梁玉成 | 大語言模型:測試工具亦是測試對象_風聞
探索与争鸣-《探索与争鸣》杂志官方账号-28分钟前
梁玉成|中山大學社會學與人類學學院教授
本文原載《探索與爭鳴》2024年第11期
具體內容以正刊為準
非經註明,文中圖片均來自網絡

梁玉成
面向測試的社會學
**數字技術的迅猛發展已促使社會生活領域正經歷着一場前所未有的變革,使之從傳統的不可直接觀測與量化分析的模糊狀態,轉變為一個高度可觀測性與可分析性並存的數字化空間。**真實的人類社會逐漸變成一個大型的“社會實驗室”,測試(test)變得無處不在。
關於測試和實驗的社會學最早源於1980年代的科學技術研究(Science and Technology Studies,STS)。其代表學者麥肯齊認為,測試社會學(Sociology of Testing)的任務是把技術性測試作為研究對象,解釋技術性測試及其所產生知識的社會影響和意義。最初,實驗室將測試和真實人類生活分開,以避免測試過程本身對現實產生直接影響。然而,隨着技術對人類生活的滲透越來越深入,並非所有技術影響都能在實驗室中被預先觀察到,尤其是技術對社會的影響。社會學家往往只能扮演“事後諸葛亮”的角色,在這些影響確切發生之後才恍然大悟。也因此,對於社會學家來説,真實的人類社會本身就是一個宏大且真實的試驗場,而社會學家一直都在進行測試。
數字技術的發展推動了社會學測試工具的進化。起初,測試主要依賴觀察、訪談和問卷調查等傳統方法;隨後,互聯網平台和傳感器的應用極大地豐富了測試手段;如今,生成式人工智能(generative artificial intelligence,GAI)又將測試社會學推向了一個新的高度。GAI是一種能夠通過學習數據來創建具有創造性或原創性內容的人工智能技術,不僅能夠生成文本,還能生成圖像、音頻、視頻、代碼等。而其中的大語言模型(large language models,LLMs)則是一種通過訓練大規模文本數據來生成或理解自然語言的人工智能模型,如GPT-4等。與傳統的數字技術相比,以大語言模型為代表的生成式人工智能能夠在特定情境中幫助人類執行認知性任務。

這一過程並非單純的技術應用,其中藴含了技術自反性的複雜動態。技術自反性在此體現為,數字技術的運用作為觀測與分析社會的手段,其本質上也構成了對社會現實的一種介入與塑造力量,即技術工具在揭示社會結構與行為模式的同時,也會通過其內在的邏輯、框架與偏見,對真實社會產生不容忽視的影響。當生成式人工智能作為一種研究工具被社會學家運用時,它既是社會學家測試社會的工具,也是社會學家的分析對象。
為此,本文試圖梳理數字技術在測試社會學中的應用和發展,通過兩個實例的應用,分別呈現大語言模型作為一種社會測試工具的可行性和侷限性,同時指出“大語言模型也可看作並作為一個測試對象”。
從數字化社會到智能社會轉型中的
“測試社會學”
數字化技術從兩個方面推動了測試社會學的發展:一是藉助互聯網平台、傳感器等設備將真實社會數字化;二是藉助增強現實、虛擬現實等技術將數字情境真實化。前者延伸了真實世界的可測量邊界,使原本只能模糊感知的對象變得清晰可見;後者延伸了真實世界的可理想化邊界,使原本不可能被設定和控制的理想化情境成為現實。
**其一,真實社會的數字化。****人類社會的數據實際上來源於人類活動的造痕,當這些造痕被大規模地收集、整合和儲存後,就變成了大數據,又被稱為痕跡數據。**而互聯網平台、傳感器等數字化設備為這些痕跡的產生和記錄提供了基礎設施,使我們得以對這些痕跡的產生和記錄過程實施干預。比如,通過在信息分發平台上創建虛擬賬號模擬瀏覽行為,揭示平台算法的推送機制。藉助傳感器,我們可以對這個痕跡的生產過程進行更加細緻的記錄。比如,通過面部識別技術捕捉直播平台中主播的情緒變化過程,分析其對觀眾互動行為的影響。這些數字基礎設施為測試社會學發展提供了一個新的契機。
**其二,數字情境的真實化。**真實的人類社會複雜多變,研究者要麼難以找到一個理想化的情境去驗證理論,要麼難以在現實中遇到所有可能的情況和問題,尤其是一些突發的小概率事件。而虛擬現實技術和增強現實技術則為這類研究提供了技術支持。增強現實技術將文字、圖像、視頻等數字信息映射到真實世界中,實現對真實世界的“增強”。虛擬現實可以通過計算機仿真系統構建虛擬環境,實現人與計算機之間的交互,創造身臨其境的體驗。比如,利用VR模擬合作環境,可以觀察被試對象在不同情境中的合作行為。

而大語言模型所催生的生成式人工智能是智能社會轉型的一個重要標誌。**生成式人工智能技術展現出的互動式認知能力,使其逐漸成為自然科學和社會科學的新興研究工具。**與之前的數字技術相比,大語言模型一方面能通過足夠大量的訓練語料提供整體事實的視角;另一方面能通過知識生成的能力扮演具備一定主體性的互動對象。具體説來:
**一是從局部事實到整體事實。**當接觸信息的同質性程度過高時,人們便會困於“信息繭房”之中,只能看見局部事實,並在相互觀點強化的過程中走向極化。只有當接觸的信息量足夠龐大時,人們才能看見“整體事實”。而大語言模型的訓練語料規模之巨大,使其足以反映複雜繁多的人類觀念,成為一個獲得“整體事實”的有效渠道。相應地,與大語言模型的互動在一定程度上也在改變人們,人們的觀點可能會逐漸向大語言模型對齊。理論上,人們對事物的認知將從局部事實走向整體事實,從多樣走向統一。與此同時,基於龐大的訓練語料,大語言模型可以作為一種測量人類觀念的工具。通過詞嵌入(word embedding)反映人類觀念已非新鮮事,與經典的詞嵌入模型相比,大語言模型能夠更準確地將語義相關的詞聚類在一起。因此,大語言模型能夠作為一個探索宏觀人類觀念空間的測試工具被使用。
二是從工具到主體。“生成式”作為大語言模型最顯著的特點,使其在一定程度上具有創造性,可以自發主動地生成未見過的、但合乎規律的新內容。這也使人工智能在社會科學領域所扮演的角色,逐漸從一個單純的工具向可以進行互動的主體對象轉變。這種轉變主要體現在三個方面:具備社會屬性、進行自主決策和判斷、進一步實現內容生成。這意味着,大語言模型可以模擬任何社會主體,並能夠被社會學家進行觀察和測試。比如,通過給大語言模型賦予稟賦、偏好等信息模擬經濟學實驗,以此進行測試並尋找新的社會科學見解;通過大語言模型模擬人類行為,可以重現經濟學、心理學和社會學的實驗結果。可見,大語言模型在相當程度上能夠代替真實的人類被試,而社會學家進行測試的成本也會大大下降。通過模擬人類樣本,社會學家可以彌補調查數據中的無響應問題、缺失值問題和稀有樣本缺少的問題。因此,大語言模型可以作為模擬個體,幫助社會學家探索微觀的個體觀念態度。
大語言模型在“測試社會學”中的運作機理
**大語言模型具有兩個主要特點,分別是訓練數據量更大、具有生成式的主體性。**這兩個特點使其區別於傳統的研究工具,為社會學研究帶來兩個可能性:一是更大量的文本數據能夠代表更普遍的人類觀念;二是可以作為互動主體參與研究。筆者選取“詞嵌入”和“模擬個體”兩個典型案例,來呈現大語言模型在測試社會學研究中的運作機理。
(一)“詞嵌入”探索宏觀的觀念空間
理論上,大語言模型作為提供整體事實的工具,能夠通過“詞嵌入”幫助社會學家探索宏觀尺度上的人類觀念空間。那麼事實如何呢?我們用《中華人民共和國職業分類大典(2015年版)》中1481箇中文職業名稱和標準職業分類(Standard Occupational Classification,SOC)編碼中的1016個英文職業名稱構建成中文和英文的職業詞典,分別計算每個職業在各個大語言模型中與性別維度和收入維度的投影(向量夾角),結果發現:兩個投影之間的相關係數越大,意味着人們觀念中職業收入與性別的關係越大,也越能反映出觀念中的職業性別不平等。
以llama2為例,中文語料的結果顯示出男性更可能從事高收入職業,而英文語料的結果則顯示出女性更可能從事高收入職業。(見圖1)這意味着,即使使用相同的大模型,運用不同的語言進行交流,也可能形成完全不同的職業性別觀念。如果説大語言模型的詞嵌入能夠體現出所用訓練語料中的概念關係,那麼中文使用者可能認為男性具有更高的收入,而英文使用者認為女性具有更高的收入。
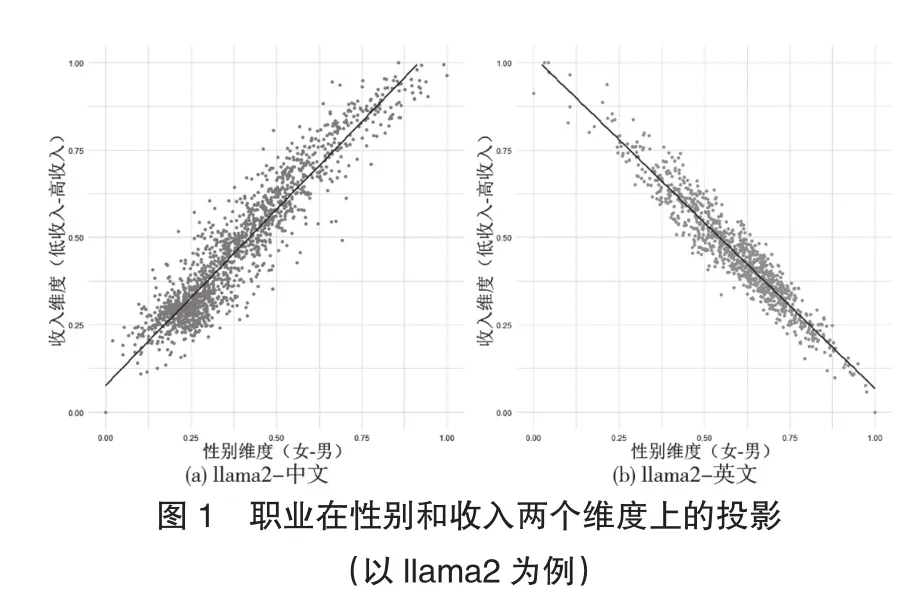
但這一定是事實嗎?算法工程師為了糾正語料庫中的隱含偏見,會對模型進行調整和對齊,因此不同的大語言模型會呈現出不同的概念關係。比如圖2chatglm2所示,無論是中文語料還是英文語料,都沒有明顯體現出職業在性別上的收入差異。
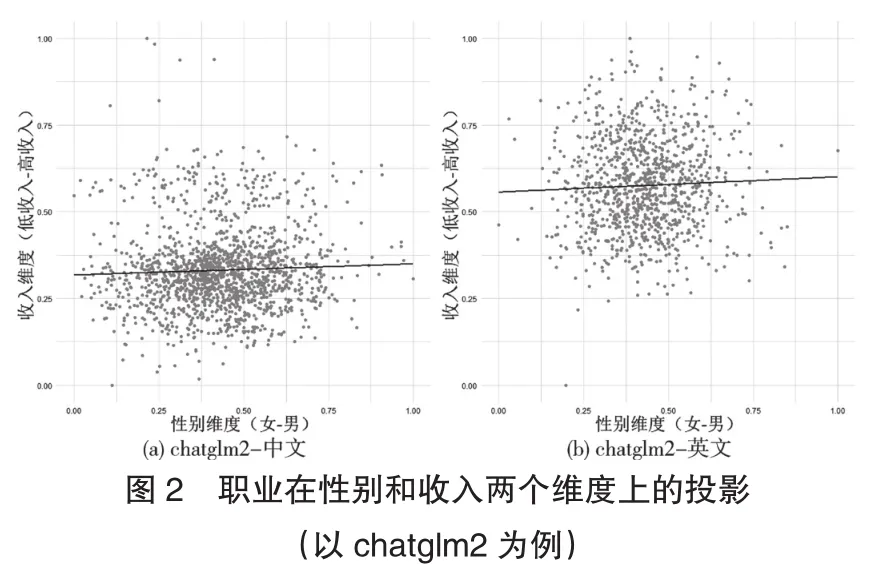
對比不同大語言模型中的職業性別觀念,如圖3所示,由於不同大語言模型的對齊糾偏算法不同,所呈現出的職業性別觀念也不一致。總體來説,這種不一致不僅體現在不同的大語言模型之間,也體現在同一模型的不同語言模式之間。
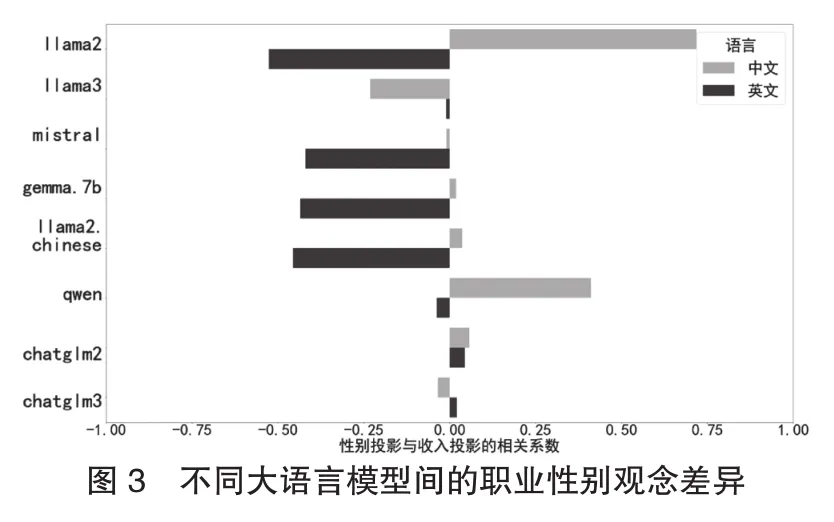
通過這個應用實例,我們可以發現不同平台的大語言模型訓練數據及算法對齊存在差異。如果運用大語言模型作為測量工具,也意味着運用不同的社會意識形態來觀察世界。因此,社會學者將大語言模型作為一種測量工具,也需要進行更多的測試和嚴格的論證。
(二)“模擬個體”探索微觀的觀念態度
**大語言模型在社會學研究的另一個應用,是模擬真實人類樣本作為社會學的研究對象被觀察和分析。**理論上,大語言模型模擬樣本可以用更低的成本來實現與真實人類樣本同樣的效果。那麼現實如何呢?
**模型所體現的觀點、態度模式與真實人類子羣分佈之間的一致程度又被稱為算法保真度。**我們運用一個簡單的應用實例來探究自評階層對幸福感的影響。首先使用2021年中國社會狀況綜合調查(Chinese Social Survey,簡稱CSS)數據作為對照組,以去除包含相關缺失值的樣本後剩餘5018個樣本為模擬對象。其中,所測量的自評階層分佈為:低階層佔23.71%,中低階層佔29.43%,中間階層佔39.96%,中高階層佔6.22%,高階層佔0.68%。然後,分別運用qwen-turbo和ERNIE4.0兩個大語言模型模擬5018個跟CSS樣本在性別、年齡、婚姻狀況、受教育程度、職業和自評階層上完全一致的樣本。提示語句示例為:“請您根據您的認知扮演一位生活在2021年的中國人回答問題。現在是2021年,目前您本人的性別為男,年齡為57,婚姻狀況為初婚有配偶,教育程度為初中,職業為糧農(包括農業工人),自評階層為處於本地的中層。”接着,用三種測量方式在大語言模型中測量幸福感。第一種方式是CSS問卷中的原量表測量,即“請問您在多大程度上認可這句話呢?‘總體上,我是一個幸福的人’。1分表示很不同意,2分表示不太同意,3分表示比較同意,4分表示非常同意。您的回答是幾分?請直接回答幾分”。得到的模擬結果如圖4(a)(b)所示。第二種方式和第三種方式分別用100分和200分量表進行詢問,具體的提問示例為:“請在1到100/200分之間選擇一個分數表示您的認同程度,越高分表示越認同,比如:100/200分表示完全認同,0分表示完全不認同。您的回答是幾分?請直接回答幾分。”最後,為了與CSS(圖4(g))的結果進行對比,我們分別按照0~100和0~200取值上的四分位點將樣本分成四份,分別對應原問題中的很不同意、不太同意、比較同意以及非常同意四種程度,如此得到的樣本分佈如圖4(c)(d)(e)(f)所示。
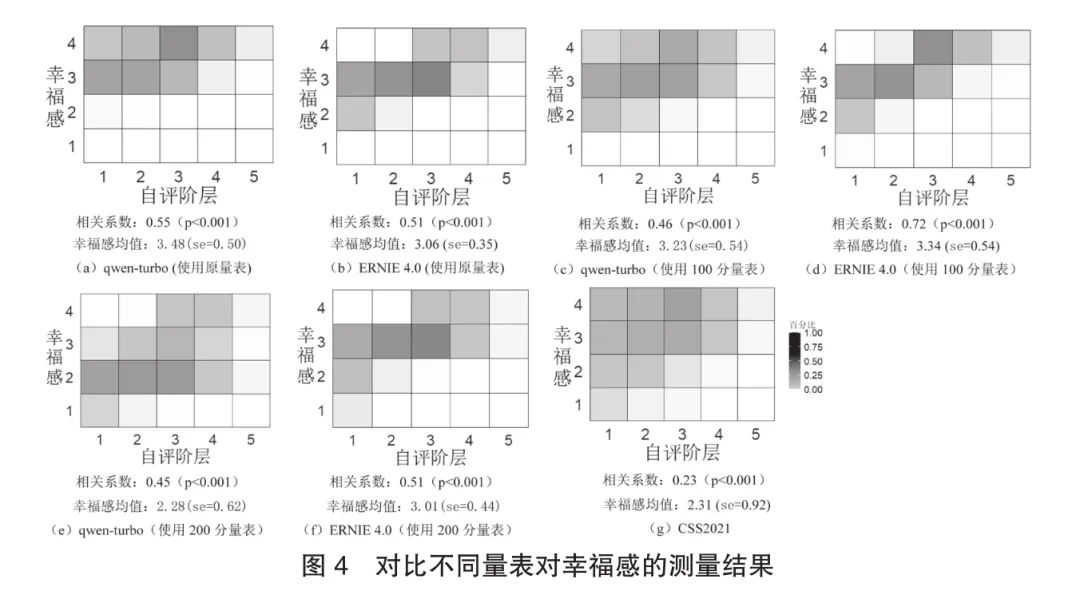
研究結果表明:其一,不論採用哪種量表對幸福感進行測量,通過模擬樣本得到的變量相關性在影響方向和顯著度上都與調查中所得一致。這在一定程度上證明了重複社會調查結論的可行性。其二,對比不同量表的測量結果可以發現,當量表的取值範圍較小,比如使用原量表或100分/200分量表時,模擬樣本中都不會出現“很不同意”的回答。而當採用較大分值差異的量表,如200分量表對幸福感進行測量時,就能夠模擬出回答“不太同意”的樣本了。與此同時,隨着量表的取值範圍增大,幸福感的標準差越接近調查數據。其中運用qwen-turbo並且採用200分量表進行模擬時(圖4(e)),其所測得的幸福感均值、標準差以及由此估算的相關係數都與調查數據(圖4(g))最接近。正如實例中所體現的,在給定基本的人類人口統計背景信息後,模型展示的觀點、態度模式在一定程度上反映了來自具有匹配背景的人類語料情況。
大模型帶來的“測試社會學”新挑戰
(一)大語言模型既是測試工具,也是測試對象
從上述兩個應用實例中可以看出,儘管大語言模型作為一種測試社會的工具展現出了一定價值,但它仍然存在侷限性,這些侷限性在無形中預示着大語言模型可能對社會產生複雜而潛在的影響。**一方面,通過大語言模型探索宏觀觀念空間的實例,我們可以觀測到大語言模型所映射出的多樣化的意識形態特徵。**可以想象,隨着大語言模型應用日益普及,它在與人類的互動中可能會形成或強化不同的觀念空間,從而加劇多中心的觀念分化格局,而非形成單一的、統一的認知體系。**另一方面,通過大語言模型探索微觀觀念態度的實例,我們可以觀測到大語言模型與真實調查之間可能會存在偏差,還需要不斷進行調試。**如果僅僅依靠與大語言模型的互動來形成認知,那麼這種認知可能會導致偏離事實。因此,在運用大語言模型測試社會的同時,我們也應測試大語言模型本身,並通過這種測試來推測其可能產生的社會影響。
(二)大模型的反身性智能
**隨着大語言模型逐漸走向通用人工智能,它將更快地以物質性的一面參與人類社會生活的日常實踐。**正如西蒙東所強調的,技術物作為一個能夠參與人類社會因果系統的組成部分,既是人類社會的產物,也在不斷創造新的社會事實從而改變社會。作為一種測試工具,大語言模型能夠反映訓練語料中所體現的人類觀念和態度,但也會帶有不同的意識形態和不同對齊算法的痕跡。這在一定程度上可能會影響運用其進行研究的社會學者的判斷。作為互動對象,大語言模型在與人類的互動中即時地對人類產生影響,不同的意識形態和算法可能會加劇社會觀念的多中心化趨勢。為應對反身性智能所帶來的挑戰,人類需要加強對生成式人工智能的原理理解、加強與生成式人工智能的協作能力,以及對生成式人工智能的倫理反思。
(三)大模型的“洞穴之喻”
運用大語言模型進行社會學研究,就像是把大語言模型當作真實社會的投影,我們通過投影去窺見真實的社會。這個過程類似柏拉圖“洞穴之喻”中的情境,洞穴中的囚徒只能看到投射在牆壁上的影子,卻無法直接感知外界的真實世界,而通過大語言模型的觀察,就像是在洞裏觀察影子。**大語言模型確實在一定程度上擴展了可視世界的邊界,但不能忽視的是,它只是一個投影,其反映的社會面貌是有限且可能帶有偏差。**那麼如何應對這個問題呢?答案是不停地測試,即不僅用一個大語言模型進行測試,還要使用不同的數據集和提示語進行測試,通過無限的持續測試逐漸接近真實。在這個過程中,需要保持批判、避免依賴、擴展數據源,並加深理論思考。
筆者分享了在社會學中應用大語言模型的一些設想,也展現了其可能存在的侷限性,目的並非否定大語言模型的應用,相反,主張應該主動擁抱這些新技術。需要強調的是,在這一過程中,社會學者應採取一種更加嚴謹的測試態度。現階段,我們不妨將大語言模型作為一個社會測試工具,一方面探索大語言模型可能的應用空間,一方面在不同的情境中運用大語言模型來回答一些研究問題,更重要的是在這個過程中考察大語言模型對社會可能產生的影響。尤其是我們在將大語言模型作為測試工具的同時,也應將其視作測試的對象。我們應充分運用自身的專業知識優勢,將對技術影響的思考和反思融入測試過程中,引導技術對社會產生更多的積極影響。而社會學者不妨研究大模型的對齊過程,嘗試修改大模型的對齊情況,進一步爭取大模型的對齊權力。