從被忽視和懷疑到深刻影響社會,因果推斷改寫思想史_風聞
返朴-返朴官方账号-关注返朴(ID:fanpu2019),阅读更多!1小时前
因果推斷(Causal inference)用於確定一個事件(“因”)是否以及如何引發另一個事件(“果”)。它的核心目的是理解變量之間的因果關係,而不僅僅是它們之間的相關性。因果推斷在許多領域都非常重要,包括醫學、計算機科學、社會科學、經濟學、哲學,等等。本文將回顧統計因果推斷的歷史背景,評述中國因果推斷研究的現狀,並且大膽推測它未來的發展前景。
撰文 | 丁鵬(加州大學伯克利分校統計系副教授)
1 引言
探求事物的原因,是人類永恆的精神活動之一。從古希臘的哲學到中國先秦的詩歌,都充滿了對原因的追問和對因果關係的思考。比如,亞里士多德就在《物理學》(Physics)和《形而上學》(Metaphysics)兩書中反覆強調,我們只有知道了事物的原因,才能算真正理解這個事物。又如,屈原在《天問》開篇,就追問日月星辰運行的原因。
長期以來,人們一方面好奇地追問原因和結果的關係,一方面又苦於這些概念的模糊性。於是,這些話題在很長一段時間都僅僅侷限在哲學和文學的範圍內。精確地描述因果關係,尤其是用數學的語言來描述因果關係,則是非常近代的事情了。這一項思想飛躍,得益於現代統計學的發展。統計學家稱之為“因果推斷”(causal inference)。雖然因果推斷在現代統計學的萌芽階段就已經產生,但是它的發展並非一帆風順:它長期被主流忽視、懷疑甚至攻擊。直至最近四十年,尤其是最近十年,它才得到了廣泛的認可和大力的研究,成為當今主流的研究方向之一。在最近的一篇文章中,Andrew Gelman和Aki Vehtari評選了過去五十年中,統計學最重要的八個想法,排名第一的就是因果推斷[1]。當今世界,很多年輕的學者加入了因果推斷的研究,他們來自統計學、經濟學、社會學、政治科學、教育學、流行病學、計算機科學、哲學等等領域。毫不誇張地説,統計因果推斷的研究迎來了它發展的黃金時代。
本文將回顧統計因果推斷的歷史背景,評述中國因果推斷研究的現狀,並且大膽推測它未來的發展前景。
2 哲學基礎:因果推斷何以成為可能?

人們常常問關於原因和結果的問題。比如,某人死於肺癌,是不是因為他常常吸煙導致的?比如,我感冒症狀減輕了,是不是因為服用了維生素C片導致的?比如,大學教育是否能夠提高收入水平?類似的問題,充滿了我們的日常生活。
但是,這些看似直接了當的問題,卻不容易回答。比如,有人吸煙,卻沒有得肺癌;有人不吸煙,卻得了肺癌。比如,我可能僅僅喝白開水,感冒也會自己消失。比如,有人沒有上大學,卻做生意發了大財。當然,有點概率論常識的人很容易意識到,這些事件都帶有隨機性。從經驗中,我們可能觀察到吸煙的人更可能得肺癌;服用維生素C的人,平均來説,自我感覺感冒恢復得更快;上過大學的人平均收入更高。但是,這些統計上的“相關關係”是否就是“因果關係”呢?
大部分西方哲學家都認為因果關係是一條本質的、似乎毋庸置疑的定律。但是,蘇格蘭哲學家大衞•休謨(David Hume,1711-1776)曾經拋出了一條驚人的論點。簡言之,他認為人類僅僅憑經驗,只能認識事物之間恆定的前後相繼關係(constant conjunction),並不能認識任何因果關係。很多哲學家都努力回應休謨的質疑,因為若是承認休謨是對的,那麼知識何以成為可能?若人類的知識僅僅是經驗性的前後相繼關係,那麼人類似乎沒有擁有任何“心智的榮耀”[2]。

哲學家們對休謨的回應似乎都是徒勞的。我在學生時代曾經上過鄧曉芒教授“康德哲學”的課,他就直言,休謨是駁不倒的。的確,休謨這樣的徹底的懷疑論者,是無法駁倒的。我回顧休謨的高論,並非想賣弄哲學史,因為休謨是繞不開的:無論何時何地,只要談及因果推斷,就可能有人引用休謨的論點質疑你問題的合理性。也正是因為休謨這種近乎詛咒似的言論,使得因果推斷的數學化步履維艱。
然而,上個世紀統計學的幾項輝煌成果改寫了思想史。如今人們已經不再羞於討論因果關係,統計因果推斷的語言,深入到了幾乎所有的應用領域。這些成果也許並沒有完全解決休謨的問題,但是它們給出了因果關係新的思考方式和推理框架。下面,我將分三部分回顧歷史。
3 統計學中“哥白尼式的革命”:內曼的“潛在結果”模型
1923年,耶日•內曼(Jerzy Neyman,1894-1981)還是波蘭華沙大學的博士生,他的畢業論文是“概率論在農業實驗中的應用”[3]。在這篇論文中,他提出了用於因果推斷的“潛在結果”(potential outcomes)的數學模型,並將它和統計推斷結合起來。他的想法非常自然,數學結構也很簡單。下面簡單地回顧一下。




內曼生前對自己在統計假設檢驗方面的奠基性工作頗為自豪,認為那是統計學中“哥白尼式的革命”(Copernican Revolution)[5]。他並未預料他在因果推斷的奠基性工作,也將產生深遠的影響。這個影響則是由唐納德•魯賓(Donald Rubin)開啓的。
4 統計學的拓荒者:魯賓關於觀察性研究中的因果推斷的研究
從直覺上,也許大家不會對隨機化實驗中的因果推斷感到驚奇。畢竟隨機化實驗保證了兩個組在平均意義下是相似的,那麼他們之間的區別就可以歸因於不同肥料對產量的因果作用。但是,現實的統計問題,很多數據收集並非源自隨機化實驗——這類研究通常被稱為觀察性研究(observational study)。比如,如果要研究吸煙和肺癌的因果關係,基本的倫理不允許我們隨機地讓一部分人抽煙、讓一部分人不抽煙。再如,研究大學教育對收入的影響,我們不能隨機地讓一部分人上大學、讓一部分人不上大學。很多流行病學和社會科學的問題,本質上一定是觀察性研究,人們也迫切地想從這些觀察性研究中獲得關於因果關係的知識。
雖然潛在結果模型成功地數學化了隨機化實驗中的因果推斷,但是它長期並未用於觀察性研究——內曼本人是持懷疑態度的,因為缺乏隨機化,觀察性研究有太多複雜性,比如抽煙的人和不抽煙的人,可能就是兩羣完全不同的人,不具有可比性。雖然他從未嘗試用他的潛在結果模型分析觀察性數據,但是他間接地啓發了一些更加有冒險精神的學者。其中一人就是魯賓[6]。

魯賓認為,觀察性研究也對應着一個假想的隨機化實驗,因此內曼的潛在結果模型可以用來定
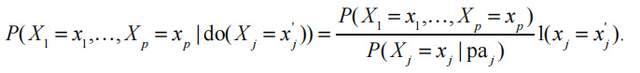

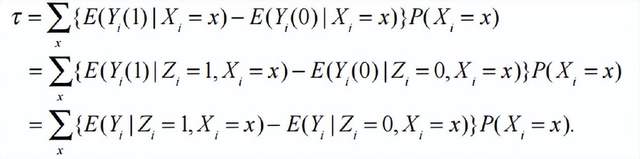
雖然內曼的因果推斷的文章為老一輩的統計學家所熟知,但是在很長一段時間它幾乎銷聲匿跡了。它不僅僅不在觀察性研究中被使用,也不在隨機化實驗中被使用。從上個世紀七十年代開始,魯賓寫了一系列文章告訴大家,潛在結果是思考統計因果推斷的有力武器,但是他的文章起初並不被統計雜誌所接受。多年以後,他這些在當時看來離經叛道的文章使他成為名副其實的統計學的拓荒者。


第一個問題不太容易有簡單的解答。珀爾試圖回答第二個問題。簡言之,回答第二個問題,需要更多的關於數據生成機制的知識,而圖模型是描述數據生成機制的一種有力工具。他提出了新的因果推斷的範式,在某些條件下重新推導出了魯賓的結果,並且得到了新的結果。
5 人工智能的“因果革命”:珀爾對圖模型的因果解釋
珀爾工作的雛形是圖模型。直觀上,這種模型用圖來刻畫條件分佈,尤其是變量之間的條件獨立性[9]。很多統計學家非常習慣用一個有向無環圖(directed acyclic graph;DAG)來表示數據的生成機制。珀爾創造性地賦予了它因果關係的解釋,並給了一系列運算法則。


來看一個具體的例子。從上面的DAG我們可以得到

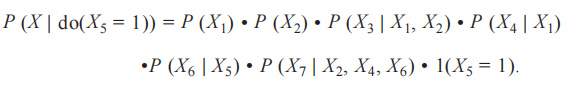
5.1 後門準則

5.2 前門準則
珀爾的後門準則並沒有給統計學家帶來很大的驚喜,因為他給的公式在形式上並不是新的。但



