騰訊混元文生圖大模型宣佈開源,未來還將跟QQ、企微和遊戲做聯動
周毅是故意的还是不小心?

文/觀察者網 周毅 編輯 張廣凱
5月14日,騰訊宣佈旗下混元文生圖大模型全面升級並對外開源。據悉,這是業內首箇中文原生的DiT架構文生圖開源模型。它支持中英文雙語輸入及理解,參數量15億。目前,該大模型已在Hugging Face平台和Github上發佈,包含模型權重、推理代碼、模型算法等完整模型,可供企業與個人開發者免費商用。
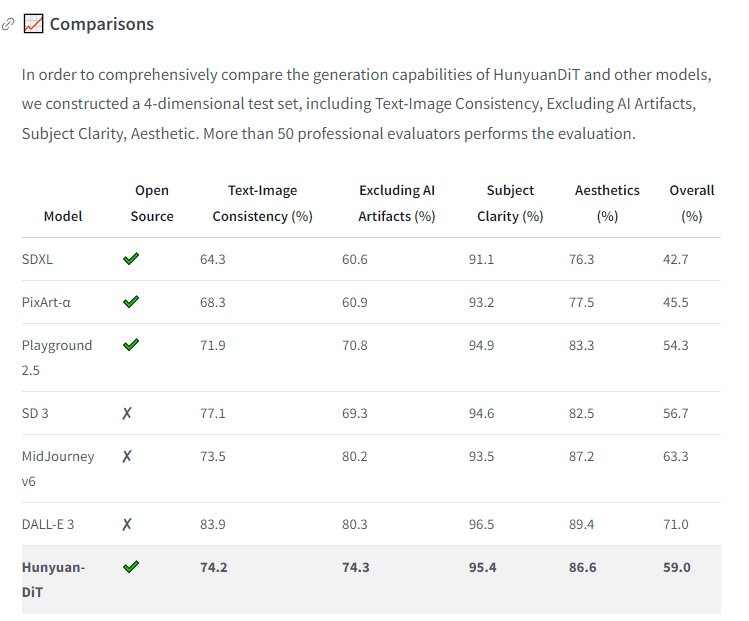
不同模型在圖文一致性等方面的表現 圖源Hugging Face
騰訊混元文生圖負責人蘆清林對觀察者網表示,提升技術能力和更廣泛的應用,是該大模型未來的兩個方向。
“從技術能力的提升來説,如何讓圖片生成的速度更快,生成的質量更好,是我們永遠都會追求的一個技術方向,它似乎是沒有止境的。”蘆清林表示,項目團隊也希望該大模型,能在騰訊內外更廣泛的業務場景應用起來。事實上,從去年開始,騰訊混元文生圖就和騰訊的廣告業務進行了一些協作。
“今年會跟社交業務,包括QQ、企業微信等很多業務場景做聯動。跟他們合作做一些新的技術能力。”蘆清林透露,同時,該大模型也會跟騰訊遊戲做一些深入的技術合作,希望能夠在美術場景中應用起來。包括QQ音樂等在內,也都是該大模型未來將會提供支撐的業務場景。
大模型的優異表現,往往離不開先進的技術架構。過去,視覺生成擴散模型主要基於U-Net架構,但隨着參數量的提升,基於Transformer架構的擴散模型展現出了更好的擴展性,有助於進一步提升模型的生成質量及效率。升級後的騰訊混元文生圖大模型採用了全新的DiT架構(即Diffusion With Transformer),這也是Sora和Stable Diffusion 3的同款架構和關鍵技術,它就是一種基於Transformer架構的擴散模型。
公開資料顯示,在DiT架構的基礎之上,騰訊混元文生圖大模型還在算法層面優化了模型的長文本理解能力,能夠支持最多256字符的內容輸入,同時賦予其多輪生圖和對話能力:在一張初始生成圖片的基礎上,用户通過自然語言描述,即可對其進行調整。
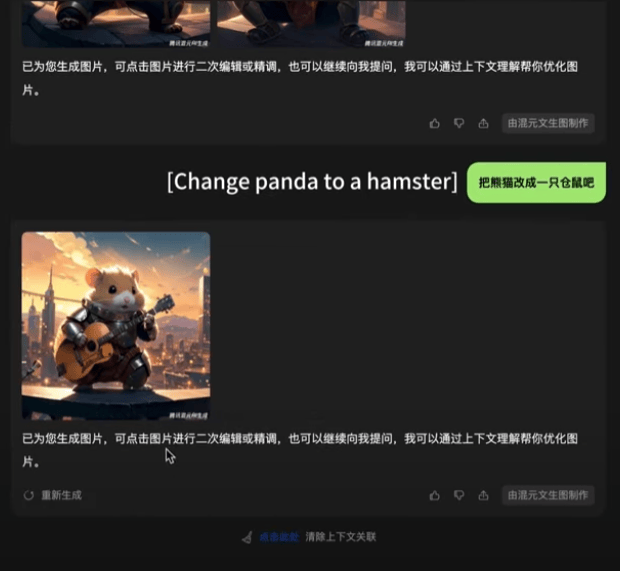
用户通過“對話”,即可調整文生圖的具體內容 測試截圖
此外,“中文原生”也是騰訊混元文生圖大模型的一大亮點,此前,像Stable Diffusion等主流開源模型核心數據集以英文為主,對中國的語言、美食、文化、習俗理解有限。作為首箇中文原生的DiT模型,混元文生圖具備中英文雙語理解及生成能力,在古詩詞、俚語、傳統建築、中華美食等中國元素的生成上表現出色。

混元文生圖大模型的部分能力展示 圖源Hugging Face
本文系觀察者網獨家稿件,未經授權,不得轉載。