司,如台積電、英偉達,以及谷歌、微軟和亞馬遜,擁有巨大的市場力量。這些公司還通過其龐大的平台生態系統獲取數據,並在大規模人工智能領域擁有先發優勢。
(一)初創企業必須“抱大腿”
對於初創企業來説,即使他們希望構建面向消費者的商業產品(而非專注大模型研發),對計算資源的需求依然強勁。為了進入這個領域,小公司必須獲取計算積分或與大型科技公司簽訂合同。此外,他們可以選擇與提供託管模型服務的公司合作,如OpenAI和Hugging Face,這些公司分別與微軟和亞馬遜建立了合作伙伴關係;谷歌也聲稱70%的通用人工智能(AGI)初創公司使用其雲設施。構建這些資源的成本過高,啓動成本高昂、計算堆棧缺乏互操作性,以及計算基礎設施關鍵組件的供應鏈存在瓶頸。計算成本和專業人才的需求也在不斷增長。
(二)大型科技公司也缺GPU
計算資源的瓶頸甚至影響到最大的AI公司。微軟在其年度報告中將“GPU的可用性”列為風險因素之一,並指出其數據中心依賴於許可、可建設土地、可預測能源、網絡供應和服務器的可用性。微軟現在正在限制其硬件的使用,並考慮與甲骨文合作,共享AI服務器以解決GPU短缺問題。其他主要雲基礎設施提供商的客户也面臨着需求增加的壓力,GPU的延遲和稀缺進一步説明了高度集中的行業帶來的不利影響。
OpenAI在資金和計算需求的壓力下,從非營利組織轉變為營利性有限合夥企業。OpenAI首席執行官奧特曼(Sam Altman)表示,**對大量計算的需求是公司許多決策的關鍵因素,推動其接受了微軟投資100億美元的要求。**奧特曼在國會聽證會上表示:“我們的GPU非常短缺,其他使用該工具的人越少越好。”谷歌也整合了其DeepMind和“谷歌大腦”團隊,英偉達的市值迅速上升,CoreWeave公司通過抵押其英偉達H100芯片籌集了23億美元的債務,進一步證實了這一點。
計算資源稀缺且價格昂貴,即使在擁有計算資源的雲基礎設施公司中也存在需求。這些因素激勵着控制關鍵瓶頸的公司通過各種方法(包括政策倡導)鞏固其市場主導地位。
(三)算力可以影響地緣政治
稀缺的算力甚至可以成為地緣政治的核心。各國將其作為工業政策的關鍵,採取措施遏制對手進步。事實上,半導體產業始於20世紀60年代,成為美國政治經濟的核心。美國的產業政策通過外交壓力和國家補貼等措施維持其在半導體制造業的主導地位。然而,20世紀90年代後,美國減少了投資,這使得台積電和荷蘭的ASML崛起。
**當前的中美人工智能“軍備競賽”,也將計算資源放在前沿。美國出口管制限制中國獲取先進計算能力,覆蓋了芯片製造整個供應鏈。**比如,英偉達被禁止在中國銷售其頂級芯片,只能提供降級版本。荷蘭的ASML也面臨出口管制,限制了其在中國的設備維護和修理。
計算資源也是各國人工智能戰略的重要組成部分。各國政府投入巨資提升學術研究和本土初創企業的計算能力。儘管如此,這些投資仍難以與行業巨頭匹敵。對算力不平衡的擔憂推動了美國“國家人工智能研究資源”(NAIRR)的設立,試圖整合雲服務商資源。
(四)我們究竟需要多少算力?
數量非常龐大。**“大模型”的計算量比同期其他AI模型高約100倍。**如果模型規模繼續按照當前的趨勢增長,有人估計到2037年,計算成本將超過整個美國GDP。儘管如此,AI模型仍在變得更大,因為規模與能力息息相關。大型AI模型市場的競爭仍然集中在模型的規模上。雖然數據質量和訓練方法對模型性能有重要影響,但要在這一市場競爭,最終需要構建比現有最先進模型更大的模型。
那些構建特定用例AI系統的人不一定需要從頭開始構建新模型,但他們會依賴託管模型或訪問API,這些通常通過主要雲基礎設施提供商提供。
計算成本可以預見地高。例如,GPT-3的最終訓練運行估計花費50萬至460萬美元,訓練GPT-4的成本可能在5000萬美元左右,整體訓練成本可能超過1億美元,因為在最終訓練之前需要進行大量試驗。
算力是訓練和運行模型所必需的。GPT-4的一次訓練運行需要大量計算,而每次ChatGPT生成響應時也需要計算(也被稱為“推理”)。每次推理的成本很低,但隨着推理次數的增加,總成本可能超過訓練成本。經合組織(OECD)的一份報告引用了一家大型雲計算提供商的估計,**其企業客户將3-4.5%的總計算基礎設施支出用於培訓,4-4.5%用於“推理”。**找到有關推理成本的準確數字具有挑戰性,因為公司將其視為競爭機密信息。本節涉及數字不包括能源和運營成本,這些成本也可能相當可觀。
**▍**人工智能涉及什麼樣的硬件?
構建大規模人工智能系統時,硬件類型至關重要。人工智能的計算需求增長速度往往超過硬件性能的提升速度。隨着大規模人工智能的成功,對先進芯片(如英偉達的H100 GPU)的需求增加,使用非頂尖芯片會顯著增加訓練時間和能耗,進而提高成本。頂尖芯片的性價比是普通CPU的10-1000倍,是舊版人工智能芯片的33倍。
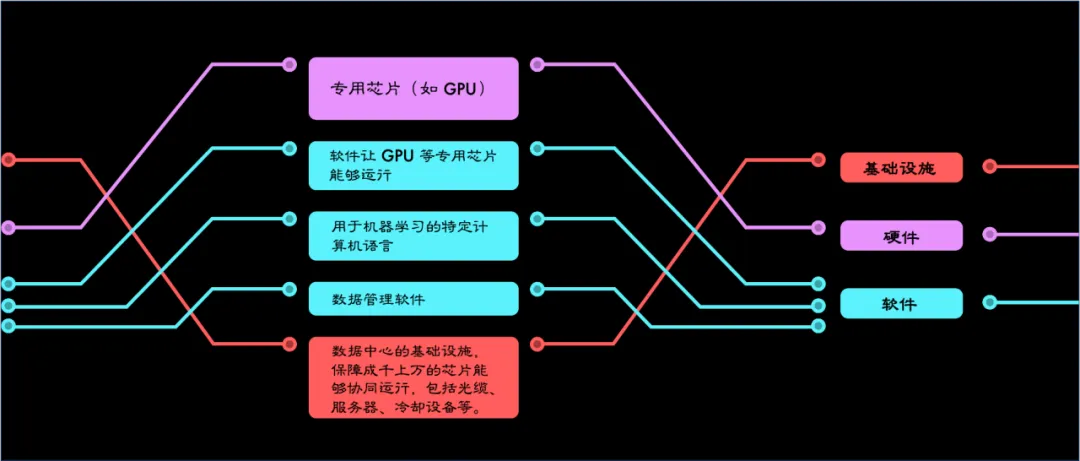
AI所需的專用計算硬件如下:
圖形處理單元(GPU):GPU最初設計用於圖像處理和計算機圖形,擅長並行處理小任務,因此非常適合構建AI系統。相比中央處理器(CPU),GPU可以並行執行計算,犧牲一些精度以提高效率。GPU的並行性和內存架構對AI非常有利,某些GPU可以在單個芯片上存儲整個大型AI模型。GPU主要用於訓練階段,有時也用於推理。
現場可編程門陣列(FPGA):FGPA可以加速數據採集和AI工作流程,在某些任務上(如語音識別和自然語言處理)比GPU更具優勢。儘管FPGA編碼耗時,它們通常用於推理。
專用集成電路(ASIC):ASIC是專為特定應用設計的集成電路,谷歌的張量處理單元(TPU)有時被歸類為ASIC。目前,ASIC的軟件層尚不完善。
**英偉達的H100芯片現已成為計算效率和性價比的行業標準,特別適合訓練大型人工智能系統。**H100的訓練速度比A100快9倍,推理速度快30倍。然而,這些系統對大多數人來説仍然昂貴:一個8-GPUH100服務器設置的成本約為30萬至40萬美元。
目前,擁有H100使用權的公司在大型AI系統方面具有優勢,但供應有限,僅台積電能製造H100。英偉達將其大部分分配給規模較小的雲計算公司,限制了試圖用自有芯片競爭的公司(如亞馬遜、谷歌和微軟)的分配。例如,英偉達在2022年11月向前加密採礦公司CoreWeave提供了H100的早期使用權,並隨後投資該公司。
擁有H100使用權的公司名單有限,僅包括微軟雲(及其部分客户如OpenAI、InflectionAI)、谷歌雲、亞馬遜雲、甲骨文、Mistral AI、Anthropic、CoreWeave、Lambda實驗室和風險投資公司C2Investments等。
**▍**人工智能硬件的供應鏈
全球半導體市場規模達1.4萬億美元,由幾家廠商主導,**而頂尖的AI芯片市場集中度更高。**供應鏈存在一些瓶頸,部分原因是生產成本高和專業知識匱乏。芯片設計在電子設計自動化軟件的幫助下進行,然後在製造廠生產,最後進行組裝、測試和封裝。
(一)芯片設計
設計高效的芯片是人工智能計算的關鍵。主要設計商有英特爾、AMD和英偉達;一些雲基礎設施提供商也在設計或計劃設計自己的芯片。例如,谷歌設計的TPU芯片用於其Gemini模型,Anthropic和Midjourney也使用TPU。微軟計劃在2024年發佈專有芯片Athena,亞馬遜雲也有自己的推理和訓練芯片。
芯片設計的進步可以用“節點”來描述,代表晶體管密度的提升。截至2020年,“領先節點”為5nm,三星和台積電正在生產3nm芯片,下一節點預計將縮小至2nm。
截至目前,**英偉達在AI芯片領域無可爭議地處於市場領導地位,並且利潤率很高。**OpenAI使用英偉達的A100訓練ChatGPT,計劃將最新的H100用於微軟雲的超級計算機。Meta也使用H100在其Grand Teton AI超級計算機中,預計明年OpenAI的ChatGPT將為英偉達帶來120億美元的收入。英偉達表示,與台積電的牢固關係對公司的成功至關重要。
AMD在消費級GPU市場佔有20%的份額,其芯片MI200在許多指標上優於A100,並且內存帶寬與H100相當。此外,AMD收購了FPGA製造商Xilinx,在“推理”領域有一定優勢。儘管AMD落後於英偉達,但在高需求環境中,AMD芯片可能成為一個有吸引力的替代品。相比之下,英特爾已經落後了,其Gaudi2芯片性能優於A100,但不及H100。
然而,英偉達的新競爭對手不斷湧現,如Cerebras和Graphcore,這些公司正在開發新技術以挑戰英偉達的市場地位。然而,這些新技術成本較高,對於大規模AI模型製造商可能更具成本效益。
英偉達的優勢之一在於其軟件產品CUDA(Compute Unified Device Architecture),**使程序員能夠將英偉達的GPU用於廣泛用途,並建立了一個活躍的開發者生態系統。**美國的出口限制使得中國無法獲得CUDA,為其人工智能發展造成了難以克服的障礙。
儘管英偉達的軟件主導地位逐漸受到挑戰,如OpenAI的Triton和臉書母公司(Meta)的PyTorch,但英偉達仍在硬件和總運營成本方面佔據主導地位。H100擁有定製的張量引擎,加快了訓練和推理速度。英偉達的規模和再投資能力使其能夠創建自定義的行業特定庫,進一步鞏固其市場領先地位。
(二)芯片製造
芯片製造的進入成本極高。隨着晶體管尺寸的減小,半導體行業的集中度也在增加。市場上的主要廠商包括台積電(佔收入的70-80%)、三星和英特爾(這兩家公司都落後於台積電約一年)。2019年,下一代芯片的生產成本估計為3000萬至8000萬美元。2017年,建造芯片製造廠的成本約為70億美元,如今已超過200億美元。
台積電是唯一能同時生產英偉達和AMD高端芯片的公司,也是唯一生產英特爾ArcGPU的公司。它能夠生產領先的3nm和2nm芯片,因此能決定芯片生產的優先級。任何與英偉達競爭的公司(如谷歌、微軟和亞馬遜)都必須面對台積電在大規模芯片製造方面的優勢。
製造成本每年增長11%,設計成本每年增長24%,而半導體市場每年僅增長7%。高固定成本帶來了高進入壁壘,但也可能導致即使是自然壟斷也難以收回成本。此外,荷蘭公司ASML是唯一能生產領先節點芯片光刻設備的公司,進一步加劇了壟斷。
(三)芯片組裝、測試和封裝(ATP)
ATP包括將晶圓切割成芯片並添加電線連接器,過程可以在內部進行或外包。ATP工作通常外包給包括中國在內的發展中國家,**中國在集成組裝方面尤其具有競爭力。**儘管台積電根據美國“芯片法案”在亞利桑那州建廠,但該工廠生產的芯片仍需運往台灣封裝,這意味着全球供應鏈網絡仍然不可或缺。
**▍**數據中心的市場格局如何?
大型人工智能模型通常使用由許多芯片組成的集羣(稱為人工智能超級計算機)進行訓練,這些超級計算機託管在數據中心。全球大約有10,000到30,000個數據中心,其中僅325到1400個可以託管AI超級計算機。這些數據中心支持高度集中的雲計算市場。
(一)巨大算力需求推動雲服務(與數據中心)集中度上升
**雲服務提供商通過大幅折扣或股權投資等方式吸引大型AI初創企業,以增加市場份額。**例如:
微軟投資了OpenAI,Azure是其獨家雲提供商,專為OpenAI打造AI超級計算機,並通過Azure OpenAI服務出售OpenAI模型獨家訪問權限;
Google DeepMind整合了Google Research的Brain團隊和DeepMind,主要原因是數據中心計算資源的競爭。谷歌雲是Anthropic和Cohere的首選雲合作伙伴,並向Anthropic投資了3億美元;
亞馬遜雲(AWS)與Hugging Face達成收入分成協議,創建了Amazon Bedrock API服務,允許訪問多個AI模型,複製了“應用商店”模式並引發“尋租”質疑;
甲骨文(Oracle)儘管市場份額僅為5%,但通過提供計算積分、無競爭關係以吸引AI初創公司,並優化其硬件以用於機器學習;
此外,雲服務提供商還投資AI服務公司,以將其轉變為雲客户。例如,Google投資Runway,使其成為雲客户。
(二)雲服務提供商引發廣泛擔憂
一些人工智能公司儘量避免使用雲服務提供商設計的芯片,因為他們擔心可能被鎖定在特定的生態系統中。
雲提供商的市場影響不僅使初創公司感到不安,甚至主導上游市場的參與者如英偉達也感到憂慮。英偉達試圖在雲市場上引入競爭**,以降低成本並減少雲提供商對芯片設計市場的壟斷可能性。**英偉達選擇優先向較小的參與者如CoreWeave和Lambda Labs提供其H100芯片的使用權,並向CoreWeave投資了1億美元,使後者得以籌集23億美元的債務。類似的投資協議正在與Lambda Labs洽談中。因此,大型雲提供商和人工智能公司不得不從英偉達偏愛的小型提供商那裏租用計算資源。例如,微軟簽署了一項可能價值數十億美元的協議,以使用CoreWeave的GPU。
英偉達還直接進軍雲業務,利用其在先進芯片設計方面的領先地位。它與微軟、谷歌和甲骨文(注意不包括亞馬遜AWS)達成協議,在它們的數據中心內租用服務器,並通過DGX Cloud項目向人工智能軟件開發商高價出租這些服務器。此服務還提供預訓練的模型,包括英偉達的Megatron 530B大型語言模型和PeopleNet(一種用於識別視頻中人類的模型)。
**▍**如何持續滿足人工智能的算力需求?
(一)降低計算成本
一種方法是改進硬件,以便使用更少的芯片完成更多計算。儘管芯片在過去幾年中取得了長足進步,但專家們對這一速度是否正在放緩存在分歧。摩爾定律是最著名的芯片性能進步基準,它預測芯片上的晶體管數量大約每兩年翻一番。隨着晶體管接近物理尺寸極限,摩爾定律可能會放緩。
算法效率的提升同樣重要,2020年OpenAI估計,訓練2012年模型的計算需求減少了44倍,超過了純硬件改進的貢獻。算法效率已經成為 AI 巨頭激烈競爭的領域——基於目前的硬件計算能力,理論上仍可以實現更高的效率。值得注意的是,英偉達一直在戰略性地收購專注於此的公司。
(二)使用較小的模型
人工智能研究人員可以通過採用較小的模型來降低計算使用量。儘管大規模模型目前被廣泛使用,斯坦福大學的Alpaca等較小模型在某些任務上已經顯示出與大模型接近的能力。然而,模仿大模型的能力並不總是能夠捕捉到其全部潛力,這表明基礎模型的規模對模型的表現至關重要。
(三)範式轉變和突破
計算領域可能會因為範式轉變(如“神經形態計算”或量子計算)而迎來全新的市場結構和更高的計算能力。儘管這些範式尚未廣泛商業化,它們有望改變計算領域的格局。此外,內存技術的進步也可能對計算市場產生重大影響,但目前還沒有看到有望取得突破的跡象。聯邦學習作為一種去中心化的訓練方法,可能有助於在保護數據隱私的同時實現規模化,但仍面臨多個技術和實施挑戰。
**▍**主要國家的政策應對
計算能力是人工智能產業政策的新興框架的重要組成部分。各國正在尋求在人工智能領域取得競爭優勢,主要通過大力投資半導體開發,並通過嚴格的出口管制削弱對手,這些政策旨在以國家安全為由限制算力供應鏈的訪問。
(一)美國
2022 年,《芯片與科學法案》是近年來科技領域通過的重要產業政策措施之一,旨在發展美國的國家半導體制造業。根據半導體行業協會的數據,這項法案通過後,宣佈了 50 多個新的半導體項目,**總價值超過 2000 億美元。**其中,台積電計劃在亞利桑那州鳳凰城投資 400 億美元建設新工廠。儘管如此,台積電新工廠生產的芯片仍將被送回台灣進行封裝和組裝,這表明市場補貼可能會加劇而非改善市場集中度。
另一方面,美國“國家人工智能研究資源”(NAIRR,National AI Research Resource)也是與計算相關的政策提案的重要部分。2020 年,《國家人工智能倡議法案》要求國家科學基金會制定共享研究基礎設施提案,以擴展計算能力、高質量數據和其他支持的訪問範圍,促進更廣泛的人工智能發展。然而,NAIRR的設計被批評未能兑現其“民主化”人工智能開發過程的承諾,這可能需要與大型雲基礎設施提供商簽訂許可合同,使其在當前的計算資源短缺情況下維持彈性。
(二)歐洲
在法國,計算能力一直是國家利益的重要組成部分,有助於法國發展其人工智能能力。2019 年,法國資助了Jean Zay超級計算機的建設,由法國國家科學研究中心(CNRS)運營,用於訓練BigScience的BLOOM大型人工智能模型。此外,法國的初創企業行業也得到了廣泛支持,最近Xaiver Niel宣佈與英偉達合作,投資2億歐元支持法國人工智能研究。
英國最近宣佈計劃斥資 9 億英鎊建造超級計算機,以支持國內的人工智能研究,並投資 25 億英鎊用於量子技術。此外,英國還將直接從英偉達、AMD 和英特爾購買 GPU,以提升其計算能力。
(三)針對雲服務行業集中度的調查
全球範圍內少數執法機構已啓動或完成了對雲計算市場的研究,探索雲計算的集中度及其對經濟的潛在影響。
美國聯邦貿易委員會(FTC)最近完成了一項針對雲計算的調查,特別關注雲計算集中度對人工智能的潛在影響。調查表明,經濟中大量依賴於少數幾個雲服務提供商可能會帶來不利影響。此外,財政部的一份報告也表達了對“單點故障”的擔憂,指出這可能會對整個金融部門產生連鎖影響。FTC發文指出,現有企業可能通過獨家雲合作伙伴關係等方式利用其在計算服務領域的權力,對新進入者採取不同的歧視性待遇,從而抑制人工智能領域的競爭。
特別值得注意的是,FTC曾在2022年阻止了英偉達收購芯片設計公司Arm的計劃,這一併購案被認為是半導體芯片史上最大的。阻止的理由之一是擔心這會損害創新,阻礙Arm開發與英偉達專有硬件無關的片上人工智能功能。第二個擔憂是英偉達可能會限制或降低競爭對手對Arm技術的訪問,從而破壞Arm在市場上的“中立”地位。
英國競爭與市場管理局最近發佈了關於人工智能基礎模型的初步報告,並計劃在2024年初啓動後續工作。該報告確認了人工智能市場中的重要垂直整合,並強調了通過合作伙伴關係和戰略投資構建的整個市場網絡。報告指出,對大型計算能力的需求和獲取途徑將成為市場集中的關鍵推動因素。
針對這些問題,英國通信管理局正在對雲服務市場展開調查,初步結果可能會建議英國競爭與市場管理局對雲市場的集中度進行正式調查。通信管理局在中期報告中表示,他們有理由懷疑公共雲基礎設施市場中的某些特徵可能會對英國的競爭產生不利影響。此外,韓國、荷蘭、日本和法國也在開始探討雲計算反壟斷問題。
**▍**下一步該怎麼做?未來政策干預的要點
(一)反壟斷
在人工智能計算市場,反壟斷政策審查關注於市場集中度高的計算堆棧。市場參與者擔心垂直整合會對價值鏈不同部分造成影響:人工智能公司擔心雲提供商整合下游市場,芯片提供商可能通過硬件與軟件捆綁濫用主導地位。同時,雲提供商也可能通過垂直整合對計算堆棧產生影響,成為人工智能芯片的定價者。
針對這些問題,監管的潛在方法包括:將雲供應與芯片設計分開,以避免供應商鎖定;分離計算硬件與軟件,或強制要求互操作性,以促進競爭和開發人員的選擇權;將人工智能模型開發與雲基礎設施分離,防止競爭不公平和市場傾斜;對關鍵計算提供商制定非歧視或公共承運人義務,確保公平服務;通過合併執法進行早期干預,防止市場進一步集中;調查和打擊反競爭行為,例如禁止默認捆綁和限制性許可條款;在人工智能計算市場應用平台和市場相關的反壟斷原則,確保平等對待平台參與者。
(二)人才政策
禁止競業協議將對緩解人才短缺產生積極影響。目前,高昂的計算成本增加了對專業人才的需求,因為只有具備專業知識的人才能充分利用有限的硬件資源。由於專業人才稀缺可能成為行業的進入壁壘,政府可以考慮採取措施減少人才流動的障礙,例如禁止競業協議。聯邦貿易委員會正在考慮這一政策。
(三)數據最小化
數據和計算是人工智能的關鍵要素,但它們是緊密關聯的。大量高質量數據可以使模型表現出色,甚至在計算資源有限的情況下,小模型也能勝過使用低質量數據的大模型。儘管縮放定律對給定計算量下可有效使用的數據量進行了限制,但隨着免費互聯網數據的減少,獨佔數據訪問變得愈加重要。因為免費數據資源已經被廣泛使用,新生成的數據也開始受到平台的更多保護。例如,Reddit和Twitter已經採取措施防止其數據被免費使用。此外,隨着互聯網出現更多人工智能生成的內容,互聯網數據的相對價值也在下降。
無法在計算能力上超過競爭對手的AI公司會嘗試通過數據提升模型質量。隨着模型規模的擴大,即使是計算資源最豐富的公司,這種趨勢也會增強。值得注意的是,雲服務提供商,尤其是大型科技公司,擁有大量個人和非個人數據的獨家訪問權。據報道,OpenAI已經使用視頻網站YouTube數據訓練其模型,這為谷歌利用包括YouTube、Gmail、GoogleDrive等服務的數據打開了大門。類似地,微軟可能會使用其企業服務中的數據,亞馬遜也可以使用其雲服務中的數據。然而,數據在市場中變得越來越不透明,許多公司不願透露其數據使用情況。
為防止數據濫用,政府可以通過更新和執行數據保護法律來減少AI計算市場的集中度。具體措施包括:接受數據最小化要求——數據政策就是人工智能政策,限制不受控制的商業監控行為將對人工智能產生重要影響;禁止數據二次使用,聯邦貿易委員會在最近的亞馬遜Alexa案中已經概述了這一原則。