HBM,最新展望!_風聞
半导体行业观察-半导体行业观察官方账号-专注观察全球半导体最新资讯、技术前沿、发展趋势。52分钟前
我們可以通過多種方式來擴展計算引擎的內存容量和內存帶寬,從而更好地驅動 AI 和 HPC 工作負載,而目前我們能夠做到的還遠遠不夠。但是,我們可能做的任何事情(目前有許多有趣的光學 I/O 選項可供選擇)都必須具有可製造性和成本效益,才能採用新的內存方法。
否則,它就不會被採納,也不可能被採納。
這就是我們現在遇到的 HBM 瓶頸的原因。一小部分非常昂貴的 HPC 和 AI 工作負載受限於內存帶寬,它們將大量並行 HBM 內存堆棧放置在非常靠近計算引擎的位置。HBM 無法同時提高內存容量和內存帶寬——只能擁有其中一種。
HBM很好,很缺
HBM 內存比使用常規 DRAM 好得多,對於帶寬是關鍵的計算引擎來説,HBM 內存也比 GDDR 好,但即使美光科技與 SK 海力士和三星一起加入 HBM 陣營,世界也無法生產足夠的這種產品來滿足需求。這反過來又導致高端計算引擎(以及 HBM 所需的中介層封裝)短缺,這反過來又使市場向不自然的方向扭曲,導致原始計算和內存容量與帶寬之間效率低下和不平衡。
之前已經在許多文章中詳細討論過這個問題,我們不再重複這些冗長的內容,只想説,按照我們的想法,現在和不久的將來推出的 GPU 和定製 AI 處理器可以輕鬆擁有 2 倍、3 倍甚至 4 倍的 HBM 內存容量和帶寬,以更好地平衡其巨大的計算量。當在同一 GPU 上將內存翻倍時,AI 工作負載的性能幾乎提高了 2 倍,內存就是問題所在,也許你不需要更快的 GPU,而是需要更多的內存來滿足它的需求。
正是考慮到這一點,我們查閲了 SK 海力士最近發佈的兩份公告,SK 海力士是全球 HBM 出貨量的領先者,也是 Nvidia 和 AMD 數據中心計算引擎的主要供應商。本週,SK 海力士首席執行官 Kwak Noh-Jung 在韓國首爾舉行的 SK AI 峯會上展示了即將推出的 HBM3E 內存的一種,該內存在過去一年中已在各種產品中批量生產。
但這款新推出的 HBM3E 內存卻有一個令人興奮的地方——內存堆棧有 16 個芯片高。這意味着每個存儲體的 DRAM 芯片堆棧高度是許多設備中使用的當前 HBM3E 堆棧的兩倍,24 Gbit 內存芯片可提供每個堆棧 48 GB 的容量。
與使用 16 Gbit 內存芯片的八高 HBM3 和 HBM3E 堆棧(最高容量為每堆棧 24 GB)和使用 24 Gbit 內存芯片的十二高堆棧(最高容量為 36 GB)相比,這在容量上有了很大的提升。
在您興奮之前,16 位高堆棧正在使用 HBM3E 內存進行送樣,但 Kwak 表示,16 位高內存將“從 HBM 4 代開始開放”,並且正在創建更高的 HBM3E 堆棧“以確保技術穩定性”,並將於明年初向客户提供樣品。
可以肯定的是,Nvidia、AMD 和其他加速器製造商都希望儘快將這種技術添加到他們的路線圖中。我們拭目以待。
SK 海力士表示,它正在使用同樣先進的大規模迴流成型底部填充 (MR-MUF) 技術,該技術可以熔化 DRAM 芯片之間的凸塊,並用粘性物質填充它們之間的空間,以更好地為芯片堆棧散熱的方式將它們連接在一起。
自 2019 年隨 HBM2E 推出以來,MR-MUF 一直是 SK 海力士 HBM 設計的標誌。2013 年的 HBM1 內存和 2016 年的 HBM2 內存使用了一種稱為非導電薄膜熱壓縮或 TC-NCF 的技術,三星當時也使用過這種技術,並且仍然是其首選的堆棧膠水。三星認為,TC-NCF 混合鍵合對於 16 高堆棧是必要的。
HBM 路線圖回顧和展望
考慮到所有這些,以及幾周前 SK 海力士在 OCP 峯會上的演講,我們認為現在是時候看看 HBM 內存的發展路線圖以及 SK 海力士及其競爭對手在試圖將這項技術推向極限時面臨的挑戰了,這樣計算引擎製造商就可以避免使用光學 I/O 將 HBM連接到電機,就像我們十年來一直在做的那樣。
目前有一系列 SK Hynix HBM 路線圖流傳,每張路線圖都有不同的內容。以下是其中一張:

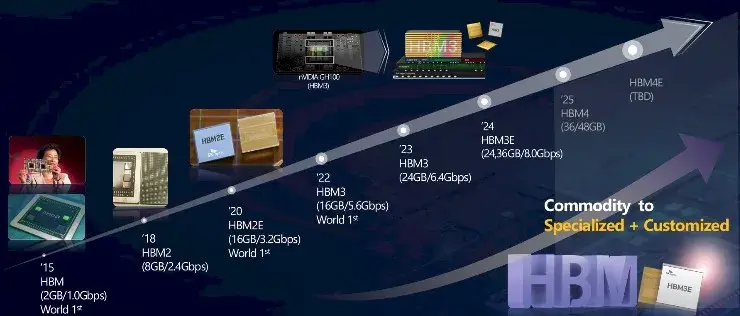
HBM2 於 2016 年推出,並於 2018 年投入商業化,此時設備的線速提升至 2.4 Gb/秒,比 HBM1 提高了 2.4 倍,每個堆棧可提供 307 GB/秒的帶寬。HBM2 堆棧最初有四個 DRAM 芯片高,但後來增加到八個芯片堆棧。HBM2 中使用的 DRAM 芯片容量為 8 Gb,因此四高堆棧最高可達 4 GB,八高堆棧則是其兩倍,為 8 GB。
這開始變得有趣起來,而當 2020 年 HBM2E 發佈時,情況變得更加有趣。DRAM 芯片密度翻倍至 16 Gbit,主內存容量翻倍至 4 層塔式機箱的 8 GB 和 8 層塔式機箱的 16 GB。DRAM 的線速提高了 50%,達到 3.6 Gb/秒,每堆棧帶寬高達 460 GB/秒。有了四個堆棧,現在一台設備的總內存帶寬可以達到 1.8 TB/秒,這比傳統 CPU 的四或六個 DDR4 通道所能提供的帶寬要高得多。
隨着 2022 年 HBM3E 的發佈,以及 Nvidia 推出“Hopper” H100 GPU 加速器和商業 GenAI 熱潮的開始,一切都變得瘋狂起來。連接 DRAM 和 CPU 或 GPU 的線路速度提高了 1.8 倍,達到 6.4 Gb/秒,每個堆棧可提供 819 GB/秒的帶寬,堆棧以八高為基礎,十二高選項使用 16 Gbit DRAM。八高堆棧為 16 GB,十二高堆棧為 24 GB。令人深感不滿意的是,HBM3 沒有實現十六高堆棧。但每次增加新的高度都不僅僅是難度的增加。
因此,我們今天推出了 HBM3E:

SK Hynix DRAM 技術規劃負責人 Younsoo Kim 介紹了公司的 HBM 路線圖,並討論了轉向 HBM4 內存所需的具體挑戰,HBM4 內存仍是一個不斷發展的標準,預計將於 2026 年在 Nvidia 的下一代“Rubin”R100 和 R200 GPU 中首次亮相,採用八高堆棧,並於 2027 年在 R300 中首次亮相,採用十二高堆棧。
“Blackwell” B100 和 B200 GPU 預計將使用 8 層 HBM3E 高堆棧,最大容量為 192 GB,而明年即將推出的後續產品“Blackwell Ultra” (如果傳言屬實,可能會被稱為 B300) 將使用 12 層 HBM3E 高堆棧,最大容量為 288 GB。(據我們所知,Nvidia 一直在嘗試產品名稱。)
我們一直在猜測 HBM4 會採用 16 個高堆棧,而令人驚喜的是,SK Hynix 實際上正在為 HBM3E 構建如此高的 DRAM 堆棧以供測試。只要良率OK,AI 計算引擎肯定可以提前利用內存容量和帶寬提升。
理想美好,現實殘酷
正如 Kim 在 OCP 演講中所解釋的那樣,在實現這一目標之前,我們還有很多問題需要解決。一方面,計算引擎製造商正在敦促所有三家 HBM 內存製造商將帶寬提高到高於他們最初同意的規格,同時要求降低功耗:
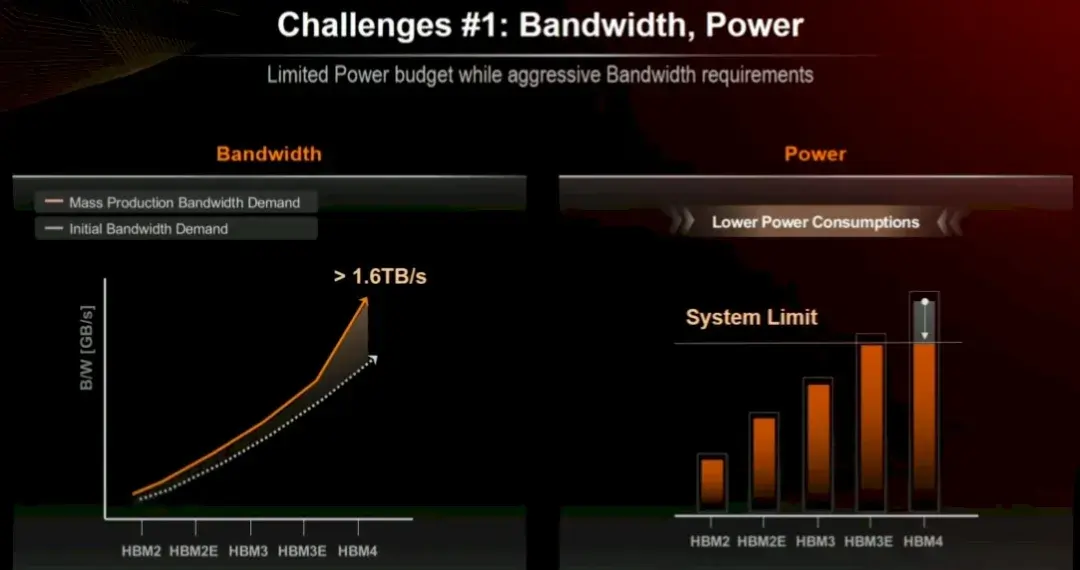
隨着計算引擎製造商將設備外殼打開,讓其升温速度快於性能提升速度,以獲得更高的性能,更低功耗的需求變得更加困難。這就是我們如何將 2013 年末 Nvidia 的“Kepler”K40 GPU 加速器的功耗從 240 瓦提高到全口徑 Blackwell B200 加速器的預期 1,200 瓦。B100 和 B200 由兩個 Blackwell 芯片組成,每個芯片有四個 HBM3E 堆棧,總共八個堆棧,每個堆棧有八個內存芯片高。192 GB 的內存可提供 8 TB/秒的總帶寬。我們還記得,整個擁有數千個節點的超級計算機集羣擁有驚人的 8 TB/秒的總內存帶寬。
順便説一句,我們認為,如果實現的話,使用 B300 中的 Micron HBM3E 內存可以將帶寬提高到 9.6 TB/秒。
遺憾的是,由於內存堆棧也增長到 16 層高,HBM4 內存密度在 2026 年不會增加。也許內存製造商會給我們帶來驚喜,推出容量更大的 32 Gbit 的 HBM4E 內存,而不是堅持使用 Kim 演示文稿中的這張圖表所示的 24 Gbit 芯片:
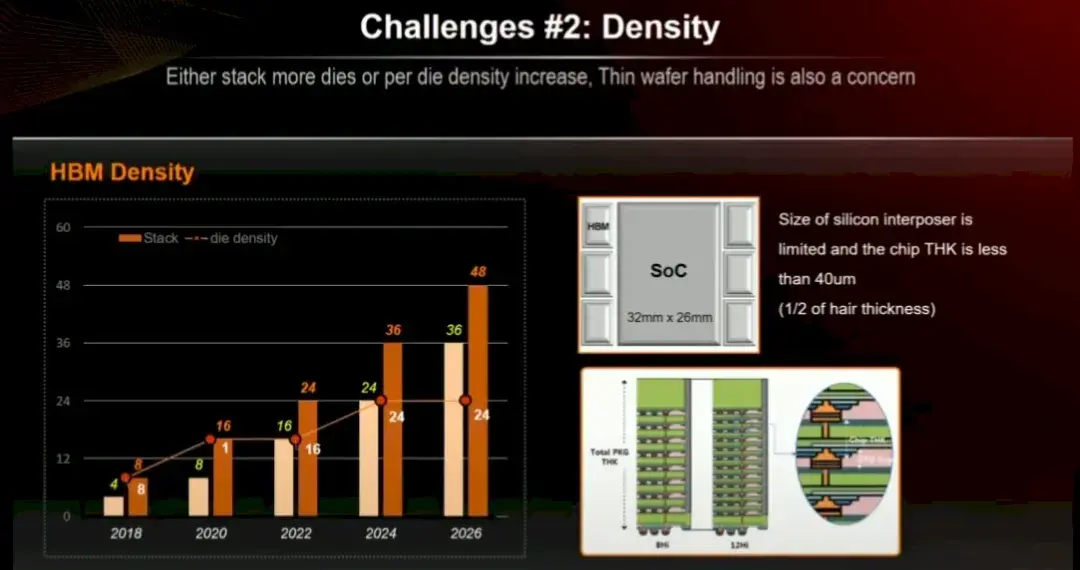
散熱問題也是一大挑戰。內存對熱量非常敏感,尤其是當你將一大堆內存堆得像摩天大樓一樣,旁邊是一個又大又胖又熱的 GPU 計算引擎時,該引擎必須與內存保持不到 2 毫米的距離,才能保證信號傳輸正常。
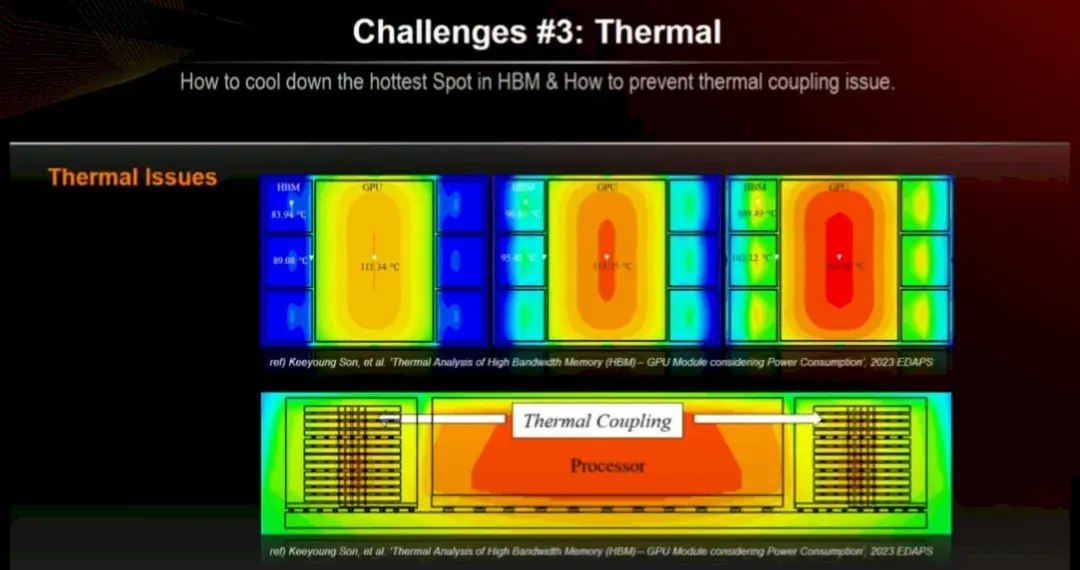
HBM3 E 具有 1,024 位寬的通道,而 HBM4 將使其加倍至 2,048 位。看起來 24 Gbit 和 32 Gbit DRAM 芯片都將支持 HBM4(可能後者用於 HBM4E,但我們不確定)。帶有 32 Gbit 芯片的 16 高堆棧將產生每堆棧 64 GB 的內存,對於 Blackwell 封裝上的每個 Nvidia 芯片來説將是 256 GB,或每個插槽 512 GB。如果 Rubin 保持兩個芯片並且只是架構增強,那就很酷了。但 Rubin 可能是三個甚至四個 GPU 互連,HBM 沿着側面運行。
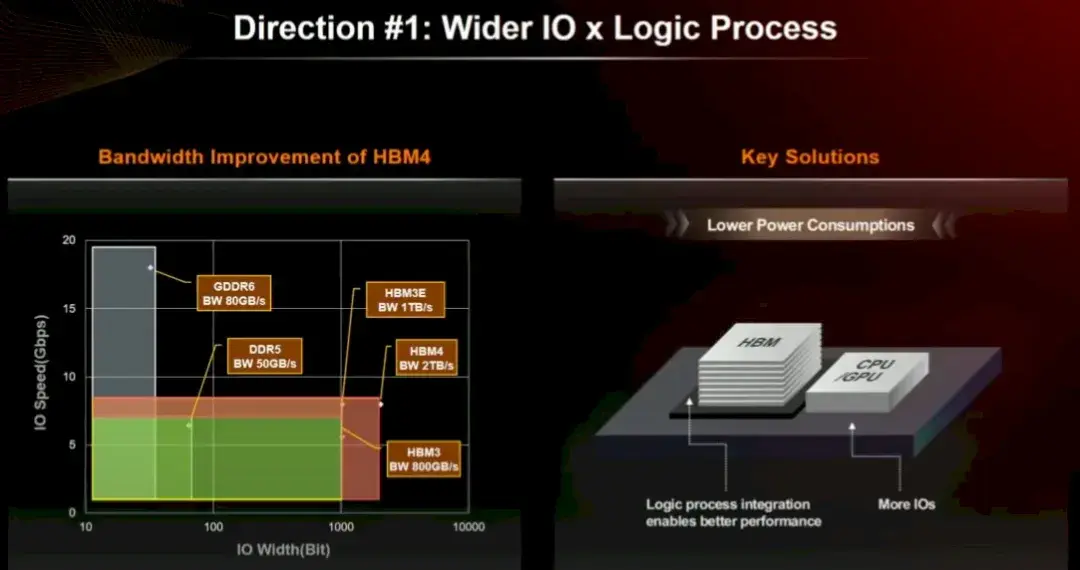
除了更寬的總線之外,Kim 還建議將內存尋址邏輯集成到 HBM 堆棧的基礎芯片中,而不是集成到 HBM 控制器中介層中的單獨芯片中,這也是一種可能性,從而降低在計算和內存之間的鏈路上進行內存控制所需的功率。

對HBM 4的展望
總而言之,HBM 4 預計將提供超過 1.4 倍的帶寬、1.3 倍的每個內存芯片的容量、1.3 倍的更高堆棧容量(16 對 12,未在下圖中顯示,因為它可能會被保存起來用於 HBM4E,除非 Nvidia 和 AMD 可以説服 SK Hynix 放棄這筆交易,並且產量足夠好,不會因使用最先進的更密集、更快的內存而損失一大筆錢),並且功耗僅為 HBM3/HBM3E 的 70%。

更好的是,讓我們將堆棧數量增加一倍,併為 Nvidia Blackwell 和 AMD Antares GPU 獲取 HBM4E。
請注意,我們並沒有要求 24 個高堆棧……那樣就太貪婪了。