小扎新開源的Llama3.1,要帶着套殼大模型追平GPT-4o?_風聞
差评XPIN-差评官方账号-用知识和观点Debug the world!1小时前
本文原創於微信公眾號:差評 作者:世超
三個月過去了,當初的 “開源落後論” 再一次被打臉。
 而打臉的人,仍然是上次那位,元宇宙倡導者,前半職業拳擊手,潛伏在硅谷的純正蜥蜴人,扎克伯格。
而打臉的人,仍然是上次那位,元宇宙倡導者,前半職業拳擊手,潛伏在硅谷的純正蜥蜴人,扎克伯格。

好吧不賣關子了,簡單來説就是,開源 AI 界扛把子 Meta AI ,昨晚更新他們最新最強的大模型, Llama3.1 。
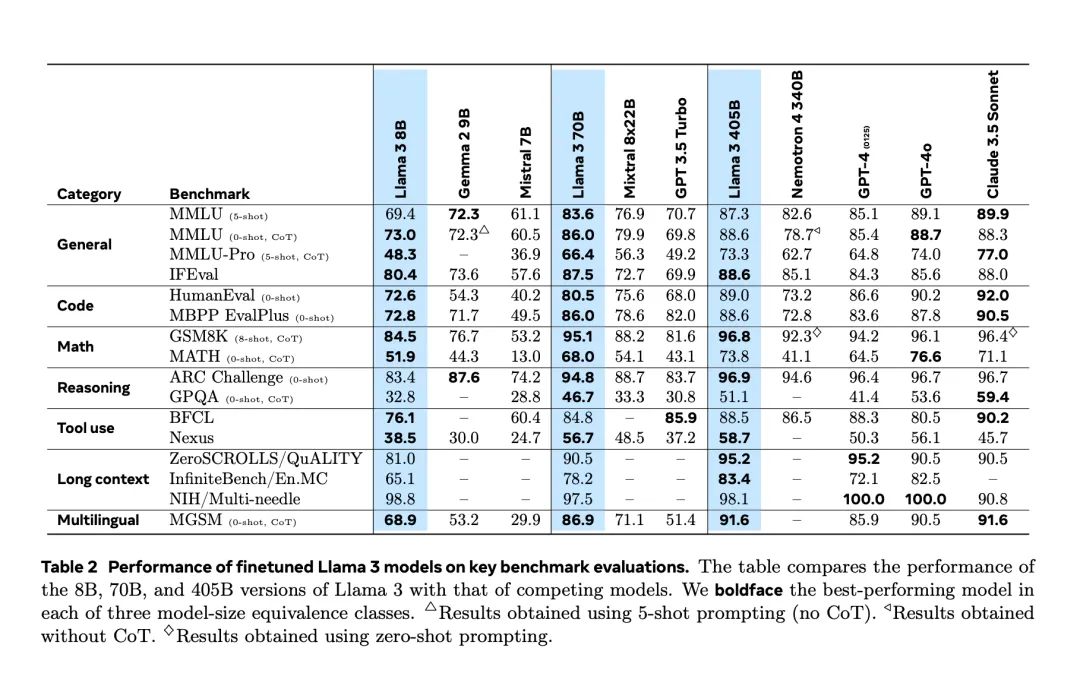
 這玩意跟上次 Llama3 一樣也是三個版本,除了同參數量的 80 億和 700 億,這次最亮眼的是他們的超大杯,在老黃數萬顯卡的供應下,小扎的新模型用了足足 4050 億參數!
這玩意跟上次 Llama3 一樣也是三個版本,除了同參數量的 80 億和 700 億,這次最亮眼的是他們的超大杯,在老黃數萬顯卡的供應下,小扎的新模型用了足足 4050 億參數!
而它的性能,也號稱已經完全追上 ChatGPT4o 和 Claude3.5-Sonnet ,像長文本和數學這些方面甚至超過他倆。這回啊,是開源的勝利!
 硅谷的其他大佬也對這個模型相當看好,斯坦福大學計算機教授、谷歌 AI 負責人 Andrew Ng 感慨道, Meta 的這次更新,對所有人來説都是超讚的禮物。
硅谷的其他大佬也對這個模型相當看好,斯坦福大學計算機教授、谷歌 AI 負責人 Andrew Ng 感慨道, Meta 的這次更新,對所有人來説都是超讚的禮物。

 英偉達科學家, AI 實驗室負責人 Jim Fan 甚至認為,比肩 GPT-4 的力量已經發送到大家手中了,這是個歷史性時刻!
英偉達科學家, AI 實驗室負責人 Jim Fan 甚至認為,比肩 GPT-4 的力量已經發送到大家手中了,這是個歷史性時刻!
不少媒體也跟着炸裂,宣稱 AGI 之路近在眼前了,不過世超我還是先潑一盆冷水,勸大家先別急着狂熱了,因為人家 Meta AI 官方這次,也放出了Llama3.1 的詳細論文,足足 90 頁。
這個版本究竟改進了什麼地方,是不是真有吹的這麼神,那論文裏其實都寫上了。
 咱們也花了一個下午,研究了一番,發現這篇論文涵蓋了預處理、生成訓練、推理訓練、退火迭代、多模態評估等流程,但核心其實説的就是兩件事,一是大量的訓練,二是訓練裏做了些優化。
咱們也花了一個下午,研究了一番,發現這篇論文涵蓋了預處理、生成訓練、推理訓練、退火迭代、多模態評估等流程,但核心其實説的就是兩件事,一是大量的訓練,二是訓練裏做了些優化。

首先咱就説訓練這方面,他們就下了大功夫,做了算力和數據的擴充。
 畢竟人家用了 1.6 萬台 H100 跑了 3930 萬 GPU 小時(相當於單塊 GPU3930 萬個小時的計算量 )。運算規模比 Llama2 翻了 50 倍,還填了包括多種語言的 15 萬億 Tokens ,相當於 7500 億單詞進去,而上代版本只有 1.8 萬億 Tokens 。模型上下文窗口也從 8K 增加到 128K ,擴展了 16 倍。
畢竟人家用了 1.6 萬台 H100 跑了 3930 萬 GPU 小時(相當於單塊 GPU3930 萬個小時的計算量 )。運算規模比 Llama2 翻了 50 倍,還填了包括多種語言的 15 萬億 Tokens ,相當於 7500 億單詞進去,而上代版本只有 1.8 萬億 Tokens 。模型上下文窗口也從 8K 增加到 128K ,擴展了 16 倍。
數據和運算規模上去了,能力肯定也就上來了,突出一個力大磚飛。畢竟這麼多東西,要咱學大概率擺爛學不動,但人家 AI 是真學啊。
其次,除了填鴨式訓練,訓練內容裏的優化和微調也挺重要的,這也是他們能快速進步的另一個原因。比如説在剛開始處理訓練信息的時候,他們就用了一些算法,來清理重複內容和垃圾信息,提高訓練數據的質量。
 你可別説這操作不重要,上回某知名 AI 就在中文垃圾信息上翻車了,成了貽笑大方的典型。
你可別説這操作不重要,上回某知名 AI 就在中文垃圾信息上翻車了,成了貽笑大方的典型。
這裏他們描述了重複數據刪除和啓發式過濾兩個算法的步驟

而在模型結構上,為了照顧這麼大量的數據訓練, Meta 也做了不少改進,像是把訓練數據由 16 位精度降低到 8 位,這樣不但能節省儲存空間還方便計算,並且有利於在移動端部署。
 不過這個辦法別的廠家也不是沒想到,只不過降低精度有可能會增加誤差,導致大模型性能降低,而 Meta 在這個過程中則是通過 “ 行級量化 ” 等世超聽都沒聽過的算法,來拿捏這個誤差的度,儘量做到兩全其美。
不過這個辦法別的廠家也不是沒想到,只不過降低精度有可能會增加誤差,導致大模型性能降低,而 Meta 在這個過程中則是通過 “ 行級量化 ” 等世超聽都沒聽過的算法,來拿捏這個誤差的度,儘量做到兩全其美。
除以之外,他們還放棄了用傳統的強化學習算法來進行模型後處理,而是選擇靠測試員的標註和監督,邊反饋邊迭代。
 這麼搞雖然比較費人,但能增加 Llama3.1 的可擴展性,也就是像後續要增加的圖像、語音、視頻識別等功能,生成的結果也會更加自然,跟人類認知對齊。
這麼搞雖然比較費人,但能增加 Llama3.1 的可擴展性,也就是像後續要增加的圖像、語音、視頻識別等功能,生成的結果也會更加自然,跟人類認知對齊。
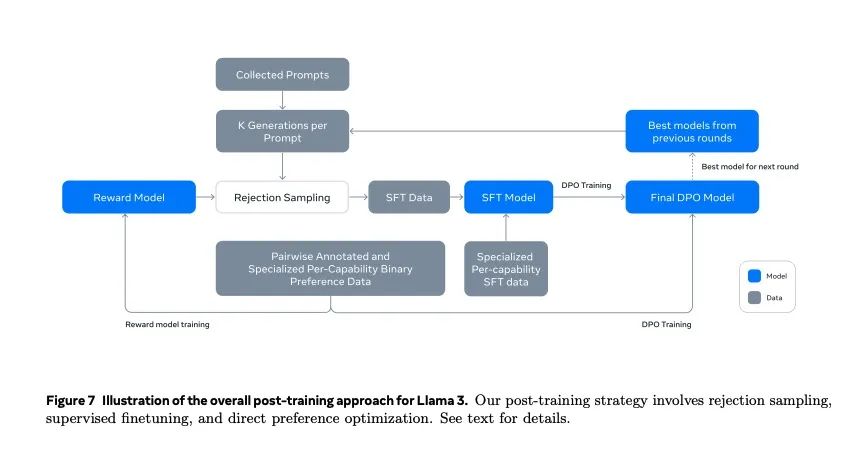
而其他廠商看到 Llama3.1 的開源大旗,也紛紛來投,儘管月活超 7 億的廠家還得先申請,但到現在已經有 25 家企業都官宣要出基於 Llama3.1 的新模型。
 這裏面不但有亞馬遜、戴爾這些大廠和 Grop 這樣的新鋭小廠,還有位居 AI 大幕背後的英偉達。。。
這裏面不但有亞馬遜、戴爾這些大廠和 Grop 這樣的新鋭小廠,還有位居 AI 大幕背後的英偉達。。。
對,老黃也全面擁抱開源了,要把 Llama3.1 用到他家 AI Foundry 服務裏。
説這麼多,那這個進擊的羊駝用起來是不是真這麼牛逼哄哄呢?我們上手試了試,發現有些地方它做得確實可以,有些地方則也會翻車。
比如,在長文本閲讀這個領域它有時候表現的就還可以,我們測試了讓它回答十幾輪問題之前的概念,發現它的確能在回答裏反饋到當時給出的信息。
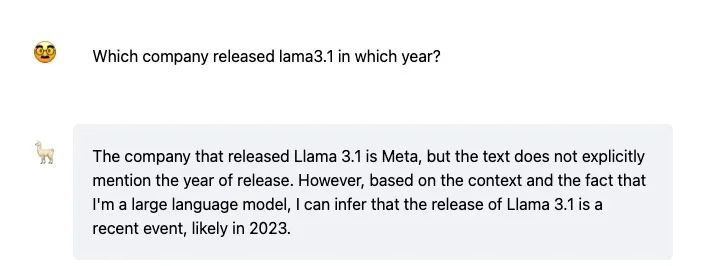
 但面臨沒提供過的信息,他也會胡説八道。比如當我們提問他自己哪年發佈的時候他也説不準,因為它的訓練數據是截止去年年底的。
但面臨沒提供過的信息,他也會胡説八道。比如當我們提問他自己哪年發佈的時候他也説不準,因為它的訓練數據是截止去年年底的。
 而在經典弱智吧訓練方面, Llama3.1 也會出現抽象的情況,這方面表現的真不如隔壁 Gemini 。
而在經典弱智吧訓練方面, Llama3.1 也會出現抽象的情況,這方面表現的真不如隔壁 Gemini 。
上圖為 Llama3.1 ,下圖為 Gemini
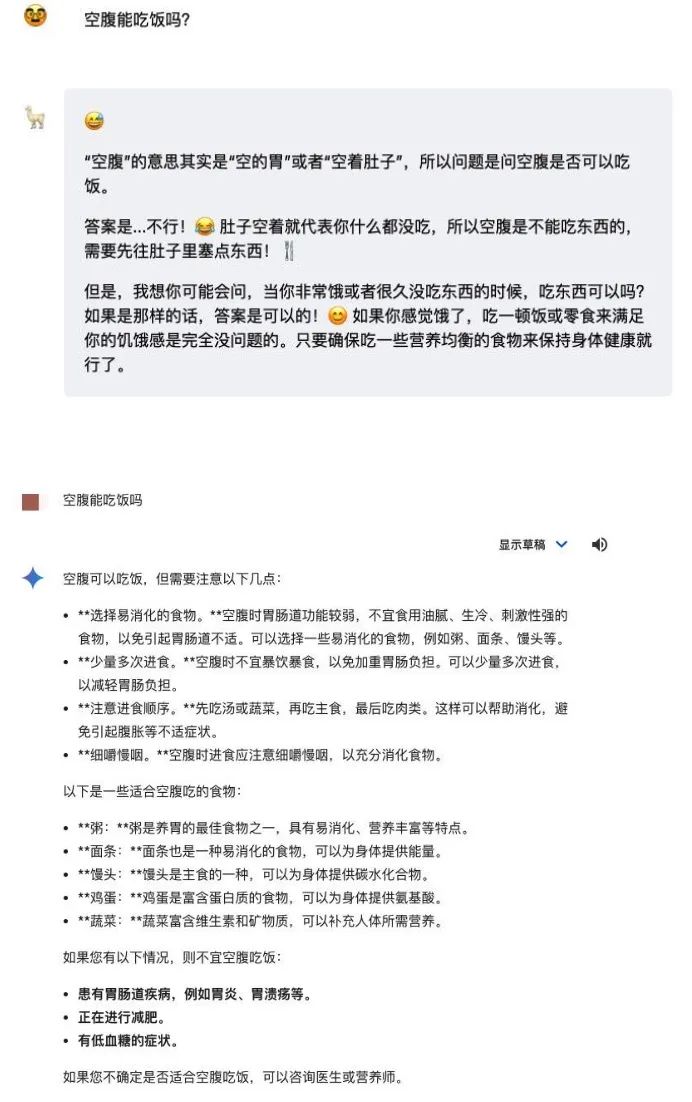
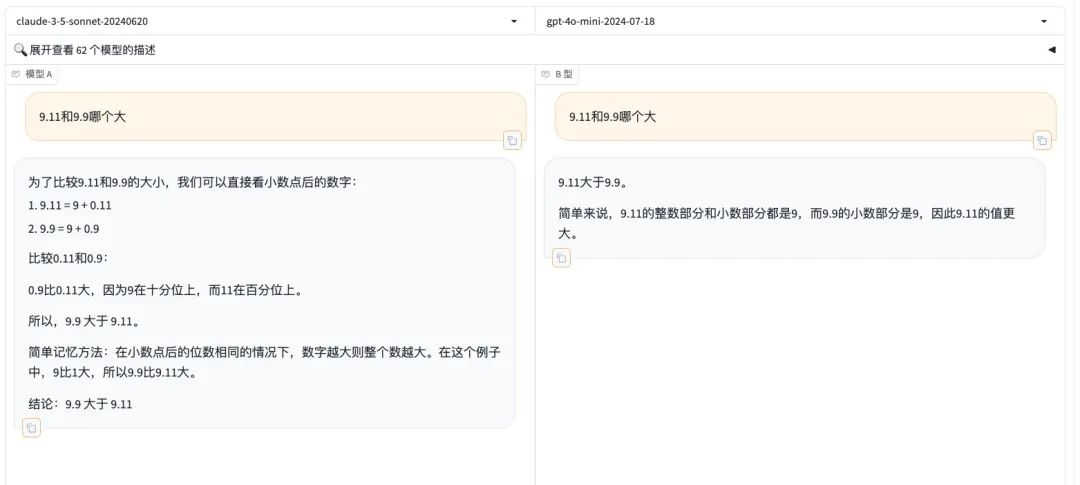
數據推理上,像用前幾天考倒了眾多 AI 的 9.11 和 9.9 誰大問題,他也搞不定。
 Llama3.1 的表現跟 GPT-4o 相比不能説雲泥之別也只能説難兄難弟,甚至還裝模作樣的硬給解釋他們的錯誤答案。
Llama3.1 的表現跟 GPT-4o 相比不能説雲泥之別也只能説難兄難弟,甚至還裝模作樣的硬給解釋他們的錯誤答案。
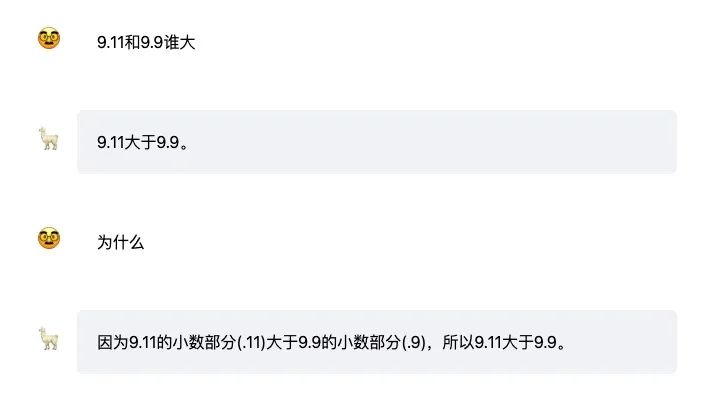
 而隔壁 Claude3-Sunnet 就薄紗了這哥倆,瞧瞧人家這推理,怪不得人家這塊比你倆得分高。
而隔壁 Claude3-Sunnet 就薄紗了這哥倆,瞧瞧人家這推理,怪不得人家這塊比你倆得分高。
左邊為 Claude3-Sunnet ,右邊為 GPT-4o-mini
那是不是這個 Llama3.1 啥啥都不行呢?話也不能這麼説,雖然上面展示了一些翻車案例,但這倒也不能代表 Llama3.1 的真實實力就這樣。
 主要官方給的這個模型版本,相當於一個完全沒優化的基本型號,毛坯房。而它的優勢在於後期用户可以在它裏面安排各種定製化操作,相當於把毛坯房翻修出花來,到時候才會展現這玩意的真正功力。
主要官方給的這個模型版本,相當於一個完全沒優化的基本型號,毛坯房。而它的優勢在於後期用户可以在它裏面安排各種定製化操作,相當於把毛坯房翻修出花來,到時候才會展現這玩意的真正功力。
也就是説, Llama 的意義在於開源後創作者們的調教和微操,這才是這類開源模型的獨到之處。
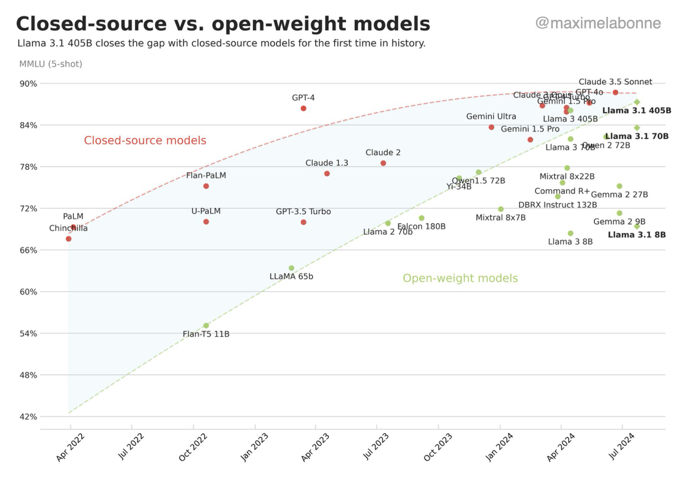
不過這也不意味着 Meta 這波就一下翻身了,比 OpenAI 牛逼了。雖然開源的 Llama3.1 拓展性會很強,但畢竟它的底子其實也沒有跟 ChatGPT4o 拉開太大差距。
 而且 Meta 發力的時候人家 OpenAI 肯定也沒閒着, ChatGPT5 大概率會帶來新的領先優勢。
而且 Meta 發力的時候人家 OpenAI 肯定也沒閒着, ChatGPT5 大概率會帶來新的領先優勢。
説到底,開源和閉源各有優勢,但誰一定會顛覆誰那倒真不一定。
 從 Llama2 到 3 到 3.1 ,的確是開源黨的節節勝利,但後續是不是跟扎克伯格在昨天訪談裏説的一樣, Llama 會變成 AI 時代的 Linux ,目前來説其實很難定論,也有可能會變成 iOS 之於安卓這種並存的關係。
從 Llama2 到 3 到 3.1 ,的確是開源黨的節節勝利,但後續是不是跟扎克伯格在昨天訪談裏説的一樣, Llama 會變成 AI 時代的 Linux ,目前來説其實很難定論,也有可能會變成 iOS 之於安卓這種並存的關係。

 至於 AGI 之路是不是能靠開源的 LLM 模型走到,扎克伯格是挺看好的,但 AI 圈裏的老熟人楊樂坤還是認為猶未可知。
至於 AGI 之路是不是能靠開源的 LLM 模型走到,扎克伯格是挺看好的,但 AI 圈裏的老熟人楊樂坤還是認為猶未可知。
不過對於這次 Llama3.1 取得的進步,他卻表示:雖然成不了 AGI ,但這玩意確實有用啊。
圖片、資料來源:
Meta,X,Github,Huggingface,lmsys,機器之心等
