實測百度iRAG技術:大模型終於知道如何去掉“AI味兒”了_風聞
三言科技-三言科技官方账号-聚焦新未来新科技,严肃又活泼昨天 22:47
出品|三言Pro 作者|DorAemon

今日,2024百度世界大會在上海舉辦,百度創始人李彥宏在會上發表了題為《應用來了》的演講。
在會上,李彥宏談到過去24個月對於大模型行業而言,最大的變化是“大模型基本上消除了幻覺”,回答問題的準確性大大的提升了。 “讓AI從一本正經的胡説八道變得可用,可被信賴。”
李彥宏在會上介紹了百度最新的iRAG技術,依託該技術,可以讓AI大模型文生圖功能準確性大增,不再有“幻覺”,也就是説,AI製作的圖片已經不再有“AI味兒”了。
其實李彥宏對AI大模型的評價是非常到位的,AI文生圖的“AI味兒重”曾經鬧出不少笑話,到現在已經進化到擺脱“AI味兒”了。
曾經“圖不對題”
如今用iRAG消除模型幻覺
記得去年國內大模型發佈之後,文生圖功能迅速吸引了一批用户,但是也很快成為網友調侃對象。
大家為什麼調侃呢,因為那時候大模型對用户“文生圖”的關鍵詞理解是真從“字面意義”上認知的。


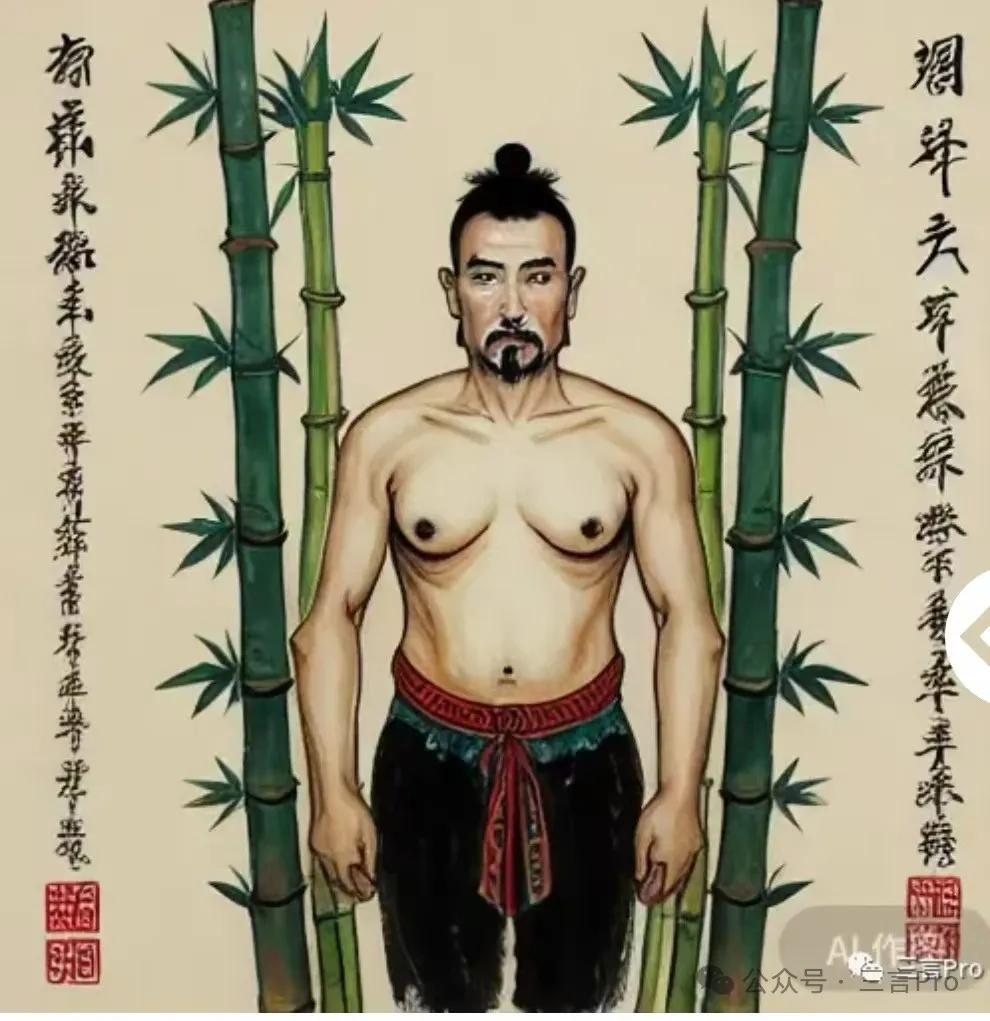


如果不説上面這五張圖的正確答案,恐怕大家很難猜得出這些圖到底表達的是什麼意思。而一旦知道了“謎底”,會立刻“笑噴”。
上面這五張圖是彼時大模型畫的錘子手機、虎皮雞蛋、胸有成竹、魚香肉絲和驢肉火燒。
除了上述這類比較“逗樂”的問題外,AI文生圖產品也經常會犯一些常識性錯誤。比如要求大模型生成一張天壇圖片,但大模型給出的結果是一座四層形似天壇的圖片,而天壇實際上只有三層。
這就是AI文生圖的“AI味兒”。
但在筆者看來,最開始大模型文生圖出現這樣令人啼笑皆非的結果,首先證明其是真“自己理解、自己生成”,而非簡單粗暴的複製網絡內容;其次,這些問題隨着產品進化也得到修復,以文心大模型為代表的國產大模型正在不斷進化。
百度世界2024上,百度正式發佈iRAG技術,即image based RAG檢索增強文生圖技術。採用該技術的文生圖能力不僅不再犯上面這種“搞笑錯誤”,更是在生成特定物品、生成特定人物與任意背景結合的圖片,比如“某人物在某地點做某事”。iRAG所生成的圖片是真實、無模型幻覺的,準確性高,沒有“AI味兒”。
那麼,擁有更強文生圖能力的文小言,實際效果如何呢?筆者決定親自測試,並且也嘗試了其他兩種不同大模型產品進行簡單對比。
測試過程中,包括文心一言在內的三個大模型使用的關鍵詞均一致,只對比不同大模型文生圖結果區別。
iRAG技術實際測試:準確率非常高
為了能夠得到更加真實的測試結果,筆者決定讓不同大模型生成十張圖,然後對比結果差異。
1. 讓大模型生成一張馬斯克在吃蛋糕的圖片。

先來看文心一言的結果,文心一言提供了兩張圖片,首先這兩張圖片中人物為馬斯克的特徵非常多,可以説一眼就能看出是馬斯克;一張中馬斯克身穿西服,手裏拿着蛋糕;另一張中則是馬斯克身着T恤,雙手端着盛有蛋糕的盤子。無論哪張,都準確無誤。

另一款大模型產品,這裏叫“大模型A”吧,一次給出了三張“馬斯克吃蛋糕的圖片”。可以看出,大模型A在特定人物刻畫上,雖然也能夠看出是馬斯克,但並沒有那麼細緻;此外,還存在一些錯誤,有一張圖片中,“馬斯克”手持蛋糕的姿勢很“詭異”,而且指頭長度明顯不對。

再看今天測試的第三個大模型的結果,這裏稱之為“大模型B”吧。大模型B畫的馬斯克與馬斯克真人相差甚遠,更別提其手持蛋糕的手指畫錯。
2. 生成一張安妮海瑟薇吃炸醬麪的圖

文心一言生成了兩張安妮海瑟薇吃炸醬麪的圖片,同樣,兩張圖中海瑟薇的細節特徵拉滿,炸醬麪、人物手部等也都準確;

大模型A則一口氣生成四張圖片,其中,有一張面部不很像海瑟薇本人;其餘三張雖然也能準確畫出海瑟薇,但在人物手部細節、餐具細節上仍有錯誤。

大模型B還是完全無法準確畫出海瑟薇形象,而且麪碗看上去也過於巨大。
3. 生成一張霍金在籃球場打麻將的圖片

這個題目筆者認為是比較“刁鑽”的,因為“元素過多”。先來看文心一言生成的兩張圖中,可以説正確率在90%,唯一錯誤則是霍金“沒有輪椅”,除此之外,人物形象、籃球場、打麻將這些細節都得到體現。

而大模型A這次屬於“徹底翻車”,不僅沒有準確生成霍金的外貌,在處理麻將桌上錯誤百出。

大模型C的結果只能説“輪椅”是正確的,人物形象和麻將牌擺放方法都不準確。
4. 生成一張蘋果CEO庫克在天壇騎車的圖片
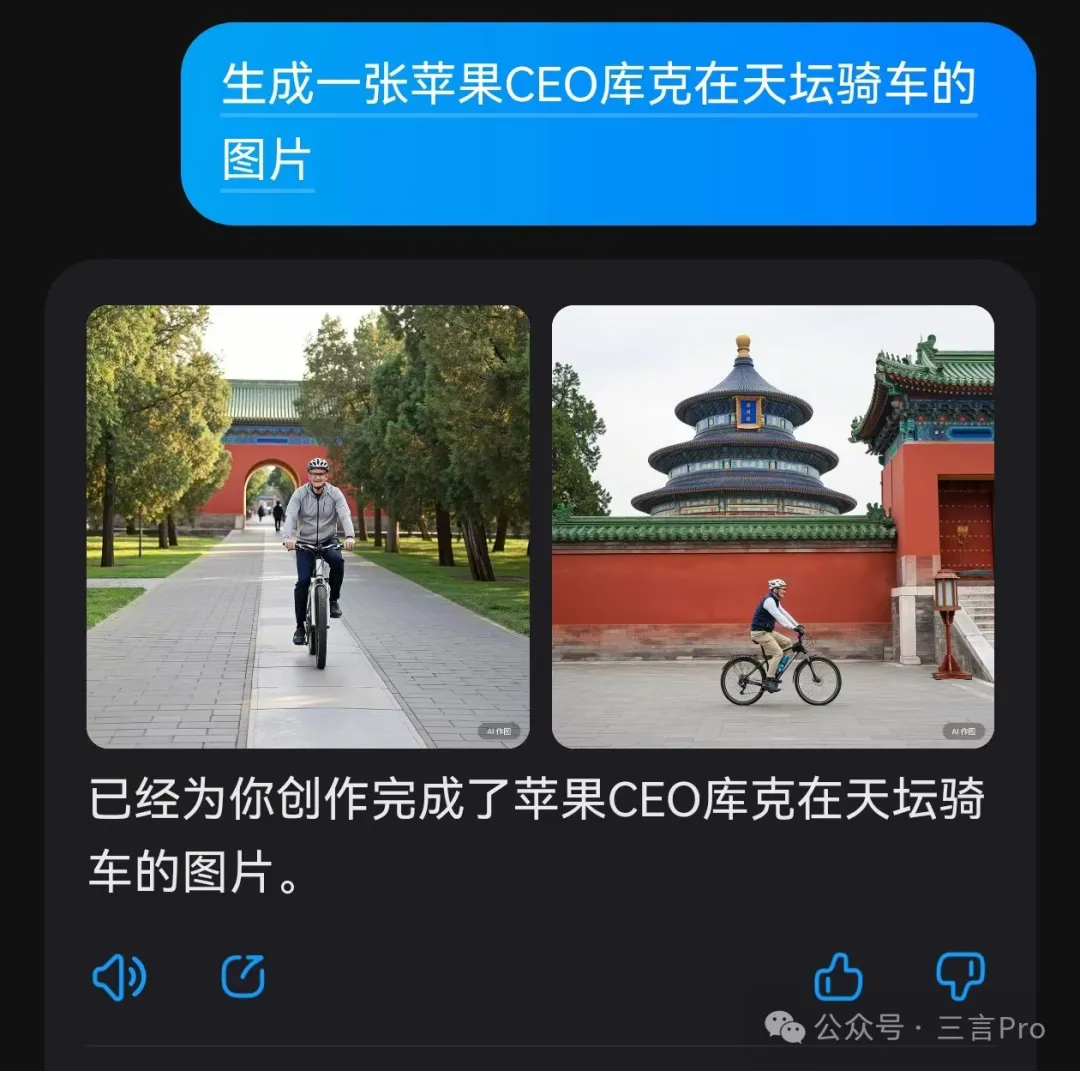
文心一言生成的兩張圖中,可以明顯看出人物具有庫克特徵,同時背景也有天壇以及天壇式建築。但庫克的面部細節還欠點意思;

而大模型A生成的四張圖中,具有明顯庫克特徵的只有一張,其餘三張人物形象偏差較大;而且騎自行車腿部細節有問題。

大模型C則再次無法生成指定人物,且騎自行車的腿部細節錯誤。
5. 生成一張喬布斯在工作的圖片。
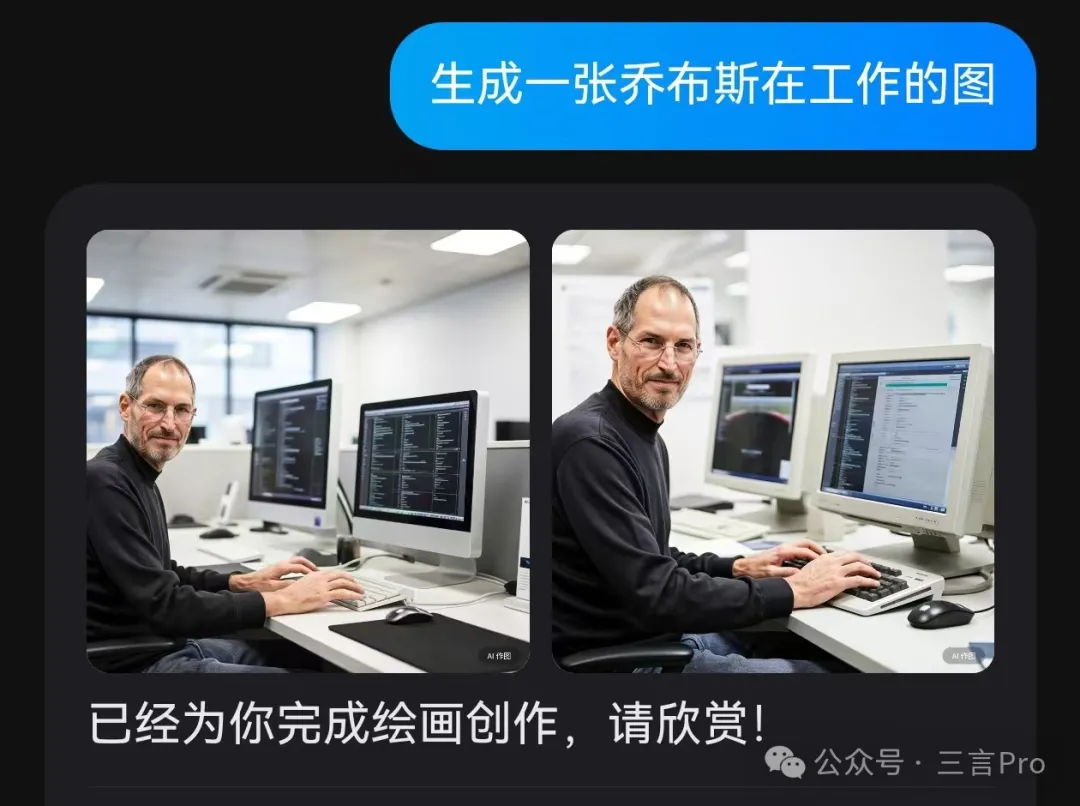
文心一言生成的兩張喬布斯工作圖基本上沒有邏輯錯誤,人物形象也比較準確,唯一問題可能是畫中電腦屏幕顯示的系統“並非Mac OS”。

而大模型A給出的四張圖中,要麼人物形象欠點意思,要麼則是對電腦處理存在明顯錯誤;

大模型B的“喬布斯”完全只是個陌生白人老人。
6. 生成一張東方明珠在深山裏的圖
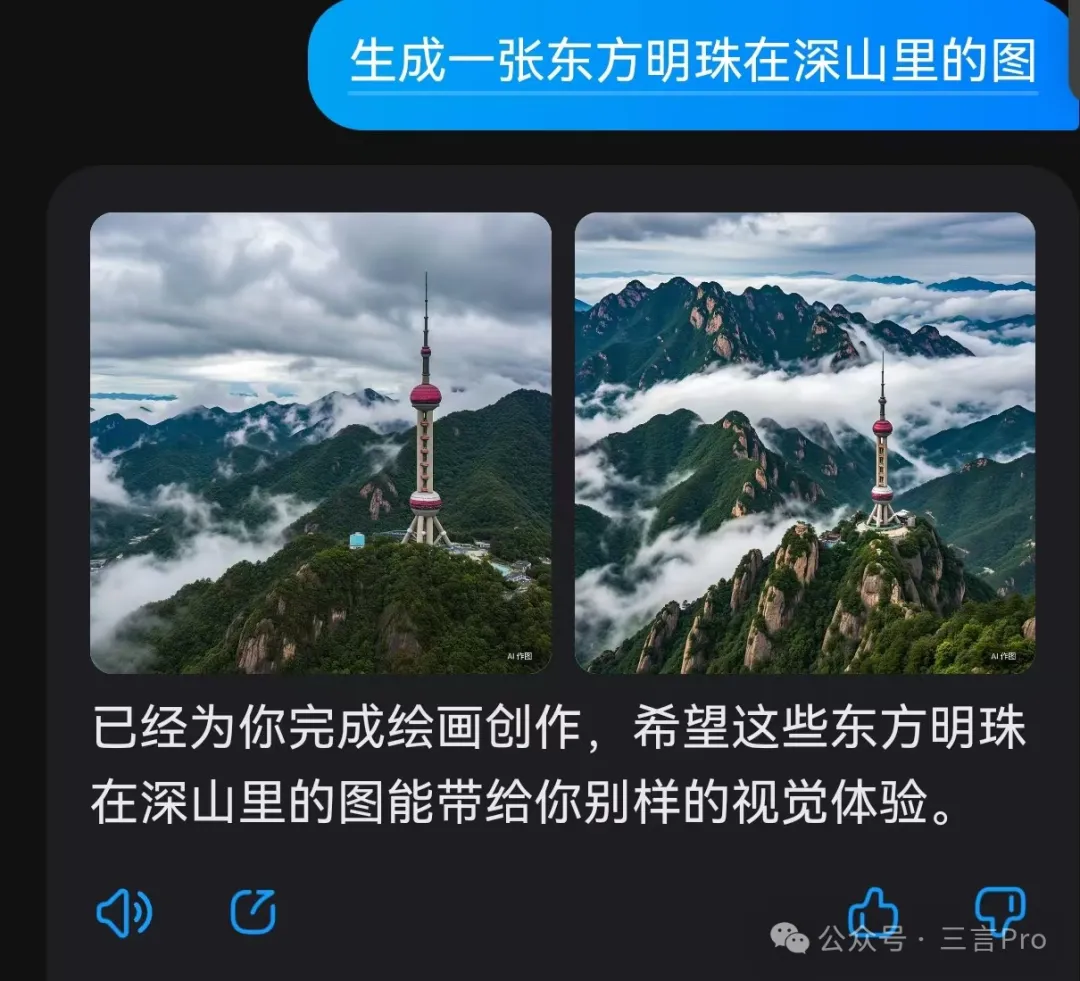
文心一言對文生圖要求比較嚴謹,不僅體現出東方明珠電視塔在深山的概念,同時也比較符合邏輯地描繪出電視塔的地基等信息。

而大模型A給出的四張圖中,則感覺比較“生硬”,有點強行將電視塔PS到山林裏的感覺,同時部分圖中東方明珠電視塔還存在細節錯誤。

而大模型B雖然體現了深山元素,但是卻完全將東方明珠電視塔描繪錯誤。
7. 生成一張魚尾獅在沙漠裏的圖
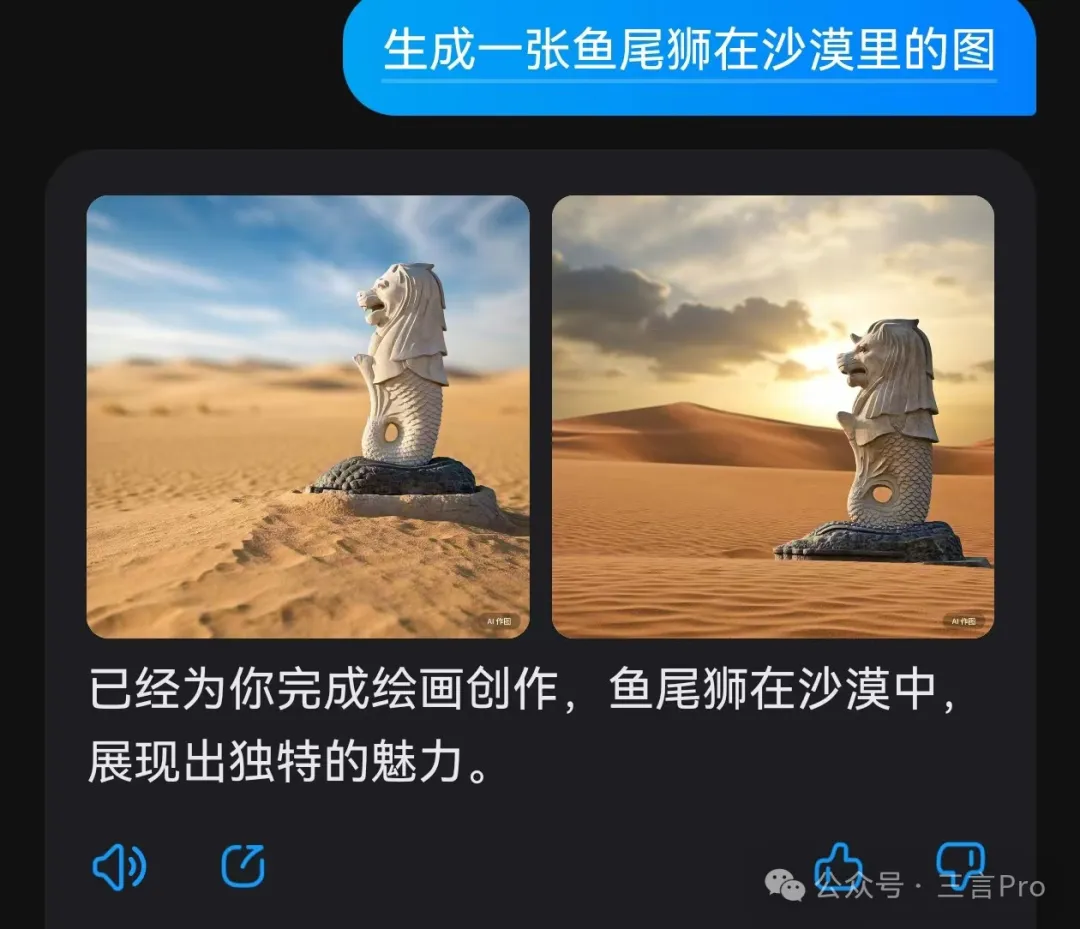
感覺這個要求對文心一言來説“輕而易舉”,不僅體現了沙漠元素,而且對魚尾獅這尊雕塑也描繪正確;


這裏把大模型A、B放一起説,因為這兩個大模型均體現了沙漠,但是卻都把魚尾獅畫錯了。
8. 生成一張天壇在海邊的圖。
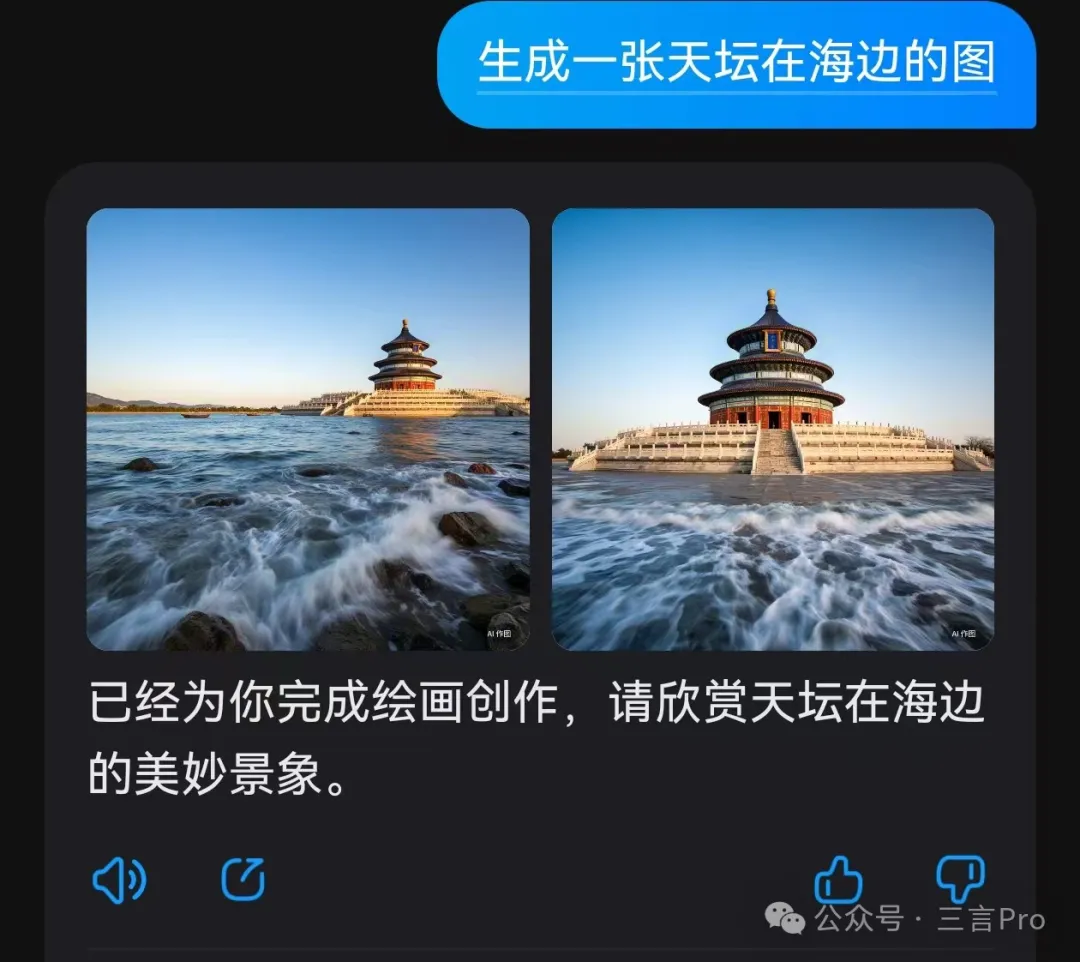
文心一言描繪的天壇在海邊圖片中,細節還是很不錯的,尤其是處理建築與水交接地方。

而大模型A生成的四張圖中,雖然也能夠比較準確描繪出天壇和海的元素,但是也存在把天壇三層建築畫成兩層情況。

大模型B乾脆把天壇“壓扁”……
9.生成一張福建土樓出現在現代都市裏的圖
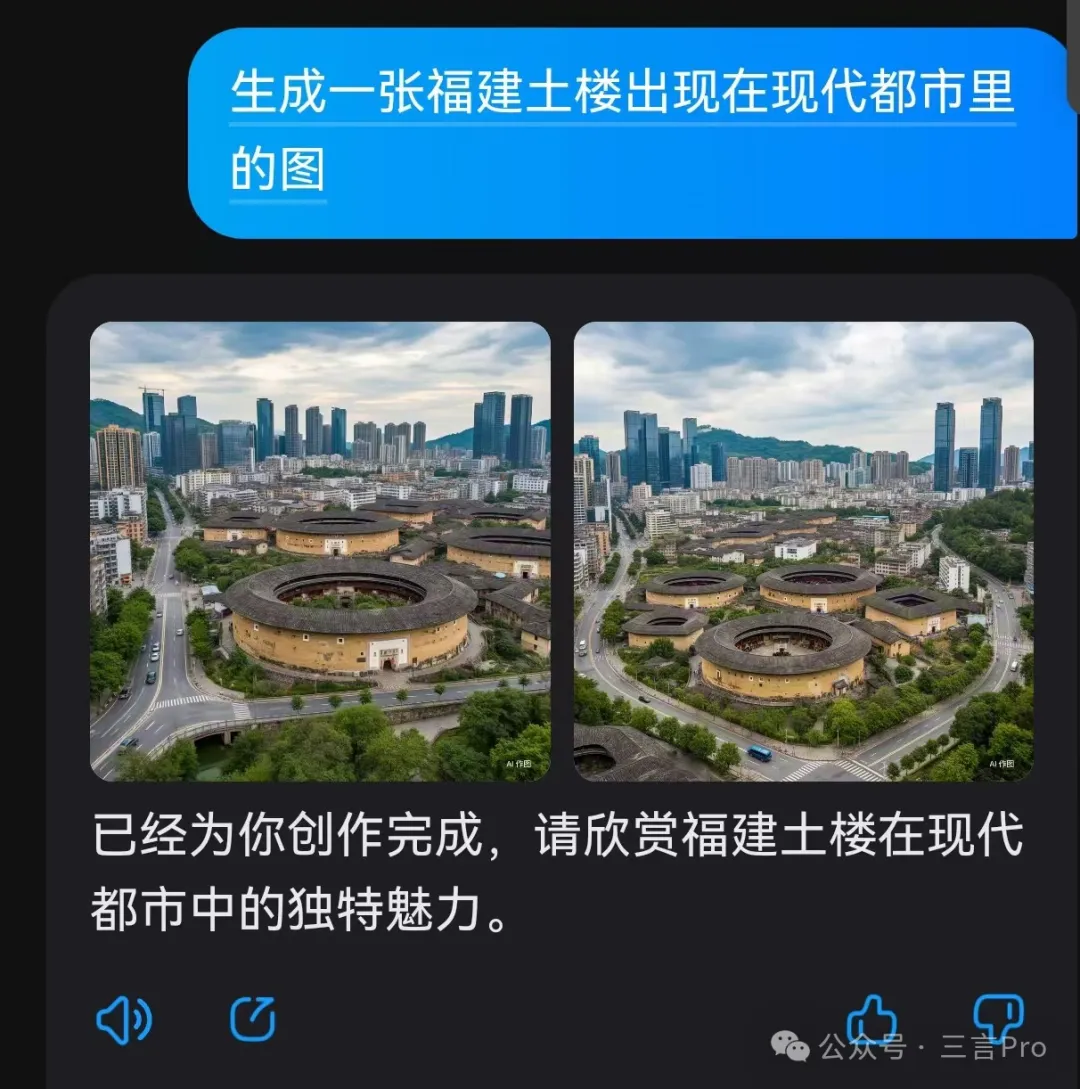
文心一言對福建土樓以及現代都市的理解準確率都很高,細節部分也都不錯;

大模型A生成的四張圖中,也基本準確的完成筆者要求,只有一張近景建築感覺“奇怪”。

而大模型B的圖片則完全把土樓畫成類似“天壇”了。
10. 生成一張甄嬛玩手機的圖
這個題目其實挺有意思,“甄嬛”歷史上並不存在,但是有其原型人物,即清朝孝聖憲皇后;所以“甄嬛”的形象對於大眾來説其實來自電視劇《甄嬛傳》,那就是演員孫儷的形象;此外,《甄嬛傳》還有原著小説,從小説角度來説,每個人心中的“甄嬛”都不一樣。
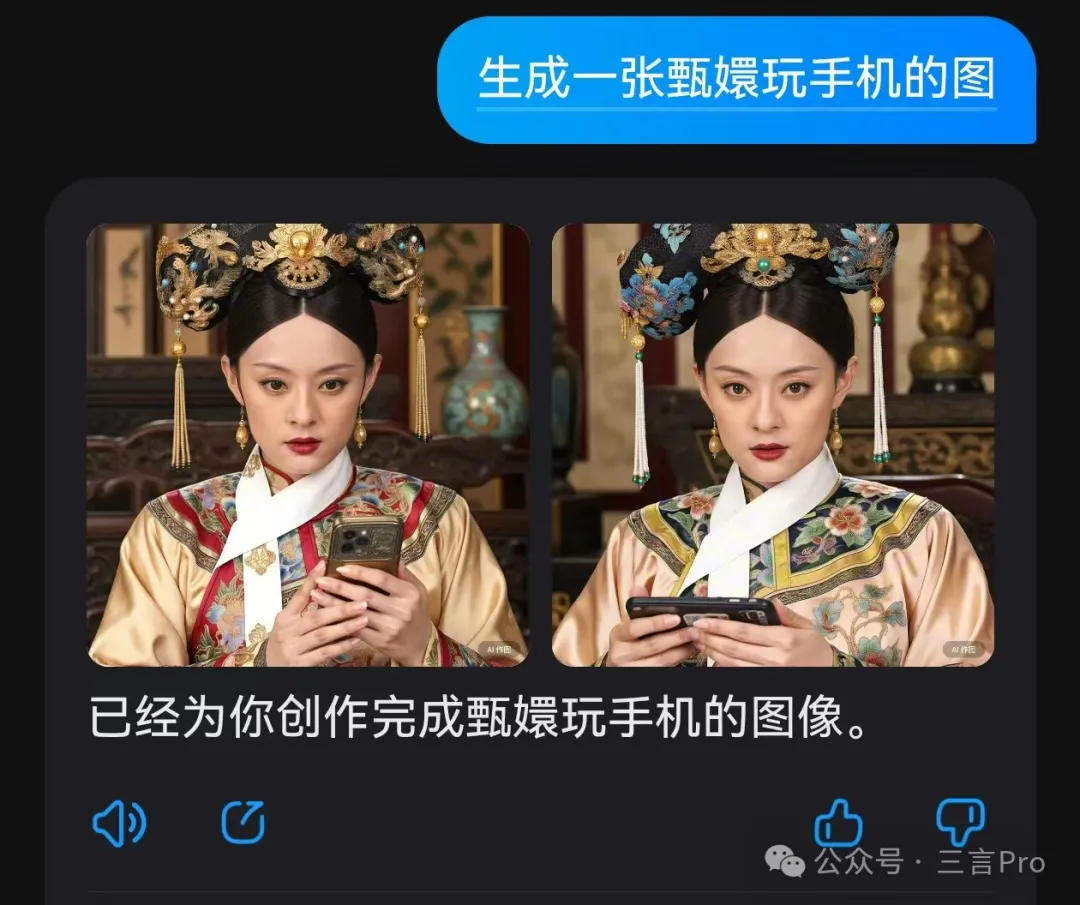
可以看出,文心一言的“甄嬛”是按照孫儷扮演的形象為基礎,相信也是很多看過電視劇《甄嬛傳》網友的“第一選擇”;同時,文心一言的圖片在細節處理準確率非常高。

大模型A則完全提供了不同的甄嬛形象,並沒有參考孫儷,不過,大模型A的圖片中,存在很多手指錯誤;

大模型B的甄嬛也同樣存在手指細節錯誤,同時手機也有些“一眼假”。
百度要做數百萬“超級有用”的應用
整個測試體驗下來,説實話,筆者着實被iRAG驚豔到。幾個大模型文生圖功能對比,文心一言對用户的指令理解能力最好,出圖正確率也是最高的。
而文心一言能夠領先,當然是基於百度強大的AI能力,而且以搜索起家的百度在這方面更是有得天獨厚的優勢。
百度的iRAG技術能夠將百度搜索的億級圖片資源和強大的基礎模型能力相結合,就可以生成各種超真實的圖片,整體效果遠遠超過文生圖原生系統,去掉了AI味兒,而且成本很低。iRAG具備無幻覺、超真實、沒成本、立等可取等特點。
在今天的測試中,文心一言對特定物品、特定人物認知能力高,同時得出的結果也沒有“變形的手指”、“詭異的物品”這種充滿“AI味兒”的情況。
再回到本文開頭提到的五張去年“鬧笑話”的AI成圖,如果讓現在的文心一言重新生成一次,結果會是什麼呢?




錘子手機不再是“真錘子”、虎皮雞蛋不再是“老虎形狀的蛋”、胸有成竹不再是字面意義上的“人和竹子”,魚香肉絲和驢肉火燒也都是美食形象……今天的大模型完全不會再犯曾經的“搞笑錯誤”,不僅能夠準確理解用户輸入詞語,而且生成的圖片如果不看水印完全認不出是AI做的。

筆者隨手用大模型A試了一下讓AI生成“胸有成竹”圖片,結果這個模型其實還是從字面意義上理解,給出的是人物和竹子兩個元素,並不像文心一言一樣能夠理解成語本意。
大模型的文生圖能力是AI應用的很小一個縮影,但同時這個功能能夠帶來的生產力提升是巨大的。小到普通自媒體工作者的圖文編輯,大到上市公司宣傳海報製作,大模型能夠顯著降低工作成本。而這一切都要建立在AI文生圖應用“好用、能用”的基礎上。
從文生圖應用拓展來看,越來越多的AI應用落地才能真正意義讓“AI時代”惠及到所有人。所以,發展AI應用其實比“卷大模型”更重要。
李彥宏對大模型的觀點也是一以貫之的,他已經不止一次指出,“卷應用”才是大模型發展的方向。其實李彥宏的觀點非常正確,應用越多才能使得大模型更加普惠化,否則只是無根之木,難以長久發展。
在今天的百度世界大會上,李彥宏稱“我們即將迎來AI應用的羣星閃耀時刻”,他還再次強調“超級能幹”的應用比只看DAU的“超級應用”更重要,只要對產業、對應用場景能夠產生大的增益,整體價值就比移動互聯網要大多了。
目前,文心智能體平台已經吸引15萬家企業和80萬名開發者參與,覆蓋應用場景豐富,涵蓋製造、能源、交通、政務、金融、汽車、教育、互聯網等眾多行業。李彥宏稱,“百度不是要推出一個‘超級應用’,而是要不斷地幫助更多人、更多企業打造出數百萬‘超級有用’的應用。”