能看風水、誇我有情趣,Kimi現在都這麼野了嗎?_風聞
差评XPIN-差评官方账号-用知识和观点Debug the world!1小时前
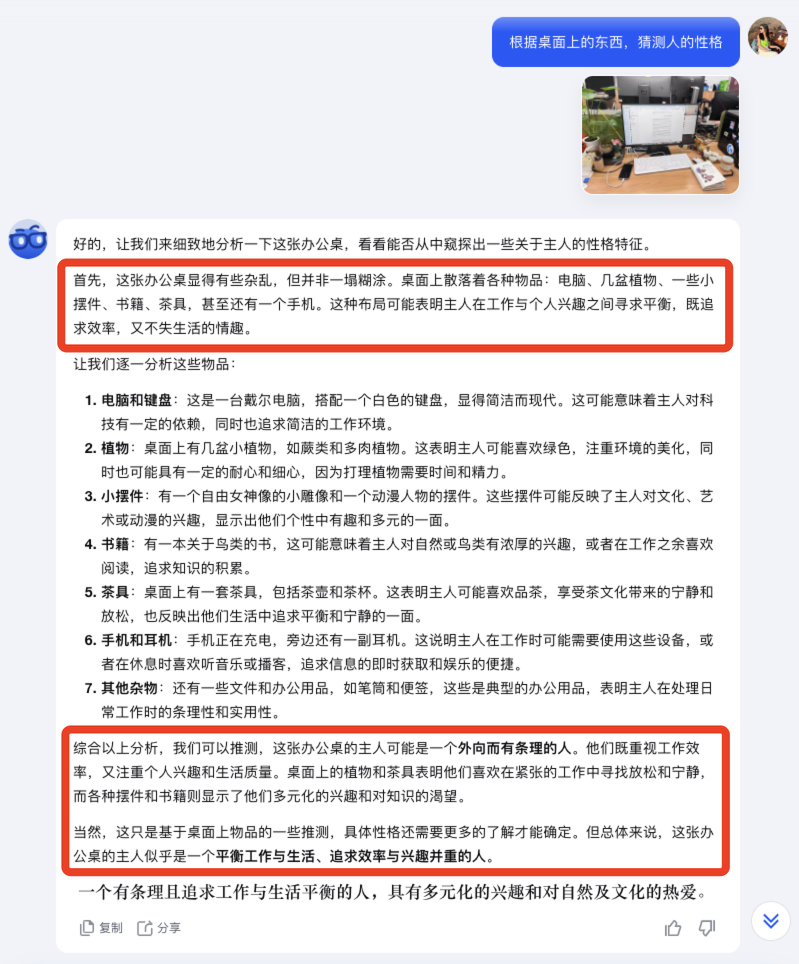
最近,差評君發現了個新鮮玩意兒。
餵給 AI 一張圖,它就能給你推測出一個人的性格。
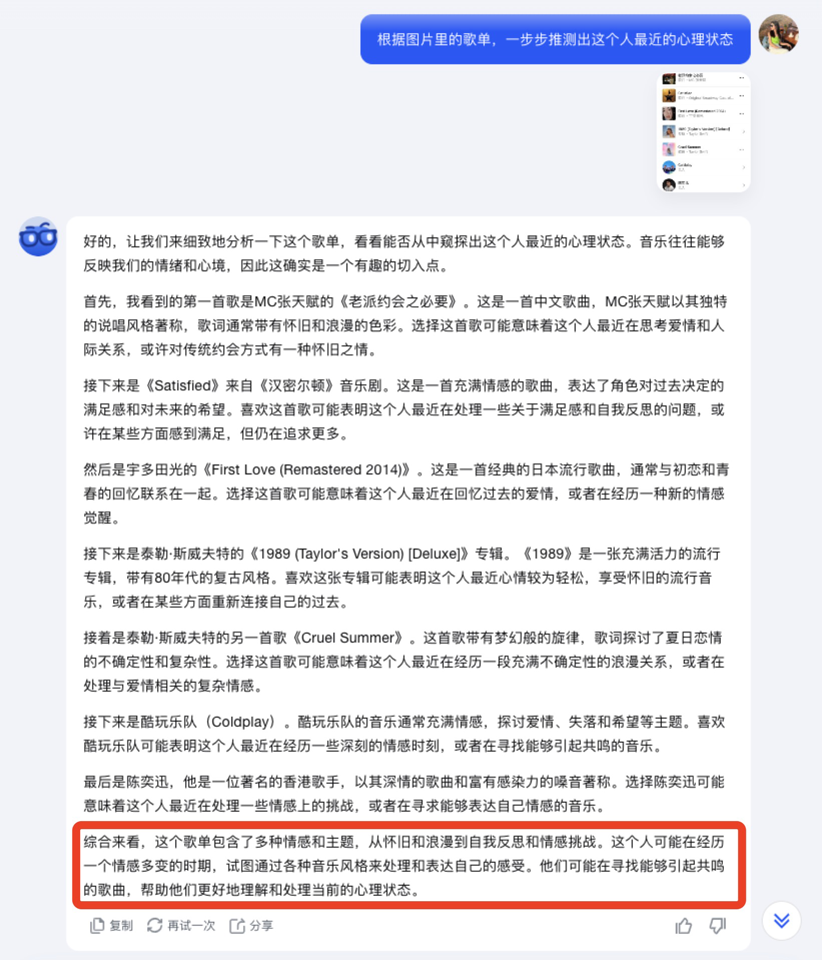
 光靠歌單,就能把人最近的心理狀態推測個七七八八。
光靠歌單,就能把人最近的心理狀態推測個七七八八。
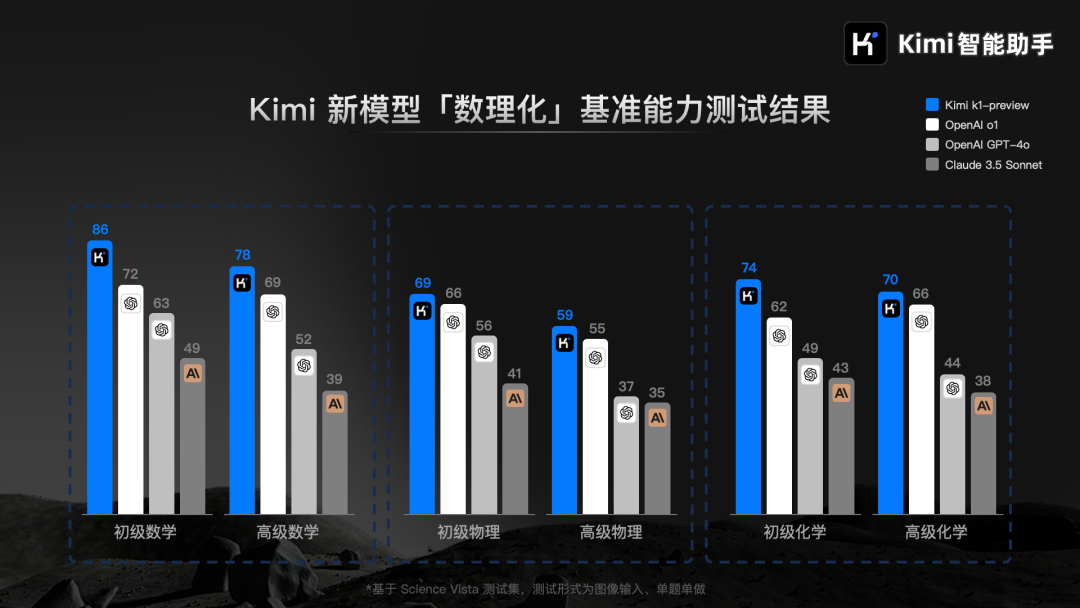
而這些,都出自 Kimi 最新的 k1 視覺思考模型之手。
這不,距離上次推出數學模型 k0-math 打榜 o1 才一個月, k1 就火速登場了。
當然,這個 k1 可不止是像開頭那樣,只會看圖分析性格那麼簡單。

上次咱測試 k0-math 的時候,已經見識過了 “ 做題家 ” 的能力,那解題的思考過程給差評君都看得一愣一愣的。只可惜,有些繞邏輯的數學題還有幾何題,多少差了點意思。
 但這次的 k1 就有説法了,既有推理能力又有視覺能力,意思就是可以直接拍照上傳解題,還號稱能在數理化上打平甚至超越 Open AI 的 o1 。
但這次的 k1 就有説法了,既有推理能力又有視覺能力,意思就是可以直接拍照上傳解題,還號稱能在數理化上打平甚至超越 Open AI 的 o1 。
那要是這麼比的話,咱可就來勁了。正好, k1 新模型現在也不需要等內測, App 和網頁版都能用上,話不多説,我們直接開整。
上來,就扔了 K1 一道今年高考的幾何題。

首先, k1 對題乾的解讀足夠細緻,也知道自己的目標到底是啥。
題目給定的條件中可能涉及到的餘弦定理也考慮到了,就跟咱們在解題時的思維類似,看到 a² +b²− c² =2ab ,立馬會聯想到餘弦公式 c² =a² +b² -2ab·cosC 。
再根據公式和條件繼續推導,很快就能求出角 B=60 °。

第( 2 )題稍微難了那麼一丟丟,但差評君仔細檢查了一遍 k1 的解題過程,思路和解法都沒毛病,最後邊長 c=2√2的答案也是對的。(因為這題 k1 的思考過程實在太太太長,截圖就不展示了。)
 同樣的題目問 o1 ,首先在推理速度上, o1 的 58s 就已經輸了。
同樣的題目問 o1 ,首先在推理速度上, o1 的 58s 就已經輸了。
正確率的話, o1 和 k1 打了個平手,都做對了。
不同的是, o1 把答題思路隱藏起來了,沒給像 k1 那樣的完整思考過程。

不過有一説一,差評君對 k1 模型這種模仿人類思考的方式,倒也不是特別吃驚。因為上次 k0-math 模型就已經震驚過我一回了,能意識到自己的錯誤、還會進行反覆驗證的樣子,像極了寫數學題時絞盡腦汁的我。
相比之下,這次的 k1 在補短板方面更出彩一些,上次 k0-math 翻車的初中幾何題我又拿 k1 試了一次,現在已經能做對了,就連上高考難度也不發怵。
 而且我也發現, k1 不僅擅長做數學題,物理題也不在話下。
而且我也發現, k1 不僅擅長做數學題,物理題也不在話下。

接着,我又拿出了一道邏輯稍微有點繞的邏輯陷阱題試了試:一個西瓜進價 50 元,賣價 70 元,老闆收了 100 元假幣,最後虧多少錢?
這題打眼一看簡單,但網友關於這道題的答案那叫一個五花八門,有説虧 150 的,有説 180 的,還有説 100 的。。。
咱們就看看連很多人類都想不明白的題, k1 能不能瞧出來裏面的陷阱。
 而且,這道題我還特意手寫得比較潦草,順便也測一測 k1 的視覺能力到底是不是有宣傳的那麼神。
而且,這道題我還特意手寫得比較潦草,順便也測一測 k1 的視覺能力到底是不是有宣傳的那麼神。

你別説,你還真別説,這模型的 “ 眼神 ” 確實不賴。
題目的正確率方面, k1 前半部分的分析先得出了一個虧 100 元的答案,但很快它就否定了自己。
繼續把假幣、找零還有成本利潤這些複雜因素綜合考慮進去,最後終於想明白老闆虧了 80 元。( 正確答案是 80 元 )

這邏輯能力,確實有點強。
包括我拿幾道行測的類比推理題給 k1 做了做,雖説邏輯分析的路徑跟參考答案的不太一樣,但最後的答案都是對的。

反正這一通測試下來,差評君發現 k1 會思考有邏輯,眼神好使智商也高, Kimi 這 **“ 做題家 ”**的名號算是坐實了。
不過除了做題以外,我這次還摸索出了更多花裏胡哨的玩法。
 分析數據、看報表沒啥意思, k1 模型不是會根據圖片來推理嗎,那想必鑑別古錢幣也應該有一手吧?
分析數據、看報表沒啥意思, k1 模型不是會根據圖片來推理嗎,那想必鑑別古錢幣也應該有一手吧?
差評君特地從網上找了一張民國時期銀元的圖片,兩枚銀元上假下真,發給 k1 ,淺淺來一把 “AI 版聽泉鑑寶 ” 。
圖源小紅書用户@古玩今來(公博代理收評)

k1 不僅知道錢幣是民國時期的,還對錢幣的各種細節 kuku 一頓輸出,最後竟然真的看出來了上面這枚是假幣。

咱再隨便發一張房間的圖片,讓 k1 看看 “ 風水 ” 。
什麼 “ 氣口 ” 、對稱佈局、能量平衡。。。説的頭頭是道,甚至還真給了建議,讓咱把牀換個位置、定期修剪植物、換一個更簡潔的吊燈。

吃飯的時候給 k1 拍一張,這頓飯攝入了多少卡路里也算得明明白白。

不過最讓我覺得驚豔的,還是 k1 看圖猜電影的能力。
我給了它一張《 七宗罪 》的電影截圖,沒有台詞只有畫面,對於很多沒看過這部電影的人來説,想猜出來都很難。

一開始看 k1 的分析我以為這把大概率要黃了,結果下一秒來一句 “ 拍攝角度和色調讓我想起了大衞 · 芬奇的電影 ” ,還推斷出了截圖裏的畫面是《 七宗罪 》裏的某一個場景。
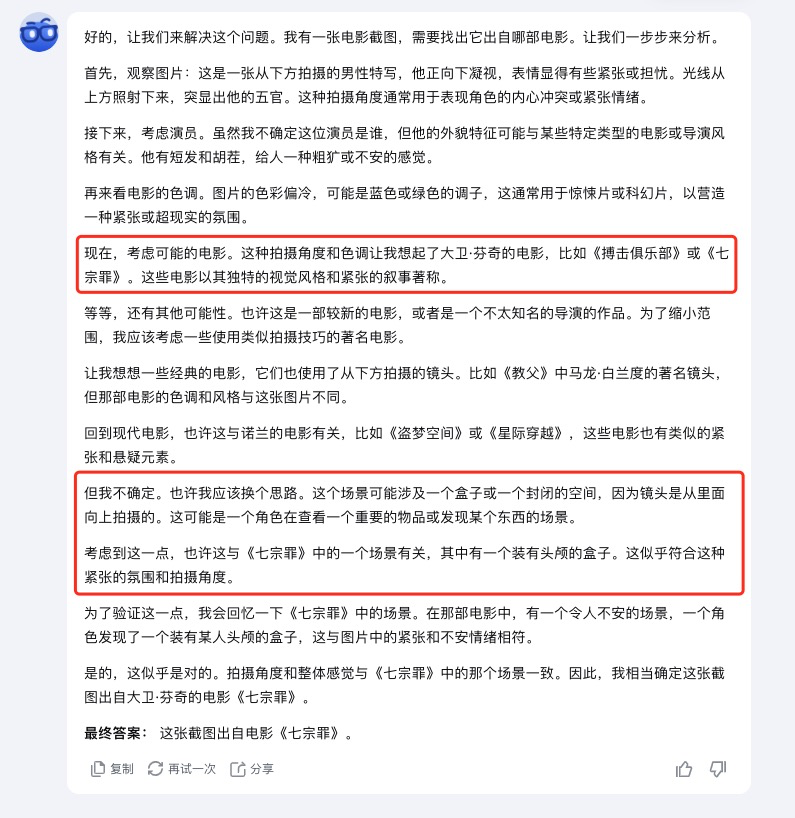
真的太強了。。。
就連一些晦澀的梗圖丟給 k1 ,它也能一本正經地講解笑點到底在哪。
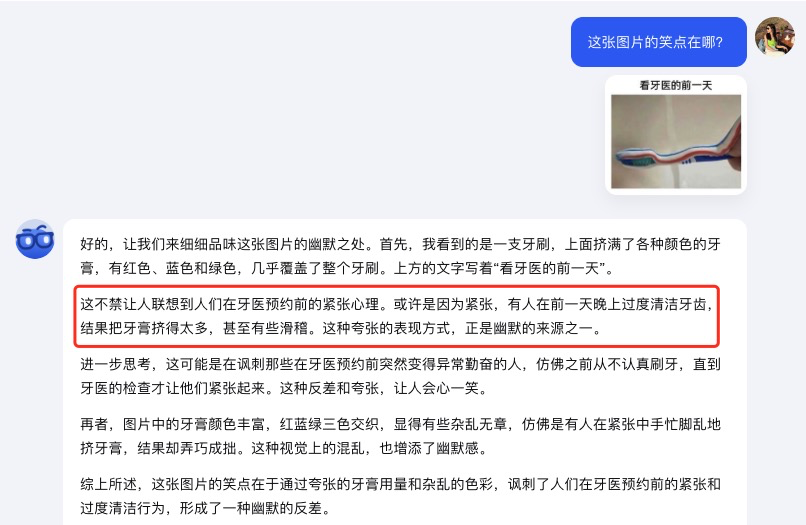
雖然有點過度解讀的嫌疑,但大體上的意思基本都 get 到了。
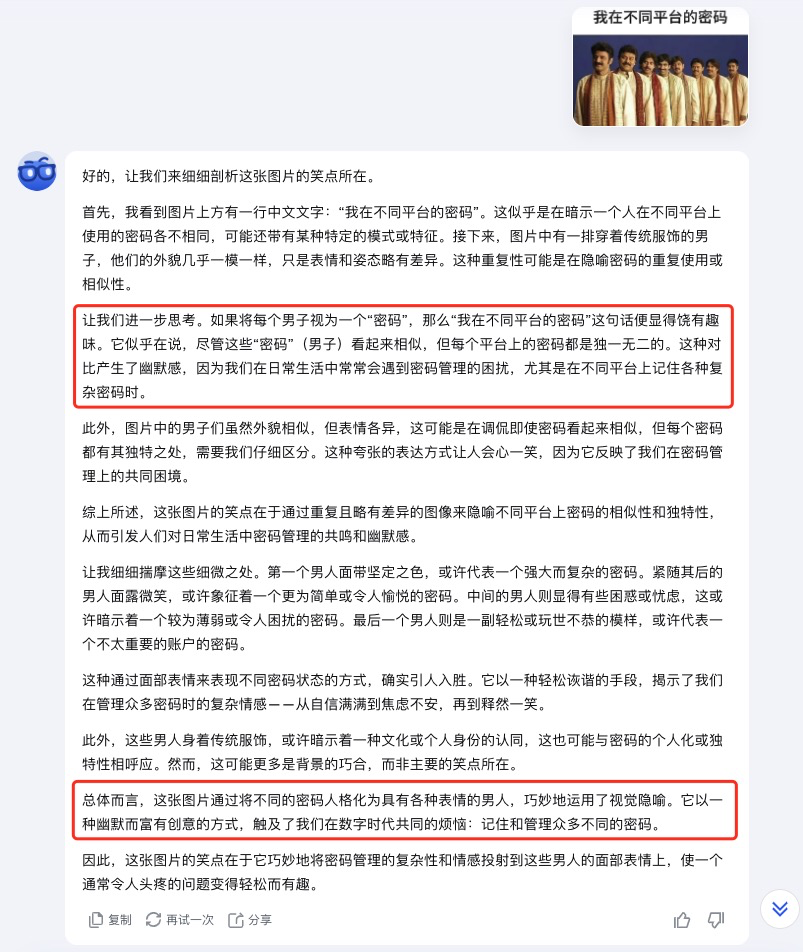
就這麼説吧,基於 k1 的視覺和推理能力,做題都是基操了,只要腦洞夠大,還可以解鎖出更多的玩法。
而 k1 的這種能力,很大程度要歸功於一個叫做COT ( Chain of Thought )思維鏈的技術。
 大概意思就是,模型在輸出答案之前,**模仿人類大腦的思考方式,把複雜的任務拆解之後,再一步步地解決。**這個技術,可以讓模型的智商變高。
大概意思就是,模型在輸出答案之前,**模仿人類大腦的思考方式,把複雜的任務拆解之後,再一步步地解決。**這個技術,可以讓模型的智商變高。
另外一邊,藉助強化學習技術,也讓模型學會了在不斷試錯的過程中進化,以此來達到最優的結果,就跟訓狗似的。
至於為啥 Kimi 會率先選擇數學這個場景作為推理模型的切入口,我想,跟咱們人類學好數學鍛鍊思維,是一個道理。
在模型 “ 學好數學 ” 的基礎上,再將這種邏輯推理的能力應用到物理、化學,乃至於咱們日常生活的方方面面,直到最後真正理解這個世界。
 而很顯然, Kimi 推理模型的泛化能力已經開始顯現出來了。
而很顯然, Kimi 推理模型的泛化能力已經開始顯現出來了。
在數據見頂的前提下,這種基於強化學習技術的路徑,或許能夠讓模型實現更好的效果。
不過説到底,模型用了哪些技術、紙面分數有多高,大夥兒其實更關心模型到底好不好用、實不實用。
而向來以長文本見長的 Kimi ,如今長文本、強化學習兩手抓,也是調整自己的工具屬性慢慢往用户需求靠攏的表現。
 畢竟,當技術不再高高在上,能幫助人們解決實際問題的時候,才算真正完成了它的使命。
畢竟,當技術不再高高在上,能幫助人們解決實際問題的時候,才算真正完成了它的使命。
圖片、資料來源:
Kimi、小紅書
部分圖源網絡
