這屆的AI故事,還能講多久?_風聞
星海情报局-星海情报局官方账号-关注“中国制造”的星辰大海1小时前

今年年初的時候,我給我爸媽演示了某款面向C端市場的AI產品。他們之前幾乎沒有接觸過任何形式的AI大模型,所以當我給他們談起現在的AI技術有多發達的時候,他們還以為這不過是siri這種語音助手的變種。
但在我通過語音通話的形式給AI提出問題並得到非常自然、流暢的回答後,我爸媽整個就震驚到了——他們用一種不可思議的目光看着我,問出了一個經典的問題:
“剛才和你對話的那個,難道不是真人嗎?”
AI數字人示意圖
在我讓他們嘗試玩了幾次之後,他們才終於確信:原來剛剛真的是在和AI打交道。後來的一兩天,我爸也下載了這款AI產品,玩得不亦樂乎。甚至一個星期後,我爸還在給我分享他讓AI寫的詩、畫的畫。
然後,就沒有然後了。
因為這款AI產品帶來的新鮮感已經淡了。
最近幾天,科技圈子裏最熱門的話題應該是被稱作“科技春晚”的蘋果iPhone發佈會。
但顯然,蘋果的“科技春晚”和“春晚”一樣,吸引力已經大不如前了——再也不復當年iPhone5S發佈時候的那種盛況——反倒是華為的三摺疊手機引起了不少討論。

可能這就是一個面向消費者的市場的殘酷性所在:消費者是很容易喜新厭舊的,如果你不能持續帶來新的東西,那麼很快,你的市場就會被競爭對手所蠶食——支撐iPhone當年地位的是前所未有的創新體驗,但現在,隨着整個智能手機供應鏈的崛起,各家的產品都已經來到了一個相當高的層次——iPhone可能再也不會給我們帶來當年的那種新鮮感了。
看看現在的AI,感覺似乎也是如此故事。而且由於大模型的迭代速度遠高於芯片,相應地,“下頭速度”自然也會更快一些。
就在上週末,一張來路不明、顯示Chat-GPT訪問量斷崖式下跌的圖就引發了華爾街的一陣動盪,緊跟着就是英偉達、谷歌、亞馬遜、Meta這些AI企業的股價下跌。
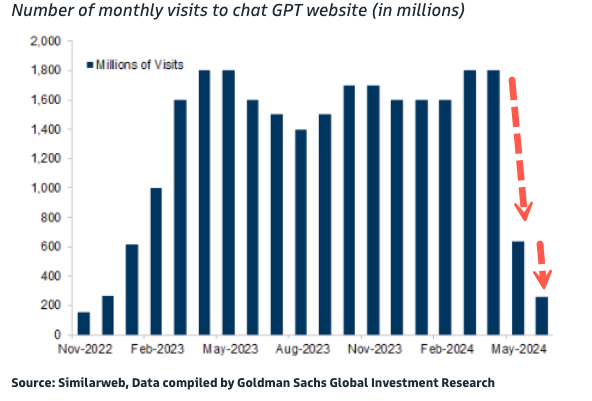
網圖,似乎是個大烏龍
雖然最終被證明是烏龍一場,但這種雞飛狗跳的畫面也挺搞笑的:
如果你真的堅信AI是未來,
又怎麼會被一張來路不明的網圖所蠱惑?
你對AI的信仰,
原來如此脆弱嗎?
今天,我們就來聊聊:現在這個版本的AI故事,究竟還能講多久。

“低端需求”
我曾經遇到過一些閃婚的情侶:初見的時候什麼都好,朋友圈裏全是什麼“斯人若彩虹,遇上方知有”的狗糧;但過了幾個月正常日子之後,私下喝酒時候,他們就開始給我吐槽各種瑣事和爭吵。
人還是那倆人,都是好同志,
但場景變了,現在真的要事兒上見了。
因為現實生活裏的問題,實在是太多樣太具體了:換下的衣服及時清洗了嗎?廚房的碗筷洗乾淨了嗎?菜買多了還是買少了?昨晚為什麼沒有把垃圾扔出去?寵物最近飯量下降了是不是要去醫院看看?中秋節假期快要到了,是不是要回老家看看爸媽……
這些零散、瑣碎、不涉及大是大非的問題,卻往往能導致一場火爆的爭吵,而案值往往不超過20元。
當事人往往會覺得自己瞎了眼了,但我們都知道,這並不是眼瞎不眼瞎的問題:
新鮮感過了,你開始用另一種更務實的KPI體系去衡量對方了,不再是熱戀期那樣單純看臉或者看性格了。
我們對當前這一波由Chat-GPT所引領的生成式AI的態度,其實也是如此。
一年多前,當Chat-GPT剛剛面世的時候,整個世界都為之驚歎——因為它確實體現出了強大的智慧,它真的可以理解我們在説什麼,還能像模像樣回答問題,還能和我們聊的有來有回,尤其是處理翻譯任務的時候,大模型幾乎吊打一切翻譯軟件。
但很快,整個市場就充滿了競爭者。
大模型終究不是光刻機,Chat-GPT證明了生成式AI的未來後,潛伏的競爭者們立刻就一擁而上——不論是美國本土的Claude.ai還是中國的文心一言和通義千問,從技術到體驗,都迅速跟上了Chat-GPT的節奏。
然後,我們和AI的“熱戀期”也就到此為止了,因為我們也要用一套更務實的眼光來看AI了。用更專業的説法就是,大家對AI的態度正在“迴歸理性”。
然後,大家才發現:原來AI也不過如此。
當下的AI,似乎只能處理我們的“低端需求”:
我曾經讓AI幫我出一個文章大綱,它反應倒是挺迅速,從原因到影響給我列了幾十條出來,但根本經不起細看,因為它完全沒有主次的概念——我那篇文章的重點就是去講述事情背後的原因,結果AI把原因分析部分只當成了一個平平無奇的章節。
七月份我去北京出差,期間和朋友約在某個燒烤店吃飯,拿到菜單我就樂了。因為菜單上的背景圖畫一眼看上就去就知道是AI的手筆——又把人物的手畫成麻花了。

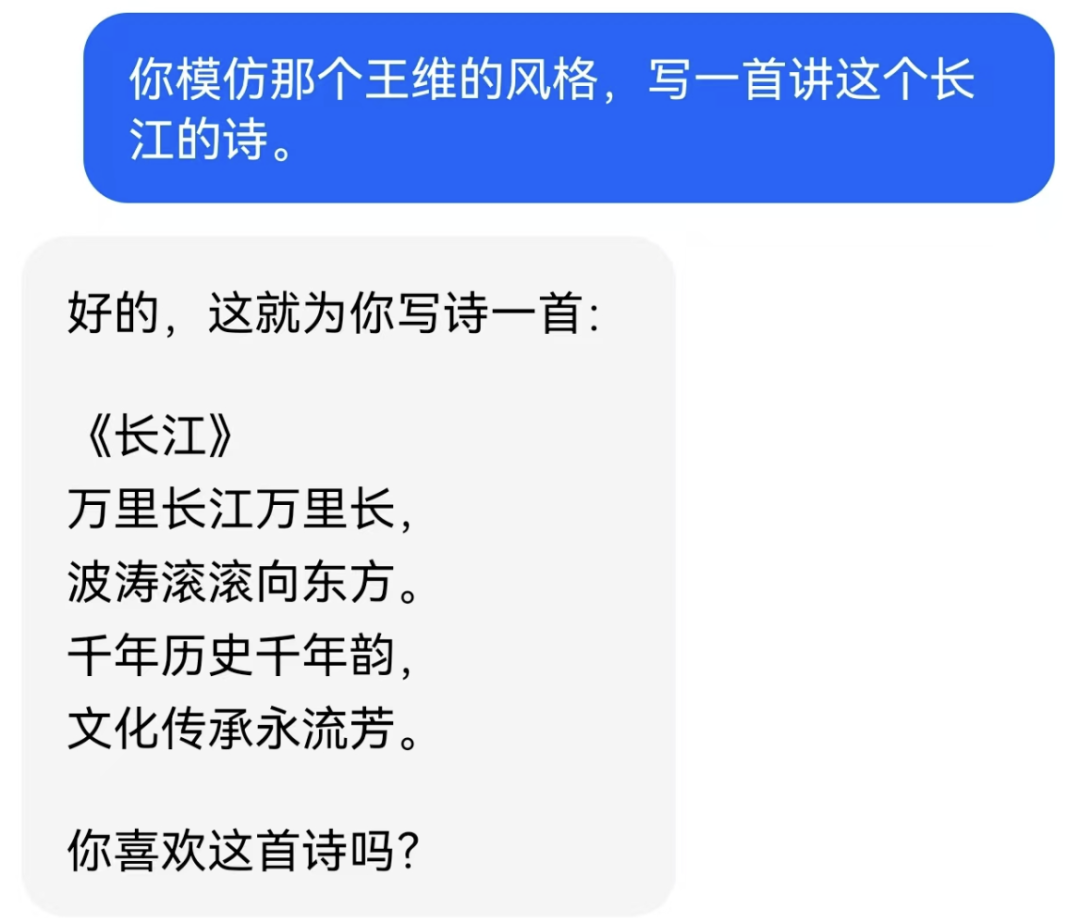
我也曾經試着讓AI幫我仿照王維的風格寫一首“氣質清冷”的詩,結果AI馬上就給我端上來一個“老幹部體”,嚇得我趕緊關了。
至於AI譜曲更是離譜,反正我自己作詞讓AI幫我編了曲之後,聽了三秒就把耳機扯下來了,實在太TM尷尬了,我這種臉皮薄的人如果再聽一分鐘估計就直接進ICU了。
……
用我朋友對AI的形容就是:每次用AI輔助工作,給他的感覺都像是在給一個剛出校園的實習生布置任務——年輕人是真的勤奮又聽話,就是腦子不太好,活兒乾的太糙了,只能做最些最基本的事情。
大模型廠商們總是在憂慮DAU和使用時間的問題,不得不説,他們的擔心是有理由的。以當下諸多AI產品在現實中的運用體驗來説,確實很難讓人把AI當成可靠的工具或者相熟的搭檔。
AI落地,應該成為工具,而不是玩具,AI應該作為我們打工人的老師傅,而不是還需要我親自去“傳幫帶”的實習生。

瓶頸期
為啥這一屆的AI產品只能滿足一些低層次需要呢?為啥感覺AI似乎也不過如此呢?
這件事,還是要從底層的技術原理上來講。
以Chat-GPT為例,打造一個像Chat-GPT一樣的大語言模型,大概需要如下幾個環節:
首先你需要海量的數據,可以是各種小説,可以是各種新聞,也可以是各種視頻、音頻,但總之,你需要準備一個足夠大的“語料庫”讓它去學習,而且為了提高它的學習效率,你還要把這些資料都給做成標準化的數據,讓模型能更好接收。
之後,像Chat-GPT這樣的大模型基本都是基於Transformer架構,這種架構我們就不多説了,説起來太複雜,我們只需要知道,這種架構的用途在於它可以按照我們人類説話的語法去輸出內容,某種意義上相當於是AI的語言中樞和喉舌。
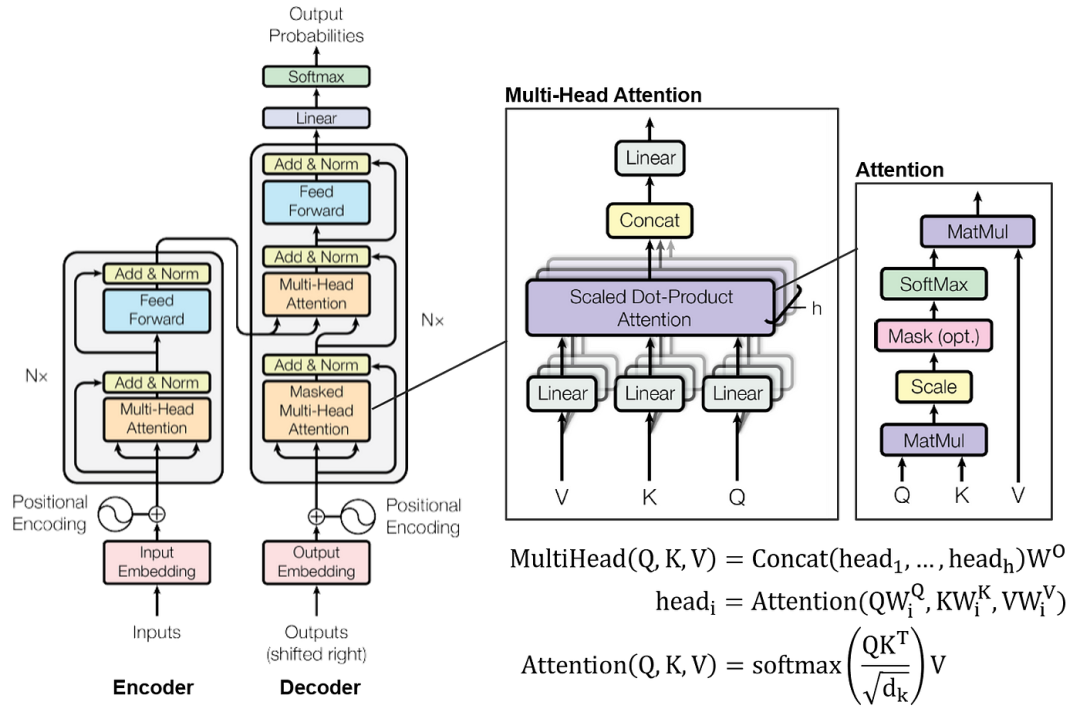
接下來,就是通過各種技術去訓練AI,再經過參數調整和一些優化,最終讓它能理解我們輸入的信息並做出合理的回覆。
但是要注意,“合理的回覆”並不代表“有用”,更不代表“擬人”——我兄弟給我發一些離譜東西的時候,我通常只會會他一串“哈哈哈哈哈哈”或者單走一個“6”,心情不好了就會回一個“有病吧”。但AI往往會故作禮貌、煞有介事地來一句“這真是一個非常有趣的圖片”。
前者雖然不合理,但卻很真實。
後者雖然很合理,但卻非常不真實。
造成這種尷尬的根本在於其開發的方式:
GPT們採用的是Transformer架構,相比起以前的RNN架構,Transformer能夠更好地理解單詞和單詞之間的順序關係,可以讓大語言模型的訓練速度顯著提高,而且能夠判斷出一句話裏到底哪個詞更重要,從而實現像真人一樣“有的放矢”。
乍一看好像沒啥毛病,但經不起細琢磨。
因為翻來覆去,GPT們做的事情都是在語言上下功夫,在不停地“猜字謎”,而不是在認識世界。
表現在實際運用中就是:你讓GPT去做翻譯工作,它可以做到99分的水平;但如果讓它去解答你的一些疑惑,可能表現就只有六七十分了。
簡單粗暴點來説就是:我説天冷了,AI自然會告訴我要穿秋褲。但AI這麼説的原因,並不是它知道穿秋褲會讓人感覺暖和,而是在它的訓練資料裏,“天冷”和“秋褲”這倆詞總是一起出現——它其實並不知道天冷了該怎麼辦,但它知道只要你説天冷了,它回一句“穿秋褲”大概率就能過關。
和某些兄弟們常説的“多喝熱水”差不多是一個意思。
説到底,這就是AI大模型開發技術上的一個通病:AI的確能理解我説的每一個字,也的確能做出合理的回答——但它做出回答的前提,並不是基於對事物發展規律的認識,而是通過海量數據的學習、通過MLM這樣的“猜字謎”訓練,給出了一個“看上去還挺靠譜”的回答。
AI視頻產品在這個問題上表現得尤其露骨,AI生成的視頻雖然有時候在畫面細節上可以做到極度仿真,但一旦涉及物理效果就會立刻把猴子屁股露出來——它並不能理解真實世界裏的物理碰撞會造成什麼結果,它只是在猜你想看什麼罷了。
Chat-GPT現在已經進化到了5.0版本(雖然還沒有正式上線),功能上當然是一代更比一代強,但這種增強的基礎,是它猜字謎的速度越來越快,猜字謎的強度越來越大,而不是真的增長了智慧。

這屆AI的故事,還能講多久?
業內對於這個問題的應對措施,則是祭出了另一種完全不同的思路——強化學習(RL)。
如果説“深度學習”的能力是在於理解語言,在自然語言處理、語音處理上可以表現優異,那麼“強化學習”則更像是在學着理解真實世界——外界不會給系統什麼指示,系統要自己試着去探索、去嘗試,然後在這個探索的過程裏獲得知識,進而讓自己越來越強大。
在這個過程裏,系統追求的是讓“獎勵信號”的最大化。這就像是一場電腦遊戲,系統不斷地和外界環境互動,每一個動作都會得到“獎勵信號”,做的越好,“獎勵信號”就越大,為了獲得更大的“獎勵信號”,系統就要自己學着做出更好的決策。
用更形象一點的話來描述就是:
AI相當於學生,人類則是老師——基於“深度學習”的AI們,它們的用着“人類教師”提供的“數據集”,在學習過程中,也要時時刻刻受着“人類教師”的監督——符合“人類教師”口味的,就會被鼓勵,不符合“人類教師”口味的就會被拋棄。
而基於“強化學習”的AI們,則更像是自學成才,“人類教師”只是領進門,修行就要靠它們自己努力了。在很多時候,它們是沒有什麼“學習資料”或者“監督指導”的,“人類教師”給他們的命令就是不停學習,至於能學成什麼樣子,其實“人類教師”心裏也沒底。

所以,我們可以看到:
基於“深度學習”的AI們,在語言理解、語音理解、圖像理解上表現極其優秀,因為這些東西的定義權掌握在人類手中,人類隨口的一句話,落在AI耳中就如神諭一般不可否定——AI們要做的就是無限貼合人類的口味,讓自己表現得和人一樣。
而基於“強化學習”的AI們則往往在和人類比高低,不論是自動駕駛系統教育老司機,還是AlphaGo打哭柯潔然後又被AlphaZero打爆,其實都反映出了一個結果:“強化學習”下的AI們,往往能夠做的比人類更好——因為人類要吃飯睡覺,但AI不用,在高性能芯片的加持下,AI訓練一年所見識過的棋局、遊戲,往往比一個職業棋手、職業電競玩家十輩子見過的都多。
畢竟,根據OpenAI自己的評估體系,像是Chat-GPT這樣的AI應用,其實只是最初級的L1水平,不過就是一個聊天機器人、一個有對話能力的AI。而基於強化學習的AI,則能夠達到L2級別,也就是能做到和人類一樣解決問題的能力。
而現在,我們已經站在了一個關鍵的時間點上:
因為大語言模型,也開始走“強化學習”的路子了,以後AI説話之前,也要動動腦子了——OpenAI一直在研究的“Strawberry”(草莓)項目,就是一個基於強化學習的大語言模型。
基於強化學習、有自己想法的大模型很可能最近一兩年就會上線,
在這樣的大背景下,我實在不知道這屆AI的故事,還能講多久。
····· End ·····