只有模仿沒有創新?國產AI用行動打破質疑_風聞
极客公园-极客公园官方账号-1小时前

MiniMax,選擇用開源「震撼」一下全球同行。
作者 | Li Yuan
編輯| 鄭玄****
大模型時代已經正式邁入第三年。
回首過去的兩年,不禁令人感慨。每年都有基座大模型架構已經塵埃落定的聲音,然而每年,技術都在飛快地迭代創新,突破人們想象。
2024 年,OpenAI 的推理模型,通過對模型架構的創新,用 RL 的方法延續 Scaling Law,讓大模型的智力水平持續進展;而中國公司也並沒有落後,價格屠夫 DeepSeek 通過 MLA 的架構創新,讓推理成本直接降低了一個數量級。
2025 年開年,令人欣喜的是,我們看到了一向在人們印象中是「低調做產品」的 MiniMax 公司,也加入了開源行列,將最先進的底層技術直接與社區和行業分享。
1 月 15 日,大模型公司 MiniMax 正式發佈了 MiniMax-01 系列模型。它包括基礎語言大模型 MiniMax-Text-01,和在其上集成了一個輕量級 ViT 模型而開發的視覺多模態大模型 MiniMax-VL-01。
開源界面|圖片來源:GitHub
「卷」起來的大模型公司,令人樂見。開源會提升創新效率,越來越好的基座模型之上,才搭建越來越有用的應用,進入千家萬户,幫人們解放生產力。
這是 MiniMax 第一次發佈開源模型,一出手就是一個炸裂模型架構創新:新模型採用了 MiniMax 獨有的 Lightening Attention 機制,借鑑了 Linear Attention(線性注意力)機制,是全球第一次將 Linear Attention 機制引入到商業化規模的模型當中。
效果也是立竿見影,模型上下文長度直接達到了頂尖模型的 20-32 倍水平,推理時的上下文窗口能達到 400 萬 token。模型效果立刻在海外上引起了關注。
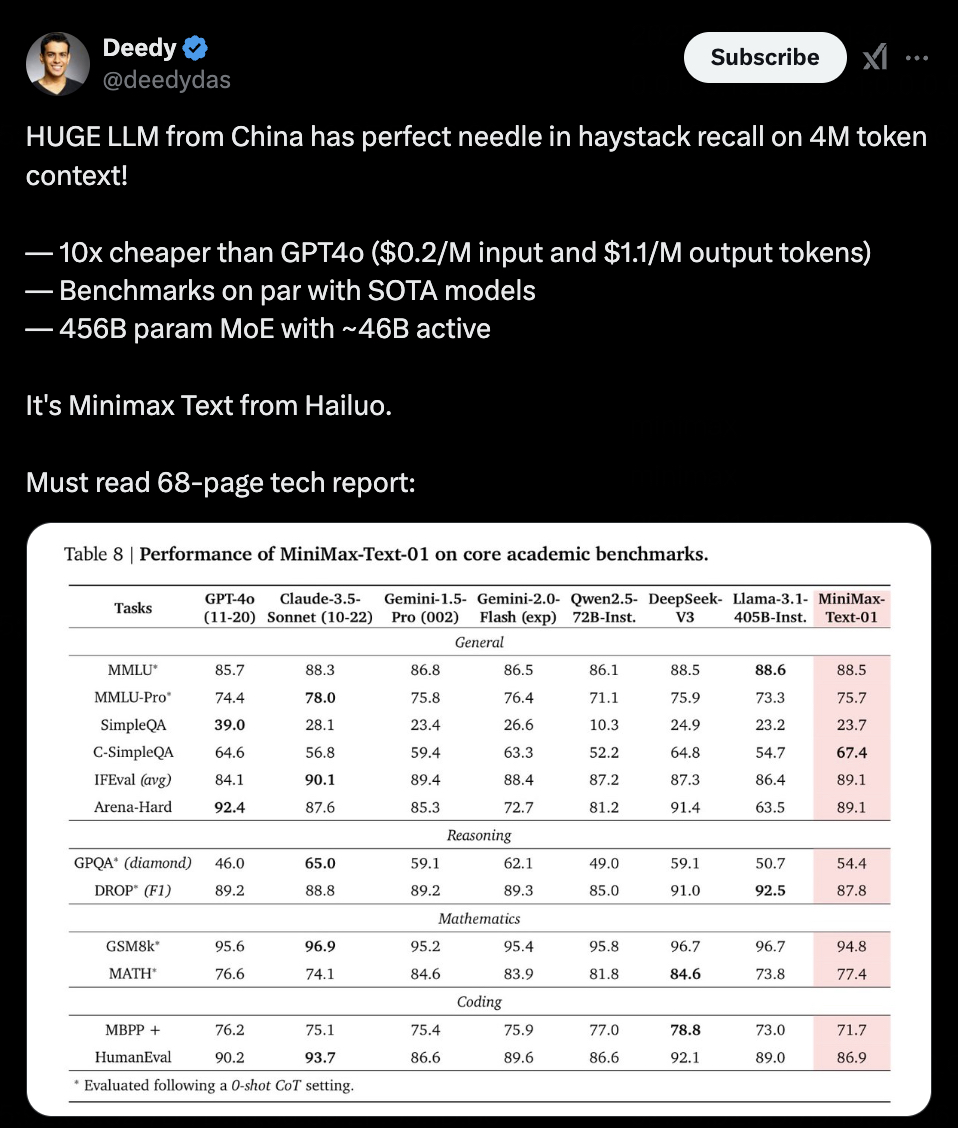
X 用户感嘆 MiniMax-Text-01 可以在 400 萬 token 上實現完美的海底撈針 | 圖片來源:X
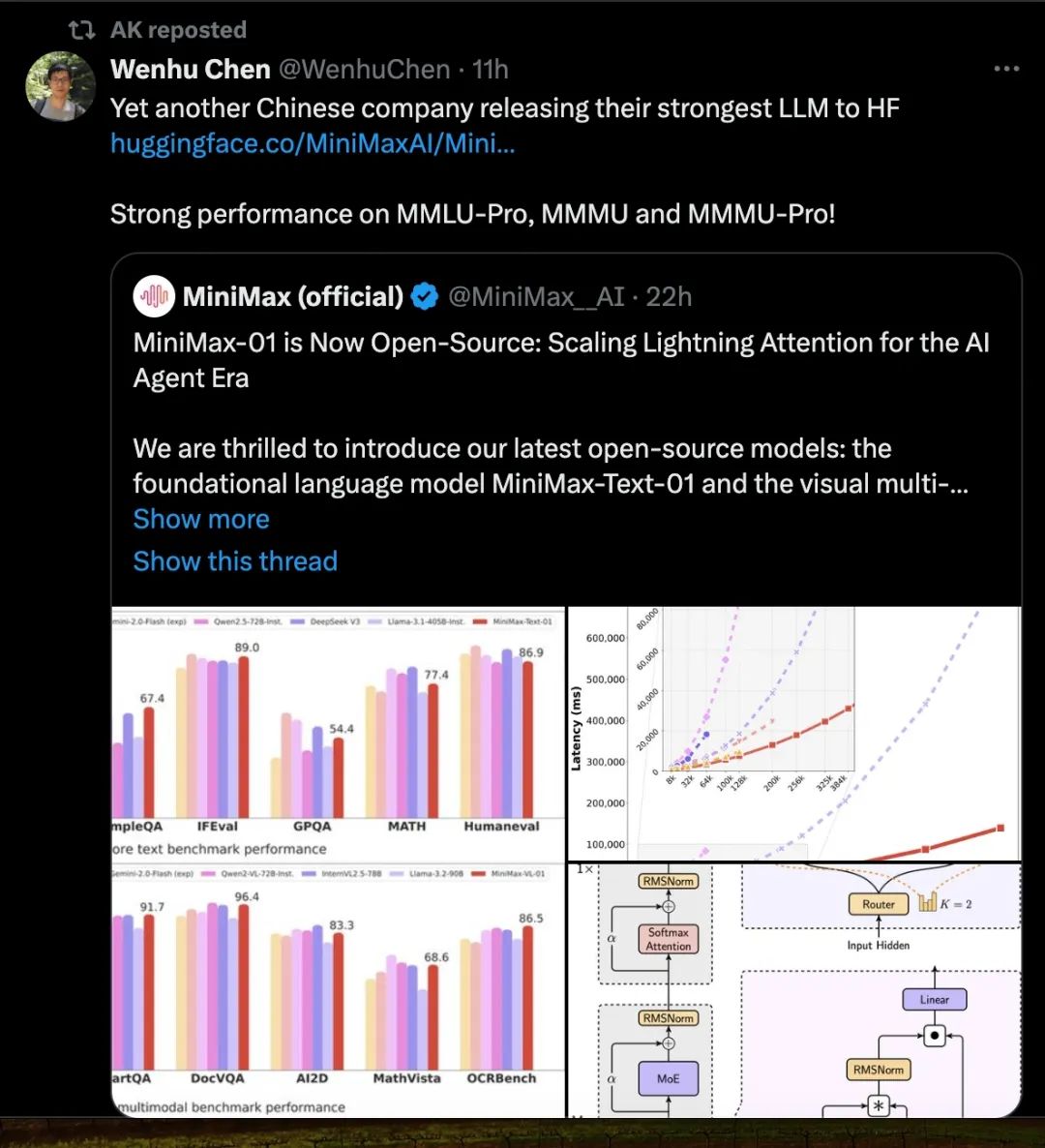
另一個來自中國公司的強大模型,在學術測試集上表現優越|圖片來源:X
模型的上下文窗口,指的是模型在生成每個新 token 時,實際參考的前面內容的範圍。就像是模型能夠一次性從書架上取下的書籍數量。模型的上下文窗口越大,模型生成時可以參考的信息量就越多,表現也就更加智能。
站在 2025 年年初的時間點,長上下文窗口還有一個新的意義:為模型的 Agent 能力,打下堅實基礎。
業界公認,2025 年,Agent 能力將是 AI 屆「卷生卷死」的重點,連 OpenAI 都在本週內推出了 Tasks,一個 AI Agent 的雛型。在 2025 年,我們很有可能看到越來越多真正「全自動的」AI,在我們的生活中起作用。甚至不同「全自動的」的 AI 共同協作,幫我們處理事務。而這對基座模型的能力,有極大的考驗。而長上下文是 Agent 能力實現的必要條件。
看起來,2025 年,基座大模型之戰仍未結束;中國公司發力,也才剛剛開始。
01
Linear Attention 架構
的第一次大規模使用
此次 MiniMax 開源的模型,最大的創新點,在於使用了 MiniMax 獨有的 Lightening Attention 機制,這是一種線性注意力。
在傳統的 Transformer 架構中,最「燒」算力和顯存的部分往往是自注意力(Self-Attention)機制。原因在於,標準的自注意力需要對所有的詞(Token)兩兩計算注意力分數,計算量隨着序列長度 n 的增長是平方級(O(n²))。
如果用通俗的語言來形容,類似於你在舉辦一場聯誼會,人很多。如果每個人都要兩兩打招呼,溝通成本會隨着人數增加而急劇上升,每個人都得重複無數次「握手」。
這帶來了一系列的問題——其中一個就是,聯誼會的人數,也就是模型的上下文的窗口,很難無限擴展。硬要擴展,對於算力的需求就非常高。
為了應對這一挑戰,傳統上,研究人員提出了各種方法來降低注意力機制的計算複雜度,包括稀疏注意力、Linear Attention(線性注意力)、長卷積、狀態空間模型和線性 RNN 等方式。
此次 MiniMax 開源的模型,就是借用了其中的 Linear Attention(線性注意力)的方式。
Linear Attention 的思路就像給會場安排了幾位「速配助理」。每個人先把自己的關鍵信息交給助理,比如「希望認識什麼樣的人、擅長什麼」。助理整理這些信息後,直接告訴每個人最適合交談的對象。這樣,大家不必一個個自我介紹,整個匹配過程更高效,溝通成本大幅降低。
不過,Linear Attention 之前雖然在理論上有所創新,但在商業規模模型中的採用有限。而 MiniMax 團隊則第一次驗證了 Linear Attention 機制在商業規模的大模型之上的可行性。
這意味着一項技術從實驗室走向真實世界。
MiniMax 團隊使用了一個傳統的 Linear Attention 的變種,被 MiniMax 團隊稱為 Lightning Attention。Lightning Attention 解決了現有 Linear Attention 機制計算效率中的主要瓶頸:因果累積求和操作的緩慢,使用新穎的分塊技術,有效規避了累加和操作。
在一些特定任務,如檢索和長距離依賴建模上,Lightning Attention 的性能表現可能不如 Softmax 注意力強。
MiniMax 團隊又引入了混合注意力機制解決這一問題:在最終的模型架構中,在 Transformer 的每 8 層中,有 7 層使用 Lightning Attention,高效處理局部關係;而剩下 1 層保留傳統的 Softmax 注意力,確保能夠捕捉關鍵的全局上下文。
這樣的架構創新,效果十分驚豔。
MiniMax-01 系列模型參數量高達 4560 億,其中單次激活 459 億。在主流模型目前的上下文窗口長度仍然在 128k 左右的時候,MiniMax-01 系列模型能夠在 100 萬 token 的上下文窗口上進行訓練,推理的時候上下文窗口可以外推到 400 萬 tokens,是 GPT-4o 的 32 倍,Claude-3.5-Sonnet 的 20 倍。
在面向現實情景,進行長上下文多任務進行深入的理解和推理的第三方測評 LongBench v2 的最新結果中,MiniMax-Text-01 僅次於 OpenAI 的 o1-preview 和人類,位列第三。
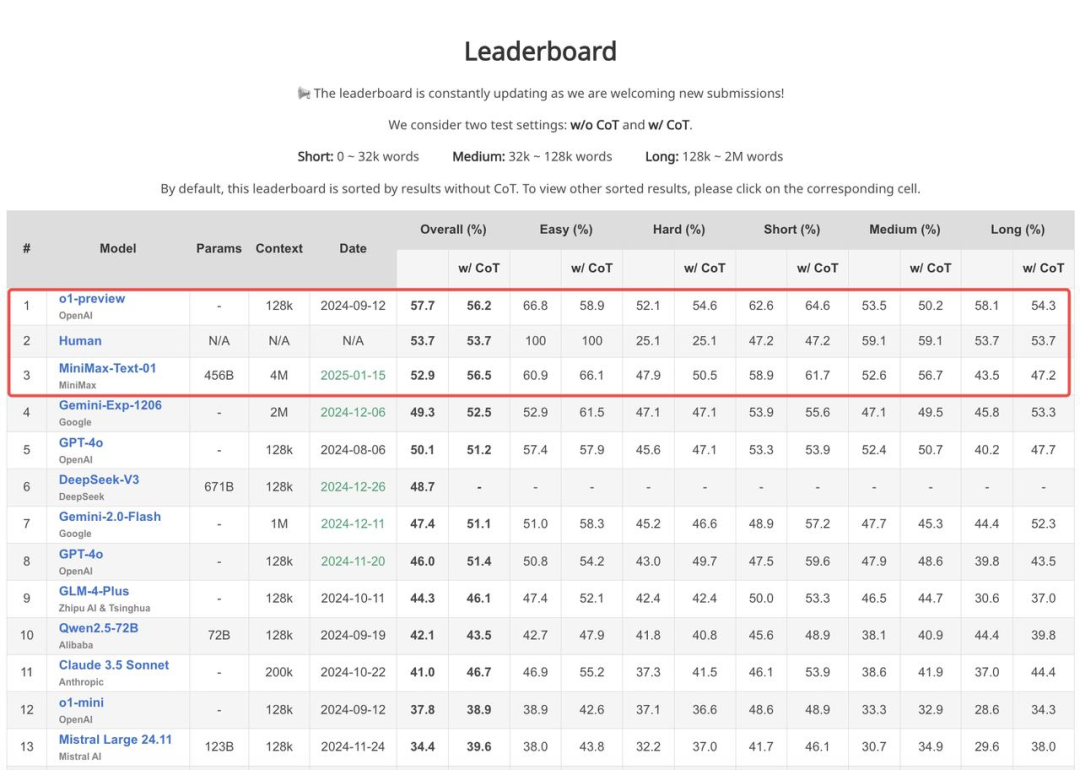
模型在 LongBench v2 上的評測表現 | 圖片來源:GitHub LongBench
在模型的基礎表現上,MiniMax-01 系列模型也在標準學術基準測試中可與頂級閉源模型相媲美。不僅如此,在模型上下文長度逐漸變長的過程中,模型的表現下降也最平緩——部分模型雖然宣佈上下文窗口長度較長,但真正使用起來,在長上下文情況下,效果並不好。
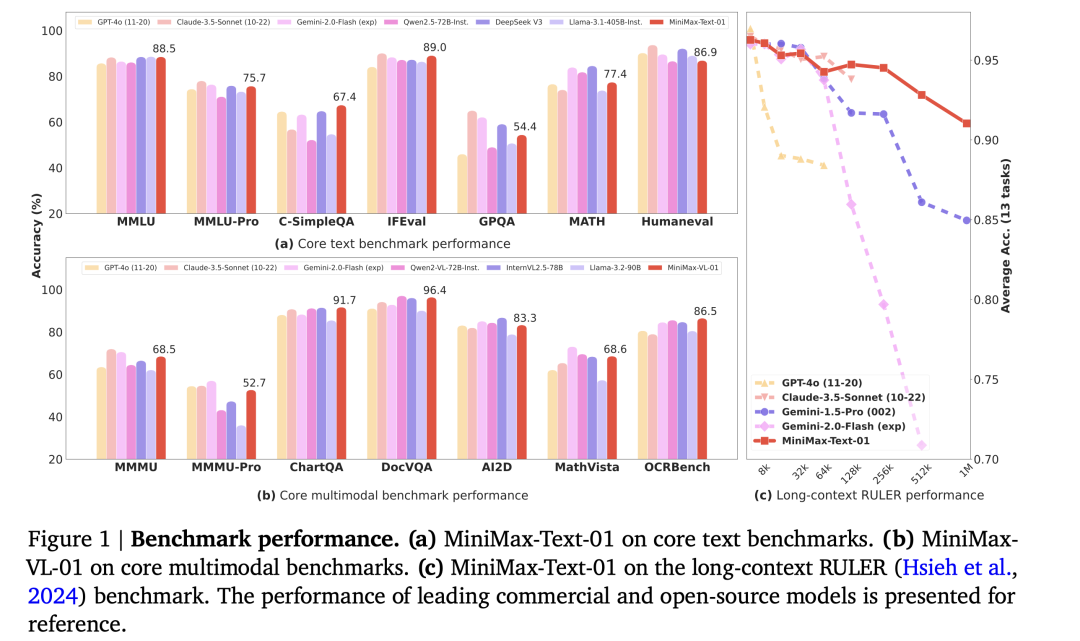
MiniMax-01 系列模型可與頂級閉源模型相媲美 | 圖片來源:MiniMax 論文
MiniMax 團隊對比了在 CSR(常識推理)、NIAH(大海撈針)和 SCROLLS 等基準測試上,在同樣的計算資源下,用採用了 7/8Lightning Attention 和 1/8 的 Softmax 的混合注意力模型可以放更多參數、處理更多數據,並且訓練效果還比只用 Softmax 注意力的模型更好,損失更低。
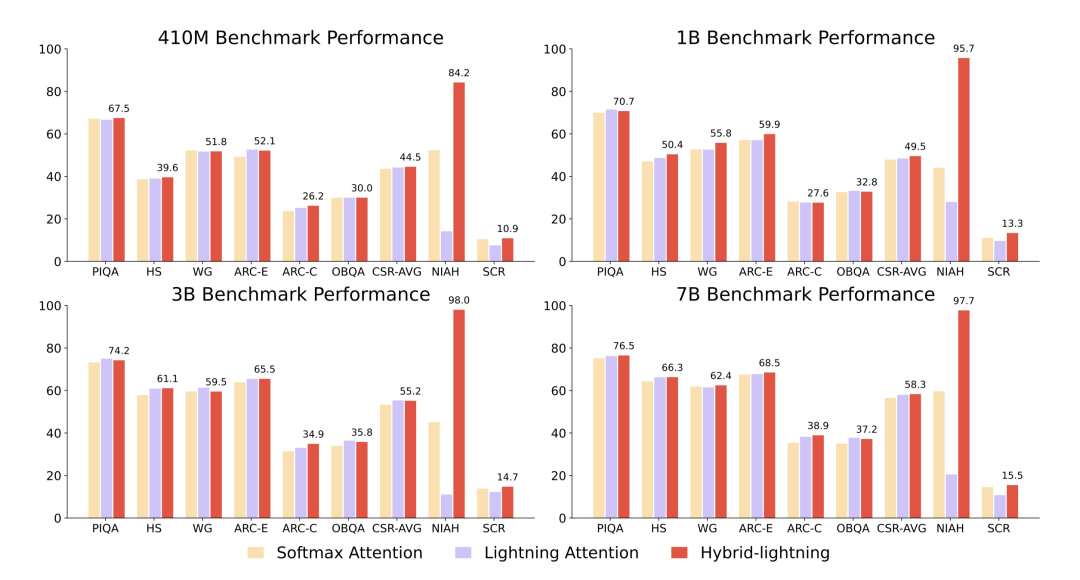
基準測試上混合 Lightning Attention 的架構表現更好 | 圖片來源:MiniMax 論文
02
為 Agent 時代爆發的前夜做準備
自 2024 年開始,長上下文一直是模型迭代的一個重要方向。
在這個領域,國外的 Google、Anthropic,國內的 Kimi,都是堅定的投入者。2024 年年末,DeepMind 的 CEO Demis Hassabis 曾表示,在內部測試中,Google Gemini 正在向無限上下文窗口發起衝擊。
或許有人會困惑,此次 MiniMax 發佈的 MiniMax-01 系列模型,上下文窗口長度已經達到 400 萬 token,如果按照兩個 token 約等於一箇中文漢字的計算方式,已經約等於 200 萬字的上下文窗口。人類需要和 AI 聊出這麼多的上下文嗎?
答案是,盯住長上下文的各家公司,可能盯住的並不是目前的一問一答的問答 AI 場景,而是背後的 Agent 時代。
無論是單 Agent 所需的持續記憶,還是多 Agent 協作所帶來的通信,長鏈路的任務都需要越來越長的上下文。
長上下文,在多種 Agent 應用場景中,將具有極大的意義。
在搜索場景中,這可能意味着用户可以一次性看到更多答案的綜合,直接獲得更精準的回答。
未來的效率工具中,這可能意味着用户擁有了無限的工作記憶。在無數版本的修改之後,當甲方讓你還是用第 1 版的文章結構和第三版的小標題的時候,你可以無痛回覆「好的」,然後讓 AI 一鍵生成兩個版本的融合。
未來的學習工具中,這可能意味着用户可以直接具有更大的知識庫。直接上傳一本教材,就能讓 AI 根據其中的內容,進行教學。
而在和 AI 助理的對話中,它將像聰明的人類助理一樣,真正記住你之前説過的話,並在你需要的時候「記起來」。MiniMax 團隊的論文當中的一個場景就很能説明問題。
模型被要求從最多 1889 條歷史交互(英文基準)或 2053 條歷史交互(中文基準)中精確檢索出用户的一條歷史互動——用户重複要求 AI 寫關於企鵝的詩歌,同時進行了多輪不相關的對話,而在最後,要求 AI 提供第一次寫的關於企鵝的詩。而 MiniMax-01 仍然很好地完成了這一任務。

長上下文的任務表現 | 圖片來源:MiniMax 論文
對於 Agent 來説,另一個重要能力,則是視覺理解——MiniMax 此次同系列也發佈了 MiniMax-VL-01。這是一個同樣採用了線性注意力架構、以及擁有 400w token 上下文窗口的視覺多模態大模型。
在 2024 年 Rayban-Meta 眼鏡爆火之後,今年的智能硬件的一大看點在於 AI 眼鏡能否真正讓 AI 成為人們的隨身助手。而能成為隨身 AI,AI 必須的能力就是長上下文——記住你的所有生活場景,才能在隨後為你提供個性化的提醒和建議。
這樣的記憶將是「真記憶」,與 ChatGPT 目前的記憶功能所能提供的簡易效果完全不同。
要真正實現隨身的 AI Agent,跨模態理解、無限上下文窗口都是基礎能力。
論文最後,MiniMax 表示未來將在線性注意力這一路徑上做到極致,嘗試完全取消 Softmax 注意力層,最終實現無限的長上下文窗口。
03
基座模型創新未死,中國公司大有可為
值得注意的是,這次是 MiniMax 公司,第一次推出開源模型。
此次的大模型命名的 MiniMax-01 系列,在 MiniMax 的內部序列中,原本是 abab-8 系列模型。
MiniMax 在上一代 abab-7 模型中,已經實現了線性注意力和 MOE 的架構,而在 abab-8 中,取得了更好的效果。
此次,MiniMax 選擇在這個時間點,將模型開源出來,並以這個節點為開始,重新命名模型 MiniMax-01。
這似乎代表着 MiniMax 的公司哲學的一種改變。
在過往,MiniMax 公司給外界一向的印象是:業務很穩定,做事很低調。
從星野、Talkie 到海螺 AI,MiniMax 有自己忠實的一波用户羣體。在去年的公開發布中,MiniMax 曾經表示每天已經有 3 萬億文本 token 的調用,在國內 AI 公司中名列前茅。
這些應用背後的 AI 技術則一直較為神秘,在此之前主要用於支持公司本身的業務。這次開源,似乎是一個轉折,是 MiniMax 第一次對外高調展示技術實力。
MiniMax 方面表示,模型可以在 8 個 GPU 單卡、640GB 內存上,就能夠實現對 100 萬 token 進行單節點推理。希望此次開源幫助其他人開發能夠突破當前模型的侷限。
回顧過往,自 OpenAI 推出 ChatGPT、Meta 發佈 Llama 系列開源模型以來,一直有聲音表示基座模型的創新已趨於終結,或僅有少數國際科技巨頭具備未來模型架構創新的能力。
最近兩次中國公司的開源動作,告訴我們並非如此。
2024 年,DeepSeek 憑藉其突破性的 MLA 架構,震撼了全球 AI 行業,證明了中國企業的技術創造力。
2025 年年初,MiniMax 再次以其全新的 Lightning Attention 架構刷新了行業認知,驗證了一條此前非共識的技術路徑。
中國 AI 公司不僅具備工程化和商業化的能力,更有能力推動底層技術創新。
新的一年,不論是 AI 應用的普及,還是技術金字塔尖的攻堅,我們可以對中國 AI 公司有更多的期待。
*頭圖來源:視覺中國
本文為極客公園原創文章,轉載請聯繫極客君微信 geekparkGO