2024年AI行業重塑之道_風聞
融中财经-股权投资与产业投资媒体平台。1小时前


人工智能大模型是指利用深度學習算法讓計算機從複雜數據集中自動提取關鍵特徵並做出精準決策的具有龐大參數規模的模型。
人工智能大模型可以分為通用大模型及行業大模型兩種類別,通用大模型是指使用通識類數據對模型進行訓練,使模型具備包括多語言工作能力、廣泛學科的基礎知識及邏輯推理能力等泛化內容任務解決的能力。行業大模型是指使用專項領域數據對模型進行訓練,使模型提取出該專項領域規律並具備專項領域任務解決能力。

(1)Transformer算法奠定大模型基礎
當前主流大模型普遍是基於Transformer算法進行設計的。Transformer的核心優勢在於具有獨特的自注意力(Self-attention)機制,能夠直接建模任意距離的詞元之間的交互關係,解決了循環神經網絡(RNN)、卷積神經網絡(CNN)等傳統神經網絡存在的長序列依賴問題。
(2)規模定律助推大模型智力湧現
“規模定律”描述了模型的表現與其參數規模之間呈現冪律關係,即隨着模型參數規模的增加,模型在各種任務上的表現會隨之提升。
“湧現能力”是指當模型的參數規模達到一定程度時,某些任務處理的能力會出現爆發性的增長,併成為大模型性能突破的關鍵。
圖 1規模定律中大模型能力的呈現

信息來源:Emergent Abilities of Large Language Models,2022

(1)參數規模競爭為頭部競爭主基調
近年來,以Open AI、谷歌為代表的行業頭部大模型廠商仍在發掘“規模定律”(Scaling Law)所能帶來的能力提升,通過將模型參數的持續擴張以提升模型的任務處理能力,人工智能模型的計算使用量呈指數級增長。
圖 2 AI大模型的參數量變化

信息來源:Artificial Intelligence Index Report,2024
根據圖3所示,過去大模型進行訓練投入的訓練成本隨着訓練數據的持續增長而呈現巨幅增長的態勢。
圖 3 AI大模型的訓練成本對比

信息來源:Artificial Intelligence Index Report,2024
(2)多模態能力成為發展趨勢
當下人工智能大模型的多模態交互正逐漸成為未來的發展趨勢。表1展示了當下多模態模型按工作原理進行的分類,並展示了各種多模態大模型的工作原理。
表 1 多模態大模型的實現方式

信息來源:Multimodal Foundation Models:From Specialists to General-Purpose Assistants,2023
除了大模型朝向多模態方向發展以外,其多模態工作的能力也在不斷深化。以圖4所示, Claude 3.5 Sonnet 相比前一代在根據文字需求改進代碼的測試中可以解決26%的更多問題。
圖 4歷代Claude 模型解決編程問題情況對比

信息來源:Claude 3.5 Sonnet Model Card Addendum,2024
(3)人工智能向全行業滲透
根據中國工業和信息化部信息,截至2024年7月30日,全國已備案的AI大模型為197個;其中通用大模型、行業大模型數量分別為61、136款,佔比分別為31%、69%;行業大模型為目前AI大模型的主要開發方向。
圖 5 全國備案大模型的行業分佈
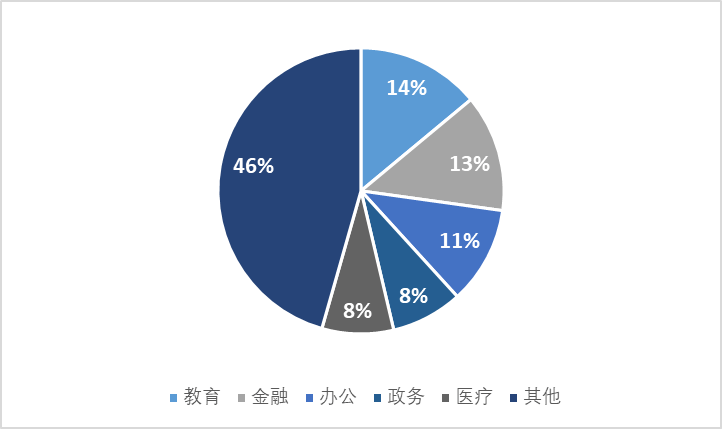
信息來源:國家互聯網信息辦公室
根據中國工業和信息化部信息,教育及金融行業是目前行業大模型開發中最受關注的兩個領域。此外在辦公、政務、醫療領域中,已備案的AI大模型的數量亦有着較大的比重。

根據中國工業和信息化部賽迪研究院數據,2023年中國語言大模型市場規模為132.3億元,預計2027年中國語言大模型行業市場規模將達到600億元。
圖 6 中國大模型行業規模,2022-2027E
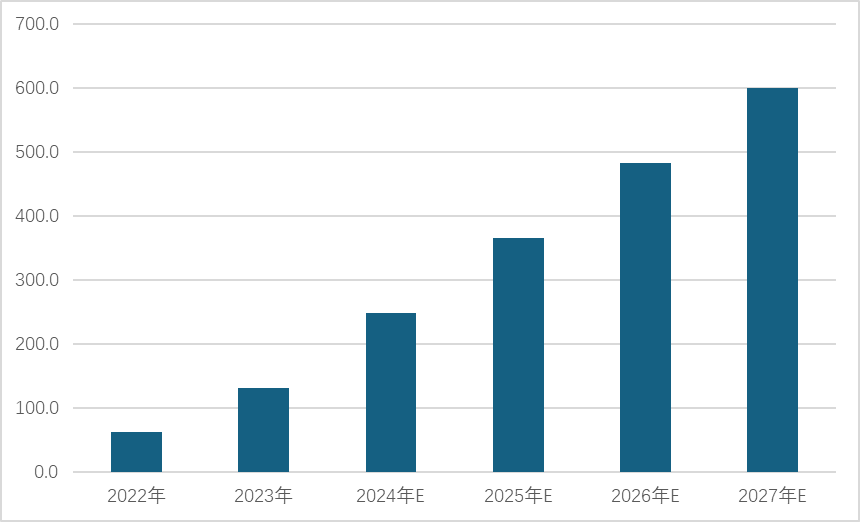
信息來源:中國工業和信息化部賽迪研究院,環球網

人工智能的發展可以看作是新一輪工業革命的開始,本章將把人工智能與傳統生產方式中的主要工作場景進行對比分析。
(1) 人工智能內容獲取場景前景分析
在內容獲取的服務能力上,人工智能已展現超越人類專家的知識水平,“消費電子+”成為行業趨勢。
在人工智能知識能力的測試方面,谷歌團隊發佈的測試顯示OpenAI o1在專業知識測評中對專業問題的解答準確率要高於相關領域的專家,展示了頂尖語言大模型在部分專業領域的知識已達到甚至超過人類博士水平的現狀。
現階段,人工智能較為熱門的落地方向之一便是可穿戴電子產品與AI的結合,相關AI電子產品包括AI耳機、AI手機、AI眼鏡等。
圖 7博士水平科學問卷完成情況(GPQA Diamond測試)

信息來源:openAI
(2)人工智能創作場景前景分析
在創作場景的服務能力上,人工智能已具備略優於人類的創造性,但對人類創作的替代能力仍不足。
2024年2月份,阿肯色大學團隊對人工智能的創造性進行測試,結果表明人工智能大模型在需要開創性思維的創作類工作中已具備匹敵甚至超越人類工作者的基礎條件。
現階段的應用情況,人工智能在文本創作上已被較多嘗試;在視頻創作上,AI視頻創作的難點在於大模型對物理規律的理解;在編程能力上,前沿大模型距離人類專業工作者的水平仍有差距。
(3)人工智能交互場景前景分析
在交互場景上,人工智能具備多模態的擬人化交互能力。現階段以GPT-4o模型和谷歌的Project Astra為代表的人工智能模型都實現了跨模態的即時推理功能。除了多模態交互能力以外,人工智能大模型還展現了情感感知能力。
(4)人工智能行業場景前景分析
在行業應用場景上,人工智能可替代或輔助人類在傳統工作場景的職能,實現人力成本的降低及效能的提升。
在金融應用場景上,人工智能可幫助機構搭建AI客服系統,提供全時段的問題解答與業務辦理等服務。在金融領域的中後台及保險行業,人工智能亦有充分應用場景。
在政務應用場景上,一方面人工智能可以基於政務數據庫,在政策的制定、社會數據的監控等方面提供智能檢索、分析、決策設計等功能。在對公工作方面,人工智能亦有充分應用場景。
在醫療應用場景上,人工智能可以輔助醫生進行疾病診斷工作、根據醫生的診斷決策,提供多種方案的用藥建議;在藥物研發方面,人工智能主要應用在靶點發現、化合物的設計與篩選上亦有所為。
人工智能在其他的行業應用場景還包括自動駕駛、AI質量檢測等對傳統人工環節的滲透或替代。

(1)解決方案:“提示工程”引導模型輸出更專業
提示工程是使模型回答更加專業化的一種解決方案,其在通用大模型現有的數據及參數基礎上提供專業的“思維引導”,這些“思維引導”通常通過挑選出的提示語言來實現,在提示語言的引導下最終使大模型輸出與專業領域要求更相關且更準確的內容。
圖 8 提示詞工程的運行步驟

信息來源:LARGE LANGUAGE MODELS ARE HUMAN-LEVELPROMPT ENGINEERS,2023
(2)解決方案:“預訓練”創造行業大模型
使大模型針對特定行業亦具備專業工作能力的解決方案之一便是使用包含行業數據集的語料庫對語言大模型進行預訓練,最後可得到專業處理能力遠超普通基礎大模型的行業大模型。
預訓練方法的應用主體除了包括對數據保密要求較高的企業,還適用於與現有大模型差異較大的場景,以更好地提升行業解決能力。
(3)解決方案:“精調”對模型進行局部調整
精調是指對已訓練好的通用大模型參數進行針對於目標行業任務的調整,將行業數據集用於再次訓練大模型,最終使通用大模型具備更豐富的行業數據積累以及專項問題解決能力的方法。與預訓練相比,精調方式減少了訓練時間,通常只需要對模型做局部調整,所需的訓練數據也相對較少,是一種更為經濟高效的方法。
圖 11預訓練與精調的對比

信息來源:公開資料整理
(4)解決方案:“RAG”外掛數據庫拓寬模型行業知識
RAG通過在通用大模型原有基礎上外掛目標行業知識庫,能為基礎大模型提供海量的行業數據信息輸入,繼而將基礎大模型的通用任務解決能力與海量專業知識相結合,形成具備解決專業領域任務能力的行業大模型。RAG架構解決方案適用於具備豐富數據資源基礎的企業,通常應用於特定行業的人工智能客服問答、內容查詢及數據處理等任務。
圖 12 RAG技術的實現步驟

信息來源:公開資料整理

百度
最近10年,百度在深度學習、對話式人工智能操作系統、自動駕駛、AI芯片等前沿領域投資,使得百度成為一個擁有強大互聯網基礎的領先AI公司。
百度自然語言處理以『理解語言,擁有智能,改變世界』為使命,致力於研發自然語言處理核心技術,打造領先的技術平台和創新產品,服務全球用户,讓複雜的世界更簡單。產品方面,百度擁有NLP能力引擎、開發平台文心、智能對話服務與定製平台 UNIT、百度輸入法和百度智能翻譯。
騰訊
在NLP方面,騰訊雲 NLP 服務深度整合了騰訊內部的 NLP 技術,提供多項智能文本處理和文本生成能力,包括詞法分析、相似詞召回、詞相似度、句子相似度、文本潤色、句子糾錯、文本補全、句子生成等。滿足各行業的文本智能需求。
科大訊飛
科大訊飛在自然語言處理領域的相關產品有訊飛聽見、訊飛輸入法和訊飛星火大模型。基於以語音交互為核心的智能語音技術,上述產品可以完成文本朗讀、語音合成、語音識別、中文自動分詞、詞性標註、句法分析、自然語言生成、文本分類、信息檢索與抽取、文字校對、問答系統、機器翻譯、自動摘要等功能。
圖表 10 科大訊飛融資歷程

資料來源:企查查、融中研究整理
拓爾思(300229)
在自然語言處理領域。拓爾思有智語·自然語言處理引擎。該引擎提供非結構化數據結構化、賦能語義智能分析和支持構建知識圖譜或本體知識庫三大功能,面向智慧專利、智慧公安、智慧政務、智慧金融、開源情報分析等應用場景,以先進的NLP技術為用户的業務應用賦智賦能。
圖表 11 拓爾思融資歷程

資料來源:企查查、融中研究整理
思必馳
思必馳自然語言處理技術,專注於智能對話中的大規模、可定製語義理解解決方案和實體識別、語義角色分析、信息抽取等自然語言技術。
圖表 12 思必馳自然語言處理核心優勢

資料來源:融中研究整理
圖表 13 思必馳融資歷程

資料來源:36氪、融中研究整理
追一科技
自然語言處理(NLP)方面,追一科技在大規模預訓練模型、自然語言智能交互(NL2X)、NLG(自然語言生成)等領域屢有創新,並將技術成果開放給業界,持續推動NLP技術的發展。在未來元宇宙時代,NLP技術有着極大的應用潛力,致力於成為元宇宙對話交互技術基礎設施提供者。
圖表 14 追一科技融資歷程

資料來源:36氪、融中研究整理
香儂科技
在自然語言處理方面,香儂科技以深度學習算法和神經網絡模型,解讀億萬文本和圖像,精準呈現關鍵信息。採用由語言學家自研設計的文本標註系統,持續進行大規模數據標註和流程優化;採用並行超算平台和大黃蜂深度學習框架,顯著提高NLP算法開發效率;採用BERT等深度學習最新模型,並在算法上持續優化和突破。香儂科技深耕NLP,提供行業領先的信息處理的全新解決方案。
圖表 15 香儂科技融資歷程
資料來源:36氪、融中研究整理
出門問問(2438.HK )
出門問問擁有行業領先的AI基礎設施能力、前沿通用大模型能力(自研大模型「序列猴子」),以及豐富的垂直領域軟硬結合的優化算法技術模塊,是為數不多的同時服務於消費者、企業、創作者三大類不同羣體的公司。
圖表 16 出門問問融資歷程

資料來源:36氪、融中研究整理
零一萬物
在自然語言處理技術方面,零一萬物走的是自主研發大模型的道路,已經完成了百億參數級別的內部測試,並計劃在未來將模型規模提升至300到700億參數。此外,該公司還計劃推出開源的模型版本,與社區共享技術成果。零一萬物的願景是不僅僅做通用大模型,還要做能夠處理圖片、視頻、3D等多種數據類型的多模態模型。
圖表 17 零一萬物融資歷程

資料來源:36氪、融中研究整理
月之暗面
月之暗面的主要業務集中在開發和推廣大模型技術,特別是在自然語言處理(NLP)領域。公司在大模型長上下文窗口技術上取得了新的突破,其自研的Kimi智能助手已支持200萬字超長無損上下文,並開啓了產品內測。
圖表 18 月之暗面融資歷程

資料來源:天眼查、融中研究整理
主線科技
表 2主線科技最新輪股權投資信息

信息來源:融中數據庫
在港口無人駕駛方面,主線科技的無人駕駛方案設計出“多交通參與者混行博弈算法”,旨在解決無人駕駛車輛在港口運輸所面臨的交通參與者複雜、道路不明晰等痛點,在結合自身成型的無人駕駛商用車體系、物聯網、大數據等技術後可為現存港口運輸實現全域智聯的無人駕駛技術升級。
深勢科技
表 2主線科技最新輪股權投資信息
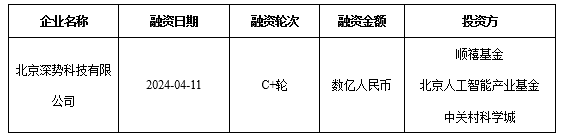
信息來源:融中數據庫
在醫藥人工智能方面,深勢科技藉助自研藥物計算設計平台,能夠提供一站式藥物設計解決方案。該平台覆蓋了從蛋白結構解析、靶點發現和確證、虛擬篩選、先導物優化到藥代動力學預測等臨牀前藥物設計的全部階段,利用自研核心算法在精度和效率上實現重大突破。