謝耘:為什麼要認真討論大語言模型的“理解”問題?
guancha
【文/觀察者網專欄作者 謝耘】
自今年初文生視頻大模型Sora引爆熱議後,本週美國軟件巨頭Adobe表示,將允許用户在其旗下的視頻編輯軟件中使用包括OpenAI的Sora在內的第三方生成式人工智能工具。
另外,馬斯克旗下人工智能公司xAI於近日推出首個多模態模型 Grok-1.5 Vision。
xAI 表示:除文本功能外,Grok還可以處理各種各樣的視覺信息,包括文檔、圖表、圖表、屏幕截圖、照片,並能進行多學科推理。xAI重點展示了Grok-1.5V的7個示例,包括:將手繪圖表轉換成Python代碼、看食品標籤計算卡路里、根據孩子的繪畫講睡前故事、解釋梗圖等。

馬斯克xAI的多模態模型Grok-1.5V
Sora 可以在每次 API 調用中為自然語言提示創建最多三種視頻變體。
無論在語言領域還是在視頻領域,它們都給出了讓許多人感到驚奇的結果,於是便出現了大量聳人聽聞的説法。其中一個核心的話題就是有人認為這些模型已經具有了“理解”能力,它們能夠理解語言背後的邏輯,能夠理解物理世界的運動規律。
當談到“理解”的時候,有多少人知道自己心中的“理解”到底是什麼?如果大家對於什麼是“理解”都沒有共同認識的話,討論這些生成模型是否有“理解”能力就失去了意義。
“理解”是一個我們再熟悉不過的詞彙了,它同時也是智能意識領域中最基本與核心的問題之一。問題越基本,我們往往越熟視無睹,越覺得無需做什麼解釋,其實把它説清楚就越困難。
從小到大,我們都在努力地去“理解”,也希望被別人理解。可是好像卻沒有誰講過到底什麼是“理解”。在受教育的過程中,幾乎所有課程,都是講授需要我們去理解的知識內容,然後用考試來檢驗我們是否理解課程。但卻沒有一門普及性的課程教授我們應該如何去理解。“理解”似乎是一個如呼吸一樣的理所當然的、每個人都會自然而然地無師自通的能力。
然而事情遠非如此簡單。只要是生理正常的人都一樣地在正常呼吸,但是正常人之間的理解能力卻是有很大的差異。如同一個老師教授的學生可以有很不同的結果表現。
如果我們將人類的理性意識活動做簡化,可以得到下圖所示的基本過程示意。
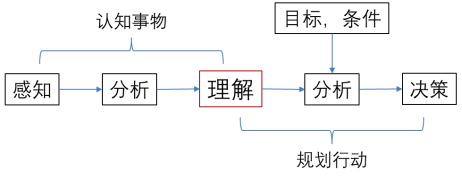
人類理性活動的簡化示意
從這個過程中我們可以看到,理解是認知的結果也是行動的前提,是人類理性意識活動的核心環節。
所以對“理解”有一個清晰的認識,對於我們提升自己的理解能力,尋找意識活動的規律,包括人工智能在內的計算機應用這個人類的“外意識”,認識各種基於不同算法的“外意識”的能力邊界都具有極其重要又十分普遍的意義。
01. 機器學習獲得的“統計性理解”
在對人的理解做了一個比較全面的討論之後,我們來看一下人類創造出來的“外意識”在“理解”的道路上到底走了多遠,以及最終能走多遠。
2023年以ChatGPT為代表的大語言模型的出現,再次引發了對機器是否具有了意識或理解能力的大規模議論。
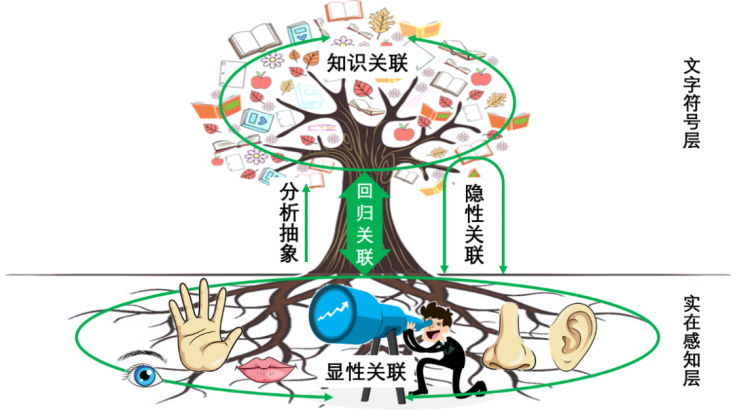
圖二 迴歸關聯核心作用的示意
目前包括大語言模型在內的機器學習方法,接受的都是人類給其提供的用文字符號表達的內容,所以即使它有了某種“理解”,也僅僅是存在於文字符號這個抽象層面的,而做不到最為關鍵的迴歸關聯理解。這被稱為人工智能的“符號落地”問題。基於多種傳感器構建“具身智能”的努力,包含了實現上圖中所示的迴歸關聯的意圖。但是因為我們沒有關於意識活動的基礎科學理論來支撐這些努力,所以藉助“具身智能”實現迴歸關聯或“符號落地”這一目標能否實現以及能走多遠,都還有待於在實踐中去探索,難以做理論上的分析推斷。
我們目前能夠下的結論是,從人類理解的本質來講,基於對文字符號做信息處理的機器學習算法,還不具有與人類一樣的理解能力,因為它對這個世界是沒有自己實在感知的,無法實現迴歸關聯。
那麼,包括大語言模型在內的機器學習算法在抽象的文字符號層面實現了某種關聯嗎?答案顯然是肯定的。機器學習最著名的一點就是它能夠發現與建立信息之間的相關性,並且因為也僅此而已而遭到詬病。但是這種相關性關聯與人類在理解的時候依靠的反映客觀聯繫的關聯有所不同。機器學習是基於對人類生成的內容做文字符號層面的統計相關處理,來確定文字符號之間的概率性關聯關係,然後據此給出相應的輸出結果。這種文字符號之間的相關性並非是人類思考的基點,而是人類因思考而產生的文字符號表達形式的一種派生特徵。

圖源:CSDN
以生成式大語言模型為例,它是對用文字符號表達的內容在文字符號層面做概率性相關統計分析,進而通過文字符號之間的關聯關係,在概率的意義上掌握學習樣本所反映的文字符號的含義、語法規則和文字符號的組合習慣、及體現不同具體表述內容的組合方式等信息,或稱之為知識。最後模型以此為基礎通過自迴歸的方式來完成內容生成的任務。
這種依靠統計獲得的文字符號之間的關聯關係,是一種語言層面的表象關聯。之所以説它是表象關聯,是因為文字符號的組合是其表述內容的外在形式,並不能簡單地等同於內容本身,所以才有“言外之意”“字面含義”等説法。因而依據它形成的關聯也並不能完全等價於基於內容的關聯。但同時,形式與內容終歸有着統一的一面。所以這種統計關聯,與人類在抽象知識層面依據內容與客觀邏輯形成的關聯有許多相通之處,但在一般的意義上也並不相同。
人類在做文字符號表達的時候,基本的邏輯是先做“構思”---捋清要表達的內容,確定要使用的表達的方式,然後根據文字符號所代表的現實意義,按照語法規則形成最後的表達形式。雖然這個過程常常包含了非邏輯化的潛意識過程,常常並沒有嚴格清晰的階段劃分,但是這個基本邏輯依然在起決定性作用。在這個過程中,“構思”是基礎與起點,最終形成的文字符號表達是結果。而且人類在這個過程中還有“反思”,它基於“構思”去斟酌修改已經形成的表述,讓其能夠更好地反映自己的初衷。
大語言模型是不存在“構思”這一關鍵環節的,當然也就不存在“反思”的過程。它是通過所謂的“自迴歸”過程來產生輸出,即利用過去已形成的輸出及掌握的概率性關聯關係去推算下一步的輸出。這是它與人類在生成文字符號表述時的一個本質差異。
它以得到的輸入為起點,利用從學習樣本中學習到的各種概率性關聯關係,以“自迴歸”的方式按照順序一步步組合出相應的輸出。在這個輸出中,文字符號的基本使用方式來自於對它從天量的學習樣本中學到的語言學知識,這使得其輸出在形式上可以很好地符合人類的表達習慣。同時根據其學習到的相關性關聯關係,在其輸出中還會含有許多來自其學習樣本中表達不同內容的文字符號組合方式。
所以雖然它沒有像人那樣的“構思”過程,可它也並不是在言之無物或憑空編造,而是通過關聯關係把其學習樣本中的許多內容有序地一步步組合在了一起。這是“自迴歸”機制自己的“思考”方式。它從接受的問題出發,通過這種“思考”方式生成了看上去含義豐富內容完整的輸出。由此,它讓許多人以為它是以與人類類似甚至相同的思維方式生成了那些文字符號的表述。
如果僅僅從語言層面來看,大語言模型可以給出相當好的結果,其表達相當的順暢,説的都是人話;但是在其對答如流中,如果我們從深層含義的角度來看,情況就變得複雜了。它有時會給出令人滿意的答案,即它給出的結果比較好地符合人類的理解認知;有時則會出現困難,甚至給出的結果讓人感到莫名其妙,即出現所謂的“幻覺”。這種“幻覺”並非是因為它走了神,而是因為它“思考”的底層機制與人類思考的機制是基於很不相同的原理,所以它按照自己的機制給出的有些結果對人類而言如幻覺一般。即使對於一些我們看上去比較簡單的、但是沒有包含在其學習樣本中的問題或表達方式,它也可能出現根本性的混亂或錯誤。
比如曾有人問:“大象與貓哪個大?”大語言模型回答道:“大象大”;但當被問道:“大象與貓哪個不比另外一個大?”大語言模型則回覆説:“它們哪個都不比另外一個大。” (“Stuart Russell專訪:關於ChatGPT,更多數據和更多算力不能帶來真正的智能”,聞菲,微信公眾號:“機器之心”,2023年2月20日)如果這個回答是人類做出的,我們會説這個人在回答問題時“沒走心”。這個例子很清楚地表明,因為大語言模型僅僅學到了文字符號層面的統計相關性關聯,在面對這個用不太常見的方式表述的問題時,它基於統計相關給出的文字表達便無法與人類的期望相應,即不符合人類的理解。
而且目前大家公認大語言模型的推理能力很弱,對於稍複雜一點的邏輯關係就無能為力。這正反映了它依靠文字符號層面的統計相關性關聯,僅僅能夠反映語言所表達的淺層含義,而卻很難體現出文字符號表達的內容所藴含的複雜或深層一些的邏輯。
而它在什麼問題上會出什麼性質的錯誤,是我們難以預計的。原因就在於它在做關聯組合輸出時,僅僅是依據學習到的統計性關聯,而並不是像人類那樣基於內容含義去表述。對大語言模型能力與侷限的分析,還是應該注重對底層機制的認識,不能僅僅依靠不完整的測試結果去論證。對於大語言模型而言,由於其面對問題的開放性,根本不存在對其做哪怕是比較充分測試的可能。
或許有人會説,人同樣要犯各種錯誤,大語言模型犯一些錯誤有什麼大不了的?這裏面有兩方面的問題。一個就是我們對自己創造的工具犯錯誤的不可預測性可以接收到什麼程度?另外一個是人確實會犯錯誤,但是人犯錯誤具有相當的可預測性。比如一個在某個領域的高水平專家,他在這個領域中犯簡單低級錯誤的概率必然非常小。可預期性對於人類來講是非常重要的。
通過上面的分析,我們可能就比較容易理解下面這句話的含義了:“It is a language model, not a ‘truth’ model. That’s its primary limitation: we want ‘truth’, but we only get language that was structured to seem correct.”(第8頁,《What Are ChatGPT and Its Friends?》, Mike Loukides著,O’Reilly Media, Inc. 出版,2023年3月第一版)。
如果一定要把這種基於統計的人工智能在文字符號層面建立的這種關聯,與原本僅為人類(或許還應該包括一些其他高級生命)的內意識所獨有的“理解”聯繫在一起的話,我們應該可以合理地稱之為對抽象知識的“統計性理解”。
放在人類的智能這個參照系中來看,這種基於對文字符號做統計性相關分析而獲得“理解”的過程,大體相當於人類“以文解文”的“望文生義”。這樣比喻並非是簡單的貶低。因為對於相對簡單直白的表述而言“望文”是可以正確地“生義”的,所以大語言模型產生了驚人的效果。當然對於那些比較複雜的表述或包含比較深的“義”的表述,僅僅靠“望文”就會出現偏差,甚至是南轅北轍。這是“統計性理解”在對文字符號所表達的內容的“理解”上,難以跨越的一個縱向深度上的侷限。這個侷限是由其“統計性理解”的基本機制帶來的,所以恐怕難以靠繼續提升模型與學習樣本的規模去超越。
統計性理解的另外一個橫向廣度的侷限就是在前一章對統計算法做分析時指出的,它無法超越學習樣本所藴含的信息,即統計方法是“就事論事”。這是由信息的本質與統計方法所依靠的基本計算機制決定的。提升模型與學習樣本的規模是可以不斷擴大“就事論事”的範圍,但是依然不可能獲得學習樣本外的新信息。
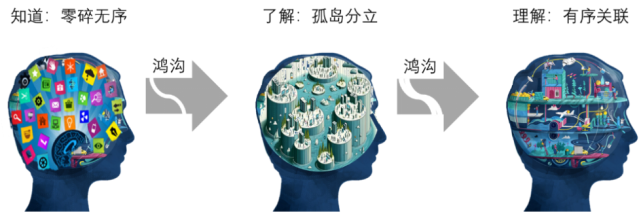
從記憶結構的角度看“知道”、“瞭解”與“理解”的差異示意
與人相對照,機器學習的“統計性理解”基本處於上圖中間的“瞭解”狀態。兩者相比有兩個出入。機器學習對知識的理解是基於表層相關性關聯,缺少人類可以利用的深層邏輯性關聯;但是機器學習可以在很多不同知識之間建立起關聯,不存在孤島問題。所以與上圖中人的“瞭解”狀態相比,機器學習的深度不足但廣度佔優,而兩者同樣都缺少理解中最為關鍵的迴歸關聯。所以可以認為它們彼此大體相當。
從這個角度來看,“外意識”在理解這條路上,確實已經取得了驚人的進步。它依靠基於暴力計算的統計方法成功地跨越了人類意義上的從“知道”到“瞭解”這個鴻溝。但下一個鴻溝---從“瞭解”到“理解”的挑戰可能有數量級的提升。就好像人類登上月球與走出太陽系是有天壤之別的難度的。
與“統計性理解”相對而言,人類的理解屬於“本質性理解”---它包括了基於被理解對象本質的各種不同性質的關聯。這種理解不是望文生義的產物,而是深思熟慮的結晶。事實證明從實際應用效果上看,這兩者是有很大交集的。在相交的部分,人工智能給出的結果與人類的理解相一致。這也符合人類的經驗:在比較簡單的問題上,我們很難看出“望文生義”與“深思熟慮”的不同。這就是生成式大語言模型引起巨大反響的原因。但是畢竟兩者的基本機制不同,面對複雜的問題時兩者的差異就會越來越明顯地顯現出來。所以我們不能因為它們在效果上有交集,就把兩者簡單地等同起來混為一談。

對數字及加減法的理解過程
如前面幾節的分析,文字符號表達藴含的意義,在本質上存在於它們與實在感知的關聯之中。目前的“外意識”不論採用什麼樣的統計算法,還都是在上圖之中的文字符號層面做表面性的文章,所以不論它給出來的結果看上去如何精妙,它其實都沒有真正從整體的角度理解文字符號所要表達的人類認知層面的意義。所以有學者説“大語言模型不懂概念,只懂概率;不懂邏輯推理,只懂概率計算”。這個説法有些過於簡單化,或許下面這個表達更準確一些:“它是依靠相關性概率去把握概念,用相關性概率計算去‘擬合’邏輯推理”。我們不能脱離文字符號及其組合的真實含義,認為語言表現出來的概率性相關關係便代表了它的一切、包括它所攜帶的本質含義。
由於生成式大語言模型給出的是自然語言回答,所以它輸出的內容,並不總是簡單地對錯分明,還包括大量的模稜兩可或是似而非的説法。這必然導致每個人對大語言模型的“理解”能力會有很不相同的評價。我們不難理解,這種個體性評價將大概率地與一個人自己的理解能力呈負相關。而理解屬於意識活動,我們還沒有辦法設計一個完全客觀可行的測試方法,來測試不論是人還是機器的理解能力。圖靈提出的人工智能“圖靈測試”,也僅僅是一個主觀評價的方法。
有人根據2024年初出現的視頻生成器Sora的一些輸出結果,便下結論説它已經從對視頻的統計分析中掌握了物理定律。如果這不是商業炒作的話,則典型地反映了評價者自己在理解能力上的侷限。僅僅靠對視頻圖像的“望文”應該無法生出深藏在其背後的物理定律之“義”的,否則以牛頓為代表的那些偉大物理學家們貢獻的價值就要被打上大大的問號了。
文生視頻界面 圖源:36氪
或許有人會説:既然機器學習可以從文字符號的表達中相當完整準確地學到其背後的語言規則,那它為什麼不可以從圖像所反映的真實過程中學到其背後的物理規律?文字符號的表述直接基於語言規則,文字符號之間的關係直接反映了語言規則;但是視頻圖像的變化與背後的物理定律之間的關係則有一條複雜的多重因果作用鏈,並非是單純地直接耦合在一起。所以即使圖像信息完整地反映了真實過程,從圖像要素之間的統計關聯中恐怕也是無法推斷出在其背後發揮作用的各種物理規律。這需要透過重重現象看到背後本質的卓越能力,即上一章講過的與統計很不一樣的“洞察”能力。正因為如此,牛頓他們的貢獻才彌足珍貴。
有人強調,機器沒有必要按照人的思維方式去思考,完全可以有自己的思維方式、自己的“理解”、自己的邏輯等等。事實上,人類創造的工具在很多情況下,都是按照與自然不同的方式在工作的。在物質性工具的時代便是如此,最為經典的例子就是車輪的發明。而計算機從一開始做的很多事情的方式也都與人類不同,人類大腦中就不存在一個關係型數據庫。所以“外意識”有自己獨特的不同於人的方式,這既不是問題、更是早已存在的事實。

發現萬有引力定律的牛頓
但是問題在於,我們創造的工具是服務於人類的,所以我們必然要關注它用自己的方式產生的結果是否滿足人類的需求。而在這個問題上,理解它運行方式的基本機理就變得重要,我們不能僅僅看它已經給出的結果。因為我們需要它的行為在未來具有可預測性,我們才能放心地使用它。
曾經這完全不是問題。那時“外意識”完全按照人類設計的顯性邏輯循規蹈矩地去運轉。但是當AI 技術在暴力計算的支撐下發展到了“不可解釋”的階段後,這變成了一個必須面對的大問題。如果我們無法預計一個工具在什麼時候、什麼問題上出現什麼樣的與我們期望不同的結果,每一次都是要等結果出來才能判斷是否符合我們需求的話,它就是一個無法讓人放心使用的工具了,甚至可以説失去了工具傳統的基本價值。
比如,如果我們期待“外意識”具有理解能力,這個期待中固有的假設就是它理解的結果與人類是一致的。即機器的理解過程可以與人的不同,但是在結果的意義上必須是等價的。否則它就無法滿足人類的這種期待。要想證明這個等價,則必須去理解它的“理解”過程,而不能僅僅靠其產出的已有結果通過枚舉法來確認。而從本章的分析可以看出,目前機器學習“望文生義”的“理解”與人類“深思熟慮”的理解是無法完全等價的,僅僅在一些產出上可以有相同或類似的結果。
而部分結果的相同,並不能構成我們“放任”機器學習在自己與人類不同的“理解”道路上一路狂奔的理由。比如一個AI系統如果給出的很多答案,其邏輯在人看來無法理喻,即使你能證明它非常符合AI自己的“理解”,這樣的系統輸出對於人類來説也沒有多大意義。
我們固然可以依靠信仰,將一個技術發揮到極致,就像當年Hinton等人所為;但是我們卻無法依靠信仰,讓一個技術去做我們期望的、又是它所力不能及的事情。每個技術都有其能力的邊界,認識這個邊界對於人類的努力有重要的意義,可以讓我們極大地減少盲目性。一個技術的能力邊界可以通過理論分析確定,也可以通過實踐碰撞發現。而現代科學的強大,就在於可以從一般性原理出發確定技術方法的能力邊界,所以我們才走出了傳統的依靠實踐碰撞掌握技術的工匠時代。今天,在“外意識”領域,我們不能僅僅滿足於實踐碰撞。努力形成一些機制原理層的認識,具有重大的意義。
那麼,是否可以通過持續地增加模型的規模,進而統計更多的數據,讓模型生成的基於表象的統計性理解去無限逼近人類的本質性理解?也就是説在“理解”這個問題上,是否也存在一個類似於概率統計中的“大數定律”——只要樣本足夠大,統計結果就可以無限逼近現象背後的本質規律?
這種可能性應該相當小。
首先,我們沒有這方面的足夠的實踐可以證實利用統計方法可以實現我們期望的理解。人類已有的實踐告訴我們,表象經驗單純在數量上的積累,即使再多也完成不了質的飛躍,無法形成對背後本質的洞見。或者説如果沒有深思熟慮,“望”再多的“文”,也“生”不出深刻的“義”;
其次,對抽象知識的關聯關係,不同於傳統數理統計中對簡單事件的概率描述。在傳統數理統計中,我們統計的是性質一致的簡單事件,並且找到了許多不同的情況下理論上的概率分佈。而對於抽象知識的關聯關係,因為我們面對的是大量性質不同的複雜“事件”,所以沒有辦法用簡單的類似概率分佈的方式來描述。我們現在使用的算法也不是在直接統計人類理解中的本質性關聯,而是統計文字符號之間的相關性。所以用概率統計中的“大數定律”來做類比,去推論預言人工智能的統計可以實現對文字符號背後深層意義的逼近並沒有多少依據。
最後,目前包括大語言模型在內的人工智能使用的統計模型,都是經驗性的。經驗的有效性具有很大的侷限,有其推廣擴展的邊界。實踐告訴我們,基於經驗構造的系統,其複雜功能下的規模擴展性是有限的。比如,如果僅僅憑藉經驗,人類可以建造規模宏大但功能簡單的金字塔;然而再出色的能工巧匠恐怕也修建不了達到迪拜哈利法塔那樣高度而且還有那樣複雜功能的建築。相信統計模型可以因為規模上持續地擴展,而不斷“湧現”出更多的“理解”上的奇蹟,不僅沒有理論的支撐,也缺乏充分的實踐依據。
所以,《Artificial Intelligence:A Modern Approach》的作者之一Stuart Russell (加州大學伯克利分校,現任計算機科學系教授(曾任系主任)、人類兼容人工智能中心主任)對基於統計深度學習的大語言模型有如下的評論:“(大語言模型)看起來聰明是因為它有大量的數據,人類迄今為止寫的書、文章……它幾乎都讀過,但儘管如此,在接受了如此之巨的有用信息後,它還是會吐出完全不知所謂的東西。

加州大學伯克利分校計算機科學專業教授、人類兼容人工智能中心(Center for Human-Compatible AI)創始人斯圖爾特·羅素(Stuart Russell) 圖源:搜狐新聞
所以,在這個意義上,我認為語言大模型很可能不是人工智能的一種進步。……我們所謂往前走的唯一方法是---模型不 work?好吧,我們再給它更多數據,把模型再做大一點。我不認為擴大規模是答案。”(聞菲,“Stuart Russell專訪:關於ChatGPT,更多數據和更多算力不能帶來真正的智能”,微信公眾號:“機器之心”,2023年2月20日)
“外意識”跨越從“瞭解”到“理解”這個鴻溝,可能需要當下主流認知之外的思路,而不是一味依賴擴大規模增加算力。人們總是對已經成功的主流手段有一種近乎迷信般的執着,但每一次關鍵的跨越常常都是在當下的主流認知之外。就好像這次在Hinton等人的長期頑強堅持下,基於暴力計算的統計方法出乎主流預料地擔當起了實現第一個跨越的重任。近期Yann LeCun被眾人攻擊,便是因為他認為當下眾人狂熱追捧的自迴歸生成式大模型之路已經快到盡頭,人工智能要繼續發展應該走一條新路,這也是他正在進行的探索。持這種觀點的學者並非只有他一個。

傑弗裏·辛頓(Geoffrey Hinton)
人類執着地試圖造出與自己有着同樣智能的機器,或許根植於人類自己渴望為造物主的強烈願望。暴力計算的出現讓這個渴望顯得比以往任何時候都更加具有可實現性。有一位國內的學者對當前拼命依靠算力來解決問題的局面寫了一段有趣的評論:“目前這種狀況下,這種領先是極其不保險的,因為説不定突然某一方祭出一個逆天的算法就會一下改變整個戰局。如果這樣往往很戲劇性,很悲壯,因為一方可能剛剛投入幾千億去擴充算力,誰知另一方倒騰出一個新的算法,竟可達到類似的效果卻只需千分之一的算力。所以,未來幾年會非常好玩。”
然而由於人工智能缺少理論基礎,所以對於未來的所有判斷也就都僅僅是一種猜測。最終只由實踐或時間給出答案。
如果我們放開視野去觀察就會發現或許還有另外一種可能。即“外意識”止步於人工智能的這個鴻溝邊,不再狂熱地模仿追趕人類已有的能力,轉而以自己不同於人類的獨特能力,大力創造自己與人類互補的價值,以此對人類的發展做出新的巨大貢獻。畢竟在人類的歷史上,有許多被認為理所當然而孜孜以求的目標,雖歷經千年卻依然渺茫,就是做不到,比如修煉成仙而長生不老。
02. “外意識”的感性與理性認知
在上一節的分析中我們看到,大語言模型通過對學習樣本在文字符號層的統計分析確實形成了自己獨特的統計性理解。那麼這種理解的產物在模型中,或者説在這個“外意識”中,是以什麼形態存在的?它是否能夠直白地告訴我們、或者我們是否能夠直觀地看到它到底理解了什麼、掌握了哪些知識?
由於以深度學習為代表的統計算法具有“不可解釋性”,所以上述問題的答案是:不能。
如果將它與人類的意識活動做個有趣的對比的話,我們不難看出依靠深度學習的大語言模型理解和掌握的內容,可以説是以“外意識”的“感性認識”的形式存在的。
之所以將這種統計性理解形成的“認識”稱之為“外意識”的“感性認識”,是因為它在算法中是以分散隱性的形態存在,沒有形成顯性的以文字符號為基礎的形式化系統性表示。即它沒有形成用文字符號表達的明確的知識,而是以參數+模型的形態存在,只有在使用時才能間接地感受到它的作用。
統計性理解形成的這種感性認識有其明顯的侷限。首先是不可傳遞性。因為沒有作為顯性的認知存在而無法被剝離出來。如果要傳遞,也只能是以參數+模型的整體方式進行;其次,無法對其做解析分析,不能從理性邏輯的角度去分析這種認識的合理性與正確性。這些特徵與人類的感性認識都非常類似。
我們把人類的認識分為感性與理性,就是因為理性認識是可以用文字符號等形式化的方式清晰地表達出來的,而感性認識卻做不到。個人的感性認識要想傳遞的話,基本只能自己親自到場操作,這與參數+模型的方式本質是一樣的。
在人類的發展過程中,從感性思維發展到理性思維能力,是人類進化的一個重要的里程碑。它讓人類的知識從此有了可以超越個體生命的存在而持續不斷積累提升的可能。在對事物的認識過程中,從感性認識上升到理性認識是非常重要的一步跨越。人類的知識積累、一代代人認知的不斷深化,都依賴於理性認識。這也是近現代科學得以歷經四百年而發展到今天這樣輝煌的高度的必要基礎之一。
對於人類自己大腦中的“內意識”是如此,那麼對於人類創造的大腦外的“外意識”呢?把自己學習到的內容,用人類可以理解的顯性方式呈現出來,讓它變成“外意識”的理性認識,是不是未來機器學習需要走出的具有決定意義的一步?
顯然,如果“外意識”能夠做到這一步,將是一個質的飛躍。這將帶來不可估量的影響,要比它像現在這樣不明不白地又學會了一個新技能要重要的多得多。把“外意識”的這種感性認識變成理性認識會讓我們對機器學習的方法有更深刻的理解,從而可以更有方向性地提升機器學習的能力,開發新的機器學習算法;也會讓機器學習的結果在更多的方面起到更大的作用,成為人類知識寶庫的重要補充來源之一;讓人類的內外意識更加密切地融合在一起,進一步提升人類整體的智慧能力。
這是一個巨大的挑戰。目前在人工智能領域內的許多研究工作,包括對機器學習的可解釋性研究都與此密切相關,但一直沒有實質性突破。
那麼,“外意識”是否與人類的內意識一樣,也是先有感性認識再有理性認識的?如果我們脱離目前基於統計的人工智能的視角,就很容易看到“外意識”走了一條很不相同的路。它是先有理性認識,然後才發展出感性認識的。
“外意識”從誕生之日起,一直非常“理性”,直到“暴力計算”的出現才打破了這個局面,讓它開始變得“感性”起來。
自從計算機誕生直到這一輪人工智能熱潮的興起,“外意識”都是人類理性創造的產物。人類將自己的理性認識注入到“外意識”中,轉化為它自身的邏輯,讓其清晰地按照這種理性認識去完成各項任務。雖然這些理性認識不是“外意識”自己產生的,但是這種做法讓“外意識”確實從人類那裏獲得了大量的對這個世界的理解,然後按照這些理解、按照人類的理性認識去循規蹈矩地勞作。即使在深度學習讓“外意識”可以自己形成出人預料的各種“感性認識”之後,業界依然有一個説法:“有多少人的智能,就有多少人工智能”。顯然這個時候人們依然認為人類注入到“外意識”中的理性認識依然是起決定作用的因素。
自大語言模型驚豔亮相之後,許多人的態度發生了轉變,認為只要任由“外意識”這種感性認知能力在“暴力計算”的推動下繼續發展下去,通用人工智能的實現便指日可待。人類很快就無需再費心耗神地將自己的理性認識注入給“外意識”,甚至有人堅信目前人工智能產生的認知已經不遜於人類,人類應該放下身段,更不必再自作多情地去充當“外意識”的導師。
面對這些觀點我們退後一步看,就會發現一個非常有趣的現象。
每個人從出生之後,便耗費大量的精力去學習各種知識,形成自己內意識所擁有的對這個世界的理性認識。這個過程如此的費力耗神,所以在電子技術出現以後人類就有一個夢想:是否可以有一種外部注入的方式,將人類積累的寶貴知識一次性地加載到我們大腦的內意識中,從而讓每一個人都能節省下用在學習上的大量的精力與時間。這個夢想一直遙不可及卻始終縈繞在我們的心中。
可是對於“外意識”而言,這根本就不是問題。它從誕生之日起,就是依靠接受人類理性認識的注入而發揮作用的。可是到今天,人們卻希望不再這樣,而是讓它自己去費力耗神地“學習”,儘管產生的僅僅是初級的感性認識。
這兩種看上去截然不同的態度,背後應該是基於同一個邏輯:讓人類自己省事。畢竟“外意識”自己去學習,主要耗費的不是人類自己的生命。但是這個出發點卻無視了一些最基本的客觀真實。
在人類真正掌握意識活動的基本規律之前,僅僅靠“外意識”自己獲得感性認識,恐怕遠遠不能滿足人類的需求,也遠遠不能發揮出擁有了“暴力計算”能力的“外意識”的巨大潛力。
在1980年代,美國用當時的超級計算機實現了對一些物理過程的模擬仿真。在報道的文章中,公佈了一個子彈斜着射穿鋼板全過程的計算機模擬結果及真實射擊的照片。在文章給出的多張對比圖片中,不論是鋼板還是子彈發生的變形,計算機仿真結果都與真實照片高度地相似。今天,隨着“暴力計算”時代的到來,做這類模擬仿真的CAE系統,依靠人類注入的物理學等方面的知識,可以在普通的服務器上高度逼真地復現各種物理過程。人類知識的注入,讓這類“外意識”真正理解掌握了物理定律,發揮着非常重要的作用。

1980年代,美國發明的超級計算機
或許有人會質疑:“靠人類的強行注入也能算機器有了自己的理解嗎?”如果這不算的話,那麼我們為什麼期望有朝一日在自己的腦袋上接上一些電極就可以把知識輸入到我們的內意識當中?對於習以為常的事情,我們常常反倒沒有能夠看清其真實面目。
對比之下,被有些人稱為“世界模擬器”的視頻生成器Sora依靠驚人的算力消耗,也僅僅是以“望文生義”的方式生成一些在視覺效果上可以亂真的視頻。它對物理世界運動規律的“理解”和“掌握”與CAE系統相比,有着天壤之別。

sora生成視頻中的人物有6根手指
培根曾經説過一句影響深遠的話:“知識就是力量”。這句話裏的知識是指理性認識的結果。理性認識的力量是遠遠高於感性認識的。對“外意識”也是如此。
在可預見的未來,以人類的理性認識注入為主體,以自己的感性認知為輔助,應該依然是絕大多數各種類型和功能的“外意識”發揮作用的基本模式。“外意識”擺脱對人類理性認識的依賴而靠自己的認知能力去獨闖天下的日子還遙不可期。當有一天“外意識”具有了普適可靠的理性認識能力的時候,我們再來談論通用人工智能,可能才會有比較充分的依據。
造物主創造了萬物之後,便高高在上冷漠地俯視着這個世界,所謂“天地不仁,以萬物為芻狗”。人類卻很不相同。我們自古就有個習慣,將自己的想象投射到自己的創造物上,然後跪倒在其腳下頂禮膜拜。哲學上有一個描述這種現象的專有名詞叫“異化”。當“暴力計算”讓我們成為了虛擬世界中貨真價實的造物主後,這種崇拜以及它帶來的恐慌反而更加嚴重。
要擺脱這種非理性的異化夢魘,深思熟慮而非望文生義地去透徹理解我們的創造物可能是唯一的出路。
本文摘自清華大學電子工程系博士謝耘新書《從凡夫到“上帝”》第四章:理解,知識與人工智能

本文系觀察者網獨家稿件,文章內容純屬作者個人觀點,不代表平台觀點,未經授權,不得轉載,否則將追究法律責任。關注觀察者網微信guanchacn,每日閲讀趣味文章。
