【環球時報2024年終報道】2024,AI開始改變世界
作者:刘扬 欧阳子涵 武彦
【環球時報記者 劉揚 歐陽子涵 環球時報特約記者 武彥】編者按:人工智能(AI)技術在經歷幾年的高速發展後,終於在2024年開始取得井噴式爆發的成果應用。無論是今年年初文生視頻大模型Sora帶來的巨大沖擊,還是全球多地自動駕駛汽車的普及、AI機器人開始在各行各業投入使用,或者是今年年底“美眾議院提交1547頁預算被AI精簡到116頁”的牛刀小試,都展現出AI技術正在深入我們的日常生活。但與此同時,AI發展可能帶來的一系列問題,從加深全球範圍的技術鴻溝、挑戰傳統社會的倫理價值觀、泄露個人隱私和構成新的網絡安全,以及AI對於能源的巨大消耗、全球可用訓練數據的“緊缺”等,也日益引起各國的高度關注,成為AI未來進一步發展面臨的挑戰。
AI應用落地元年,介入生活方方面面
2024年被稱為是AI應用落地的元年,各種AI應用開始深入到我們日常生活的方方面面。例如12月12日美國著名AI企業OpenAI公司旗下的ChatGPT聊天助手突然斷網數小時,竟引發大範圍混亂,許多依賴OpenAI API開展項目的公司也受到影響,“ChatGPT崩了”直接衝上微博熱搜,足以證明AI對於現代生活的介入有多廣泛。

北京郵電大學人機交互與認知工程實驗室主任劉偉接受《環球時報》記者採訪時表示,2024年之所以被認為是AI應用落地的元年,大都源於這一年AI技術在多個領域取得了顯著的進展,許多創新型應用開始向實際場景擴展併產生影響。其中一些在2024年表現突出的AI應用,不僅展示了技術的成熟,也代表了行業發展的重要趨勢。
首先值得一提的是生成式AI的廣泛應用。例如2024年2月,OpenAI公司發佈的文生視頻大模型Sora通過對內容對齊的文本句子和圖像/視頻數據之間關聯關係學習,具備模擬和重建物理世界視頻所刻畫複雜現象的能力,將人工智能內容生成從文本內容生成躍升到多模態內容生成,被喻為“視頻世界模擬器”。Sora帶來的巨大沖擊,使它被中國工程院列為“2024全球十大工程成就”之一。同時生成式AI在文本、圖像、音頻和視頻等內容創作方面繼續取得突破。AI寫作工具不僅可以生成新聞報道,還能創作小説、詩歌等複雜的文學作品;AI圖像生成工具如DALL·E能夠根據簡短的文字描述生成複雜的圖像,廣泛應用於設計、廣告、娛樂等行業,提升了品牌和客户之間的互動質量,AI助手也在客户支持領域變得更加智能,能夠處理複雜的查詢和任務,未來可能在創意產業、教育、科研等多個領域大規模應用,推動知識生產和娛樂內容創作的效率提升。
第二是自動駕駛與智能交通的廣泛落地。2024年,自動駕駛技術在城市公共交通、長途貨運以及消費者汽車等領域迎來了新的發展里程碑。各大自動駕駛公司(如Waymo、百度Apollo、特斯拉等)已在多個城市開展自動駕駛出租車服務,且技術的成熟度不斷提高。自動駕駛的感知、決策、規劃能力得到了進一步優化,尤其是在複雜城市環境中的表現更為突出。AI被廣泛應用於城市交通管理,自動化調度、交通流量優化、事故預警等系統的部署,使得交通更加智能和高效。AI算法還能夠對交通事故和擁堵進行快速預測與響應。自動駕駛和智能交通代表了AI與物聯網(IoT)結合的趨勢,推動了智慧城市的建設。隨着技術的成熟,自動駕駛和智慧交通將成為解決城市交通擁堵和能源消耗等問題的關鍵手段。
第三是醫療AI的加速普及,特別是在診斷支持和個性化治療方面的進展。AI被用於圖像識別,幫助醫生更快速地診斷疾病,尤其是在腫瘤檢測、眼科、皮膚病等方面的表現顯著。AI診斷系統的準確性不斷提高,有助於提升醫療效率和診療質量。另外,AI在藥物研發、基因組學分析以及個性化治療方案的制定中發揮了重要作用,AI模型可以通過對大量醫學文獻、臨牀數據以及基因信息的分析,發現潛在的新藥物靶點或預見疾病發展的模式。
第四是工業AI與製造業智能化。2024年,AI技術在工業自動化和智能製造領域的應用取得了顯著進展。AI通過即時監控和數據分析,能夠預測設備故障並提前進行維護,減少了停機時間和維護成本。在製造業中,AI被應用於生產過程的優化,能夠自動調整生產參數,提升生產效率和產品質量,AI還與機器人、物聯網技術結合,形成了高度自動化的生產系統。工業AI的普及代表了製造業智能化轉型的趨勢,企業通過AI的引入,可以實現更高效、更靈活的生產流程,同時提高產品質量和降低生產成本。
第五是語言理解與跨語言AI技術不斷取得突破,尤其是在自然語言處理和跨語言翻譯方面。AI在即時翻譯和語言理解上的能力有了大幅提升,尤其是在多語言支持的場景下,幫助不同語言和文化背景的用户之間消除了溝通障礙。AI的情感分析能力進一步增強,能夠精準識別用户的情緒狀態,為客户提供更具人性化的服務體驗。自然語言處理的進展代表了跨語言溝通與全球化的趨勢,將極大促進全球信息交流與合作。
總而言之,2024年,AI技術的快速落地不僅展示了其強大潛力,也表明AI將在未來幾年深刻影響各行各業。
擁抱AI時代,全球南北方態度有差異
《環球時報》記者注意到,儘管AI在全球範圍內掀起熱潮,但受限於工業化能力、數字化能力、人工智能技術等稀缺能力的分佈不均,導致了國家間、地區間的能力鴻溝,且鴻溝有持續擴大的趨勢。
環球時報研究院2024年發佈的《中國AI經驗在全球南方的應用機遇》研究報告顯示,發展AI的數字鴻溝首先體現在全球數字資源分佈不均上。當前,如OpenAI等主流平台主要基於英語數據資源構建。對於包括中國在內的全球南方國家而言,數字資源特別是語料數據的開發利用與保護程度,相較於英語類數據資源,在數據規模和質量上仍存在明顯差距。
其次,算力與算法差異也構成顯著挑戰。全球數字資源分佈不均,形成數據能力差距。數字鴻溝不僅體現於技術可獲得性,還包括數據使用能力、效率及最終收穫效果的不均。長期以來,全球南方國家享受到的數字發展紅利有限,一定程度上被排斥在發達國家及科技巨頭構築的信息壁壘之外。這導致南北差距的進一步擴大,並加劇了發展中國家在全球數字秩序中的邊緣化地位。非洲地區的54個國家中近半數缺乏本土數據中心,其數據被迫存儲於國外,核心數據資源受控於他國領土內。算力與技術落後又會進一步加劇數據偏差與算法偏差,最終影響到應用層面的準確性和完整性,甚至可能產生歧視性結果或無法有效回應宗教文化語言差別較大地區的應用需求。
再次,能源成本及供應穩定性問題,在一定程度上限制了全球南方國家本土人工智能的發展能效。人工智能發展對資源與能源的需求呈現出指數級增長態勢,對電力供應成本與穩定性也有極高的要求。在電力成本高昂或供電不穩的國家,AI產業的部署與擴展面臨顯著挑戰。同時,全球南方國家正處於能源轉型的關鍵時期,其從傳統煤電向新能源的轉變進程尚存在不確定性。轉型速度若未能與AI產業發展的能源需求相匹配,將導致算力提升遭遇能源供應瓶頸,拉大這些國家或地區數字鴻溝。

此外,大模型具備的問答功能,雖然促進了全球知識與文化的交流融合,但不同國家和地區的民眾向大模型提問時,回答的數據來源都掌握在同樣的機構手裏,其結果有很大可能消弭了文化的多元性,以及一些國家和社會獨特的社情民意與價值體系。
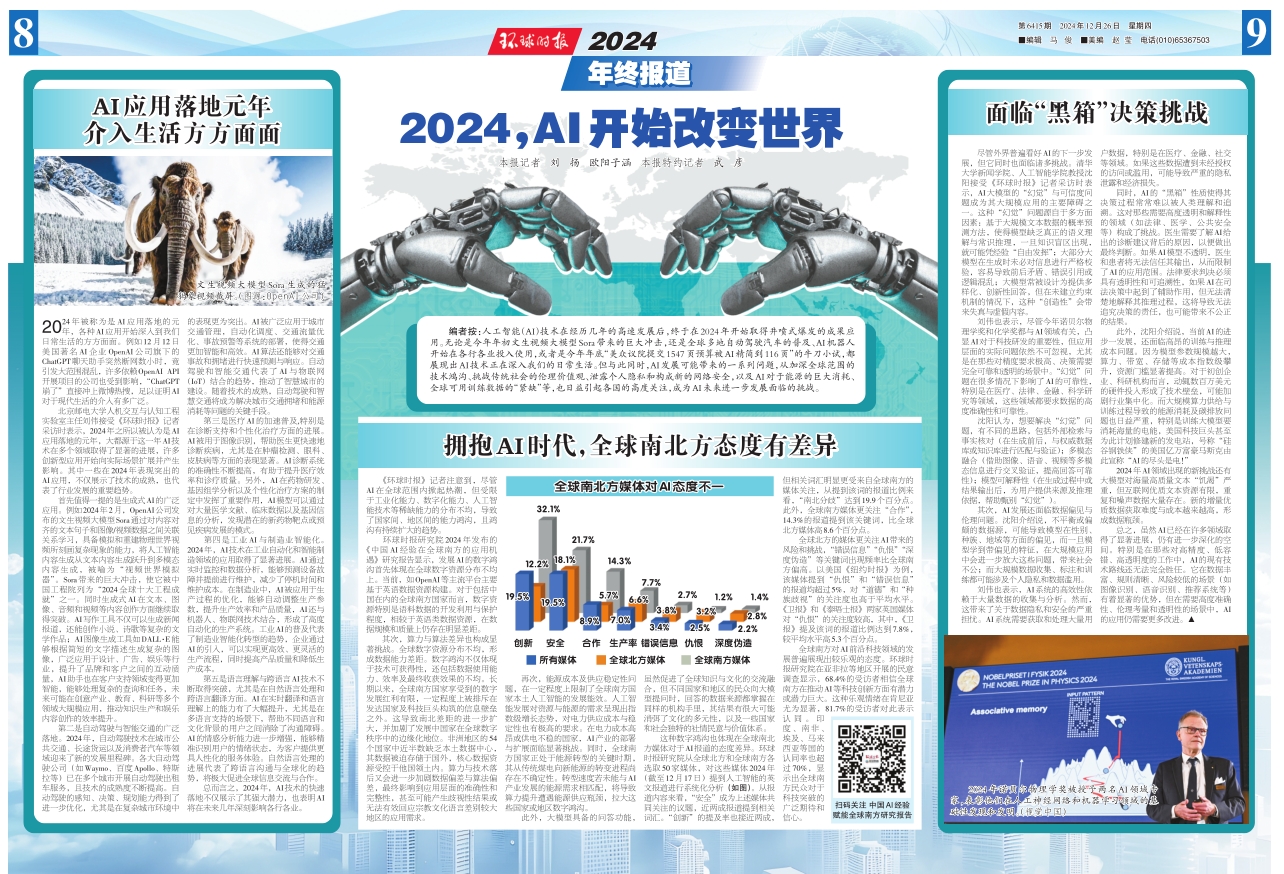
這種數字鴻溝也體現在全球南北方媒體對於AI報道的態度差異。環球時報研究院從全球北方和全球南方各選取50家媒體,對這些媒體2024年(截至12月17日)提到人工智能的英文報道進行系統化分析(如圖)。從報道內容來看,“安全”成為上述媒體共同關注的議題,近兩成報道提到相關詞彙。“創新”的提及率也接近兩成,但相關詞彙明顯更受來自全球南方的媒體關注,從提到該詞的報道比例來看,“南北分歧”達到19.9個百分點。此外,全球南方媒體更關注“合作”,14.3%的報道提到該關鍵詞,比全球北方媒體高8.6個百分點。
全球北方的媒體更關注AI帶來的風險和挑戰,“錯誤信息”“仇恨”“深度偽造”等關鍵詞出現頻率比全球南方偏高。以美國《紐約時報》為例,該媒體提到“仇恨”和“錯誤信息”的報道均超過5%,對“道德”和“種族歧視”的關注度也高於平均水平。《衞報》和《泰晤士報》兩家英國媒體對“仇恨”的關注度較高,其中,《衞報》提及該詞的報道比例達到7.8%,較平均水平高5.3個百分點。
全球南方對AI前沿科技領域的發展普遍展現出較樂觀的態度。環球時報研究院在亞非拉等地區開展的民意調查顯示,68.4%的受訪者相信全球南方在推動AI等科技創新方面有潛力或潛力巨大。這種樂觀情緒在肯尼亞尤為顯著,81.7%的受訪者對此表示認同。印度、南非、埃及、馬來西亞等國的認同率也超過70%,顯示出全球南方民眾對於科技突破的廣泛期待和信心。
面臨“黑箱”決策挑戰
儘管外界普遍看好AI的下一步發展,但它同時也面臨諸多挑戰。清華大學新聞學院、人工智能學院教授瀋陽接受《環球時報》記者採訪時表示,AI大模型的“幻覺”與可信度問題成為其大規模應用的主要障礙之一。這種“幻覺”問題源自於多方面因素:基於大規模文本數據的概率預測方法,使得模型缺乏真正的語義理解與常識推理,一旦知識盲區出現,就可能憑經驗“自由發揮”;大部分大模型在生成時未必對信息進行嚴格校驗,容易導致前後矛盾、錯誤引用或邏輯混亂;大模型常被設計為提供多樣化、創新性回答,但在未建立約束機制的情況下,這種“創造性”會帶來失真與虛假內容。
劉偉也表示,儘管今年諾貝爾物理學獎和化學獎都與AI領域有關,凸顯AI對於科技研發的重要性,但應用層面的實際問題依然不可忽視,尤其是在那些對精度要求極高、決策需要完全可靠和透明的場景中。“幻覺”問題在很多情況下影響了AI的可靠性,特別是在醫療、法律、金融、科學研究等領域,這些領域都要求數據的高度準確性和可靠性。
瀋陽認為,想要解決“幻覺”問題,有不同的思路,包括外部檢索與事實核對(在生成前後,與權威數據庫或知識庫進行匹配與驗證);多模態融合(藉助圖像、語音、視頻等多模態信息進行交叉驗證,提高回答可靠性);模型可解釋性(在生成過程中或結果輸出後,為用户提供來源及推理依據,幫助甄別“幻覺”)。
其次,AI發展還面臨數據偏見與倫理問題。瀋陽介紹説,不平衡或偏頗的數據源,可能導致模型在性別、種族、地域等方面的偏見,而一旦模型學到帶偏見的特徵,在大規模應用中會進一步放大這些問題,帶來社會不公;而大規模數據收集、標註和訓練都可能涉及個人隱私和數據濫用。
劉偉也表示,AI系統的高效性依賴於大量數據的收集與分析。然而,這帶來了關於數據隱私和安全的嚴重擔憂。AI系統需要獲取和處理大量用户數據,特別是在醫療、金融、社交等領域。如果這些數據遭到未經授權的訪問或濫用,可能導致嚴重的隱私泄露和經濟損失。
同時,AI的“黑箱”性質使得其決策過程常常難以被人類理解和追溯。這對那些需要高度透明和解釋性的領域(如法律、醫學、公共安全等)構成了挑戰。醫生需要了解AI給出的診斷建議背後的原因,以便做出最終判斷。如果AI模型不透明,醫生和患者將無法信任其輸出,從而限制了AI的應用範圍。法律要求判決必須具有透明性和可追溯性,如果AI在司法決策中起到了輔助作用,但無法清楚地解釋其推理過程,這將導致無法追究決策的責任,也可能帶來不公正的結果。
此外,瀋陽介紹説,當前AI的進一步發展,還面臨高昂的訓練與推理成本問題。因為模型參數規模越大,算力、帶寬、存儲等成本指數級攀升,資源門檻顯著提高。對於初創企業、科研機構而言,動輒數百萬美元的硬件投入形成了技術壁壘,可能加劇行業集中化。而大規模算力供給與訓練過程導致的能源消耗及碳排放問題也日益嚴重,特別是訓練大模型要消耗海量的電能,美國科技巨頭甚至為此計劃修建新的發電站,號稱“硅谷鋼鐵俠”的美國億萬富豪馬斯克由此宣稱“AI的盡頭是電!”
2024年AI領域出現的新挑戰還有大模型對海量高質量文本“飢渴”嚴重,但互聯網優質文本資源有限,重複和噪聲數據大量存在。新的增量優質數據獲取難度與成本越來越高,形成數據瓶頸。
總之,雖然AI已經在許多領域取得了顯著進展,仍有進一步深化的空間。特別是在那些對高精度、低容錯、高透明度的工作中,AI的現有技術路線還無法完全勝任。它在數據豐富、規則清晰、風險較低的場景(如圖像識別、語音識別、推薦系統等)有着顯著的優勢,但在需要高度準確性、倫理考量和透明性的場景中,AI的應用仍需要更多改進。