OpenAI斷供,中國企業:謝邀,已登頂_風聞
酷玩实验室-酷玩实验室官方账号-昨天 23:13
OpenAI斷供了。
自7月9日起,包括中國大陸、中國香港、俄羅斯、朝鮮、伊朗等國家和地區都不能再接入他們的API。

一看名單,全是美利堅的制裁對象,這當然是一個政治問題。
不過大家要是對OpenAI這家公司持續關注的話,這個決定一點也不奇怪。
不久前,OpenAI的CEO奧特曼就解散了安全團隊——超級對齊,這個由OpenAI曾經的首席科學家Ilya Sutskever帶的團隊。

Ilya隨即出走。很快,奧特曼就組建了一個新的安全團隊,而這個團隊的領導人是美國國安局前局長保羅·中曾根(Paul M. Nakasone)。

當OpenAI變成CloseAI,會對整個行業帶來什麼影響呢?
我們先看看這一波“斷供”可能會帶來什麼吧。
01
所謂的斷供“API”,這裏的API指的是“應用程序編程接口”。
你可以把API通俗地理解為餐廳的菜單。你可以用它來點菜,但你並不知道菜是怎麼做出來的。
還記得ChatGPT剛出來那陣兒,湧現出來無數AI公司麼。它們就是顧客,炒菜的是OpenAI,然後它們再把炒好的菜包裝一下,賣給餐廳外的我們。
所以本質上它們就是套殼公司,真正生產的是OpenAI。
可想而知,斷供對這些公司來説無異於釜底抽薪,把吃飯的傢伙給收走了。
但換個角度想,OpenAI這個AI行業內巨無霸居然主動讓出市場,有錢不賺是傻蛋。
這不,國內各路高手立馬就像餓虎撲食一樣衝上來搶這潑天富貴,各種**“搬家計劃”**紛紛出爐,服務不要太周到。
比如阿里的通義千問,除了提供專屬的遷移服務外,主力模型調用API的價格更是隻有GPT-4的1/50。這還是在通義千問跟GPT-4實力相當的情況下的價格。
其他包括智譜、訊飛、百度、百川等都提供了相當優惠的價格。
所以,現在擺在他們面前的已經不是to be or not to be的生死問題,而是如何從一眾“備胎”中挑最好的那個。
02
什麼樣的模型才是好模型呢?
正如歐洲歷史上最強的男人拿破崙所説,不想拿第一的模型不是好模型。

就像學生通過各個科目的考試比成績,大模型的能力也是看做題的成績。
學生有語數外理綜文綜的項目,大模型有推理能力、數學能力、編程能力、語言能力、多模態能力等多種項目。
比如最常用的MMLU數據集,內容涵蓋了STEM、人文、社科等57個學科,就是常用來測試模型知識和推理能力的數據集。
此外還有專考中文的C-Eval、考奧數的MATH(好會取名字)等等。
自然,每家模型都會爭取考個好成績。但就像學生考試一樣,有的人實力強大,有的人有自己的辦法。
截至2024年6月28日,C-Eval榜單上,前20名全是我國的大模型,GPT-4位於21位。
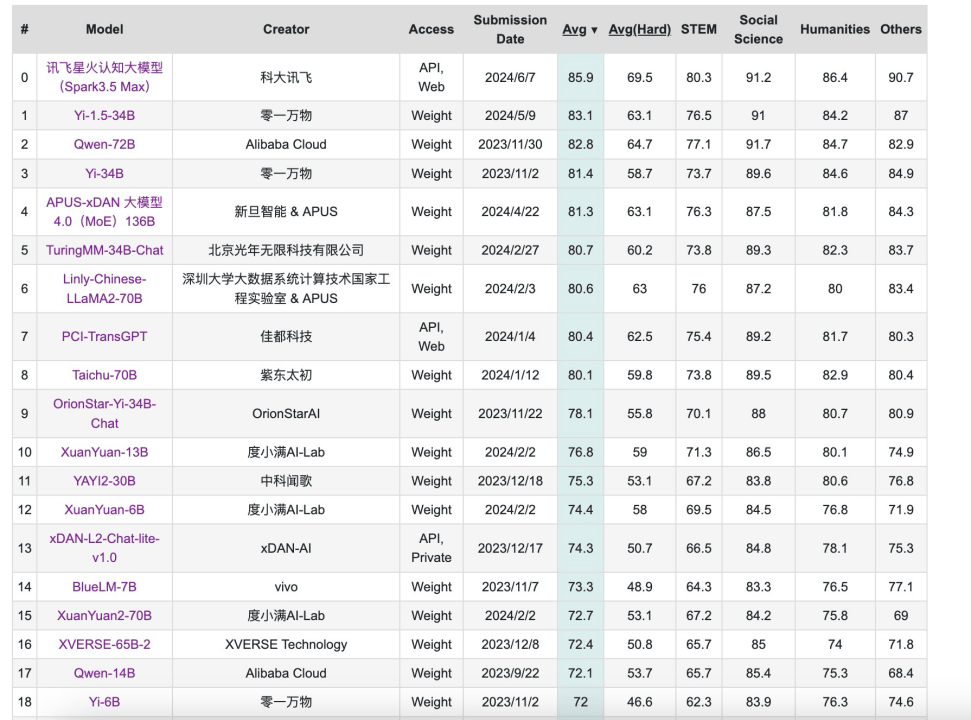
這並不符合我的實際體驗,雖然GPT-4的能力並沒有像以前一樣碾壓了,但也不至於排到21名啊。可以説,這份榜單在某種程度上失真了。
造成這種現象的原因有很多。
首先是隨着大模型的不斷升級,一些題目變得相對簡單了。就像以前大家都是小學生,考初中的題目,大家分都不高。但經過一年多的學習,大家的水平上升到了高中生,再去做這些題,都能得個90分以上,那麼這個試題就不能很好地區分大家的水平了。
其次,**閉卷變開卷。**雖然這些考題都不是公開數據集,但我每天就擱那考試,一連考幾十天。那考試就跟刷題庫一樣了,考試的題目也逐漸公開。後來的大模型們直接用這些公開的題目去訓練,那再去考的時候,就相當於開卷考試了。就算是難如數學競賽,出成績也不是不可能的。
當然了,考題本身的質量也很重要。
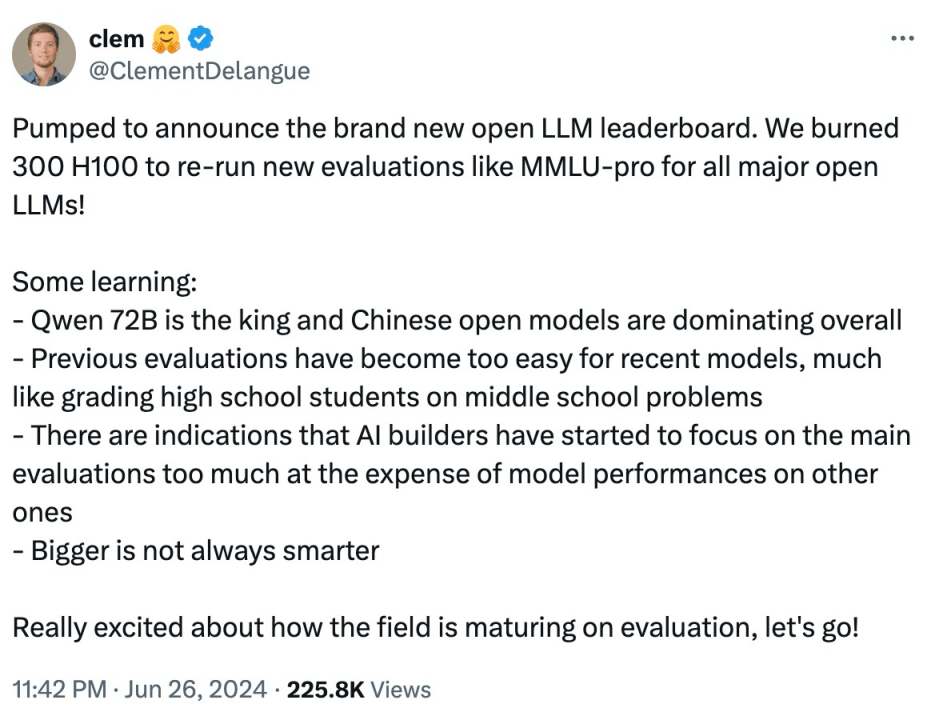
這是著名的開源社區Huggingface發佈的榜單Open LLM Leaderboard的最高成績。可以看到,從2023年9月到2024年5月,大模型在各個科目取得的成績都不斷地提高,都接近虛線,也就是人類水平。
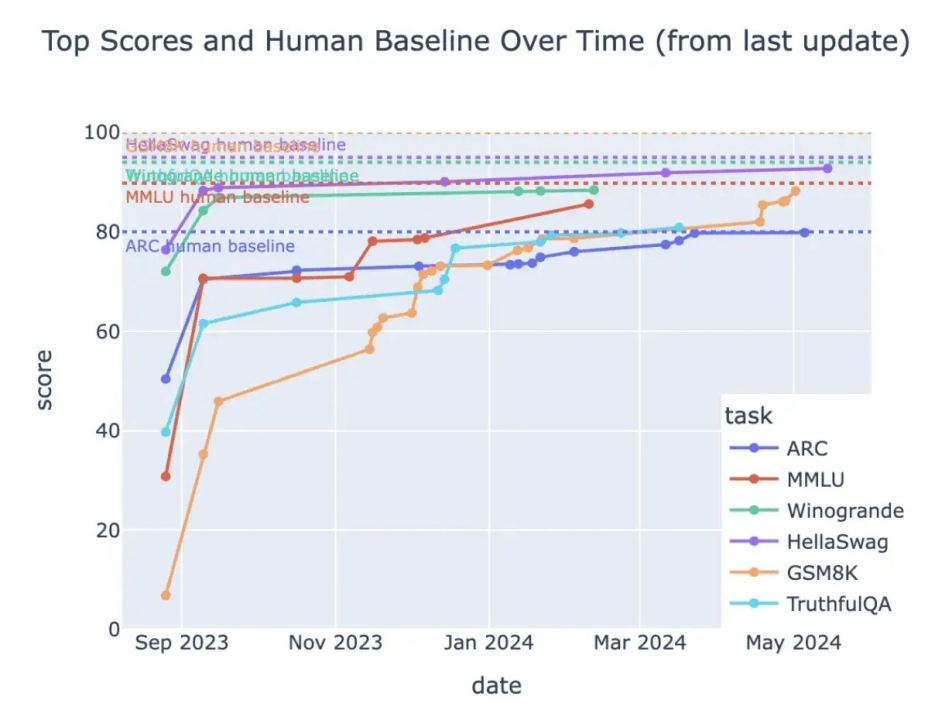
當然這個成績並不意味着大模型已經跟人一樣了,而是説明了這份卷子已經被做爛了。
所以,Huggingface在6月推出了一套新試題,升級版的Open LLM Leaderboard v2。

這套試題比此前版本難度高了不少,比如GPQA數據裏面全是研究生級別的知識,且專門找了生物、物理、化學等領域的博士生來出題。
客觀講,這一波很有誠意,沒給那些刷榜的大模型留下什麼空子鑽。
各考生做這套卷子的成績很快出來,榜單很出乎意料:
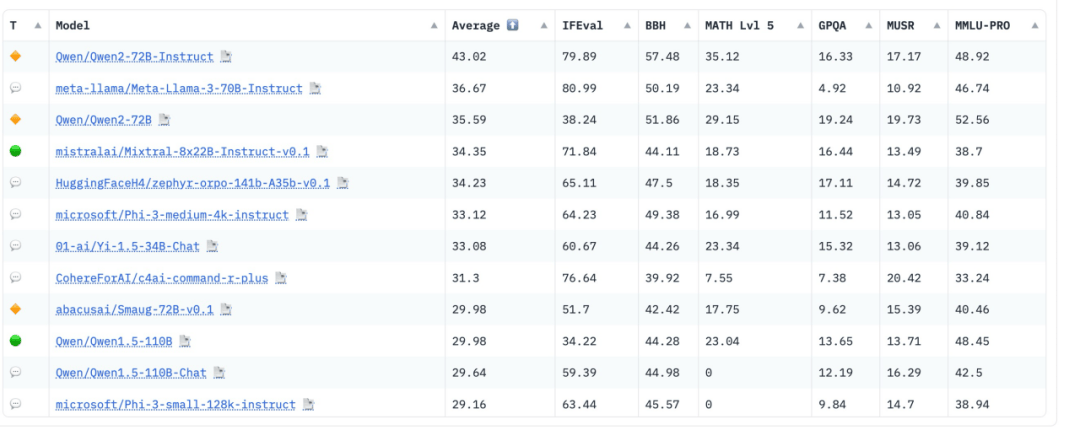
裏面有不少老熟人,當紅炸子雞,“法國的OpenAI”Mistral、“史上最強開源大模型”Llama3以及打敗了Llama3的通義千問Qwen2-72B(720億參數)。
在這家法國榜單上看到咱國產的通義千問,屬實是有點驚訝。
我又去看了詳細的成績單,Qwen2的數學(MATH)、專業知識(GPQA)和長上下文推理(MuSR)是優勢學科,尤其是數學,比第二高了6分。哦不好意思,第二名是沒有經過微調的Qwen2。
這份成績得到了Huggingface CEO的稱讚:
我去看了另一個榜單LiveBench AI,這是在圖靈獎得主、AI三巨頭之一的楊立昆(Yann LeCun)主導的一個大模型測評基準。
Qwen2-72B排名第8。
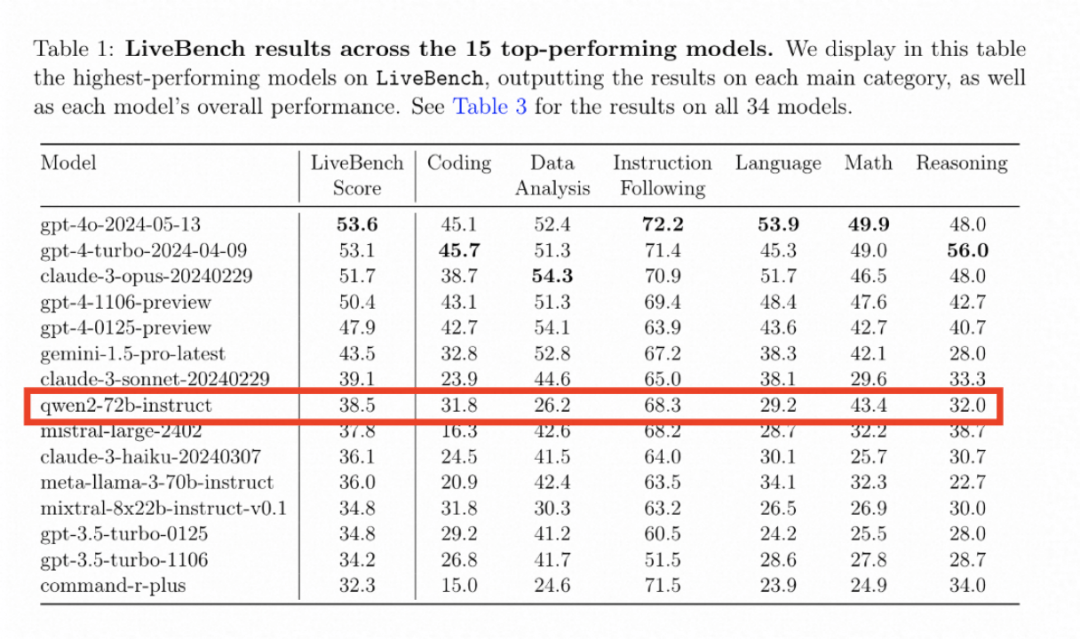
但這是包括了所有閉源模型的總榜單,Qwen2-72B是前十中唯一一個開源模型。
還有其他的榜單,Qwen2基本都是開源中的霸主,在這裏就不多列了。
這説明了Qwen2的做題能力很強。但它到底是做題家還是真的實力強大呢?這需要一線開發者的測試。
紅迪(reddit)裏的開發者測試後,給出了肯定的評價:

初次測試很不錯,有一個題目其他模型都錯了,只有Qwen7B對了
另一個意大利的開發者甚至説“太強了以至於不像真的”:
我又去看了看推特,開發者們測試後也都非常認可Qwen2的能力,比如這位斯坦福的計算機副教授Percy Liang:
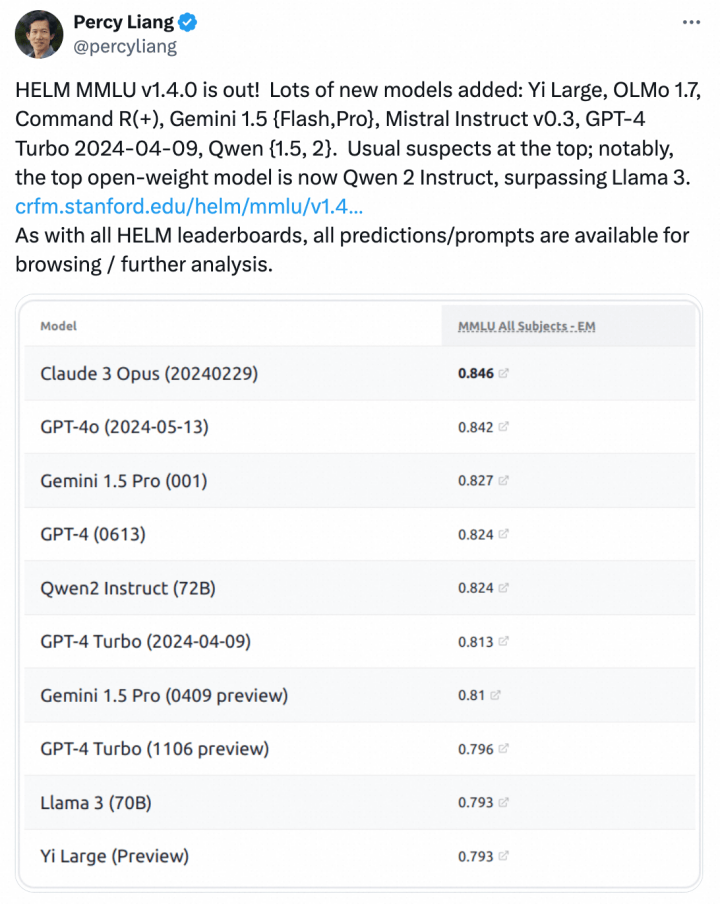
至此,我覺得Qwen2的實力已經沒什麼可質疑的了。
03
開源這條賽道上,競爭從來都不比閉源小。
前有法國獨角獸Mistral直接免費甩出自家大模型 Mistral 7B 的磁力下載鏈接。
開發者們下下來一跑,發現竟然性能並不比 130 億參數的 Llama 2 弱多少,而且微調一下,用一張顯卡上就能跑。
後來他們又推出了更大參數量的 Mixtral 8x7B,性能追平了Llama2和ChatGPT3.5。
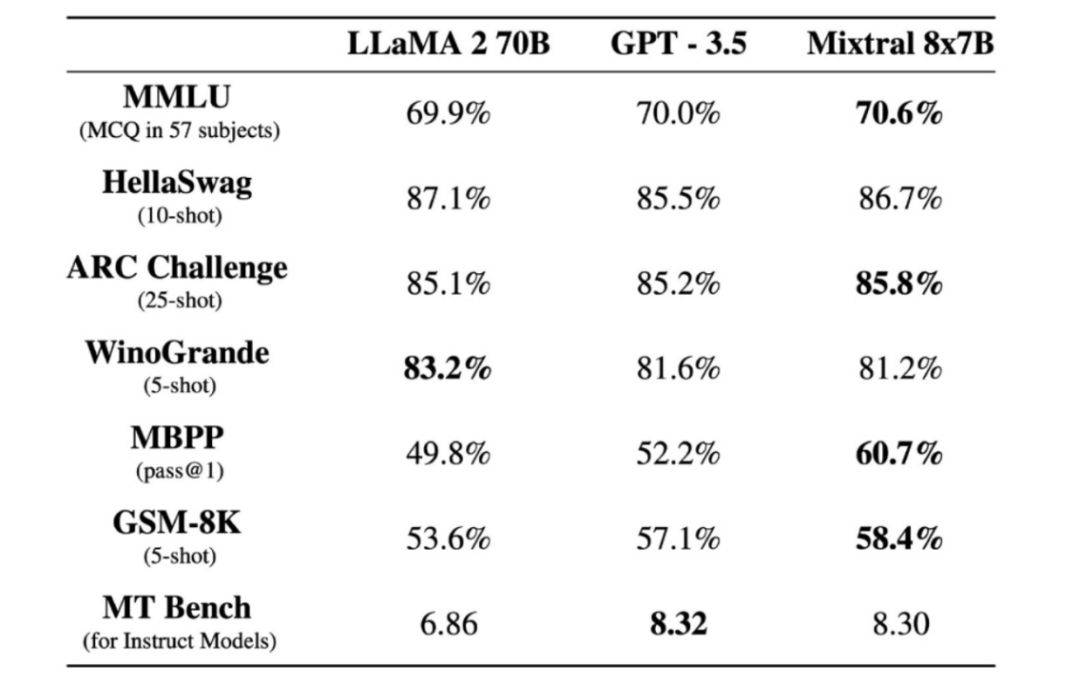
這讓Mistral先後融資超11億刀,數錢數到手軟。
而兩個月前,深耕開源的Meta正式發佈了Llama3 8B和70B,這個據估計花費了1500萬美元來訓練的開源模型,重新奪回鐵王座。

Meta官方認證為**“迄今為止最強的開源大模型”**。
當時外界有一種聲音説:“只有GPT-5能壓住Llama3了。”
但GPT-5沒來,Qwen2先來了,驚不驚喜,意不意外?

其實,阿里雲是國內首個做開源的大型科技企業。2023年8月,他們就開源了Qwen7B。
到現在,他們一共開源了Qwen-VL、Qwen-14B、Qwen-72B、Qwen-1.8B、Qwen-Audio、Qwen1.5的8款模型和Qwen2系列的5個模型,參數從5000萬到720億,可謂是全家桶了。
看到這裏,可能有人會問,阿里雲還有自己的閉源模型,是在開源上遲疑了嗎?
但Qwen2這次全球第一的“出人頭地”,證明了阿里雲做開源是認真的!
隨着GPT-5發佈時間一而再再而三地延後,現在的消息已經推遲到明年年底了,大概率OpenAI還沒找到辦法讓GPT-5在GPT-4的基礎上大幅進步。
而與此同時,以Qwen2為代表的開源模型,表現正不斷地逼近閉源模型之首GPT-4。
將OpenAI變為CloseAI,從非盈利變為盈利的Sam Altman,在看到Qwen2的表現時,是否心中會生出一絲後悔呢?