突破CUDA包圍圈,再出一招_風聞
半导体行业观察-半导体行业观察官方账号-专注观察全球半导体最新资讯、技术前沿、发展趋势。14分钟前
關於CUDA在AI行業的影響力,這無需多言,在半導體行業觀察之前的諸多文章中,我們也有講述。
外媒HPCwire之前也曾直言,GenAI 和 GPU 與 Nvidia 的合作並非偶然。Nvidia 一直認識到需要工具和應用程序來幫助其市場增長。他們為 Nvidia 硬件創建了非常低的獲取軟件工具(例如 CUDA)和優化庫(例如 cuDNN)的門檻。
確實,Nvidia 被稱為一家硬件公司。但正如 Nvidia 應用深度學習研究副總裁 Bryan Catanzaro 所説,“很多人不知道這一點,但 Nvidia 的軟件工程師比硬件工程師還多。”Nvidia 圍繞其硬件建立了強大的軟件“護城河”。
雖然 CUDA 不是開源的,但它是免費提供的,並且由 Nvidia 牢牢控制。雖然這種情況讓 Nvidia 受益(理所當然。他們在 CUDA 上投入了時間和金錢),但對於那些希望通過替代硬件搶佔部分 HPC 和 GenAI 市場的公司和用户來説,這帶來了困難。
不過,最近又有一個方案躍躍欲試。
SCALE,橫空出世
如Phoronix所説,為了突破CUDA護城河,現在已經有各種努力,比如 HIPIFY 幫助將 CUDA 源代碼轉換為適用於 AMD GPU 的可移植 C++ 代碼,然後是之前由 AMD 資助的ZLUDA,允許 CUDA 二進制文件通過 CUDA 庫的直接替換在 AMD GPU 上運行。
但現在又出現了一個新的競爭者:SCALE。SCALE 現已作為 GPGPU 工具鏈公開,允許 CUDA 程序在 AMD 圖形處理器上本地運行。
據介紹,SCALE 由英國公司 Spectral Compute 歷時七年打造。SCALE 是 CUDA 的“潔淨室”(clean room)實現,它利用一些開源 LLVM 組件,同時形成一種解決方案,無需修改即可本地編譯適用於 AMD GPU 的 CUDA 源代碼。
與其他僅通過轉換為另一種“可移植”語言或涉及其他手動開發人員步驟來幫助代碼轉換的項目相比,這是一個巨大的優勢。
SCALE 可以按原樣使用 CUDA 程序,甚至可以處理依賴於 NVPTX 彙編的 CUDA 程序。SCALE 編譯器也是 NVIDIA nvcc 編譯器的替代品,並且具有“模擬”(impersonates)NVIDIA CUDA 工具包的運行時。
SCALE 已成功通過 Blender、Llama-cpp、XGboost、FAISS、GOMC、STDGPU、Hashcat 甚至 NVIDIA Thrust 等軟件的測試。Spectral Compute 一直在 RDNA2 和 RDNA3 GPU 上測試 SCALE,並在 RDNA1 上進行基本測試,而 Vega 支持仍在進行中。
從本質上講,SCALE 是一個兼容 nvcc 的編譯器,它可以編譯 AMD GPU 的 CUDA 代碼、AMD GPU 的 CUDA 運行時和驅動程序 API 的實現,以及開源包裝器庫,後者又與 AMD 的 ROCm 庫交互。
例如,雖然 ZLUDA 是由 AMD 悄悄資助的,但 Spectral Compute表示,他們自 2017 年以來一直通過其諮詢業務資助這一開發。SCALE 唯一直接的缺點是它本身不是開源軟件,但至少有一個可供用户使用的免費版本許可證。
據官方的文件介紹,SCALE 是一個 GPGPU 編程工具包,允許 CUDA 應用程序為 AMD GPU 進行本地編譯。SCALE 不需要修改 CUDA 程序或其構建系統,而對更多 GPU 供應商和 CUDA API 的支持正在開發中。
從構成上看,SCALE 包括:
1.一個nvcc兼容編譯器,能夠為 AMD GPU 編譯 nvcc-dialect CUDA,包括 PTX asm。
2.針對 AMD GPU 的 CUDA 運行時和驅動程序 API 的實現。
3.開源包裝器庫(wrapper libraries )通過委託給相應的 ROCm 庫來提供“CUDA-X”API。這就是和等庫的cuBLAS處理cuSOLVER方式。
與其他解決方案不同的是,SCALE並不提供編寫 GPGPU 軟件的新方法,而是允許使用廣受歡迎的 CUDA 語言編寫的程序直接為 AMD GPU 進行編譯。同時,SCALE 旨在與 NVIDIA CUDA 完全兼容,因為他們認為用户不必維護多個代碼庫或犧牲性能來支持多個 GPU 供應商。
最後,開發方表示,SCALE 的語言是NVIDIA CUDA 的超集,它提供了一些可選的語言擴展 ,可以讓那些希望擺脱的用户更輕鬆、更高效地編寫 GPU 代碼nvcc。
總結而言,與其他跨平台 GPGPU 解決方案相比,SCALE 有幾個關鍵創新:
1.SCALE 接受原樣(as-is)的 CUDA 程序。無需將它們移植到其他語言。即使您的程序使用內聯 PTX 也是如此asm。
2.SCALE 編譯器接受與相同的命令行選項和 CUDA 方言nvcc,可作為替代品。
3.“模擬” NVIDIA CUDA 工具包的安裝,因此現有的構建工具和腳本就可以cmake 正常工作。
具體到硬件支持方面,在特定硬件支持方面,以下 GPU 現在會得到支持和測試:
AMD GFX1030(Navi 21、RDNA 2.0)AMD GFX1100(Navi 31、RDNA 3.0)以下 GPU 目標已經過臨時手動測試並且“似乎有效”:
AMD GFX1010AMD GFX1101Spectral Compute 正在致力於支持 AMD gfx900(Vega 10、GCN 5.0),並且可能會針對其他 GPGPU。
當然,如前所説,他們會支持更多的GPU。
突破CUDA,AMD和Intel的做法
作為GPU的另一個重要玩家,AMD也正在通過各種各樣的辦法跨越CUDA護城河。
在HPCwire看來,替換Nvidia 硬件意味着其他供應商的 GPU 和加速器必須支持 CUDA 才能運行許多模型和工具。AMD 也已通過HIP CUDA 轉換工具實現了這一點。據瞭解,這是一種 C++ 運行時 API 和內核語言,可讓開發人員從單一源代碼為 AMD 和 NVIDIA GPU 創建可移植的應用程序。需要強調一下的是,HIP 不是 CUDA,它原生基於AMD ROCm,即 AMD 的 Nvidia CUDA 等效產品。
AMD 還提供了開源HIPIFY轉換工具。HIPIFY 可以獲取 CUDA 源代碼並將其轉換為 AMD HIP,然後可以在 AMD GPU 硬件上運行。的歸納然,這同樣是其 ROCm 堆棧的一部分。
AMD同時還和第三方開發者共同合作,推出了ZLUDA項目,從而讓AMD的GPU也可以在英偉達CUDA應用上運行。ZLUDA 在 AMD GPU 上運行未經修改的二進制 CUDA 應用程序,性能接近原生。ZLUDA 被認為是 alpha 質量,已確認可與各種原生 CUDA 應用程序(例如 LAMMPS、NAMD、OpenFOAM 等)配合使用。直到最近,AMD 還悄悄資助了 ZLUDA,但贊助已經結束。該項目仍在繼續,因為最近有人提交了代碼庫。
來到英特爾方面,他們也做了很多嘗試。
在2023年9月的一個演講中,英特爾首席技術官 Greg Lavender 建議,我們應該構建一個大型語言模型 (LLM),將其轉換為可以在其他 AI 加速器上運行的東西——比如它自己的 Gaudi2 或 GPU Max 硬件。“我向所有開發人員提出一個挑戰。讓我們使用 LLM 和 Copilot 等技術來訓練機器學習模型,將所有 CUDA 代碼轉換為 SYCL”,Greg Lavender 説。
據介紹,SYCL在異構框架中跨 CPU、GPU、FPGA 和 AI 加速器提供一致的編程語言,其中每個架構都可以單獨或一起使用進行編程和使用。SYCL 中的語言和 API 擴展支持不同的開發用例,包括開發新的卸載加速或異構計算應用程序、將現有的 C 或 C++ 代碼轉換為與 SYCL 兼容的代碼,以及從其他加速器語言或框架遷移。
具體而言,SYCL(或者更具體地説是 SYCLomatic)是一個免版税的跨架構抽象層,為英特爾的並行 C++ 編程語言提供支持。
簡而言之,SYCL 處理了大部分繁重的工作(據稱高達 95%),即將 CUDA 代碼移植到可以在非 Nvidia 加速器上運行的格式。但正如您所預料的那樣,通常需要進行一些微調和調整才能讓應用程序全速運行。
“如果你想要充分利用英特爾 GPU(而不是 AMD GPU 或 Nvidia GPU),那麼你就必須採取一些措施,無論是通過 SYCL 的擴展機制,還是簡單地構建代碼,”英特爾軟件產品和生態系統副總裁 Joe Curley解釋道。
與此同時,由英特爾、谷歌、Arm、高通、三星和其他科技公司組成的一個團體正在開發一款開源軟件套件,以防止人工智能開發人員被 Nvidia 的專有技術所束縛,從而使他們的代碼可以在任何機器和任何芯片上運行。
這個名為“統一加速基金會”(UXL:Unified Acceleration Foundation )的組織告訴路透社,該項目的技術細節應該會在今年下半年達到“成熟”狀態,但最終發佈目標尚未確定。該項目目前包括英特爾開發的OneAPI開放標準,旨在消除對特定編碼語言、代碼庫和其他工具的要求,避免開發人員必須使用特定架構,例如 Nvidia 的 CUDA 平台。具體可以參考之前的文章《打破CUDA霸權》。
但是,這似乎還不夠,更多廠商也在行動。
還有更多方案
如大家所知,在 HPC 領域,支持 CUDA 的應用程序統治着 GPU 加速的世界。使用 GPU 和 CUDA 時,移植代碼通常可以實現 5-6 倍的加速。(注意:並非所有代碼都能實現這種加速,有些代碼可能無法使用 GPU 硬件).
然而,在 GenAI 中,情況卻大不相同。
最初,TensorFlow 是使用 GPU 創建 AI 應用程序的首選工具。它既適用於 CPU,也可通過 GPU 的 CUDA 加速。這種情況正在迅速改變。TensorFlow 的替代品是 PyTorch,這是一個用於開發和訓練基於神經網絡的深度學習模型的開源機器學習庫。Facebook 的 AI 研究小組主要開發它。
AssemblyAI的開發者教育者 Ryan O’Connor在一篇博客文章中指出,熱門網站HuggingFace(用户只需幾行代碼即可下載並把經過訓練和調整的最新模型合併到應用程序管道中)中 92% 的可用模型都是 PyTorch 獨有的。
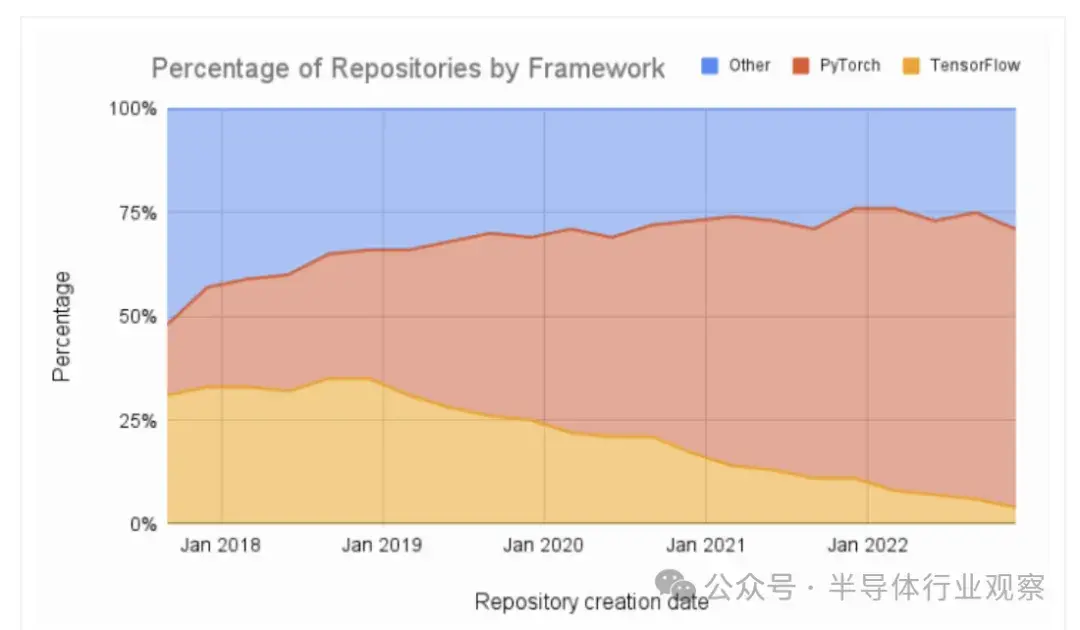
此外,如圖一所示,機器學習論文的比較顯示出了明顯的傾向於使用 PyTorch 而遠離 TensorFlow 的趨勢。
對於這些方案,大家都是怎麼看啊?
https://www.hpcwire.com/2024/07/18/scaleing-the-cuda-castle/