2024大模型大浪淘沙,誰是真正的實力者?_風聞
智谷趋势-智谷趋势官方账号-新中产的首席财富顾问。微信500强。31分钟前
當前,人工智能大模型發展一日千里。2024年大模型格局有何變化?最近一份來自國家部委的權威報告,揭示中國大模型最前沿動向。
由工信部直屬的中國互聯網絡信息中心,發佈了《生成式人工智能應用發展報告(2024)》(下稱《報告》),有幾個信號非常值得關注。
截至今年7月,中國完成備案並上線、能為公眾提供服務的生成式人工智能服務大模型數量,已經高達190多個。隨着競爭日趨激烈,一場淘汰賽已經展開。事實上,國內外不少大模型初創公司如Stability AI、Adept、Humane、Reka AI等,都已經在排隊尋求“賣身”。
與此同時,生成式人工智能與製造業、農業、醫療、教育等傳統行業深度融合,推動產業轉型升級,促進新業態、新模式的不斷湧現。
《報告》指出,截至2024年6月,中國已經有2.3億人表示自己使用過生成式人工智能產品,佔整體人口的16.4%。哪些產品最受歡迎?從這份覆蓋了全國3萬網民的大規模抽樣調查結果來看,百度文心一言仍然領跑,在網民中使用率高達11.5%,位居第一。
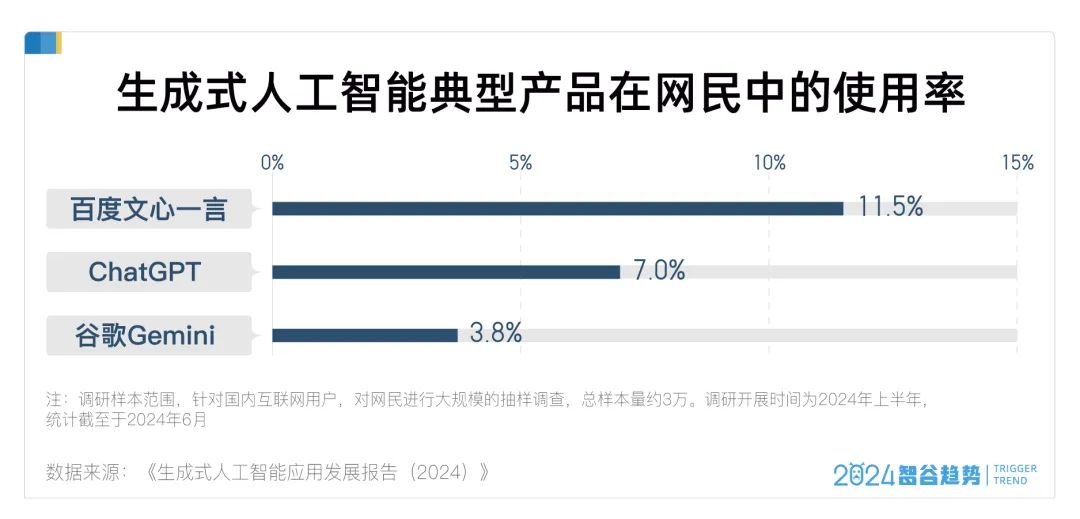
事實上,以百度、阿里、字節跳動等為代表的科技巨頭,憑藉雄厚的資金、充足的人才等優勢,已成為國內大模型的核心玩家,一超多強格局顯現。尤其是百度,最早佈局了文心大模型,投入力度大,關鍵成果多,在多個評測維度位列第一,領先身位明顯。
隨着大模型進入應用爆發期,在贏家通吃的AI江湖,誰能一舉奪魁?這將深刻影響中國人工智能的未來。

抓住最大的金礦
全球大模型競賽中,各大巨頭的核心競爭力是什麼?
天風證券研究所所長趙曉光最近分享了一個觀點:中國經歷了從勞動力紅利到工程師紅利的時代,未來最大的紅利實際上是科研紅利。科研產業化,是最大的金礦、最核心的源頭。
這一判斷在人工智能領域已經體現得淋漓盡致。
技術只有走出實驗室,才能變成科研紅利。對人工智能企業而言,就是要通過科研讓技術應用化,讓AI對無數普通人更友好。
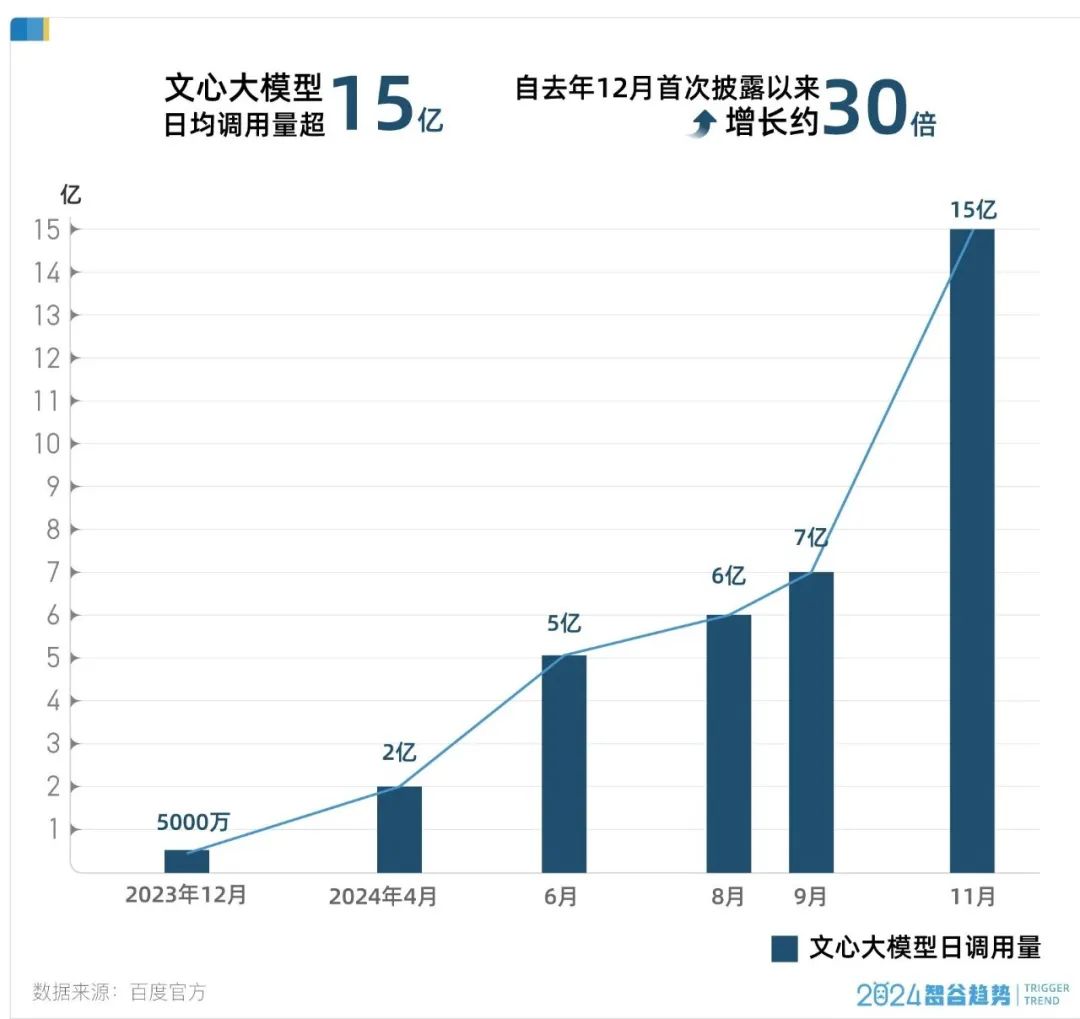
以百度為例,截至11月初,百度文心大模型的日均調用量已經超過15億,相較一年前首次披露的5000萬次,增長約30倍。這條陡峭的增長曲線,正是過去兩年中國大模型應用爆發的縮影。
近日,沙利文發佈的《2024年全球AI生態全景概覽》,百度和OpenAI、谷歌一起,成為了全球唯三被該機構承認的“AI原生巨頭”,也是中國唯一一個榜上有名的公司。
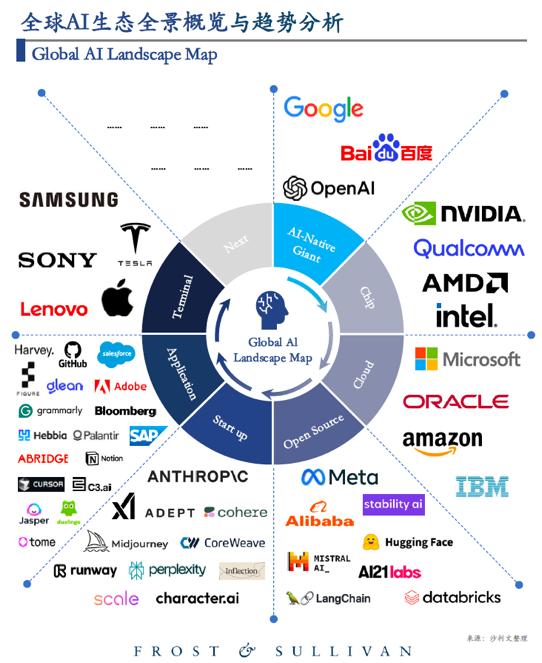
沙利文《2024年全球AI生態全景概覽》報告中,百度與谷歌、OpenAI位於AI-Native Giant 同一象限
百度為什麼能上榜?其關鍵原因,就是用多元化AI原生應用,率先推動“科研產業化”,抓住了人工智能領域未來最大的金礦。抓住紅利的同時,社會千行百業擁抱AI的門檻得以降低,符合國家對發展新質生產力和未來產業的期望。
具體來看,百度降低使用者進入AI的門檻,一個重要方式就是對傳統互聯網應用進行AI重構。比如百度文庫就基於文心大模型重構為“一站式AI內容獲取和創作平台”,具備發佈智能PPT、智能寫作、思維導圖、研究報告、拍圖生文等上百項多模態AI能力。
據不完全統計,百度這兩年推出了不下15款AI產品。這些從傳統互聯網應用升級來的AI應用,拉近了普通用户與AI的距離。就比如一個沒有AI素養的小學生,也可以直接和文心一言用自然語言交流。
從某種程度上説,這才是AI應用該有的樣子。因為技術不僅要成為應用,更要成為真正的“有用”。而人類發展史上對不同新技術的孜孜追求,最終目的就是為了“世界應該是平的”。
百度,就是在用這些簡單、易上手的AI應用,努力填平AI科技鴻溝。
隨着用户對AI應用的接受度越來越高,百度對AI應用有了更進一步的認知。在今年世界大會上,李彥宏強調了AI應用的兩個方向:一是智能體,二是產業應用。
他將智能體視為“AI原生時代,內容、信息和服務的新載體”。《報告》也指出:“以智能體為代表,正成為未來人工智能應用的主流形態”。
目前,百度已經佈局了公司類智能體、角色類智能體、工具類智能體和行業類智能體四大類。
在企業運營領域,比亞迪等企業將智能體應用於銷售、售後領域,為用户提供專業、高效的諮詢服務,其銷售線索轉化率大大提升;
在政務服務領域,中衞慧通利用基層政務智能體幫助村民們解答生活中的各種問題,已覆蓋20個區縣,約3萬名基層政務工作人員正在用大模型服務超千萬居民。
如果説“智能體”降低了我們作為AI產品開發者的門檻,那麼產業應用則拓寬了科技企業技術應用的想象邊界。
截至目前,百度發佈了基於大模型的100大產業應用,涵蓋製造、能源、交通、政務、金融、汽車、教育、互聯網等眾多行業。比如在智慧能源領域,深圳燃氣與百度合作探索將大模型應用於燃氣行業,首次在行業引入視覺大模型,建設智能視頻中台,解決燃氣企業運營場景複雜、識別困難等難題。目前已應用在68個場站、58個營業廳,一期接入視頻超過1000多路,在一線實踐中取得顯著成果。
人工智能向千行百業深入,這符合國家關於發展未來產業和新質生產力的期望。《報告》中指出:“生成式人工智能與實體經濟的深度融合,將打造‘人工智能+千行百業’的產業新格局,形成現代化、智能化的產業體系,促使傳統生產力向新質生產力轉型”。
向新質生產力轉型過程中,科技巨頭必須承擔技術賦能的角色。以人工智能的底層技術和AI原生應用支撐,做各行各業的智能應用和算力供應商,從而帶來生產方式的變革和生產質效的提升。
這樣的融合,對千行百業的發展太重要了。擁抱大模型,就是擁抱新質生產力。

模型升級,始終先行一步
為什麼各行各業的網民,使用文心一言的比例最高?除了應用層的豐富,背後還有很重要的一個原因,從底層模型架構來看,百度模型層的升級始終先行一步。
簡單來説就是,百度具備技術和應用“雙重領先”的競爭優勢。
比如,沙利文發佈的《2024年中國大模型能力評測》中,百度文心一言拿下數理科學、語言能力、道德責任、行業能力及綜合能力等五大評測維度的四項第一,穩居國產大模型首位。
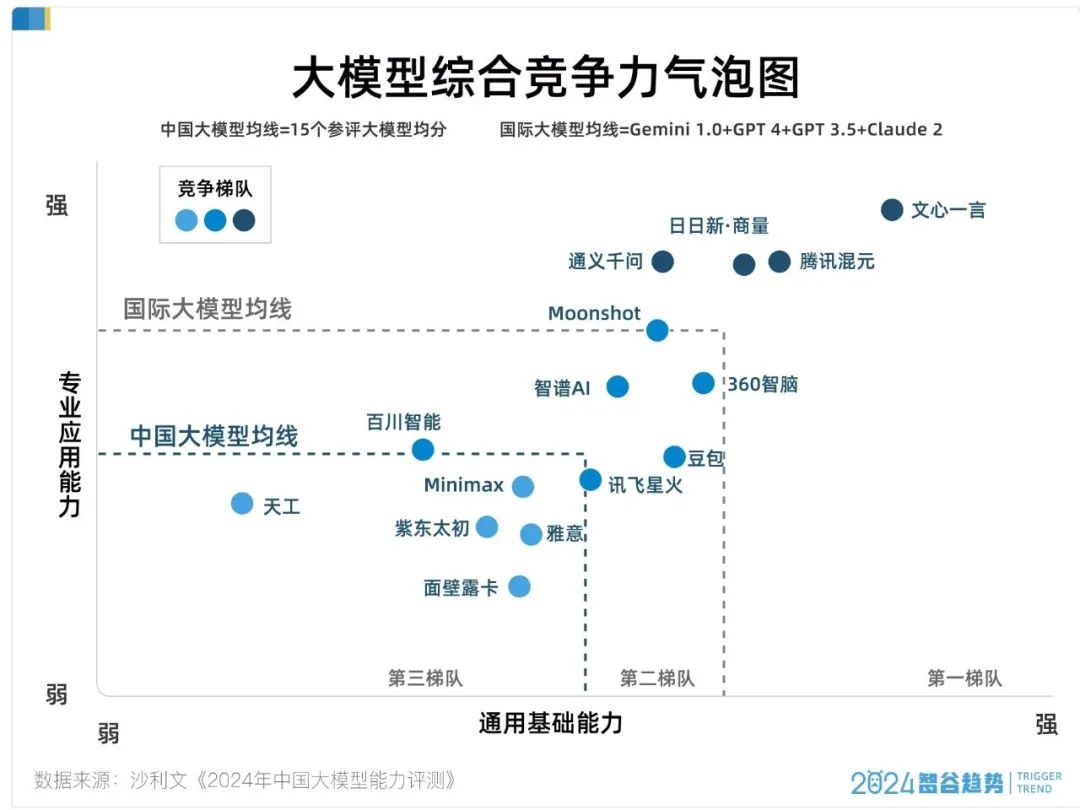
泛摩爾定律行業有一條不成文準則:由於技術迭代週期縮短,領先者並不以進場先後順序和資金規模為轉移。後來者通過押注更新技術,完全有可能超越先行者。但百度似乎打破了這一定律。它不僅是全球第一個推出生成式AI的企業,技術水平也保持領先。
在百度2024世界大會上,李彥宏還提到:大模型的幻覺正在基本消失。
也就是説,一年前,你向聊天機器人提問,不管是查資料、訂票、歷史,你都不敢完全相信它的答案。因為AI有幻覺,可能“已讀亂回”。但今年,我們再提問文心一言,可以明顯感知到AI準確度和可信任度在優化。哪怕是技術含量更高的文生圖,也多了一層寫實感和真實感。
技術水平和應用體驗的雙重提升,帶來用户端的認可與信賴。
再比如自動駕駛之於多模態模型。《報告》指出,多模態能力拓展了生成式人工智能的應用邊界。自動駕駛是新質生產力典型代表,也是多模態大模型的典型應用場景,更是我們觀察百度多模態大模型實力的最佳窗口。
而今年以來,百度的無人駕駛汽車蘿蔔快跑已經掀起了好幾輪熱議浪潮。從最開始被無人駕駛車震驚,再到在行業中深究,百度作為“自動駕駛”技術領先者的身份才完全展露在大眾面前。
很多人都感嘆:“我以為百度還是個搜索引擎,沒想到玩起了自動駕駛。特斯拉沒做到的,竟然百度做到了”。
實際上,蘿蔔快跑已經覆蓋全國10餘個城市,並在多個城市提供了自動駕駛出行服務,在超1億公里實際道路測試里程中,實現0重大傷亡事故。
梳理完百度在大模型應用上的成績,新的問題隨之而來:
為什麼百度在大模型的各個發展階段都能領先,為什麼一眾科技大廠裏,百度最先吃到了“科研產業化”的紅利?

全棧自研的技術底色
這一問題的答案,可以追溯到百度在人工智能研究上的時間起點。
2013年,百度深度學習研究院成立,成為第一個把模擬人腦神經網絡的深度學習提到核心技術創新地位的中國互聯網企業。兩年後,OpenAI的創始人山姆·奧特曼才和馬斯克討論,要成立一家實驗室來抗衡谷歌剛剛收購的DeepMind。
最早入局,奠定了百度在大模型競賽中的先發優勢,持續性的巨大投入則帶來高於時代的技術產出。
從2013到2024的11年裏,百度在人工智能研發上的投入資金超過1700億元,是中國科技公司中對人工智能研發時間最長、投入資金最多的公司。
近期,許多業內人士還爆料,為AI大模型研發提供理論基礎和實操指導的Scaling Law最早源於百度。“大多數人不知道,關於Scaling Law的原始研究來自2017年的百度,而不是2020年的OpenAI”。

換句話説,百度在人工智能領域的起跑時間,甚至早於OpenAI,這也為它後來成為全球第一家推出生成式AI產品的企業提供瞭解釋邏輯。
早入局、高投入,最終所追求的目標是產品技術的全鏈路自研,這決定企業在AI競賽上能否不依附外界,獨立自主搞AI。
從芯片層的崑崙芯、框架層的百度飛槳、到模型層和應用層,百度的AI全棧佈局擁有中國首個全棧自研的基礎設施,也是中國第一個擁有全棧AI技術架構的企業。
完全自主可控的技術讓百度在大模型的核心戰場上有更大的自信和行業不可比擬的優勢,這也是為什麼在許多關鍵技術節點,第一個實現突破的中國大模型企業往往是百度。
比如,2024年最火熱的大模型技術“慢思考”能力。今年9月,OpenAI發佈的o1大模型,可以處理相對複雜的推理任務,帶來全球AI行業的新高潮。但是,早在o1發佈將近1年前,百度已經預判性提出“慢思考”能力,提出以內容生成即時性為主導的系統1,搭配以具備理解、規劃、反思和進化能力系統2的技術路線。
今年,多智能體寫作已經在文心大模型體系中有了技術落地。
再比如,“消除大模型幻覺”,是催生AI應用爆發的技術前提。幾乎所有大模型廠商都想攻克這一難題,但在IDC、沙利文和中國軟件評測中心等多家機構的調研數據裏,位居中國第一、國際第一梯隊的始終是百度文心大模型。
百度為解決“大模型幻覺”,研發了“理解-檢索-生成”協同優化的檢索增強技術(iRAG技術)。李彥宏還在世界大會現場發佈了最新成果——檢索增強的文生圖技術iRAG,將百度搜索的億級圖片資源和強大的基礎模型能力結合,可以生成各種“去掉了機器味”的超真實圖片。
為什麼百度在今年大家都卷類Sora產品的時候,選擇先解決模型幻覺問題?
這也是因為百度在AI佈局上的全棧自研,讓它獲得更大的自主選擇權。在全行業都朝着一個賽點競爭的時候,百度有實力也有餘地去做它所認為的“更值得去做的事”。
在今天內卷加劇的大模型賽道,也只有技術完全自主可控並保持領先的企業,可以選擇不隨波逐流。因為它們不是跟隨者,而往往是革新者。
所以,入局早奠定基礎、高投入輸送動力,由此持續領先的自研技術,才是百度文心一言強勢領跑大模型領域的最核心要素。

結語
行業洗牌期,領先的自研技術其實也是決定中國大模型能否彎道超車的關鍵。
科技巨頭們從不缺少資金,但真正領先的自研技術如同厚重綿延的長城,絕不是一天能建成的。未來AI應用的大爆發,更需要強大的技術實力探路鋪路。而隨着西方國家對中國高新技術的“圍追堵截”,註定中國大模型產業不能再走“市場換技術”的老路。
彎道超車的辦法,唯有自力更生。
從這個角度來説,百度用超過10年的科研深耕、技術積累,為中國的大模型企業闖出了一條新路——依靠完全獨立自研,也能向世界一流水平看齊。這種十年磨一劍的科研精神與核心技術,才能夠真正帶來屬於我們的AI自信。
正因如此,不論是起步的大語言模型,還是今天主流應用形態的智能體,亦或是未來具有無限應用場景的自動駕駛,在多個評測維度位列第一的百度,都可以説是大模型戰場上具有絕對實力的核心玩家。
從它的佈局中,我們能看見中國大模型潮水湧動的方向。