為何物理諾獎頒給兩位人工智能學者?人工智能的歷史變遷及對人類社會的影響_風聞
返朴-返朴官方账号-关注返朴(ID:fanpu2019),阅读更多!1小时前
實際上,辛頓對人工智能真諦的探索一直是有轉變的。
撰文 | 張軍平(復旦大學計算機科學技術學院教授)
2024年10月8日,國慶節放假結束第一天,2024年的諾貝爾物理學獎頒給了兩位人工智能學者,約翰·霍普菲爾德(John Hopfield)和傑弗裏·辛頓(Geoffrey Hinton),因為他們通過人工神經網絡對機器學習方面形成了奠基性貢獻。我相信這結果讓大多數物理學家大失所望,畢竟物理學方面的成就也不少。自1901年首次頒獎開始,歷屆的物理學獎也從未給過其它專業的科學家,倒是反過來的有,比如居里夫人,1911年因發現元素釙(Polonium,對她出生國波蘭的紀念)和鐳獲得諾貝爾化學獎,成為第一個兩獲諾貝爾獎的人。

不過,約翰·霍普菲爾德和傑弗裏·辛頓獲得諾貝爾物理學獎,估計讓人工智能學者也同樣大吃一驚。畢竟人工智能界的最高獎通常是圖靈獎,是為紀念人工智能圖靈所設。辛頓在2018年和他兩學生Yoshua Bengio, Yann LeCun(楊立昆,中譯名)因對深度學習的貢獻獲得圖靈獎,估計已經知足了,沒想到還有大獎在後面。而另一讓人工智能學者吃驚的可能是,為啥霍普菲爾德能拿諾獎。從1936年圖靈提出想模擬人類智能的圖靈機開始,傑出的人工智能學者層出不窮,為啥霍普菲爾德能夠勝出呢?下面以我個人的理解,來簡單聊聊兩位人工智能科學家的貢獻。

辛頓是大家熟悉的,他的成名作是與Rumelhart以及Williams於1986年在《Nature》上發表的誤差反向傳播算法。該算法讓神經網絡經歷第一波寒冬後,重新走向人工智能的舞台。儘管該算法在數學界很早就有相關的研究,但應用於神經網絡則是從1986年開始。只是,反向傳播算法引發的熱潮,在1995年左右很快又被統計機器學習蓋過去,因為後者在當時既有嚴格的理論保證,也有比當時的神經網絡更為出色的性能。結果,有將近20年的時間,人工智能的主流研究者都在統計機器學習方面深耕。即使2006年辛頓在《Science》上首次提出深度學習的概念,學者們仍然將信將疑,跟進的不多。
直到2012年,辛頓帶着他的學生Alex在李飛飛構建的ImageNet圖像大數據上,用提出的Alex網絡將識別性能比前一屆一次性提高將近10個百分點,這才讓大部分的人工智能學者真正轉向深度學習,因為以之前每屆用統計機器學習方法較上一屆提升性能的速度估計,這次的提高需要用20多年時間。
自此以後,人工智能界開始相信,大數據、算力、深度模型,是走向通用人工智能的關鍵三要素。科學家們想到了各種各樣的方式來增廣數據,從對圖像本身的旋轉、平移、變形來生成數據、利用生成對抗網來生成、利用擴散模型來生成;從人工標註到半人工到全自動機器標註。而對算力的渴望也促進了GPU顯卡性能的快速提升,因為它是極為方便並行計算的。但它也導致了對我國人工智能研究的卡脖子,因為目前幾乎絕大多數學者和人工智能相關企業都認為硬件是對大數據學習的核心保障。深度模型的發展也從最早的卷積神經網絡,經歷了若干次的迭代,如遞歸神經網絡、長短時記憶網絡、生成對抗網、轉換器(Transformer)、擴散模型,到基於Transformer發展而來的預訓練生成式轉換器 (GPT),以及各種GPT的變體。
回過頭來看,這些研究與辛頓在人工智能領域、尤其是人工神經網絡方面的堅持是密不可分的。
當然,辛頓的堅持並不意味着他只認定一個方向。實際上,他對人工智能真諦的探索一直是有轉變的。記得某年神經信息處理頂會(NIPS,Neural Information Processing Systems)會議曾做過一個搞笑視頻,講述辛頓對大腦如何工作的理解,從1983年的玻爾茲曼機、到1986年的反向傳播、到對比散度、再到2006年的深度學習,經歷過多次的變遷。如果用機器學習的表述來理解辛頓的觀點,可以説依某個小於1(1表示確定,0表示否定)的概率成立。
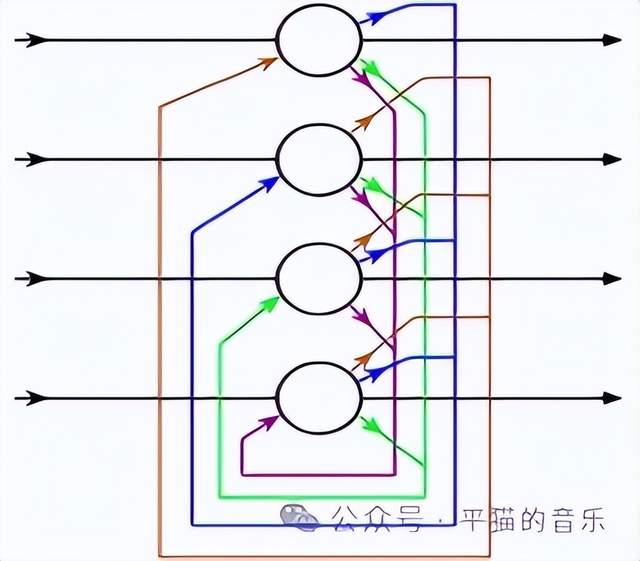
再説説霍普菲爾德。他的主要貢獻是1982年提出的Hopfield網絡,如果從發表的時間節點來看,當時沒有反向傳播算法,這個網絡的初期版本自然是無法通過誤差反向來調優的。
但這個網絡當時發表在PNAS期刊上,文章的標題裏有一個與物理相關的單詞“Physical Systems”。網絡的主要想法是,如果按物理學講的能量函數最小化來構造網絡,這個網絡一定會有若干最終會隨能量波動穩定到最小能量函數的狀態點,而這些點能幫助網絡形成記憶。同時,通過學習神經元之間的聯接權值和讓網絡進行工作狀態,該網絡又具備一定的學習記憶和聯想回憶能力。
另一個與物理相關的是,構造該網絡的設計思路模擬了電路結構,假定網絡每個單元均由運算放大器和電容電阻組成,而每一個單元就是一個神經元。
不過,這個網絡從當時看,還是存在諸多不足的。比如只能找到局部最小值。但更嚴重的問題是:
儘管從神經生理學角度來看,這個網絡的記憶能對應於原型説,每個神經元可以看成是一個具有某個固定記憶的離散吸引子(Discrete Attractor),但它的記憶是有限的,且不具備良好的幾何或拓撲結構。
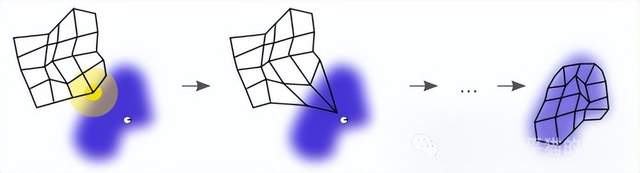
所以,便有了很多在此基礎上的新方法的提出。比如1989年的Kohonen網絡在設計時就假設有一張網來與數據雲進行匹配,通過算法的迭代最終可以將網絡完好地擬合到數據上,而網上的每個節點便可以認為是一個記憶元,或離散吸引子。這樣的網絡有更好的拓撲或幾何表徵。
另外,關於人的記憶是不是應該是離散吸引子,至今也沒有終結的答案,比如2000年左右就有一系列的流形學習文章發表(Manifold learning)。這些文章在神經生理學方面的一個重要假設是,人的記憶可能是以連續吸引子形式存在的。比如一個人不同角度的臉,在大腦記憶時,吸引子可能是一條曲線的形式,或者曲面、或者更高維度的超曲面。人在還原不同角度的人臉時,可以在曲面上自由滑動來生成,從而實現更有效的記憶。在此理念下,僅考慮離散吸引子的Hopfield網絡及其變體,自然就少了很多跟進的研究者。
當然,流形學習的研究實際上後期也停頓了,因為這方面的變現能力不強。
隨着深度學習的興起,大家發現通過提高數據量、加強算力建設、擴大深度模型的規模,足以保證深度學習能實現好的預測性能,而預測性能才是保證人工智能落地的關鍵要素。至於是否一定要與大腦建立某種關聯性,是否一定要有好的可解釋性,在當前階段並不是人工智能考慮的重心。
也許,等現有的大模型出現類似計算機一樣的摩爾定律時,人工智能會迴歸到尋找和建立與大腦更為一致、更加節能、更加智能的理論和模型上。
再回到人工智能與諾獎的關係。從今年諾貝爾物理學獎的得獎情況,和人工智能近年來對幾乎全學科、所有領域的融入程度來看,也許,未來學好人工智能,很有可能會比拒絕人工智能的人,能更有效的工作、生活、形成新的重要發現,甚至爭奪各個方向的諾貝爾獎。
張軍平寫於2024年10月8日晚
作者簡介

本文轉載自微信公眾號“平貓的音樂”。

1. 進入『返樸』微信公眾號底部菜單“精品專欄“,可查閲不同主題系列科普文章。
2. 『返樸』提供按月檢索文章功能。關注公眾號,回覆四位數組成的年份+月份,如“1903”,可獲取2019年3月的文章索引,以此類推。