9天用户暴漲80萬,躋身美國社交APPTop5!這款反AI產品火了_風聞
乌鸦智能说-2小时前
AI浪潮滾滾向前,眾生皆被裹挾。
今年6月,Meta更新了隱私權政策。根據新版隱私權政策,用户必須同意將自己發佈的內容給Meta的AI模型訓練,否則將被禁止使用Facebook和Ins等產品。
這個政策徹底點燃了藝術家們的反AI情緒。他們紛紛離開Ins,“逃亡”到一個叫Cara的地方。
從6月1日到6月9日,在未進行任何廣告投放的情況下,Cara用户量就從4萬增至80萬,一躍成為美國社交應用榜Top5,超過了X、Reddit、Discord等,一時間風頭無兩。要知道,Ins平均每週的增長用户約為135萬,這意味着Cara的增量已經接近Ins的60%。
 藝術家們之所以看重Cara,就是因為這個平台足夠“反AI”:Cara不允許用户發佈AI生成的圖像,也不允許科技公司隨意收集平台的信息,還會給藝術家們提供“反AI”的保護工具。
藝術家們之所以看重Cara,就是因為這個平台足夠“反AI”:Cara不允許用户發佈AI生成的圖像,也不允許科技公司隨意收集平台的信息,還會給藝術家們提供“反AI”的保護工具。
從Ins到Cara,並不是一次普通的平台間用户遷移,這背後反映了AI時代平台與用户之間的矛盾正在加劇:
當數據越來越值錢,用户正在試圖從平台手中重新拿回數據控制權。
/ 01 / 給AI“下毒”,反AI平台Cara火了
在藝術領域,藝術家與AI的矛盾由來已久。2022年,MidJourney在美國科羅拉多州博覽會藝術比賽中憑藉AI畫作拿下第一名。
自那一刻起,在很多人眼裏,藝術失守幾乎只是時間問題。搶飯碗就算了,畢竟藝術家管不着。但現在AI公司們變本加厲了。
今年6月,Meta更新了隱私權政策。根據新版隱私權政策,除了用户與好友之間的私密消息內容外,其他數據及衍生數據均會被用於模型訓練。這是通知,不是商量,用户沒有手動勾選其他選項的可能。
這下藝術家真的怒了。飯碗都要沒了,平台還要拿我辛辛苦苦創作的成果去訓練AI,這誰能答應?
6月11日,普利策獎得主、攝影記者丹尼爾·埃特(Daniel Etter)發佈了一則題為“選擇退出——致Meta的公開信”的公告,強烈反對Meta公司使用旗下平台上的公開照片來訓練其人工智能產品。截至目前,已有超過200位攝影師、攝影機構和編輯簽署了這封公開信。
離開Meta後,他們很快找到了一個沒有AI的地方——Cara。在很短的時間內,大量用户紛紛湧入Cara。除了移動端下載量暴漲,網站流量也出現劇增。據similarweb數據,6月前Cara的網站訪問量屈指可數,到了6月猛增到了920萬。
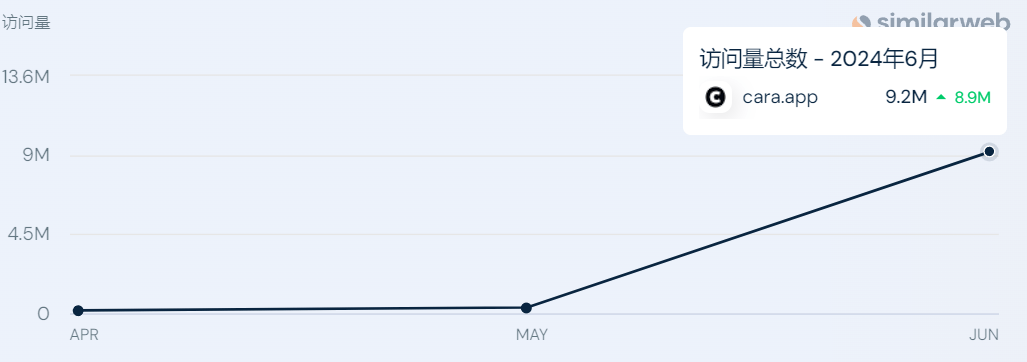 ▲Cara的網站訪問數據,來源:similarweb
▲Cara的網站訪問數據,來源:similarweb
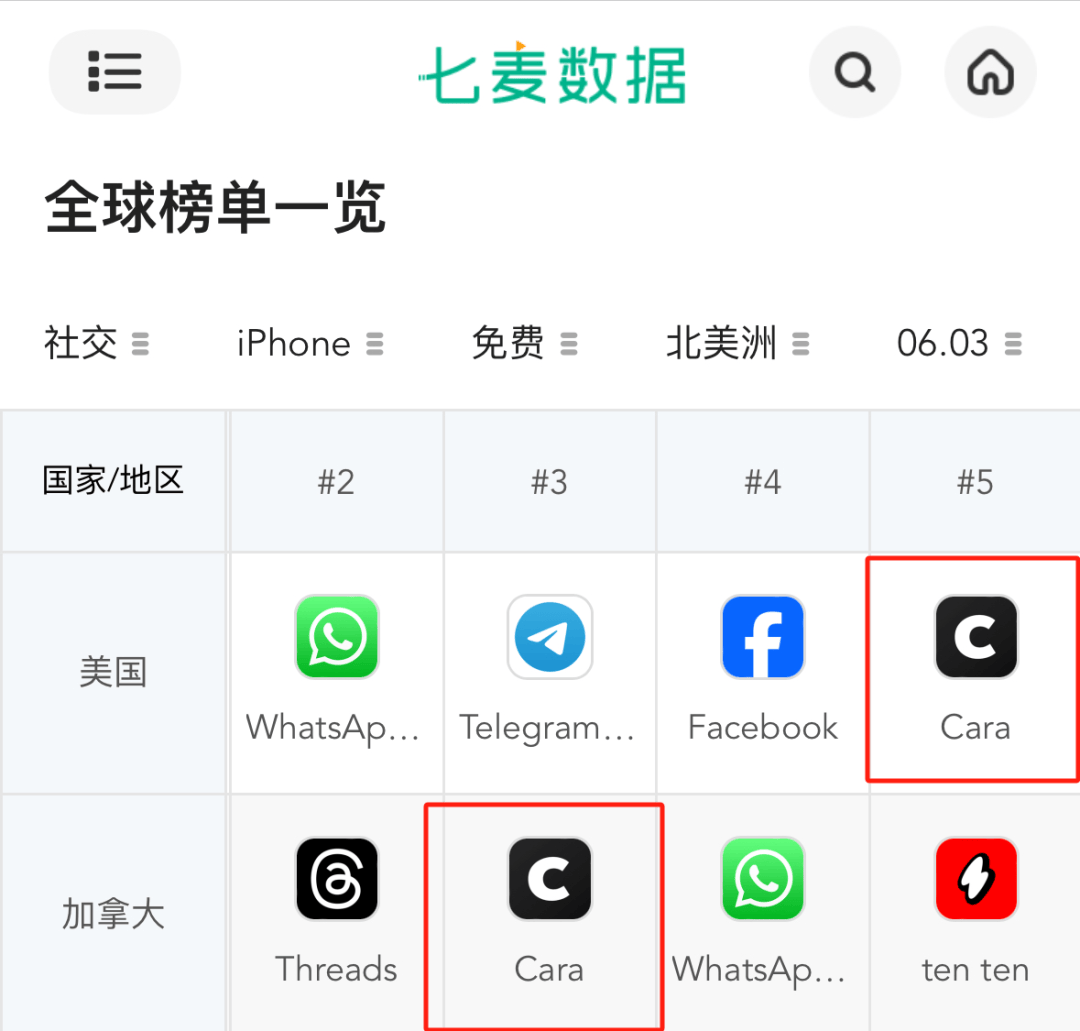
據七麥數據,Cara在5月27日之前還未進入應用任何榜單。到了6月3號,Cara已經進入了各國社交應用榜前五:在美國排名第5,在英國、澳大利亞、新西蘭、挪威、瑞典排名第4,在西班牙、加拿大排名第3。
Cara吸引藝術家的原因也很簡單,就是在身上打滿“反AI”標籤。平台不僅專注於建立非AI圖片的社區,同時承諾不會將用户內容用於AI訓練。
Cara創始人Jingna Zhang(張晶娜)本身就是一名藝術創意從業者兼攝影師,對版權保護的立場堅定,曾參與多起作品維權,其中包括面向Stable Diffusion、Google以及其他AI生圖工具的集體訴訟。
更重要的是,Cara還會給藝術家們提供“反AI”的保護工具。
當藝術家在Cara平台發佈作品時,Ta可以勾選“我要保護這張圖”,網站會給作品“上一層釉”,而這個操作並不會影響畫作的肉眼效果。而這道工序背後暗含着Cara的一個秘密武器——Glaze技術。
 ▲在Cara“上釉”前後的圖片對比,來源:Jingna Zhang
▲在Cara“上釉”前後的圖片對比,來源:Jingna Zhang
Glaze通過向圖像添加不可見的噪聲來保護藝術家,使AI系統感知到與原始風格不同的風格,從而防止AI模仿藝術家的獨特風格。比如,Glaze會對梵高的畫作進行微調,導致AI模型無法準確學習梵高的繪畫風格,從而實現對原作藝術風格的保護。
這樣的保護機制之所以成立,原因是人類與AI看畫的方式很不一樣。
人類通常是通過觀察線條、色彩等視覺元素來感知藝術作品,而AI是基於純數學的方式進行分析。人類在觀看時不會關注到每一個像素的細節,但計算機會讀取每個像素。即使是肉眼看來微小的改動,也可能對AI的理解造成顯著影響。
根據Glaze技術團隊的説法,科技公司要去除Glaze的效果非常困難,這個過程的難度相當於,毒藥已經在一杯水裏溶解,現在你要把毒性從這杯毒水裏完全去除。
固然,Cara能夠用魔法打敗魔法,但依然解決不了根本問題:在AI時代,用户數據的控制權到底歸誰?
/ 02 / 當數據成為一種生意,控制權爭奪戰正在打響
在互聯網大廠,修改隱私條款的情況並不是個例。
過去一年裏,包括Adobe、谷歌、Zoom和X等大公司都紛紛更新其服務條款或隱私政策。目的只有一個,就是允許自己使用用户數據來訓練AI模型。
去年7月,谷歌對其隱私政策進行了修改,增加了“公共信息可用於訓練其AI聊天機器人,以及谷歌翻譯、Bard等產品和功能”的描述,這一動作引發爭議。為了安撫用户,谷歌聲明稱,其隱私政策的變更只是澄清了“像Bard(現為Gemini)這樣的新服務也包括在內。”
6月初,Adobe就在其隱私政策中加入了一句關於內容訪問權限的更新,激怒了不少創作者。這個條款影響了Adobe創意雲套件的超過2000萬用户,一些用户認為Adobe正在收集用户的藝術作品,用於訓練AI模型。
 來源:Adobe
來源:Adobe
不止硅谷,國內類似的事件也時有發生。
2023年3月,網易旗下LOFTERAI繪畫功能被質疑使用用户作品進行AI訓練,導致不少原創畫師逃到了其他平台。隨後,LOFTER下架相關產品,併發布官方致歉信。
2023年8月,多位插畫師發佈停更通知,他們質疑小紅書旗下AI繪畫產品TriK未經允許,將其繪畫作品“投餵”給AI訓練,引發版權爭議。
這些背後凸顯了一個關鍵問題——當數據價值越來越大,平台選擇不斷釋放數據價值,而用户正試圖重新拿回數據控制權。
在互聯網時代,用户數據的討論主要集中在安全性。但到了AI時代,這事的性質徹底變了。數據不僅成了重要的生產資源,甚至買賣數據成為了媒體和社交平台一種的商業模式。
作為全世界最大的UGC平台之一,Reddit擁有超過10億個帖子和160億條橫跨各個主題的評論,無疑是數據採集的金礦。
根據Reddit財報披露,公司預計今年從LLM開發商授權數據的交易中獲得6600萬美元收入,佔年收入的6%。隨着與OpenAI達成新的數據授權協議,這一數字還有不小增長空間。
此前,蘋果公司也曾向新聞出版商提供5000萬美元的報價,以獲取其內容訓練LLM。一些出版商也已與OpenAI等公司簽約,價格也很可觀,按照每張圖片1-2美元、每段短視頻2-4美元、每字0.001美元的定價向其出售內容。
當數據買賣逐漸成為平台重要的收入來源時,作為數據內容的重要生產方,用户與平台之間仍然缺乏一個合理的分配機制。
更令人頭疼的問題是,由於監管的滯後性,傳統著作權法中所適用的侵權判定原則,並不適用於平台AI的侵權問題。
談到如何判定AI侵權事件時,律師事務所從業者甲片告訴烏鴉君,著作權本意是維護作者的獨創性,而AI作為大數據的產物,利用百家之所長將各種要素堆砌在一起形成不同風格的作品,由於要素涉及面廣,很容易直接“複製黏貼”其他作者獨到的地方。
甲片補充説,作為新興產物,AI相關法律法規並不完善,如將以前判定抄襲方式同樣應用到AI上恐怕會造成認定困難。在實務中,判定AI侵權的難點在於舉證,被侵權人很難用完整的證據鏈證明AI存在抄襲行為,最終導致不構成侵權等不利後果。
也就是説,平台的用户和創作者幾乎沒有任何反制的手段。從這個角度看,藝術家們紛紛“逃離” Ins,何嘗不是拿回數據控制權的一種選擇。
從長遠看,只要一天沒有建立合理的利益分配機制,平台與用户之間數據控制權的爭奪就永遠不會結束。這次藝術家與Meta旗下平台發生衝突,Cara爆火,一切更像是一個開始。
