2025年,中國AI的趨勢與思考_風聞
IT时报-《IT时报》官方账号-51分钟前

讓浦江西岸的風吹散AI頭頂的兩朵“烏雲”
作者/ IT時報記者****郝俊慧
編輯/郝俊慧孫妍
“公開的高質量數據即將用盡了嗎?如何未雨綢繆”“不同具身智能技術路線的能力邊界在哪裏”“我們需要什麼樣的AI4S基座模型”“當前大模型是否遭遇瓶頸”……12月13日~14日,數十個人工智能領域最前沿的關鍵話題出現在浦江西岸,在由上海人工智能實驗室發起並主辦的首屆“浦江AI學術年會”上,全球150餘名人工智能領域專家學者就這些話題進行了深入研討。
兩年前,ChatGPT橫空出世,掀起一場超強的“AI旋風”;最近,OpenAI用連續12天的發佈會再次讓全球進入“AI狂歡”。但不同於兩年前的震驚、興奮與困惑,今天的學界和產業界對於AGI路線有了更多的“中國思考”。

定義“智能”
什麼是“智能”?
儘管人工智能這個詞來源於1956年著名的達特茅斯會議,但會議的發起人麥卡錫卻並不喜歡這個名字,“畢竟,我們的目標是‘真正的’智能,而非‘人工的’智能。”
2022年底,ChatGPT的出現驚豔了世人,也被認為出現了智能“湧現”,但香港大學計算與數據科學學院院長馬毅對此並不認同,他認為,GPT有的只是知識,而不是智能,“智能系統一定是具有自我糾正和自我完善現有知識體制的系統”。
馬毅最近幾年一直致力於研究“白盒大模型”,“白盒”概念對應的正是基於深度學習模型的“AI黑盒説”——儘管大模型給出了令人滿意的結果,但人們對其決策過程卻並不瞭解,甚至輸出結果很難預測和控制,也即出現所謂的“幻覺”。
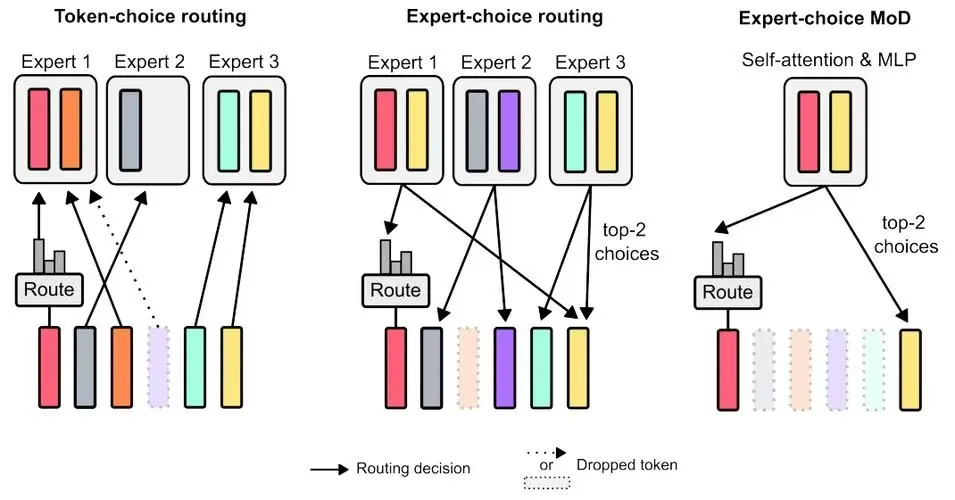
馬毅認為,現有的深度學習模型,例如 Transformer(主流大語言模型架構),本質上是“減墒”,從高維的圖像、聲音、語言等信號裏,不斷壓縮、去噪,然後找到核心規律、低維結構,而白盒就是要清晰解釋這個壓縮過程。
Transformer
簡單理解,與ChatGPT的“暴力出奇跡”不同,“白盒”反其道而行之,試圖先搭建一個可解釋的框架,然後在這個框架下設計出能被解釋的網絡和模型。由於知之而為之,大大減少了Transformer架構的試錯成本,從而從根本上解決當前遇到的“數據牆”和“算力牆”問題。
稀宇科技創始人閆俊傑則認為,智能的定義可以非常廣泛,黑盒模型在某些應用中足夠,但白盒模型在理解人類的智能上可能有優勢。儘管當前的模型和產品已取得一定進展,但未來將會有更多創新出現,不同研究機構和企業將提出各自對智能的理解,並在特定領域內超越現有水平。

新解“Scaling Law”
論壇現場,馬毅的觀點迅速成為學者們熱議的焦點,而在“什麼是智能”的問題背後,隱藏着的另一個提問是,“Scaling Law(尺度定律)還能走多久?”
大洋彼岸,幾乎同時舉行的另一場學術重磅會議——NeurIPS 2024上,OpenAI的前首席科學家Ilya Sutskever語出驚人,“預訓練時代即將終結(Pre-training as we know it will end)”,理由是作為AI發展燃料的數據即將枯竭,依賴海量數據的預訓練模型將難以為繼。
數據枯竭、算力昂貴、效果下降……最近半年,Scaling Law“撞牆”的反思頻繁出現在學術界和工業界。閆俊傑指出,當前全球有效數據被清洗後大概只有20萬億Token。
同時,要想和人腦實現同樣功能的計算量是巨大的,圖靈獎得主楊立昆在其新書《科學之路》中指出,為了達到人腦的計算能力,必須將10萬個GPU連接上功耗至少25兆瓦的巨型計算機才能實現,能量消耗是人腦的 100 萬倍,因此深度學習的能力十分強大卻又十分有限。
圖源:pixabay
“根據我們的觀察,隨着大模型規模的不斷擴大,歸納相關的能力快速提升,而且可能會繼續遵循Scaling Law,但其演繹能力,包括數學和推理方面的能力,隨着模型Side進一步提升,不僅沒有增長,反而在下降。”會議間隙,階躍星辰首席科學家張祥雨告訴《IT時報》記者,他對萬億以上參數大模型的能力提升,並不絕對樂觀。
包括OpenAI在內的全球頂尖AI公司和科學家們都在“另闢蹊徑”。北京時間12 月 6 日凌晨2點鐘,OpenAI 宣佈推出滿血版o1和o1 pro mode,緊接着,谷歌祭出最強下一代新模型Gemini 2.0 Flash,第一時間都“嚐鮮”之後,張祥雨對兩個大模型的創新頗為讚賞,不過,雖然“視覺和推理都有很大突破,但離真正的AGI仍有很長的路要走,未來需要更智能的目標導向和試錯機制”。

Gemini 2.0 Flash
大會圓桌論壇階段,上海人工智能實驗室主任助理、領軍科學家喬宇同樣表示,在通往AGI的路線上仍需要突破3~4個關鍵挑戰,目前,大模型並不具備人類的推理、情感、倫理等戰略性思考能力,“並不是説Scaling Law要被拋棄了,而是應該尋找新的Scaling Law維度,很多難題並不能單純靠擴大模型規模、數據、算力解決,我們需要更豐富的模型架構和更高效的學習方法,同時也希望在AGI發展過程中,能有來自中國的核心貢獻,找到與中國資源稟賦更加匹配的、自主的技術路線”。

面向2025的“中國思考”
那麼,面對即將到來的2025年,當OpenAI、谷歌扔出一個又一個“王炸”時,中國科學家們將在哪些領域攜手突破呢?
經歷了兩年的“狂飆”之後,大模型的發展目標逐漸出現分化:一部分人求解高難度的科學問題,在數學、物理等尖端問題上探索大模型的上限;另一部分人則更關注大模型的落地和穩定性,期待提高模型的下限。
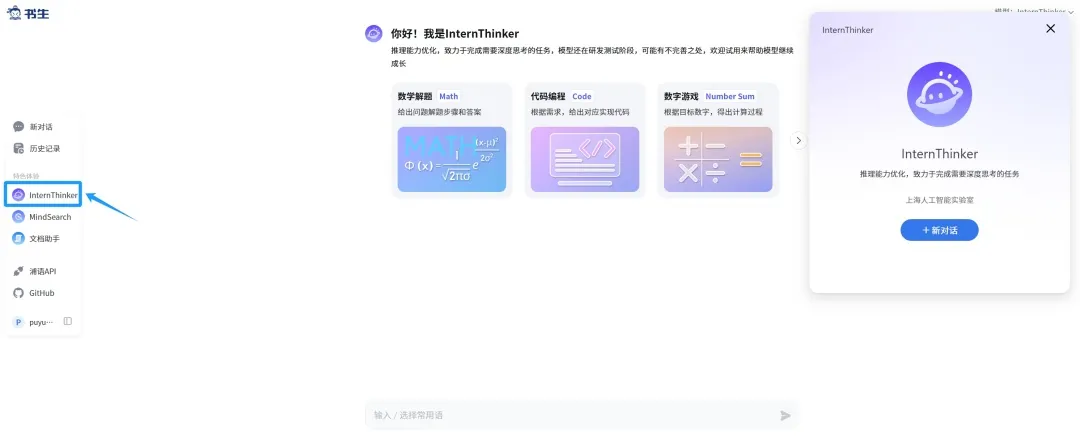
上個月,上海人工智能實驗室按照通專融合AGI路徑,在第一階段構建併發布了強推理模型書生InternThinker,它解決問題的路徑更接近人類學習方式的路徑,面對複雜的推理任務時,並非從海量的樣本中學習單點知識,而是學習人類的思維模式——先回憶所需知識,再逐步推理和計算,最終給出準確解答,如果某條推理路徑失敗,它能夠快速調整思路,嘗試新的解決方案,體現出獨特的深度推理與專業泛化能力的結合。
通過這種方法,InternThinker在“24點”等高難度數學題以及編程題的解決中展現了卓越的能力,不僅完成了解答,還進行了系統的自我檢查與反思,確保結果的準確無誤。
“如果説,通用大模型已經具備了高中知識,那專用大模型就是在此基礎上再學習大學的專業知識,未來希望能夠將大學的知識慢慢融入高中教學中,”上海人工智能實驗室領軍科學家歐陽萬里表示,實驗室正在進一步探索通專融合的技術路線。
喬宇則希望,新的一年中,多模態大模型的湧現能力能夠像語言大模型一樣取得重要的突破,上海人工智能實驗室最近發佈的書生萬象2.5已經在多模態思想鏈(Chain-of-Thought CoT)上取得突破,成為首個MMMU測試(一個大規模多學科多模態理解和推理基準測試)突破70%的開源多模態大模型。
張祥雨同樣希望多模態大模型實現理解和生成一體化,可以直接在視覺空間裏理解並完成視覺推理,通過新範式的加持,讓Scaling Law重新與智能程度的發展正相關。
清華NLP實驗室劉知遠教授團隊則提出了大模型的密度定律(densing law):自2023年以來,模型能力密度隨時間呈指數級增長,約每100天翻一倍,這意味着,當前訓練出的一個模型,100天后,只需一半的參數就可以實現相同的能力。
基於此規律,一年後,一個58B參數規模的大模型就可以復現750B參數大模型一樣的效果。同時,隨着芯片電路密度(摩爾定律)和模型能力密度(密度定律)持續增強,意味着主流終端如PC、手機將能運行更高能力密度的模型。
“我們大膽預測,只要是這個世界上能夠訓練出的模型,未來一定會在某個時刻跑在終端上,這也揭示了端側智能巨大的潛力。”劉知遠認為,未來應該不只是追求規模更大的模型,而應該追求更高的模型製造工藝,尋找更加陡峭的成長曲線,從而讓大模型可以實現高質量可持續的發展。
“和100多年前的物理界一樣,當前的人工智能領域頭頂也有兩朵烏雲:一朵是下一代智能系統一定是有自主連續增量學習的系統,更接近於人類的個體智能;另一朵是必須取代DP(動態規劃)路線,自主學習必須是局部的、高效的,當前(大模型得出同樣結果)的能耗比自然界高出8~9個數量級。”馬毅希望,參會的年輕科學家們能“吹散”這兩朵烏雲。

萬事之始仍是“人才”
事實上,上海人工智能實驗室舉辦“浦江AI學術年會”的初衷,正是希望以年會為載體,推動“以問題為導向”的學術討論深入開展,通過高質量問題激發更多創新靈感,“互相出好題、互相協同”,在更高層面實現產業合作、協同創新。
本次大會主席、上海人工智能實驗室主任、首席科學家周伯文認為,當前大家都在關注“Scaling Law”,但接下來“Scaling What”(什麼規模化)?除了業界關注的算力、數據和最近的推理時間,他認為提升研究者的“Scale”同樣重要,“1911年,首篇關於原子結構的論文只有三個人署名,但現在歐洲核子研究中心每次新發現都有數百甚至上千名科學家協作,如何能夠創造性地發揮團隊本身的創造力,同時又能更好地完成團隊間的協作,實現更高層面的Scale,我認為這是Scaling Law下一階段需要研究的問題。”
令人欣喜的是,本次大會的另一位主席、清華大學交叉信息研究院及人工智能學院院長、上海期智研究院院長姚期智發現,中國人工智能高端人才培養已經進入轉折點,國內大學培養出的博士,其創新成就和工作成果已可與國際頂尖實驗室“比肩”,這意味着指導這些博士生科研團隊跟師資到達世界最高水平,下一步,他期待國內各個高校、科研機構進一步加大對年輕科研人員(博士後階段)的培養力度,讓他們能儘快在人工智能科學道路上獨當一面。
排版/ 季嘉穎
圖片/ 谷歌 書生 東方IC pixabay
來源/《IT時報》公眾號vittimes
E N D