美國算力管制,擋不住中國大模型_風聞
正解局-正解局官方账号-洞察产业/城市/企业,正解中国成长的力量。55分钟前

 中美又在AI領域隔空交手了。
中美又在AI領域隔空交手了。
1月13日,美國曆史上第一個人工智能出口管制規則出台,對先進計算芯片以及閉源AI模型實施新的管控措施,向中國等國家出口高端AI芯片和閉源AI大模型幾乎被全面禁止。
而72個小時之內,中國這邊也迅速給出了回應。作為央國企大模型產品的首選,科大訊飛全網直播,高調發布了星火語音同傳大模型,和全面升級了底座能力的訊飛星火4.0 Turbo,以及當前唯一一個,在全國產算力平台上訓練的深度推理模型—訊飛星火X1。
星火X1的發佈,是一個歷史性的時刻,它證明了在長久的角逐之後,中國AI大模型的發展,終於初步擺脱了美國的限制。
 在過去幾年裏,大模型一直是中美競爭的焦點。從2022年的1007規則,到2023年的1017規則,再到2024年的1202規則。美國為了阻礙中國AI大模型的發展,以一年一次的速度,不斷升級芯片出口管制。這對美國而言,是相當驚人的行政效率。
在過去幾年裏,大模型一直是中美競爭的焦點。從2022年的1007規則,到2023年的1017規則,再到2024年的1202規則。美國為了阻礙中國AI大模型的發展,以一年一次的速度,不斷升級芯片出口管制。這對美國而言,是相當驚人的行政效率。
然而與此同時,中國的大模型技術卻同樣日新月異,從2022年諸多公司緊隨chatgpt入局;到2023年百模大戰,文生文、文生圖等應用產品井噴;再到2024年,訊飛星火等第一陣營產品趕超世界一流水平。數據顯示,2023年8月至2024年10月,中國大模型指數從100點基數增長至260.16點,增長了1.60倍,月均複合增長率達7.07%。
為什麼美國已經盡其所能,中國的大模型依然高速狂飆?這是一個複雜的問題,其主要原因之一,就是中國自有算力平台的成熟。這次的星火成功,就是象徵。

 中國大模型快速進步的動力之一,就是既有自主算力,又有願意吃螃蟹的大模型廠商。
中國大模型快速進步的動力之一,就是既有自主算力,又有願意吃螃蟹的大模型廠商。
許多人不知道,美國在AI領域壟斷的不僅是算力,還有軟件生態。為什麼全球絕大多數AI廠商,都必須購買英偉達的GPU產品?除了其硬件設計與性能外,還因為英偉達開發的CUDA,是當下最成熟和完善的並行計算平台和編程模型。這才是高通、AMD、英特爾等同樣實力強大的芯片廠商,都望洋興嘆,難以從AI市場分一杯羹的核心原因,因為CUDA生態,基本只能使用英偉達的硬件。
所以,華為昇騰等國產算力打出一片天不容易。但是利用國產算力,訓練大模型,同樣是個艱難的過程。
早在2023年,華為就通過整合雲、存儲、算力等先進技術,構築新型算力基礎設施。但是因為成本和易用性問題,應者寥寥。只有堅持全國產化的科大訊飛,聯合華為推出國內首個萬卡規模大模型算力平台“飛星一號”,並在之後一年多里,成功攻克了數據構建、框架調優、模型驗證等一系列難題,將訊飛星火大模型持續迭代至V4.0,全面對標GPT-4 Turbo。終於證明,基於國產算力打造自主可控通用大模型底座,是完全可行的。
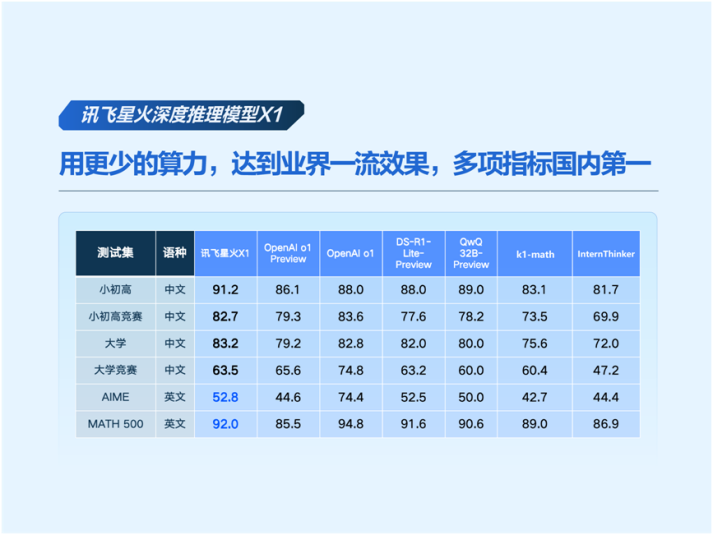
 而這次發佈的深度推理訓練模型訊飛星火X1,則是國產算力集羣對標國外的又一關鍵里程碑。
而這次發佈的深度推理訓練模型訊飛星火X1,則是國產算力集羣對標國外的又一關鍵里程碑。
與通用大模型相比,X1的解題過程更接近人類的“慢思考”方式。在發佈會上,訊飛星火X1解答高考題、AIME競賽題以及高中奧賽題,不僅準確給出了這些題目的答案,更重要的是,它還對解題思路和步驟進行了詳細拆解。像人類一樣,懂得將問題化繁為簡,複雜問題簡單化;同時能自我探索和反思驗證;最後還依據答案正確與否進行強化訓練。
很容易想象,星火X1在教育領域有着極高的應用價值,已經有一線教研員和教師用它來解答高中數學創新題,並因此大獲好評。而教育之外,科大訊飛也聯合多家頂尖醫院,利用星火X1打造了多款針對特定疾病的大模型,顯著提升了人工智能輔診效果。可以説,星火X1的發佈,證明中國大模型的探索,正在進入一個新的歷史階段。
除了技術和生態的進步,中國大模型還有一個殺手鐧,那就是數據。

 大模型的競爭,數據為王。
大模型的競爭,數據為王。
眾所周知,大模型的能力不是虛空產生的,而是必須利用數據集來訓練,可以説,算法和算力決定了大模型的下限,而數據集質量決定了上限。所以大模型的本質,就是過去積累數據的一種有效利用。
得數據者得天下,而這恰好是美國的短板。其雖然算力更充沛,大模型技術也相對先進,但是由於美國的產業處於衰退週期,因此數據存量和電力一樣,無法憑空創造出來。
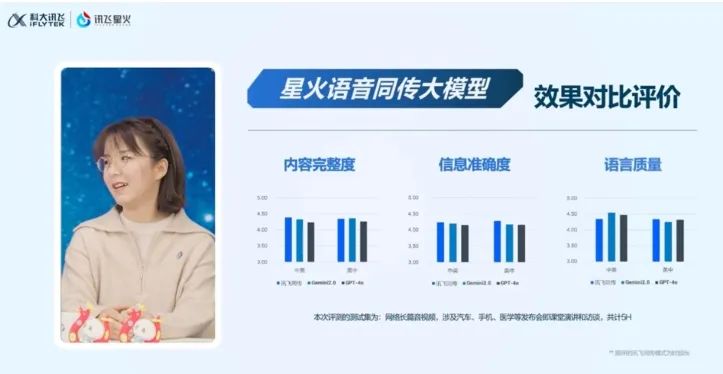
因此在過去幾年,中國需要大量專業數據的行業大模型百花齊放,滲透千行百業。最近的案例,就是這次科大訊飛針對難度最高的同傳翻譯,正式發佈的國內首個具備端到端語音同傳能力的大模型——星火語音同傳大模型。
在這次發佈會上,科大訊飛展示了星火語音同傳大模型技術的應用效果。其不僅翻譯效果更準確流暢,而且首次響應時間縮短到5秒之內,在多種場景下實現了交流的無延遲。甚至其能跟熟練的資深同傳翻譯一樣,根據“順句驅動”原則,自動對碎片化信息進行重組,確保整個翻譯過程更加流暢。
 為什麼星火大模型的性能如此強大?
為什麼星火大模型的性能如此強大?
其原因非常樸實無華:作為長期以來的翻譯界扛把子,早在2018年,科大訊飛的翻譯機,就成功通過了全國翻譯專業資格考試,並連續多年在國際口語機器翻譯比賽中奪冠。完全可以説一句,沒人比我更懂翻譯。而星火大模型的性能,只是科大訊飛在翻譯領域技術的延伸與昇華。
根據科大訊飛透露,在2025年,針對語音到語音同傳場景的訊飛翻譯機,就將推出商務套裝,配置耳機、音箱、麥克風等產品中,滿足用户的使用需求。能夠預見,全球交流無障礙的時代即將到來。
可以説,當前中國在大模型領域的競爭中,已經佔據了一部分優勢,不僅性能迎頭趕上,而且在實用性上更勝一籌。

 與美國相比,中國的大模型競爭,要殘酷得多。
與美國相比,中國的大模型競爭,要殘酷得多。
與美國資本市場依然將大模型視為孵化中的藍海,擁有幾乎無限的耐心相比,中國的大模型領域早已進入紅海的絞殺戰,各個產品從拼算力到燒營銷再到比應用,敗者一無所有,而勝者的獎勵是進入下一輪。數據顯示,2023年,中國上線的大模型數以百計,而在殘酷的競爭下,到2024年底,依然保持着更新與活力的產品十不足一。
這對想要講故事拼概念的企業不是好消息。但也讓以實用説話的大模型迅速迭代,脱穎而出。時代週刊曾感嘆,目前中國的一些AI大模型,已經通過軟件和算法的優化,把芯片性能發揮到了極致,在表現能力上反超了有尖端芯片的美國大模型。
實際上,科大訊飛等在大模型競爭中佔優的企業,其共同特徵就是從沒有抱過僥倖心理,“大模型發展,應用才是硬道理”。
在本次發佈會中,我們可以看到,訊飛的大模型產品,所有性能的“應用場景”都一目瞭然。星火X1除了賦能教師教學,也能使科大訊飛AI學習機學習推薦和診斷將變得更加精準,助力孩子學習更省時、爸媽輔導更省心。
而作為央國企首選的大模型,訊飛星火4.0 Turbo底座能力也迎來了全面升級,除了七大核心能力全面提升,全面對標OpenAI最新版的GPT-4o之外,更重要的是在行業理解能力上實現了顯著提升,成為了更懂行業的大模型。
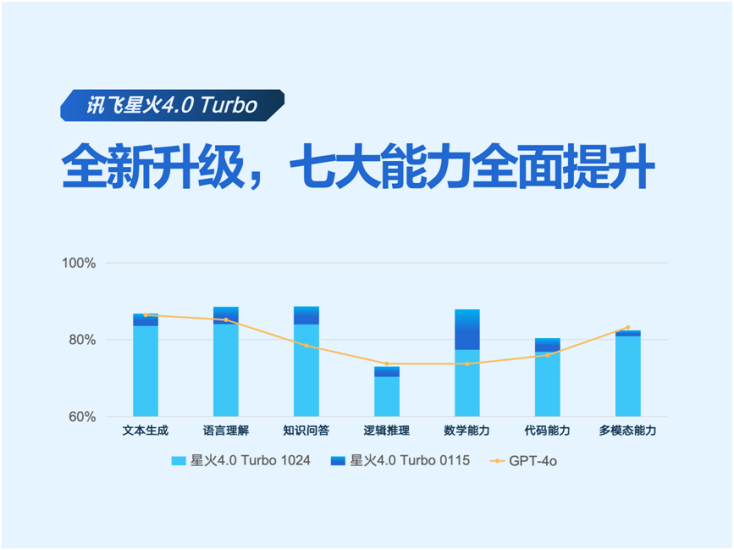 升級後的星火,不僅複雜表格和潦草筆記難不倒,還開發了基於智能體的全新長文本框架,對長文本注意力機制進行了優化,並首發了混域知識搜索技術。這項技術能夠實現對個人知識、企業知識、業務系統數據、精品行業數據以及互聯網信息的綜合搜索,用户只需一次提問,即可獲得綜合搜索後的結果,大大提升信息搜索效率。
升級後的星火,不僅複雜表格和潦草筆記難不倒,還開發了基於智能體的全新長文本框架,對長文本注意力機制進行了優化,並首發了混域知識搜索技術。這項技術能夠實現對個人知識、企業知識、業務系統數據、精品行業數據以及互聯網信息的綜合搜索,用户只需一次提問,即可獲得綜合搜索後的結果,大大提升信息搜索效率。
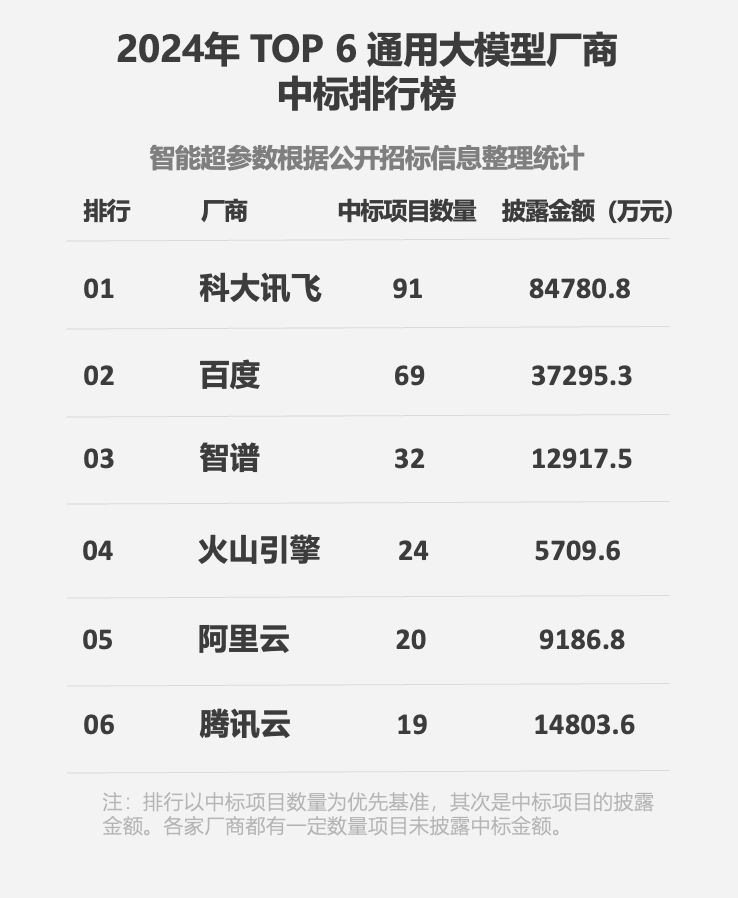
當前,科大訊飛的大模型產品,因為極強的實用性,正在超越央國企大模型首選的定位,成為市面上最受歡迎的產品之一。根據《中國大模型中標項目監測報告》顯示,2024年,中國1107箇中標項目披露的金額達到64.67億元,相比去年增長7.2倍。而其中訊飛拿下了其中91個,中標金額達到8.47億元位居首位,超過第二名一倍以上。而在C端,科大訊飛的大模型產品,用户已經超過2億。
 科大訊飛,正是中國大模型發展的縮影,面對技術封鎖迎難而上,同時深入千行百業,變得更有生命力。
科大訊飛,正是中國大模型發展的縮影,面對技術封鎖迎難而上,同時深入千行百業,變得更有生命力。
這樣的產品,是不會被封鎖和管制所打倒的。