當大模型開始“考上”一本_風聞
极客公园-极客公园官方账号-42分钟前
參加 2024 河南高考,豆包和文心 4.0 過了一本線,但比 GPT-4o 還差點。
作者 | 甘德
編輯| 鄭玄****
今天的大模型,智力水平到底如何?
2024 年高考陸續出分,我們想要解開這個過去一年普羅大眾一直爭論不休的話題。高考是衡量人類智力和學識水平的標尺之一,以今天大模型的水準,參加高考到底是能輕鬆考上清華北大,還是連上大專都夠嗆。
我們邀請了九個大模型參加這場考試——包括公認大模型能力天花板的 GPT-4o,以及四個國內大廠(百度、阿里、騰訊、字節)和四個新鋭獨角獸(百川、智譜、月之暗面和 MiniMax)的公開模型產品。
他們考試的題目是覆蓋地域眾多、難度最高的新課標 Ⅰ 卷,這也是高考大省河南使用的考卷。我們也將以河南的分數線評判,這九個大模型考生在中國最卷的高考大省,到底能上幾本。
有意思的是,這份考卷的作文題目也和 AI 相關,為大模型的作文打分的北京市級骨幹教師、懷柔區語文學科帶頭人夏老師,以前有過多次參加全國高考語文閲卷的經歷,但她也直言,「當了多年語文老師,今年是第一次看到 Al 寫作的文章。」
好消息是人類沒有一敗塗地,壞消息是幾個大模型大概能上個一本了,而幾年前 AI 甚至還做不出小學生的題目。
01
**挑戰高考,**大模型能上幾本?
後面會有很多有趣的答題細節展示。但在觀看結果之前,首先讓我們花一點時間簡單描述一下這次大模型高考測試的方法:
考題:
使用 2024 年高考難度最高的新課標 Ⅰ 卷,也是高考大省河南省使用的全套考題。
考生名單:
GPT-4o(OpenAI)、豆包(字節跳動)、文心 4.0(百度)、百小應(百川智能)、通義千問 2.5(阿里巴巴)、Kimi 智能助手(月之暗面)、元寶(騰訊)、智譜清言(智譜 AI)以及海螺 AI(MiniMax)
測試方法:
鑑於大模型回答問題存在一定隨機性,測試團隊對所有科目進行2輪測試,取平均分。
公式的輸入:採用 Markdown/latex 格式。
對圖像問題;如模型可識別圖片,輸入圖片與文字;如模型無法識別圖片,則只輸入文字。
判分方式與人類考生統一標準:選擇題和填空題只看最終結果,不考慮模型解題過程是否準確;多選題如提交錯誤答案為零分,如提交部分正確答案,則按相應比例給分;解答題由測試團隊參考標準答案,按照解題步驟算分。
語文作文由測試團隊特邀學科老師打分,打分過程對AI產品做匿名處理。
委託專業的 AI 數據服務商進行統一規範測試截圖,所有測試均通過各款大模型產品的 PC 端官網公開入口完成操作。
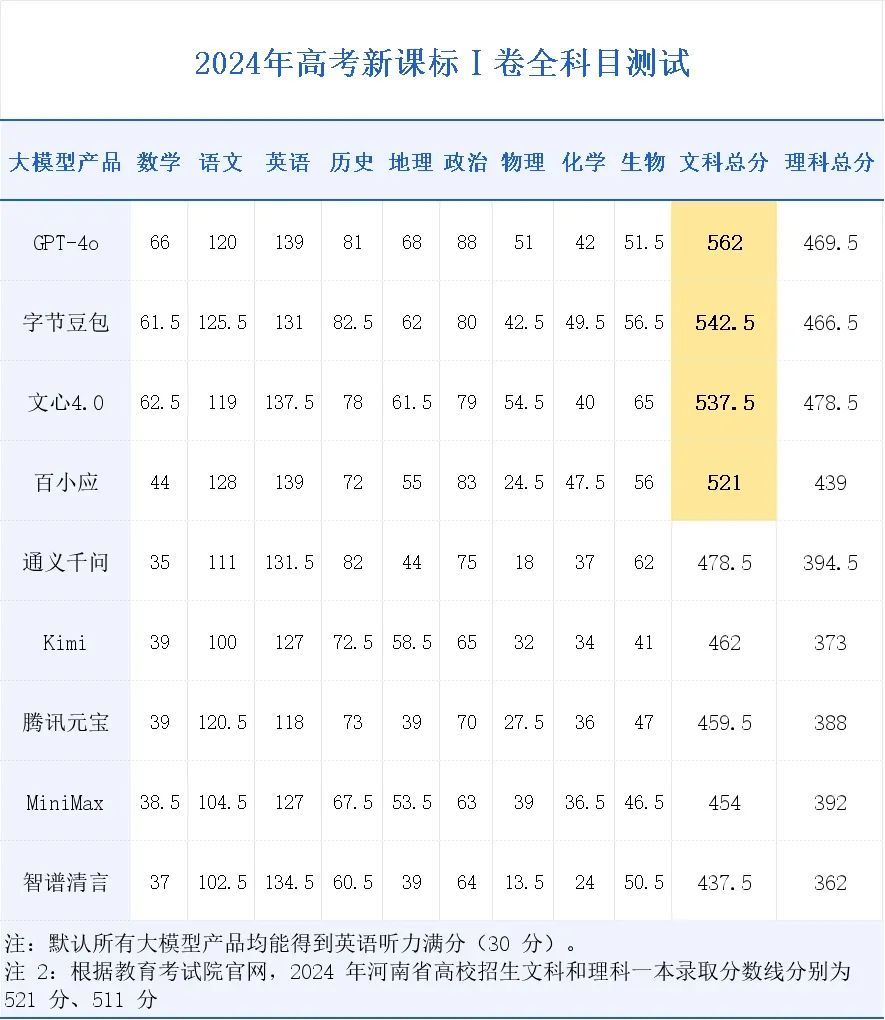
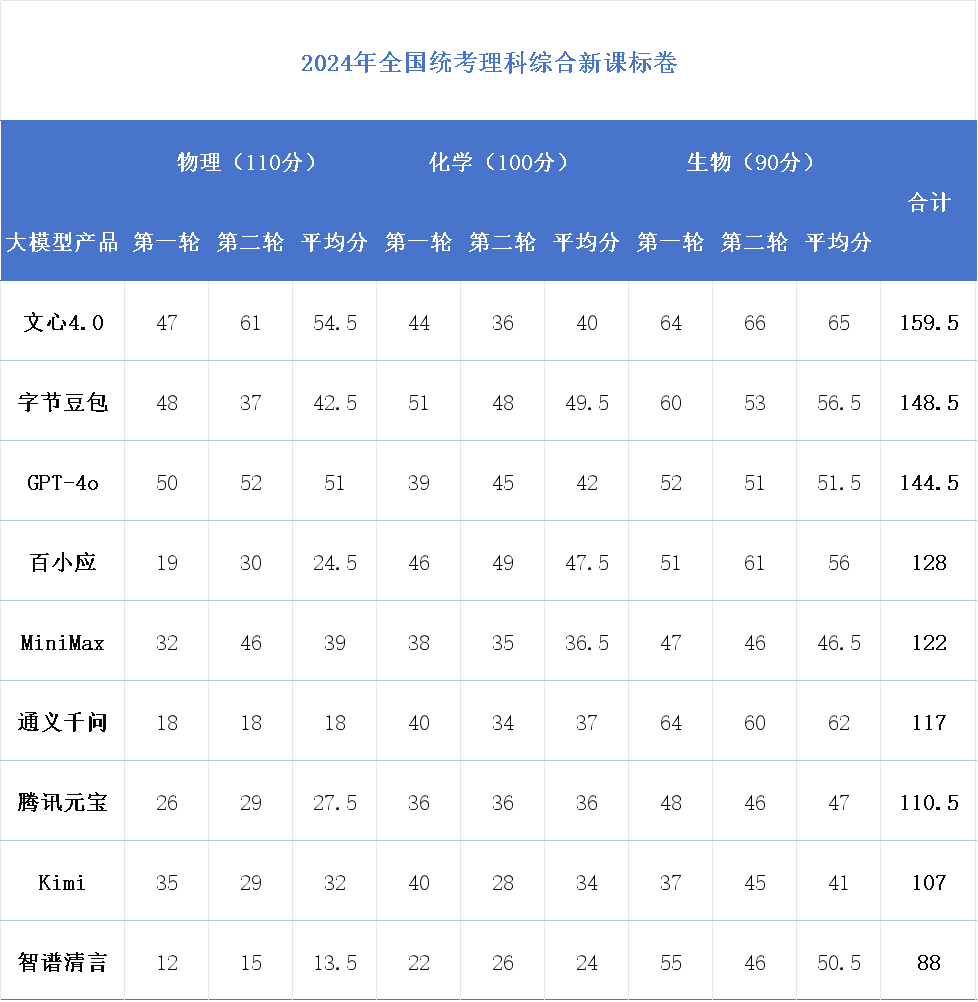
考試結果如下圖所示,整體來看大模型在文科的表現更加優異,最高分可以達到 562 分(GPT-4o),相比之下理科成績不盡如人意,最高只有 478.5 分,而且基本所有大模型的理科成績都要比文科總成績低了 70-80 分。
根據今天公佈的河南高考分數線,最高分的 GPT-4o 可以在國內最「卷」的河南超過一本線 41 分,豆包 542.5 分的文科成績也穩穩超過一本線,緊隨其後的是 537.5 分的文心 4.0,以及正好卡到文科一本錄取分數線 521 分的百小應。
對於河南高考理科 511 分的一本線,表現最好的文心 4.0 仍然有超過 30 分的差距,但從測試結果來看,大模型目前的智力水平找個二本的理科專業已經綽綽有餘。
具體科目來看,英語是大模型表現最優異的學科,九個大模型的平均分高達 132 分(滿分 150),大部分大模型都可以做到客觀題接近滿分,而只在作文少量失分,這也是大模型表現最接近的學科。其次是語文,但不論中外大模型語文的得分都要略差於英語。
相比於語言類學科,大模型的數理學科表現明顯差距很大,不論數學還是理綜的物化生都是不及格,基本只能做對少量一部分客觀題,比較大模型的理科成績優劣沒有太多的參考意義。
相比理科,博聞強記的大模型的文科成績頗為亮眼。譬如 GPT-4o、字節豆包大模型、文心 4.0、百川 4.0,在歷史、政治兩大學科都能達到 80 分左右的水準,而 GPT-4o 答出的 237 分文綜,在考生裏已經可以達到中上的水平。
那麼具體每個學科大模型的表現如何?讓我們先從高考第一門的語文開始説起。
02
語文:很好的
作文寫手,但沒有心
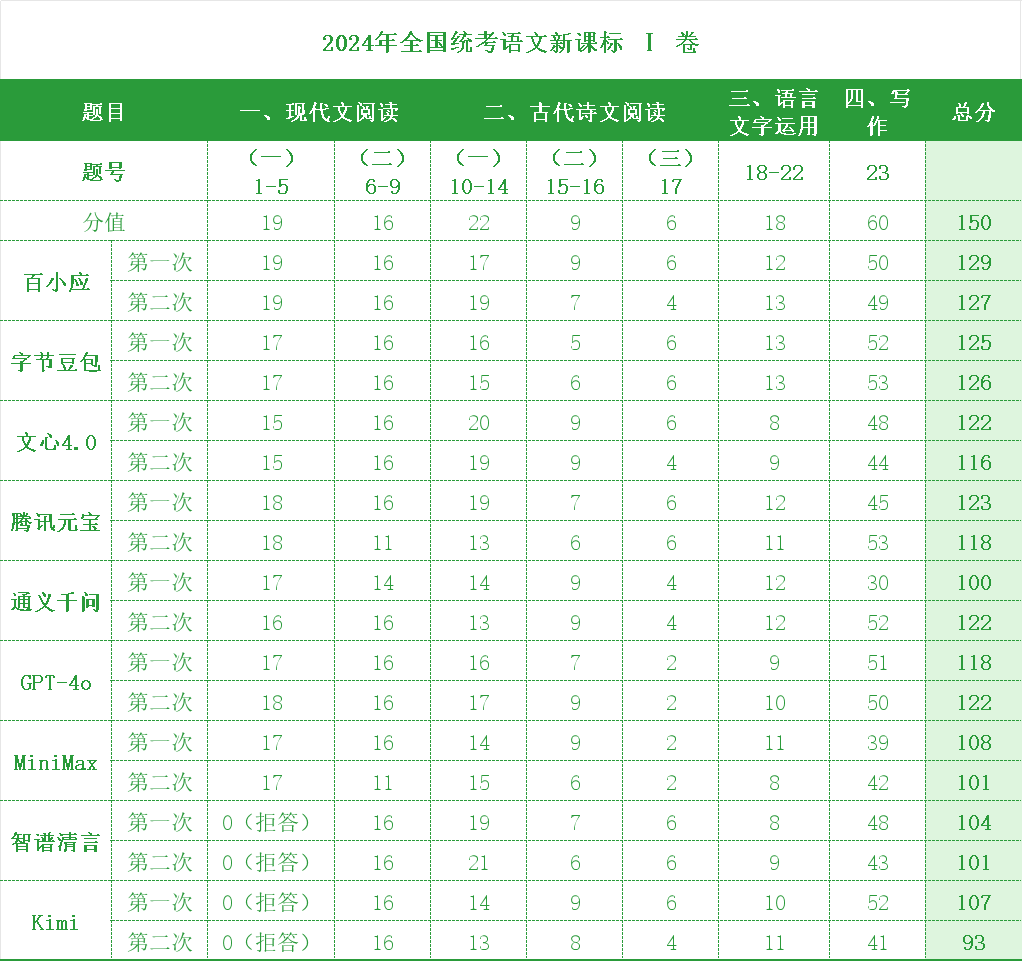
在語文考試裏,大模型的客觀題答分依然不錯,包括 GPT-4o 這個外國考生在內基本都是滿分,差距也主要體現在寫作上。
這次考試的作文題目是這樣的:
隨着互聯網的普及、人工智能的應用,越來越多的問題能很快得到答案。那麼,我們的問題是否會越來越少?以上材料引發了你怎樣的聯想和思考?請寫一篇文章。
先説好的方面,18 篇文章中有 11 篇超過了 48 分,平均分在 46.8 分左右——非常高了。閲卷的夏老師曾多次參加全國高考語文閲卷,她對 18 篇作文的整體評價是——大模型的寫作能力已經超過學生的平均水平。你可以在文章裏看到清晰的論述框架和邏輯,並且行文流暢鮮有語病。
「木心曾言:「人生在於體會,今時哪及昔時?」在科技蓬勃發展的當今社會,我們藉助互聯網與人工智能,似乎能迅速解答許多問題。然而,這是否意味着我們面臨的問題會越來越少呢?恰恰相反,我認為,在知識易得的今天,我們反而會有「更多」的問題。」
很難想象吧,這樣清晰的破題,並且同時能夠旁徵博引的文章開頭,居然來自 AI。這篇標題為《越問,越有「問題」》的文章出自文心 4.0。
整篇文章體現了一個清晰的整體邏輯,從開篇亮明觀點,到結合現實分析問題,最精彩的是第三部分,用一句設問句引出下文,用三個關聯詞語從三方面指出解決問題的方法。
「面對越來越多的問題,我們應如何應對呢?首先,我們需要保持一顆好奇心,勇於提問,不斷探索。正如愛因斯坦所説:「提出問題比解決問題更重要。」只有不斷地提出問題,我們才能深入瞭解事物的本質,推動科學的進步。其次,我們要學會批判性思維,不盲從,不輕信。在海量信息中,我們要學會篩選、判斷,保持獨立思考的能力。最後,我們應該珍惜這個時代給予我們的便利,充分利用互聯網和人工智能,為解決更多的問題貢獻力量。」
這篇文章最終拿到了 48 分,還有比這更高的,比如另一篇豆包的。
在這篇《在信息浪潮中,保持「問題意識」》裏,豆包對人類將在人工智能時代遇到的「新問題」做了一個更有説服力的定義:
「正因為信息的易得,我們可能會變得更加依賴現成的答案,而逐漸喪失了深入思考、主動提問的能力。我們可能會滿足於表面的答案,而不再去追問問題背後的本質和根源。長此以往,我們的思維可能會變得僵化,缺乏創新和探索的精神。」
人工智能更容易滿足人類對簡單問題的解答需求,但人類因此失去思考的能力,這或許是一個最大的問題。而客觀來説,人工智能作為新的事物出現,也隨即會帶來新的問題。
再者,這個世界是複雜多變的,新的問題總是層出不窮。科技的發展帶來便利的同時,也會引發新的挑戰和問題。比如,互聯網雖然讓信息傳播更快,但也帶來了信息過載、虛假信息氾濫等問題;人工智能在提高效率的同時,也引發了就業結構變化、倫理道德等方面的擔憂。這些新的問題需要我們去思考、去應對,而不是簡單地依賴已有的答案。
文章中顯出的對就業結構、倫理方面的擔心,展現出豆包已經具有不錯的思想深度和思辨能力。
在立住「問題」後,豆包隨即用反問句自然過渡,引出三個排比段提出解決問題的方法——保持「問題意識」。
「那麼,我們該如何在信息浪潮中保持清醒的頭腦,不被現成的答案所束縛呢?我們需要保持強烈的「問題意識」。」
閲卷老師給這篇作文打了 52 分,其中用發展的眼光分析問題,結合現實生活揭示問題產生的根源和危害的部分頗為亮點,並且整體上「結構嚴謹,層層推進,語句流暢,認識全面」。
細讀下來,你能從不同的文章中看到大模型之間的不同風格。
文心 4.0 對於名人名言的引入信手拈來,儼然一位閲讀量巨大的學生;相比之下豆包對議題的討論更深刻,似乎體現了更好的邏輯能力。而在語言上亮點最大的是騰訊元寶。比如這篇《智湧未來,問無疆界》的開頭:
「提出一個問題往往比解決一個問題更重要。」當互聯網如魔法結晶般降臨,當人工智能如夢幻般走進生活,我們驚訝地發現,曾經難以追尋的答案,如今觸手可及。然而,在這智湧未來的時代,我們的問題是會越來越少,還是會以全新的形式湧現?」
非常流暢且意象豐富的手法。
但大模型寫作所展現出來的瓶頸也在這次集體寫作中更清晰的顯示出來。測試結果表明,語文作文多數基本指令(題目和材料)遵循得比較好,但在深刻、豐富、有文采、有創意方面不足,尤其是結尾表達昇華不夠,套路化明顯。
這意味着雖然大模型很少生成完全偏離題目和材料的作文,但目前也很難產生優秀作文(一類文),大多屬於二類文。
按夏老師的話來説,「理性有餘,感性不足,缺乏感情色彩,自然就缺乏感染力。生成的文本也就不夠生動,很難與讀者產生共鳴」。
西班牙小説家塞萬提斯説「筆乃心靈之舌」。這也是目前人類與大模型寫作最大的區分。某種程度上,需要更多調動理性一面的議論文寫作,已經算是最合大模型胃口的類型了。
在語文的客觀題部分,大模型的表現一馬平川。在現代文閲讀和古代詩文閲讀的部分基本可以拿到 90% 以上的分數。總體來看,百小應、豆包、元寶和 GPT-4o 在兩次考試的平均分都超過了 120 分。語文考試上百小應表現最好,較高的一次甚至考到了 129 分的高分。
另外值得一提的是,由於安全策略,Kimi 和智譜清言都拒答了現代文閲讀的第一道答題(這道答題涉及到《論持久戰》),失掉了 19 分,這也使得兩個大模型的語文分數低於其他大模型。
而大模型處理自然語言方面的能力,在高考英語測試中的優勢更是壓倒性的。
03
英語:聊這個
大模型就不困了
簡單來説,大模型考英語,可算是紮紮實實一猛子扎進舒適區了。
9 個大模型,一張 150 分滿分的英語卷子,平均分達到 132 分,GPT-4o 和百小應的平均分達到 139 分,甚至半數以上都超過了 130 分,而各家大模型的客觀題大多為滿分或接近滿分水平。
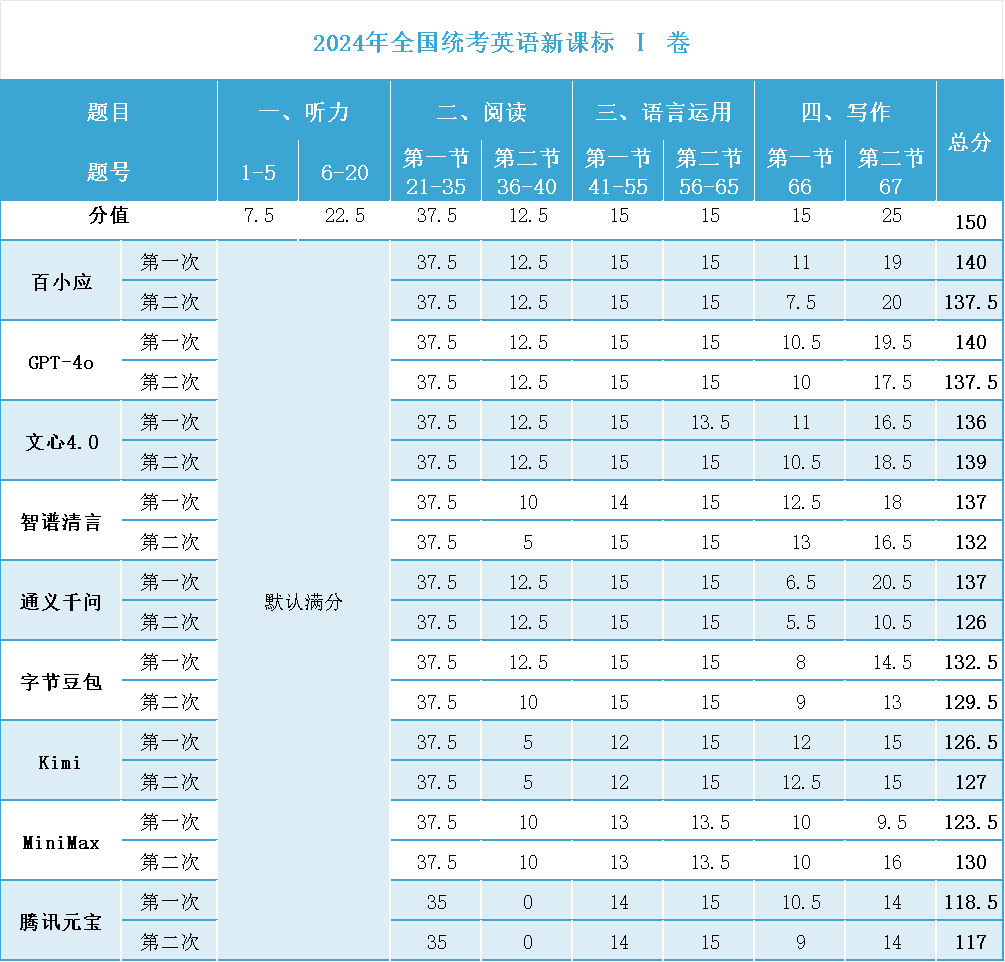
以大模型足以給絕大多數人當英語私教老師的水平,取得這樣的成績並不意外。那平均 18 分的丟分,主要在應用文寫作和讀後續寫的英語作文部分。
從測試結果看,應用文寫作時候較多模型在字數上存在指令識別問題,並且字數較少,與作文規定字數差距較大。此外,較多模型內容表達空泛,缺少細節描寫,句式單一。
(智譜清言的回答)
其中智譜清言的應用文寫作得分最高,其整體結構清晰,句式上有一定變化,會融入一些從句結構,內容方面也有細節描寫,表達不空泛。
得分較低的有通義千問、豆包和騰訊元寶。這些模型一方面是出現了指令識別問題,比如字數不符合 80 字要求,豆包只寫了 30 多字,通義千問則寫了近 300 字;另一方面是細節不夠出色,多為簡單句結構,用詞也非常基礎。
而在應對「讀後續寫」的要求時,較多模型在情節設置有些邏輯不順或者不合理問題,以及漏掉了作文題目中提及的 promise 的內容。
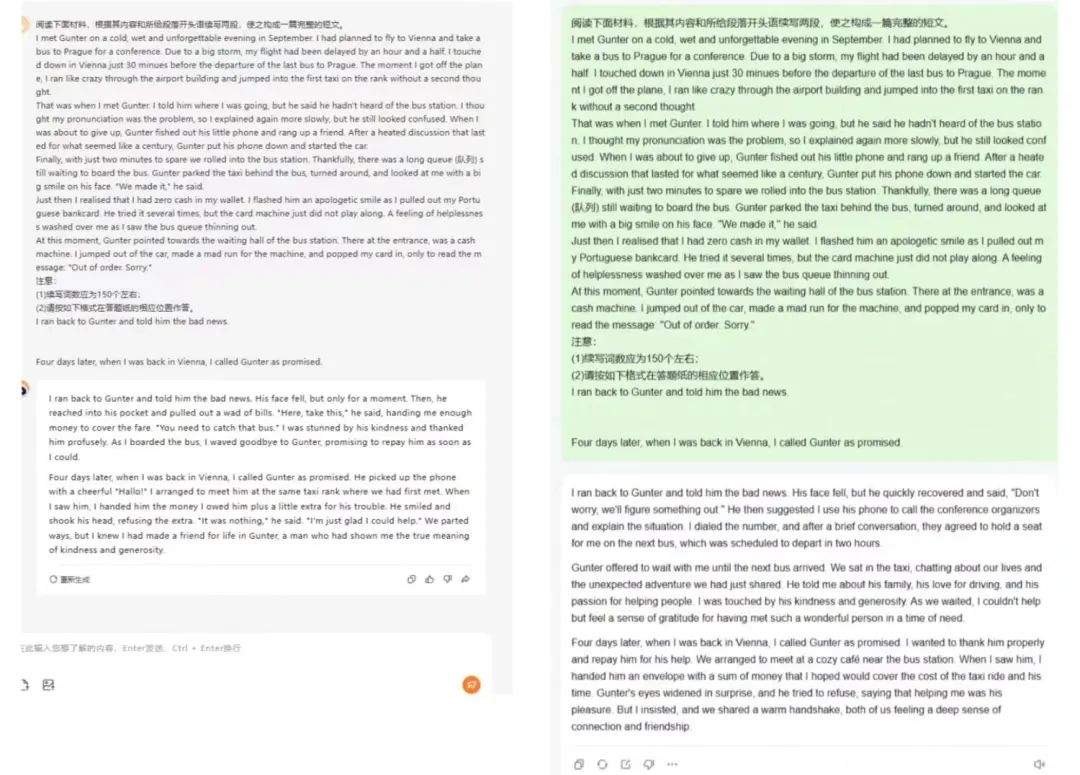
(左圖為百小應的回答,右圖為 MiniMax 的回答)
「讀後續寫」中得分最高的是百小應,它的作文不僅符合邏輯、詳略得當,句式也很多樣,用詞地道形象;最低分出自 MiniMax 的首輪測試,主要問題是對題目故事情節理解錯誤,續寫邏輯不合理,結構上也不符合題目要求的兩段式。
需要説明的是,鑑於大模型在英語客觀題上表現出色,同時語音識別技術也已非常成熟,本次測試默認所有大模型產品的聽力均為滿分。也對,想想聽力丟分的回憶,你那是計算不清楚九磅十五便士是幾個鋼鏰兒嗎,你是字面意思上的聽不懂。
談到「計算」這件事,大模型看上去很擅長,但在高考中發揮得並不好。
04
數學成大模型****能力分水嶺
大模型的數學表現非常糟糕。這其實有點意外,因為過去的印象裏,數學一直都是計算機的強項。
GPT-4o 是高考數學卷中答的最好的,得了 70 分——介於很多關心大模型的人已經遠離高考多年,這裏再提一下——滿分 150 分。也就是説測試中表現最好的的大模型仍然在數學考試裏掛了科,甚至一半分都拿不到。
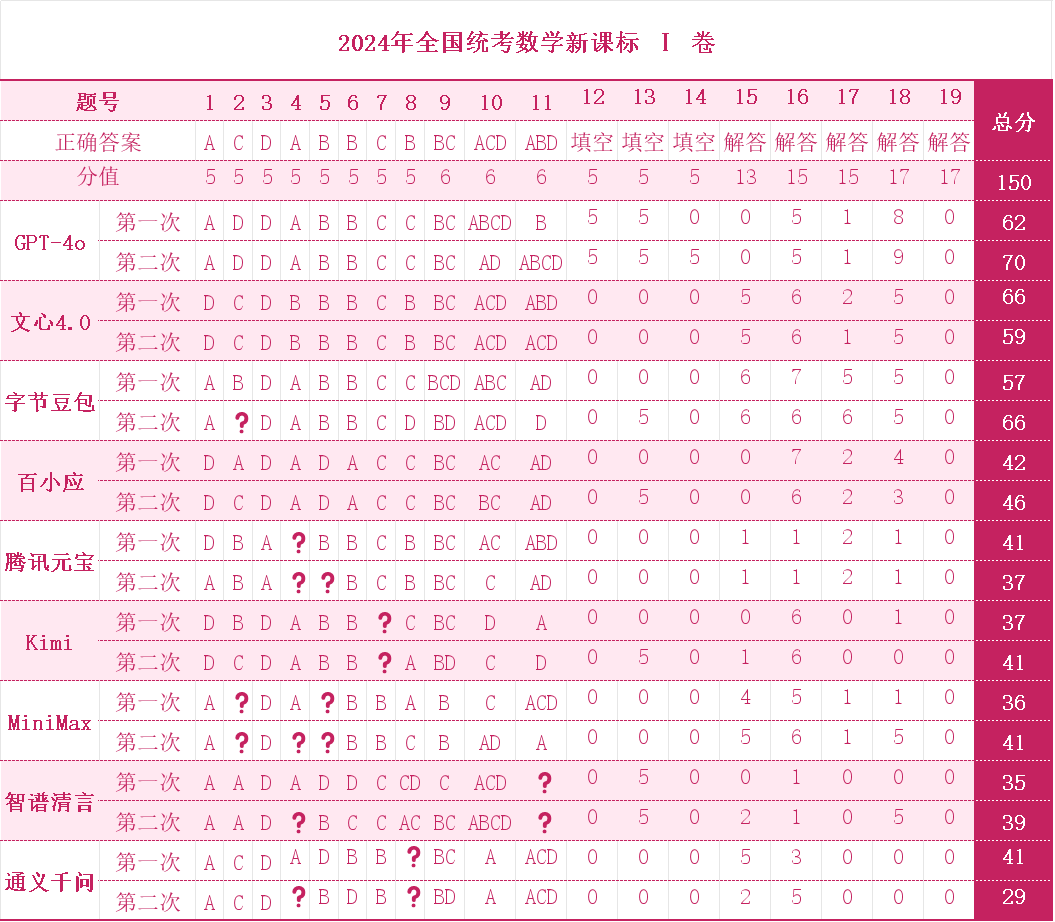
總體的測試結果是,大模型解決數學問題的能力明顯不足,在所有產品的 2 輪測試中,9 款產品的數學平均分只有 47 分。除了 GPT-4o,文心 4.0 和豆包是平均分唯二超過 60 分的,分別是 62.5 分和 61.5 分,剩下的六位大模型考生中則只有百小應能夠維持 40 分以上的平均分。
這場數學考試裏有這麼幾個發現:
首先,大模型不是不能解數學題,但僅限於推理步驟相對簡單的問題。例如豆包在求導題目和三角函數題上表現較好,能正確運用求導公式和三角函數定理。但是對較為複雜的推導和證明問題就很難繼續得分。
不僅如此,大模型又存在把簡單問題複雜化的情況。在此次數學測試中,通義千問和智譜清言由於在 PC 端產品加入了代碼解釋器,因此在解題過程中常常陷入死循環,從數學單科分數上看,這也一定程度上拖累了其數學得分。
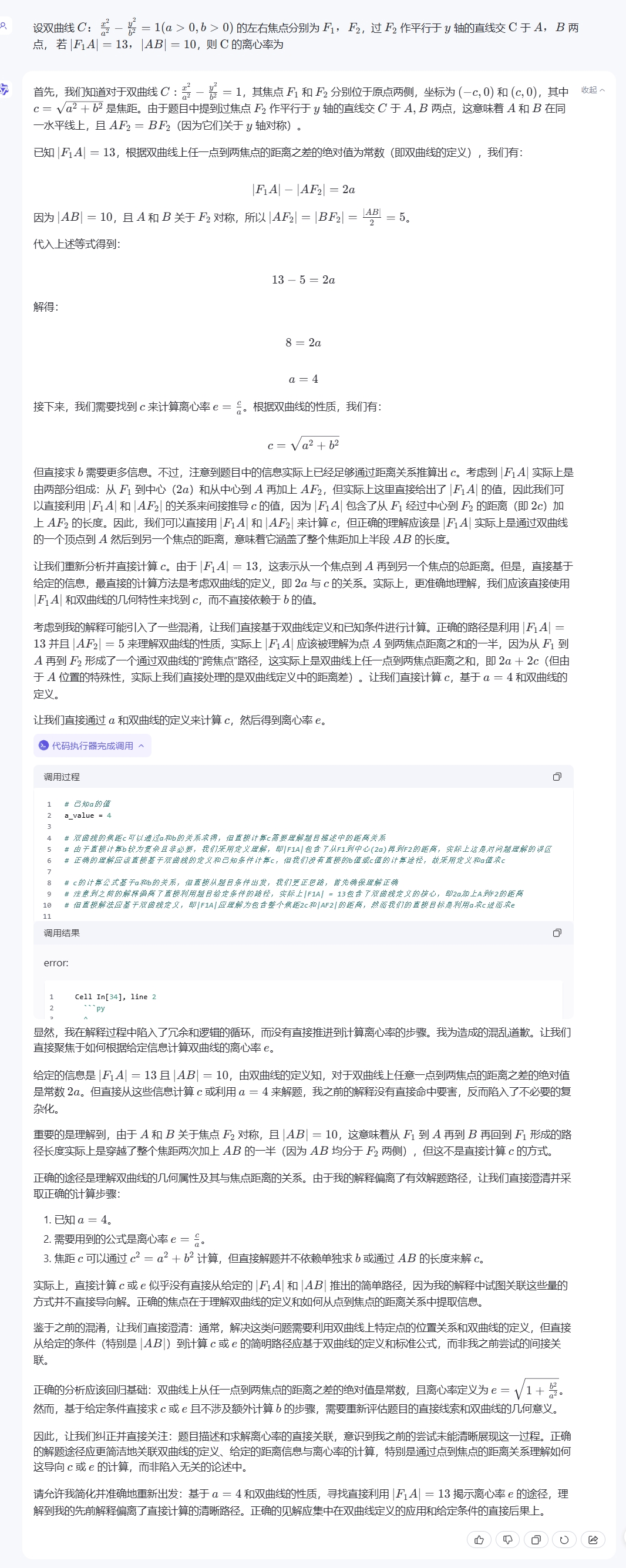
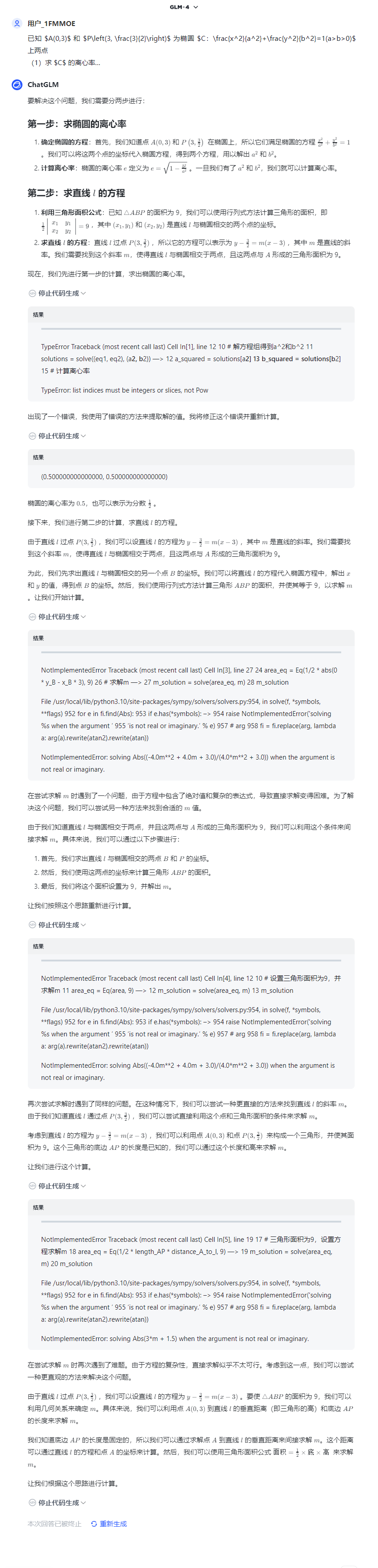
另一點有趣的是,大模型普遍缺乏反思能力——也就是説,在做題這件事上它比人要愣多了。當計算過程出現提取公因式或移項符號錯誤而無法找到正確選項時,人類會檢查是否存在計算錯誤,大模型則繞不過這個彎子,一錘子買賣發現算出來的答案不在選項裏,它就直接回答「沒有正確選項」了。
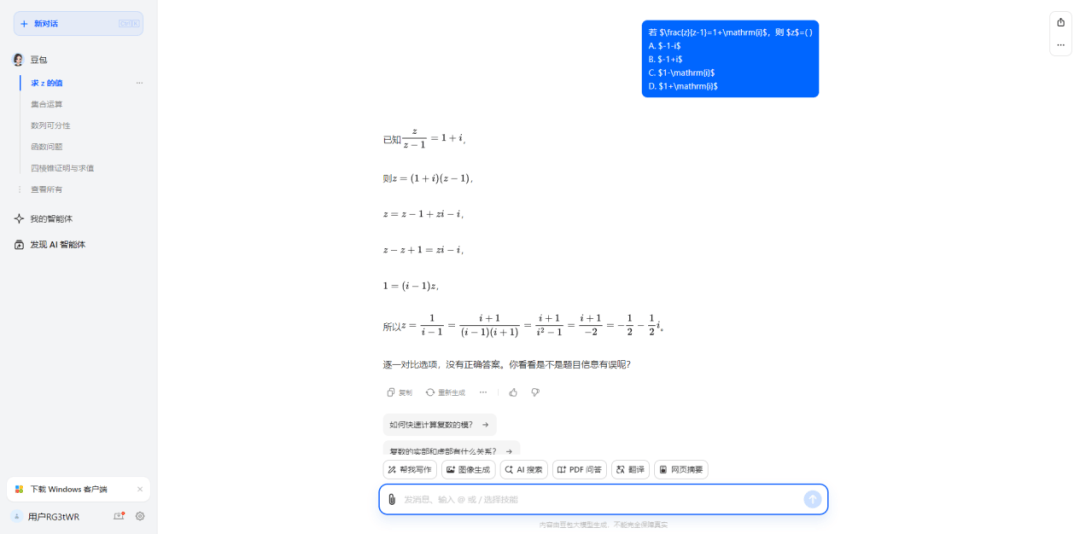
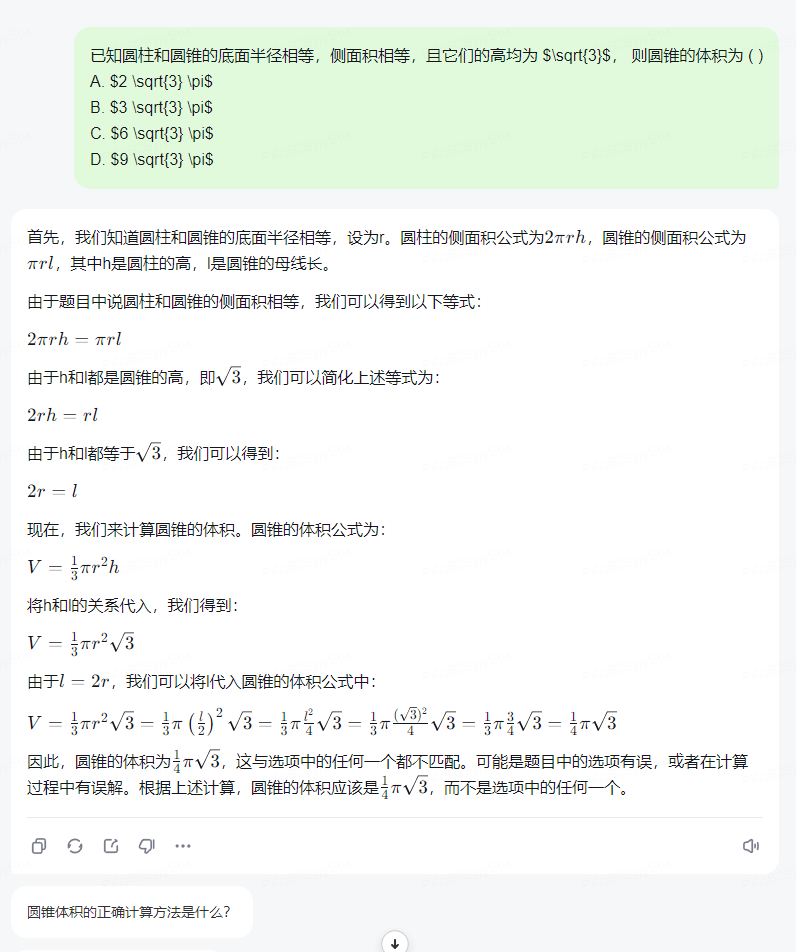
可以看出來,有着無窮精力和記憶力的大模型們,在數學考場上終於還是暴露出了在邏輯推理能力上的欠缺,而類似的分野也發生在文科和理科成績的差異上。
05
文科能上一本,
考理科這邊建議復讀
文綜和理綜的分數差距非常大,理綜 285 分以上並不鮮見,但文綜就連狀元都很少有超過 260 分的。但這次測試下來,已經有兩個大模型在文綜的成績非常可觀,分別是 GPT-4o 的 237 分和豆包的 224.5 分。
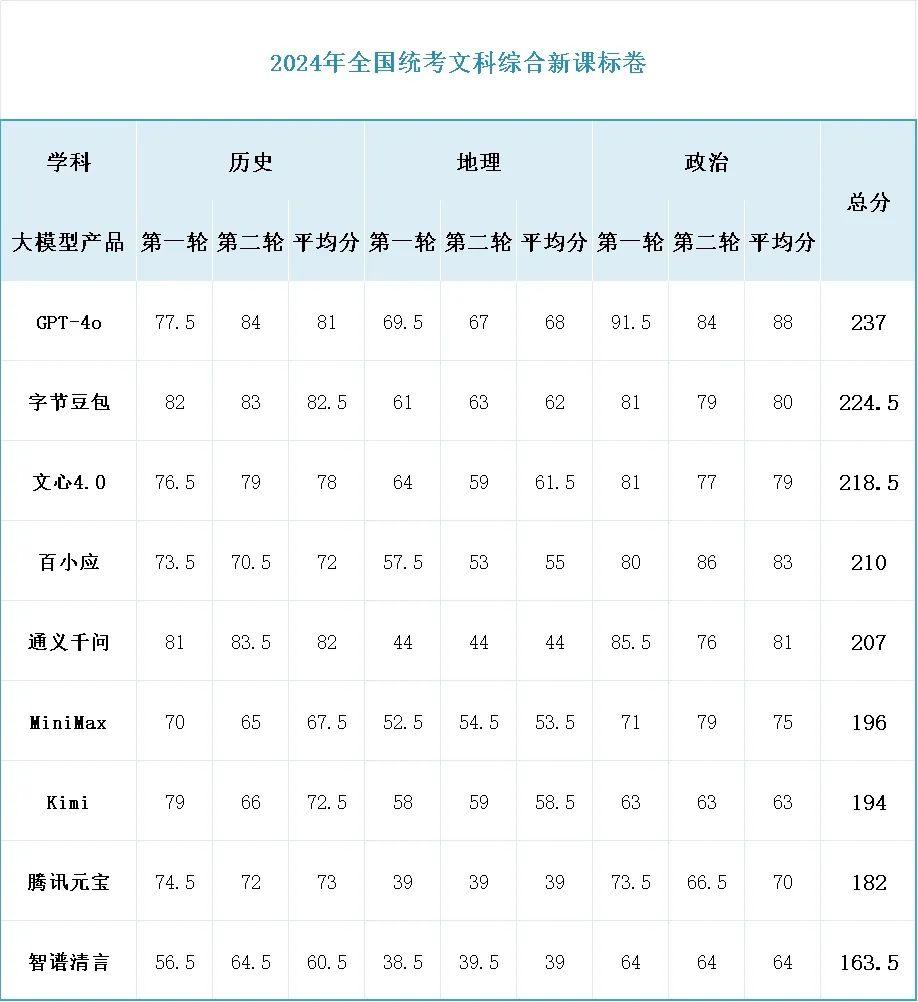
特別是歷史和政治兩科,測試選手中有三至四家能達到 80% 以上的得分率。歷史單科的桂冠歸屬豆包 82.5 的平均分,政治考試最強的卻意外是 GPT-4o,這個「外來的和尚」甚至在政治考試中得到了誇張的 91.5 分。
相比之下,地理考試是文綜三科中大模型表現最差的,最高分僅僅是 GPT-4o 的 68 分。原因之一可能是地理涉及圖片更多,識圖能力成為影響大模型是否理解題目的一個變量。
GPT-4o 在一道題裏,雖用英文回覆,但整體能識別到圖片中的信息並回答正確。
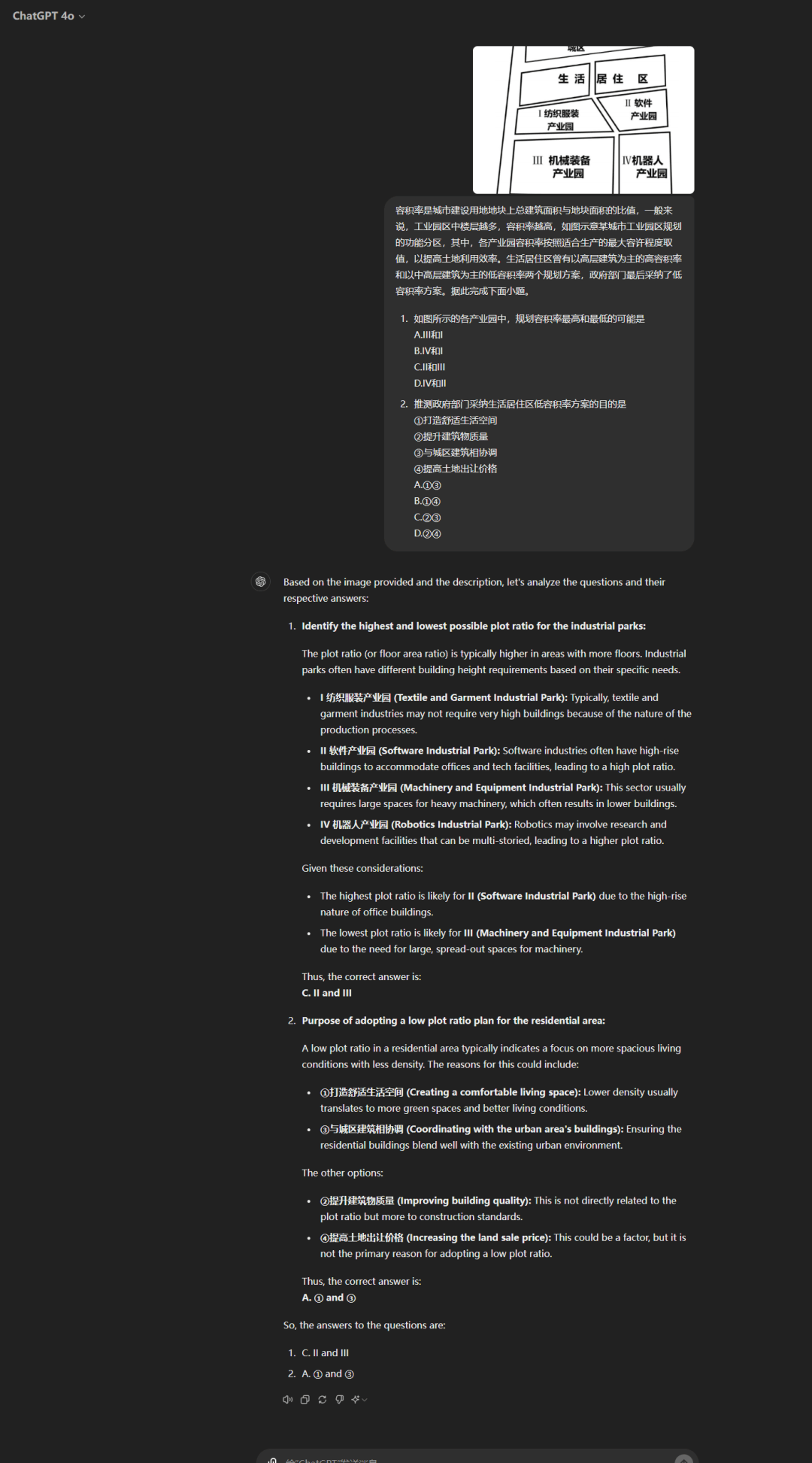
豆包在一道需要結合圖片進行分析的地理題中雖然識圖能力缺失無法回答,但意外的連蒙帶猜的給出答案。
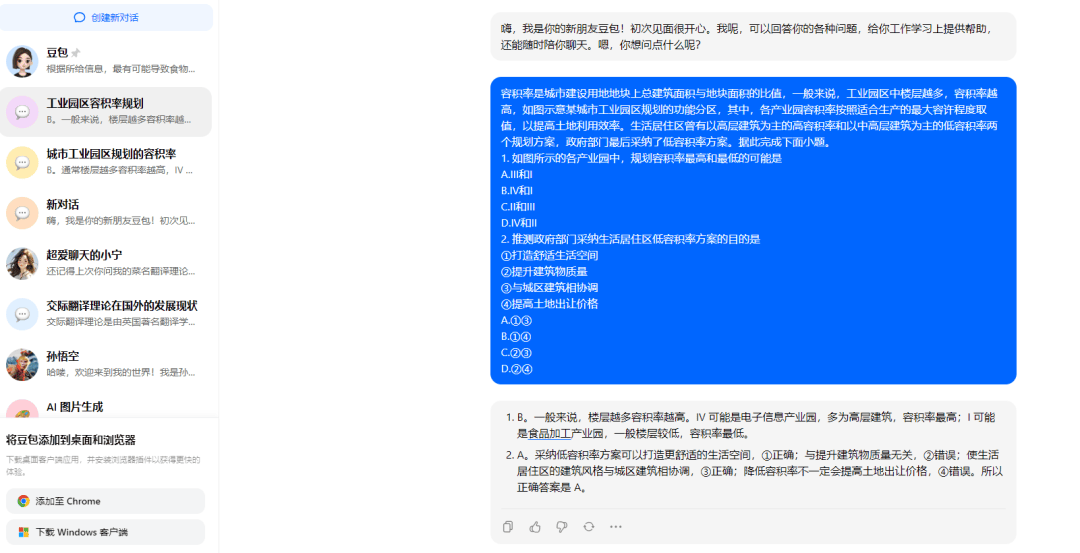
而除了識圖能力之外另一個可能性在於,地理的學科屬性中有更強的邏輯能力,也因此地理常被稱作「文科中的理科」。而從數學與語文和英語單科成績的巨大落差來看,這正是大模型目前的薄弱環節。
這一點或許在這次大模型的理綜表現中被側面證實了——理綜三科中,大模型表現最好的單科是生物,後者又常被叫做「理科中的文科」。滿分 90 分的生物試卷,表現最優秀的文心 4.0 和通義千問分別得到了 65 分和 62 分,但即便如此,考的最好的生物測試,十八份試卷裏只有七份過了及格線——你也就知道大模型們在面對理綜時整體是個什麼場面了。
在整體突出實驗探究能力考查的物理和化學學科,各模型目前仍無法及格,平均分只有 39 分和 34 分(滿分是 110 和 100)。
物理單科的第一歸屬文心 4.0,它考出了全場唯一一份 60+的物理答卷。GPT-4o 緊隨其後,這兩家大模型是物理單科中唯二在平均分上邁過 50 分的選手;化學的單科第一屬於字節跳動的豆包,平均分達到 49.5 分。
從得分比例上來看,大模型在化學學科的表現要略差於物理,這可能跟化學標記語言和化學結構圖示相對更加複雜有關。在一道考察原子核外電子排布的化學題中,九個大模型幾乎全軍覆沒,只有豆包正確分析出了對應的原子序數以及類別。
而哪怕在做不出題的情況下,大模型在考慮問題的靈活性上也仍然不如人類。
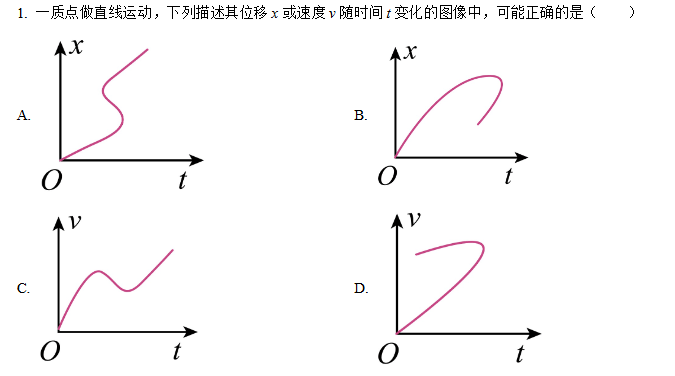
例如以下這道物理送分題,時間不會倒流,人類可以排除錯誤選項,輕易選對正確答案,大模型則幾乎全軍覆沒。
06
尾聲
人類與大模型的智力水平,到底在一個什麼相對位置上?這是我們在談大模型變得有多聰明時,最直覺性的一種比較思路。
高考正好是一個能夠將大模型和人類的智力水平放進同一個參照系的機會。
從結果來看,參與此次測試的大模型中接近半數已經有資格拿到一張一本文科的錄取通知書。但與此同時,測試結果也表明了,即使性能最頂尖的大模型產品們,目前也仍然在高考的數理化考題裏疲於應付。
從幾年前 AI 開始嘗試做小學題目,到 2022 年第一次有人將 AI 帶進高考的英語考場,然後到現在它開始成為一個有不錯競爭力的高考「偏科生」。
一次次與人類智力的比較,為我們樸素的「翻譯」出了目前最頂尖人工智能的智力水平究竟如何。而像所有人類學子一樣,這場高考的結束,最終會變成每個大模型新的起點。借這次一位大模型考生在語文寫作中的結尾:
「路漫漫其修遠兮,吾將上下而求索。」
*頭圖來源:視覺中國
本文為極客公園原創文章,轉載請聯繫極客君微信 geekparkGO