遭GPT-4o碾壓,豆包們直面語音AI生死戰_風聞
科技新知-科技新知官方账号-洞察技术变化背后的产业变迁。26分钟前

在算力資源的匱乏下,中國的實時語音AI正面臨着一場艱難的較量,試圖在技術舞台上與GPT-4o一決高下,這無疑是當前中國AI版圖中的尷尬局面。
@科技新知 原創
作者丨廖政 編輯丨蕨影
最近,語音AI這個賽道,又被OpenAI搞火了。
就在9月25日,GPT-4o高級語音終於開始全量推出,Plus用户一週內都能用了。在OpenAI的移動端APP上即可體驗!
講真,這是AI漸冷的日子裏,為數不多的“高光時刻”。
此外,還帶上了一些更新,增加自定義指令、記憶、5種新的聲音和改進的口音。與標準語音模式進行區分(黑色旋轉球),高級語音將以藍色旋轉球表示。
並且,其中還包括對諸如重慶話、北京兒化音等地域性方言的精準模仿,可以説是學嘛像嘛。
在消除語音機械感的同時,用户不僅可以隨時打斷通話,即使不和它説話時,它也能保持安靜,一旦有任何問題可隨時向它提出。
從總體上來説,這次語音AI的更新,讓GPT-4o的交互越來越有“人味”了。
不過,早在GPT-4o的實時語音功能推出前,國內的一批大廠,就已經率先開始了對語音AI這塊高地的爭奪,其焦點也是衝着“實時交流”“真人化”等方向去的。
至於結果…… 只能説,在“徒有其表”的模仿下,國內的語音AI,離真正通用且泛化的人機交互方式,還有相當一段距離。
**Part.**1
短板暴露
在AI時代,語音AI最大的意義是什麼?
對於這個問題,科大訊飛給出了一個具有全局性的答案:
語音平台可能成為未來物聯網的“操作系統”,換句話説,就是當物聯網將所有的設備都能聯網後,什麼智能硬件、自動駕駛汽車、消費級機器人等等,都是潛在的應用場景。
到那時候,要想讓這些設備能聽懂人話,那就得靠語音平台了。
但是,雖然總的思路挺有格局的,但在具體實施的手段上,訊飛這樣的大廠卻走了一條**“自下而上”的路線。**

大體意思是,在語音AI生態的構建上,訊飛這幾年基本上是從行業場景一個個往下打,像教育、醫療、政務這些場景,都是它們重點發力的地方。
從總體上看,訊飛的策略是先抓住這些垂直領域,通過提供專用解決方案來逐步累積數據和優化算法。這個做法有個好處,就是每個場景裏,訊飛可以做得很深、很專。
舉例來説,訊飛在2022年推出了“訊飛醫療AI醫生助手”,這款產品能在病歷記錄、輔助診療等方面提供語音輸入和智能建議,幫助醫生減輕文書工作壓力。

類似的例子,還有訊飛在2023年推出了“智慧課堂解決方案”,旨在通過語音識別和評測技術,幫助教師進行實時的課堂互動與教學反饋。
在這些垂直領域,星火的定製化方案,確實解決了很多行業痛點,也使得訊飛能夠在激烈的市場競爭中保持行業的龍頭地位。
在GPT-4o推出語音演示功能後,訊飛的星火大模型,也緊隨其後,推出了同樣能夠極速響應、自由打斷,且能在各種情感、風格、方言隨意切換的語音AI。
然而,對於構建能夠“統一調度”的大平台級別的語音AI來説,除了做到佈局廣,且“説話流暢”之外,還有至關重要的一步。
那就是:實時狀態下的語音AI,究竟能否幫助用户解決一些較為複雜的需求?
關於這點,我們對訊飛的星火大模型進行了一次測試。
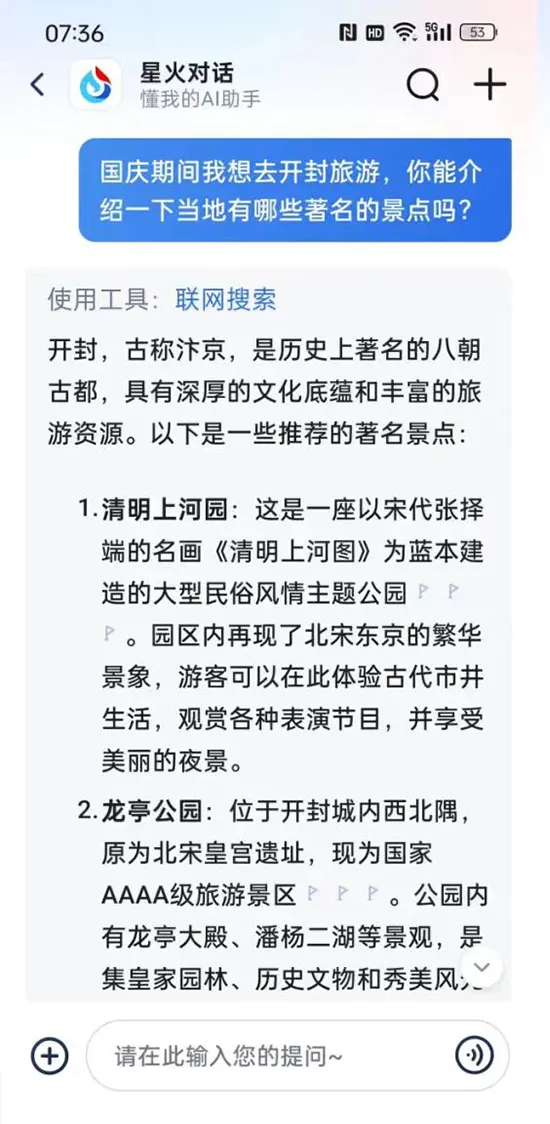
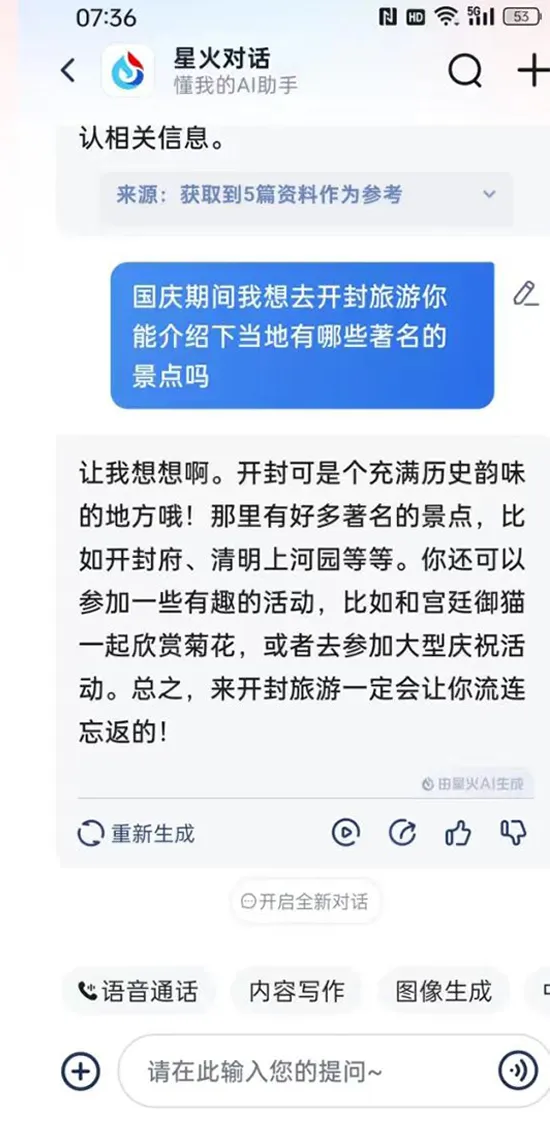
上:純文本狀態下的回答,下:實時語音狀態下的回答
例如,在詢問開封有哪些著名景點時,訊飛的實時語音AI,雖然回答得很流暢,但答案卻較為簡單,比純文本狀態下省略了很多內容。
那造成這種差距的關鍵原因是什麼?
其實,對於GPT-4o這樣的語音AI來説,除了確保通話流暢的RTC技術外,其背後還有一種關鍵的技術。
這就是端到端的語音大模型。
**在以往的AI語音交互中,語音的處理大致分成了三個步驟。**傳統的 STT(語音識別,Speech-to-Text)-LLM(大模型語義分析)- TTS(文本到語音,Text To Speech)三步走的語音技術。
這樣的技術,特點是成熟,但反應慢,缺乏對語氣等關鍵信息的理解,無法做到真正的實時語音對話。
與過去的三步式語音交互產品相比,GPT-4o 是一款跨文本、視覺和音頻端到端訓練的新模型,這意味着所有輸入和輸出都由同一個神經網絡處理。
這也是GPT-4o説話時反應賊快,智商還在線的重要原因。
而當今一眾力圖模仿GPT-4o的國產廠商,例如字節跳動,雖然依靠RTC技術,讓語音AI做到了流暢、即時,但在最核心的“內功”,即端到端語音模型方面,卻露出了短板。
**Part.**2
“智力”縮水
在今年的8月21日,字節挑動的豆包大模型,搭載了火山引擎的RTC技術,也實現了類似GPT-4o的實時音頻互動表現,能夠做到隨時打斷,交流自然,感覺就像真人説話一樣。
所謂RTC(Real-Time Communication)技術,是一種支持實時語音、實時視頻等互動的技術。旨在降低語音通話中的延遲,使得用户在進行語音對話時感覺更加自然和順暢。
但RTC主要解決的,僅僅是語音AI流暢性和實時性問題,但它並不能直接整合語音識別、理解和生成的步驟。
換句話説,在實時通話時,模型雖然話説得利索了,但智商卻不一定在線。
一個明顯的例子,就是字節的豆包大模型,在通過實時語音AI與用户交流時,遇到了和訊飛星火一樣的問題,那就是語音AI的智力,明顯比純文本大模型被“砍”了很多。
上:實時語音狀態下豆包的回答,下:純文本狀態下豆包的回答
例如,在對《黑神話:悟空》這一話題進行交流時,純文本狀態下的豆包,回答明顯要比實時語音的豆包要更詳細,更有針對性。
一個可能的原因,是豆包在進行語音交互時,使用的並不是真正的端到端語音大模型。
在非端到端模型中,語音識別、理解和生成可能仍然是分開的步驟,模型需要在極短的時間內完成語音識別、理解和生成,而這一過程的計算和響應速度,會限制其對複雜問題的深入處理。
當模型被迫快速反應時,由於無法充分利用上下文信息,從而導致了“智力下降”的表現。

其實,真正的端到端語音大模型,實現起來遠非想象中那麼簡單。
其中的難點,一在訓練數據,二在計算資源;
根據騰訊算法工程師Marcus Chen的推測,GPT-4o這樣的端到端語音大模型,背後使用的一種工程學方法,很可能是一種名叫離散化技術的路子。
這個技術,簡單點説,就是把這些連續的聲音波形切成一段一段的,每一段都提取出它特有的特徵,比如語音的語義信息和聲學特徵。這些特徵就像是一個個小的“口令”,機器可以把它們當成輸入,丟到語言模型裏去學習和理解。
但這可不是什麼人人都能輕鬆掌握的技術。
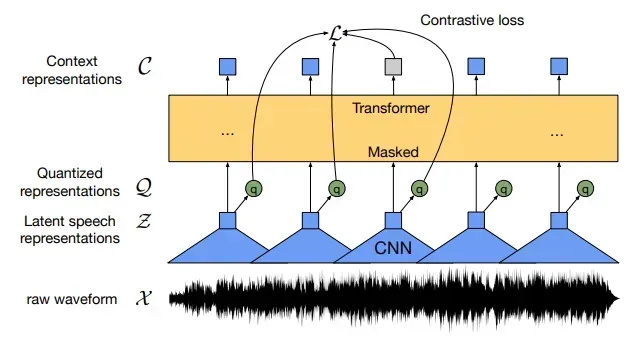
要想做出高質量的語音token,需要大量的數據積累和複雜的建模過程。
這樣的高質量數據,往往來自高質量的視頻、播客等等。成本是過去文字訓練模型的幾十倍甚至更高。
而在計算資源方面,在實時互動場景中,計算必須在極短的時間內完成,這意味着端到端的大模型,通常需要消耗大量的計算資源,尤其是在處理高維度的語音數據任務時。
這也是為什麼,OpenAI在推出GPT-4o的語音AI功能後,對用户的使用量進行了額度限制。其額度消耗和GPT-4o回覆的額度一樣。
反觀現在以豆包為首的一些國產語音AI,雖然以免費、不限次數為噱頭,但其生成質量,卻相較於純文本狀態大打折扣。
這或許正是在算力資源緊張的情況下,模型採取的一種“權宜之計”。
因為當計算資源不足時,模型可能會優先選擇簡單的、低耗能的響應方式,以確保能夠及時回應用户的請求。
畢竟,又想要免費無限地使用,又想要高質量的實時回覆,天底下哪有那麼好的事?
**Part.**3
算力困境

在AI時代,各類To C 語音產品的主要邏輯是,將昂貴或難以獲得的人類服務,且是基於對話且可以在線完成的,替換為 AI,主要場景包括心理療愈、輔導、陪伴等。
對於To C 類APP,要想大範圍地落地,其中一個前置條件,必然是成本的大幅度降低。唯有如此,企業才能夠以更低的價格提供服務,進而不斷擴大用户基數。
但問題是,在降低成本的同時,質量和成效能否保障一定的水準?
這正是最考驗訊飛、字節等大廠的一點。

從商業上來説,在降低成本的同時,要想質量不拉胯,就需要有源源不斷的資金,進行研發和技術迭代。
這就要求企業找到一種明確的商業模式,來自我造血。
OpenAI之所以能在如此短的時間推出GPT-4o的語音功能,是因為背靠微軟,能獲得源源不斷的融資,從而不斷強化其模型的能力。
相較之下,坐擁幾乎是行業內最為豐富業務場景的科大訊飛,雖然趕上了2023年AI浪潮,並在同年6月市值一度逼近2000億大關,可隨着其大模型持續高額的投入、銷售費用持續攀升**。**當下,訊飛對大模型收益能否覆蓋成本尚無定論,成本壓力始終存在。

一個重要的問題是:既然在一些特定的行業,例如醫療、教育、客服等,傳統語音AI已經能夠勝任了,那麼以端到端大模型為核心的語音AI,又該怎樣從中獲取自己的市場份額?
一個可能的方向,就是在各種長尾需求中,對一系列複雜查詢和非標準化指令做出回應。例如在智能汽車或移動應用中,端到端模型可以通過自然語言,理解用户説的犄角旮旯的地點在哪,並提供精確的導航指令。
然而,在這種模式下,用户更多地是為語音AI背後強大的語言模型付費,為其出眾的智力付費。
因此,端到端語音AI的盈利之路,一開始就因為這種“附屬地位”而充滿了坎坷,因為前者的能力一旦遇到瓶頸,其也會跟着“一損俱損”。
而在附屬於語言大模型的尷尬之下,在算力資源的分配方面,語音AI也面臨着一種不利的態勢。例如,對於字節來説,迄今為止,字節跳動已經推出了11款AI應用;其中,豆包是國內用户最多的AI獨立應用,其MAU可能已達到2000萬量級。
然而,從業務佈局上來説,語音AI現階段不太可能是字節的重點。
在9月24日的深圳AI創新巡展上,火山引擎發佈兩款視頻生成大模型PixelDance(像素舞動)和Seaweed(海草),很多業內人士分析,這條視頻AI的類“Sora”賽道,才是以短視頻聞名的字節真正不能輸掉的一仗。
而AI視頻生成,恰恰又是最消耗算力的一條賽道。

來源:豆包AI視頻生成模型
與語音AI相比,同樣消耗高算力的視頻生成AI,因為對應着短視頻這個更明確,且更易於盈利的賽道,因此在資源分配上,更有可能得到大廠或投資者的傾斜。
結合之前豆包在實時通話狀態下的智力表現,我們或許能夠推斷,留給豆包打造端到端語音大模型的算力,未必會那麼充足。
而這種資源不足,卻又要在面上與GPT-4o一較高下的情況,這正是當下實時語音AI這支“偏軍”在中國AI版圖中的窘境所在。
語音交互技術火熱了十來年,到了大模型時代,OpenAI、科大訊飛、字節這些大廠,又開始重新在往這領域擠,為何?因為這種技術,實際上暗藏着語音平台可能成為未來物聯網“大腦”的想象。
通過一個語音平台,操控所有智能終端,這是所有傳統語音AI都辦不到的事。但是,這技術要想做得好,得先解決一個大問題,就是機器得能真正理解人説的話。這就需要AI在自然語言理解、知識獲取這些領域有新的突破。
然而,在語言大模型遇到瓶頸,且算力資源被視頻AI等“光環”更耀眼的產品搶走的情況下,語音AI在中國人工智能的版圖中,暫且只能是個尷尬的存在。