ECCV'24論文提出跨域小樣本物體檢測新數據集|已開源_風聞
量子位-量子位官方账号-1小时前
CD-ViTO團隊 投稿
量子位 | 公眾號 QbitAI
解決跨域小樣本物體檢測問題,入選ECCV 2024。
最新研究認為目前大多數跨域小樣本學習方法均集中於研究分類任務而忽略了目標檢測。
來自復旦大學、蘇黎世聯邦理工學院、INSAIT、東南大學、BOE科技的研究團隊,提出了一個用於算法評測的CD-FSOD數據集及用於衡量領域差異的style、ICV、IB數據集指標。
對現有目標檢測算法進行了廣泛實驗評估。
除此之外,團隊還提出了一種名為CD-ViTO的新方法,基於優化一個在經典FSOD上達到SOTA的開放域物體檢測器而得到。
CD-ViTO在多數情況下優於基準,成為該任務的新SOTA。
目前該項研究已入選ECCV 2024,所有數據集、代碼、以及相關資源都已開源。

研究目的
跨域小樣本學習任務(Cross-Domain Few-Shot Learning,CD-FSL)解決的是源域與目標域存在領域差異情況下的小樣本學習任務,即集合了小樣本學習與跨域兩個任務的難點問題:
源域S與目標域T類別集合完全不同,且目標域T中的類別僅存在少量標註樣本,例如1shot,5shot;
S與T屬於兩個不同領域,例如從自然圖像遷移到醫療圖像。
大多數的現有方法均集中於研究分類問題,即Cross-Domain Few-Shot Classification, 但是同樣很重要的物體檢測任務(Object Detection,OD)卻很少被研究,這促使了研究團隊想要探究OD問題在跨域小樣本的情況下是否也會遭遇挑戰,以及是否會存在跟分類任務表現出不同的特性。
與CD-FSL是FSL在跨域下的分支類似,跨域小樣本物體檢測(Cross-Domain Few-Shot Object Detection,CD-FSOD)同樣也可以堪稱是FSOD在跨域下的分支任務。
所以研究團隊先從經典的FSOD開始分析。大多數的FSOD方法都可以被粗略地劃分為:
meta-learning based,典型方法包括Meta-RCNN;
finetuning based,例如TFA,FSCE,DeFRCN。
然而近期出現了一個名為DE-ViT的開放域方法,通過基於DINOv2構建物體檢測器同時在FSOD以及開放域物體檢測(OVD)上都達到了SOTA的效果,性能明顯高於其他的FSOD方法,因此這引發了團隊思考:
現有的FSOD方法,尤其是SOTA的DE-ViT open-set detector能不能在跨域的情況下仍表現優異?
如果不能,什麼是難點問題,以及是否有辦法能夠提升open-set detector的性能?
先用下圖來揭示一下問題的答案:
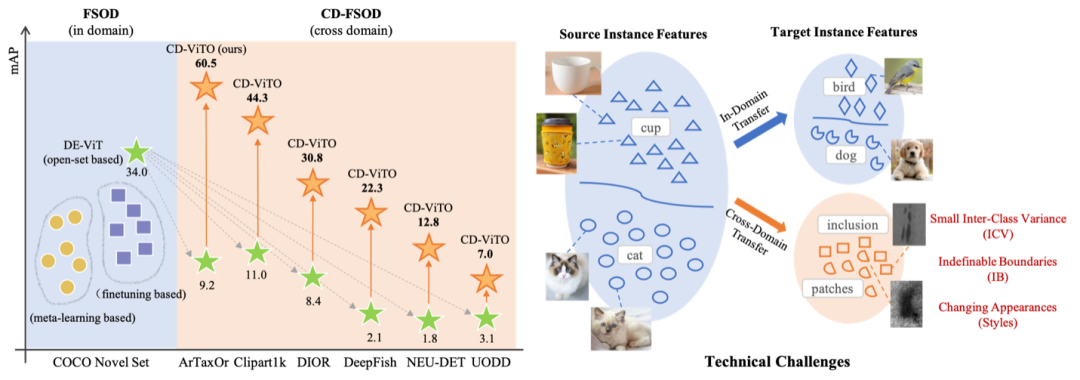
如上左圖所示,哪怕是SOTA的open-set detector DE-ViT(綠色星形)在跨域泛化的情況下性能也會出現急劇下降。
而本文研究團隊基於DE-ViT搭建的CD-ViTO方法 (橙色星形)能夠使原本性能下降的模型得以進一步提升。
而右圖,展示了相比於in-domain的小樣本物體檢測,跨域小樣本物體檢測通常會面臨三個問題:
1)目標域T的類間距離(ICV)通常較少;2)目標域的圖像可能會出現前景與背景邊界模糊(Indifinable Boundary,IB);3)目標域T得圖像相較於源域S而言視覺風格(style)發生變化。
ICV、IB、Style也成為了研究人員用於衡量不同數據集在跨域下的特性。
主要工作及貢獻
下面首先總結一下CD-ViTO團隊在解答兩個問題的過程中的主要工作及貢獻:
Benchmark, Metrics, and Extensive study
為了回答問題1,即研究現有的物體檢測器能不能泛化至跨域小樣本物體檢測任務中:
研究人員研究了CD-FSOD任務下的三個影響跨域的數據集特性:Style, ICV, IB;提出了一個CD-FSOD算法評測數據集,該數據集包含多樣的style,ICV,IB;對現有物體檢測器進行了廣泛研究,揭示了 CD-FSOD 帶來的挑戰。
New CD-ViTO Method
為了回答問題2,即進一步提升基礎DE-ViT在CD-FSOD下的性能,研究團隊提出了一個新的CD-ViTO方法,該方法提出三個新的模塊以解決跨域下的small ICV、indefinable boundary以及changing styles問題。
Learnable Instance Features:通過將初始固定的圖像特徵與目標類別之間進行對齊,通過增強特徵可分辨程度來解決目標域ICV距離小的問題 。
Instance Reweighting Module:通過給不同的圖像設置不同的權重,使得嚴具有輕微 IB 的高質量實例分配更高的重要性,從而緩解顯著的 IB 問題;
Domain Prompter:通過合成虛擬領域而不改變語義內容來鼓勵模型提升對不同style的魯棒性。
CD-FSOD數據集&Extensive Study
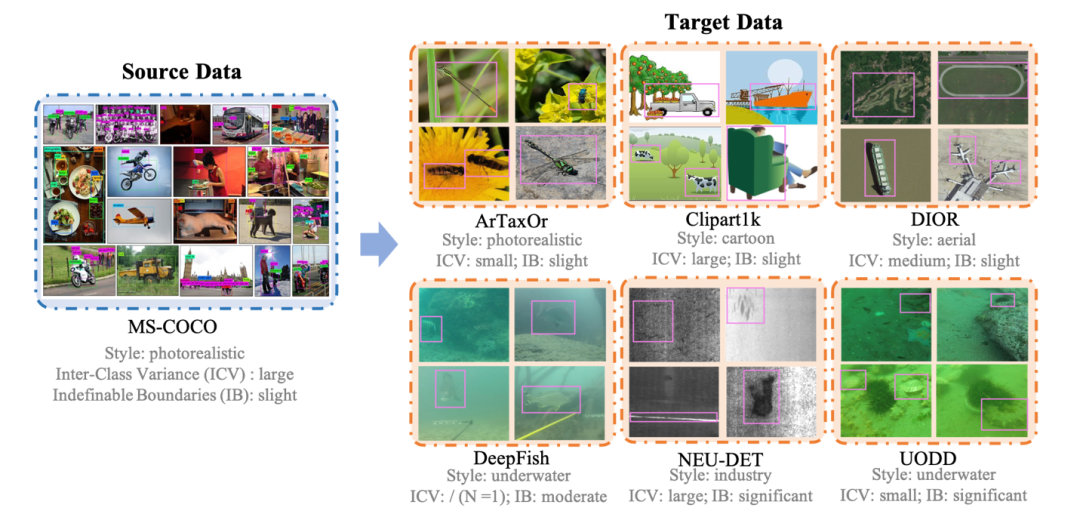
下圖為研究團隊構建的CD-FSOD數據集,該數據集以MS-COCO作為源域S,以ArTaxOr、Clipart1K,DIOR,DeepFish,NEU-DET,UODD作為六個不同的目標域T;
團隊也分析並在圖中標註了每個數據集的Style、ICV、IB特徵,每個數據與數據之間也展現了不同的數據集特性。
所有的數據集都整理成了統一的格式,並提供1shot、5shot、10shot用於模型測評。
數據集更多的介紹,比如數據類別數,樣本數等可以在論文中找到細節。
Extensive Study
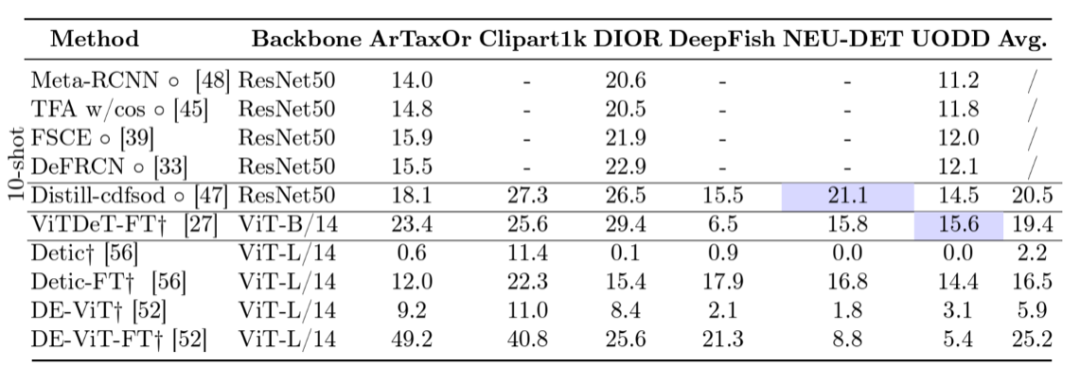
團隊對現有的四類目標檢測器進行了實驗,包括:
典型的FSOD方法:Meta-RCNN、TFA、FSCE、DeFRCN
現有的CD-FSOD方法:Distill-cdfsod
基於ViT的方法:ViTDeT-FT
開放域方法:Detic(-FT), DE-ViT(-FT) (DE-ViT僅利用視覺信息,Deti則依賴視覺-文本相似性)
其中“-FT”表示團隊用目標域T的少量樣本對方法進行了微調。
團隊結合實驗結果對這個任務以及相關方法展開了詳細的分析,主要有以下這幾點結論:
現有FSOD方法可以泛化到跨域問題嗎?A:不能
基於ViT的方法會比基於ResNet的方法好嗎?A:看情****況
開放域方法能夠直接用於應對CD-FSOD問題?A:不能
開放域方法的性能可以進一步得到提升嗎?A:可以
不同的開放域方法是否呈現不同的特性?A:是的
Style,ICV,IB是如何影響domain gap的?A:在分類裏影響巨大的style對於OD任務而言影響相對較少;ICV有較大影響但是可以被有效緩解;IB是這三者中最具挑戰的。
詳細的分析就不在這裏展開了,感興趣的朋友可以看看文章。
CD-ViTO方法&主要實驗
本文方法整體框架結構圖如下所示:
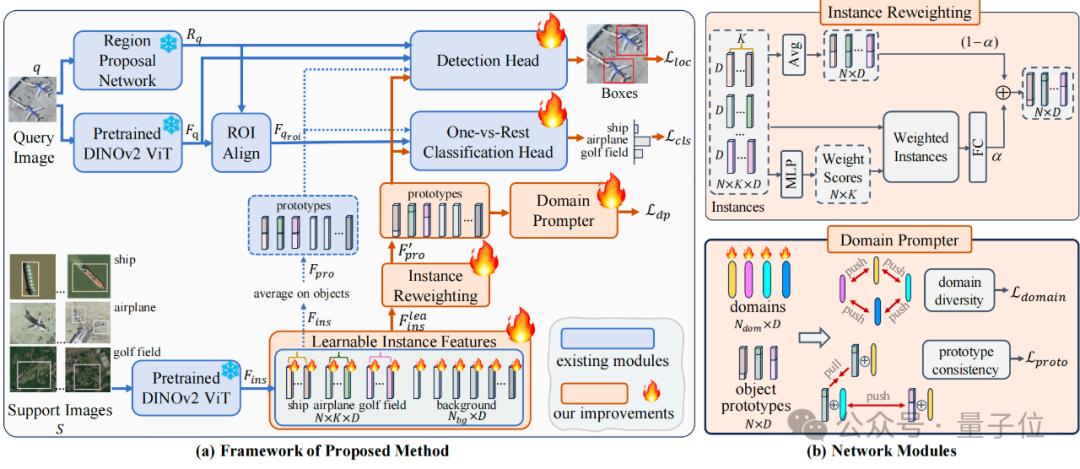
整體來看,本文研究團隊的方法是基於DE-ViT搭建的(圖中藍色塊), 首先將DE-ViT方法簡化為圖中所示的幾個模塊,主要包括Pretrained DINOv2 ViT, RPN,ROI Align, Instance Features, Dection Head,One-vs-Rest Classification Head。
DE-ViT的核心想法是利用DINOv2提取出來的視覺特徵對query image boxes與support images中所構建出來的類別prototypes進行比較,從來進行分類和定位。
基於DE-ViT方法,團隊提出了三個新的模塊(圖中黃色塊)以及finetune(圖中火苗)以搭建CD-ViTO。如前所述,每個模塊都各自對應解決CD-FSOD下存在的一個挑戰。
Learnable Instance Features
原本的DE-ViT首先利用DINOv2獲取instance features,然後簡單對同類特徵求和的方式得到support的class prototypes。
然而在面對目標域類別之間可能很相似的情況,直接使用這種預訓練的模型所提取出的特徵會導致難以區分不同類別。
因此團隊提出將原本固定的特徵設置為可學習參數,並通過結合finetune方法將其顯式地映射到目標域類別中,以此增加不同類之間的特徵差異程度,緩解ICV問題。
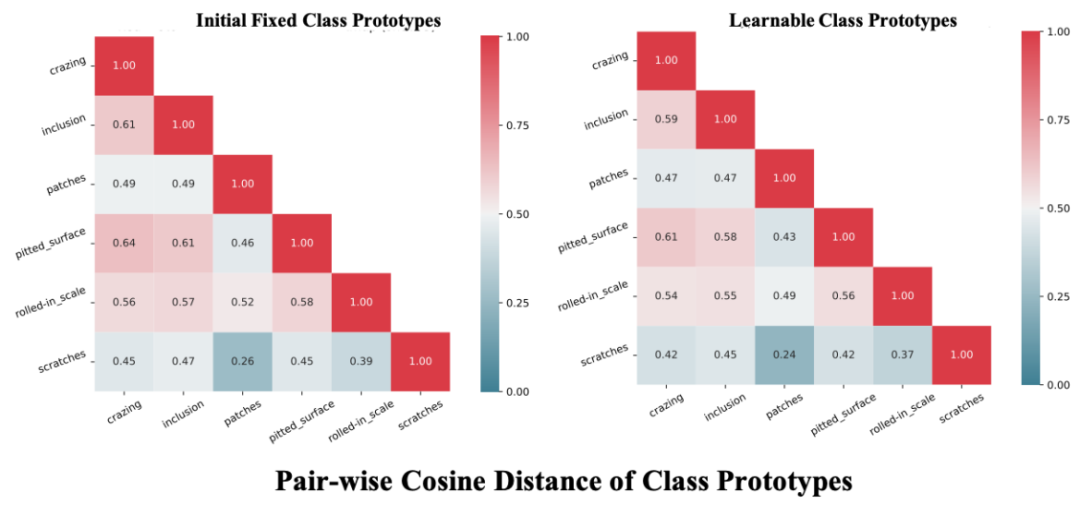
團隊對比了使用該模塊前後的類間cosine相似性,結果説明他們的模塊可以降低類間相似度,從而提升ICV。
Instance Reweighting Module
圖像模糊邊界的問題本身很難得到解決,這個模塊的主要想法是通過學習可調整的權重給不同質量的樣本賦不同的權重,使得嚴重IB的圖像被抑制,沒有或者輕微IB地圖像被鼓勵。
模塊的設計如框架圖右上所示,主要包含一個可學習的MLP。
同樣的,團隊也對該模塊做了可視化分析,他們按照所分配到的權重從高到低給圖像排序,得到如下結果。從圖中可見,前後景邊緣模糊的圖像得到的權重要低於邊緣清晰的圖像。

Domain Prompter
Domain Prompter的設計主要是希望方法能夠對不同的domain魯棒,如框架圖右下所示,在原有object prototype的基礎上,團隊額外引入數量為$N_{dom}$維度為D(等於prototype維度)的虛擬domains變量作為可學習參數。通過學習和利用這些domains,他們希望最終達到:
1) 不同domain之間相互遠離,增加多樣性 (domain diversity loss)
2) 添加不同domain至同一類別prototype所生成得到的兩個變種仍為正樣本,添加不同domain至不同類別prototype生成得到的兩個變種為負樣本 (prototype consistency loss)
兩個loss與finetuning所產生的loss疊加使用進行網絡的整體訓練。
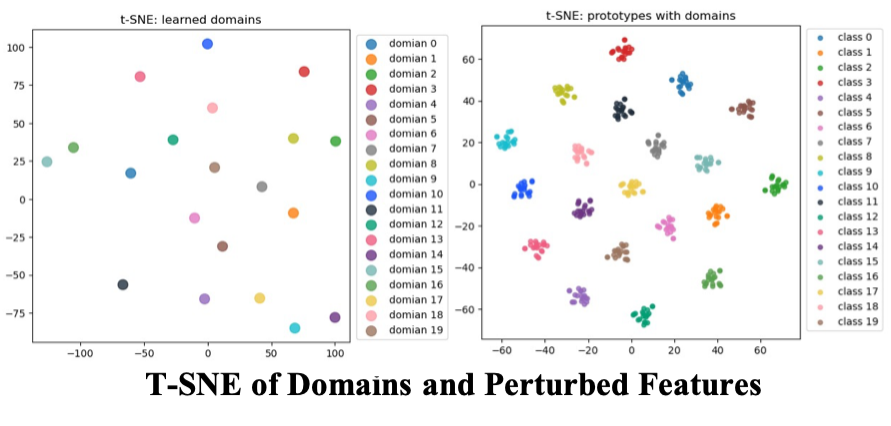
如下T-SNE可視化圖説明學習到的domains之間相互遠離;疊加不用domains至class prototype不影響語義變化。
作為簡單但有效的遷移學習方法,團隊也採用了在目標域T上對模型進行微調的思路,論文附錄部分有提供不同finetune策略的不同性能表現,團隊主方法裏採用的是僅微調兩個頭部。
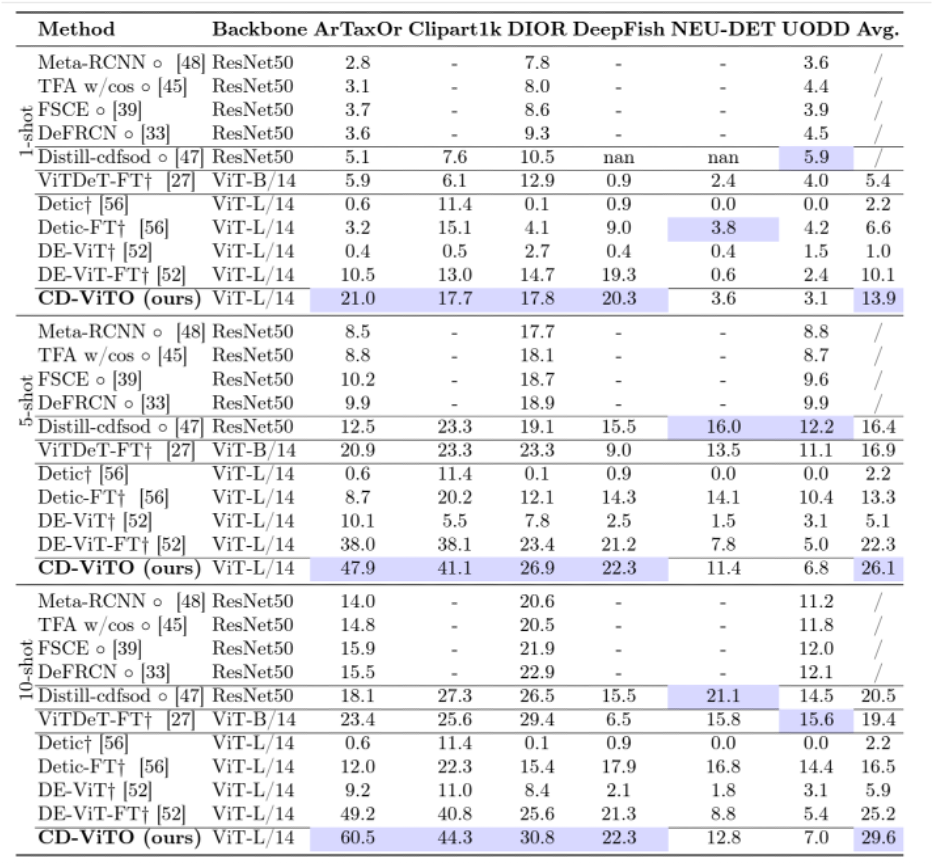
團隊在1/5/10shot上與其它方法進行了對比實驗。
實驗説明經過優化後的CD-ViTO方法在大多數情況下都優於其它的對比方法,達到了對基本DE-ViT的有效提升,構建了這個任務的新SOTA。
論文鏈接:https://arxiv.org/pdf/2402.03094
網頁鏈接:http://yuqianfu.com/CDFSOD-benchmark/
GitHub鏈接:https://github.com/lovelyqian/CDFSOD-benchmark
中文講解視頻:https://www.bilibili.com/video/BV11etbenET7/?spm_id_from=333.999.0.0
英文講解視頻:https://www.bilibili.com/video/BV17v4UetEdF/?vd_source=668a0bb77d7d7b855bde68ecea1232e7#reply113142138936707