“夜襲” OpenAI!DeepSeek 開源最強推理模型 R1,再震歐美同行_風聞
极客公园-极客公园官方账号-58分钟前

中國的 OpenAI,出現了。
作者 | 宛辰
編輯| 靖宇****
對標 OpenAI o1 正式版的國產大模型來了!
1 月 20 日晚,DeepSeek(深度求索)公司發佈推理模型 DeepSeek-R1 正式版,同步開源模型權重,並允許用户利用模型輸出、通過模型蒸餾等方式訓練其他模型。
網友熱評:這,才是真正的OpenAI。能力相當於一個月 200 美元的 ChatGPT o1 版本,卻完全免費。
不止如此,DeepSeek 一同開源的還有「技術報告」,那些訓練 R1 時踩過的坑、做過的事通通講給你聽,只為鋪平 AGI 的路。
第一時間閲讀這份技術報告後,英偉達高級研究科學家 Jim Fan 帶來了新鮮解讀,值得我們大聲齊讀:

「我們生活在這樣一個時代:由非美國公司保持 OpenAI 最初的使命——做真正開放的前沿研究、為所有人賦能。這似乎講不通,但戲劇性的往往最有可能發生。
DeepSeek-R1 不僅開源了大量模型,還泄露了所有訓練秘密。他們可能是第一個顯示 RL(強化學習)飛輪發揮主要作用、持續增長的 OSS 項目。
影響可以通過『內部實現了 ASI』或『草莓計劃』等神話名稱來實現。也可以通過簡單地轉儲原始算法和 matplotlib 學習曲線來產生影響。」
中國公司 DeepSeek,正在實現趕超 OpenAI 的使命**。**
01
DeepSeek-R1:
實力派選擇「秀肌肉」
「DeepSeek-R1」的發佈,擺明了是:有實力所以明晃晃地秀肌肉!
這首先體現在它不整期貨那一套,而是「發佈即上線」,現在,你就可以在 DeepSeek 官網與 App 體驗最新的推理模型 DeepSeek-R1,隨便體驗隨便用,免費。
登錄 DeepSeek 官網或官方 App,打開「深度思考」模式,即可調用最新版 DeepSeek-R1 完成各類推理任務。|圖片來源:DeepSeek
DeepSeek-R1 也同步上線了 API,對用户開放思維鏈輸出,通過設置 model=‘deepseek-reasoner’ 即可調用。
值得注意的是 DeepSeek-R1 API 服務定價為每百萬輸入 tokens 1 元(緩存命中)/ 4 元(緩存未命中),每百萬輸出 tokens 16 元。看下面這這圖你會有更直接的體感,輸出 API 價格只有 OpenAI o1 的 3%。低價背後,顯然仍是秀肌肉,價格實力展現了技術實力——從AIInfra 層面降本的技術能力。
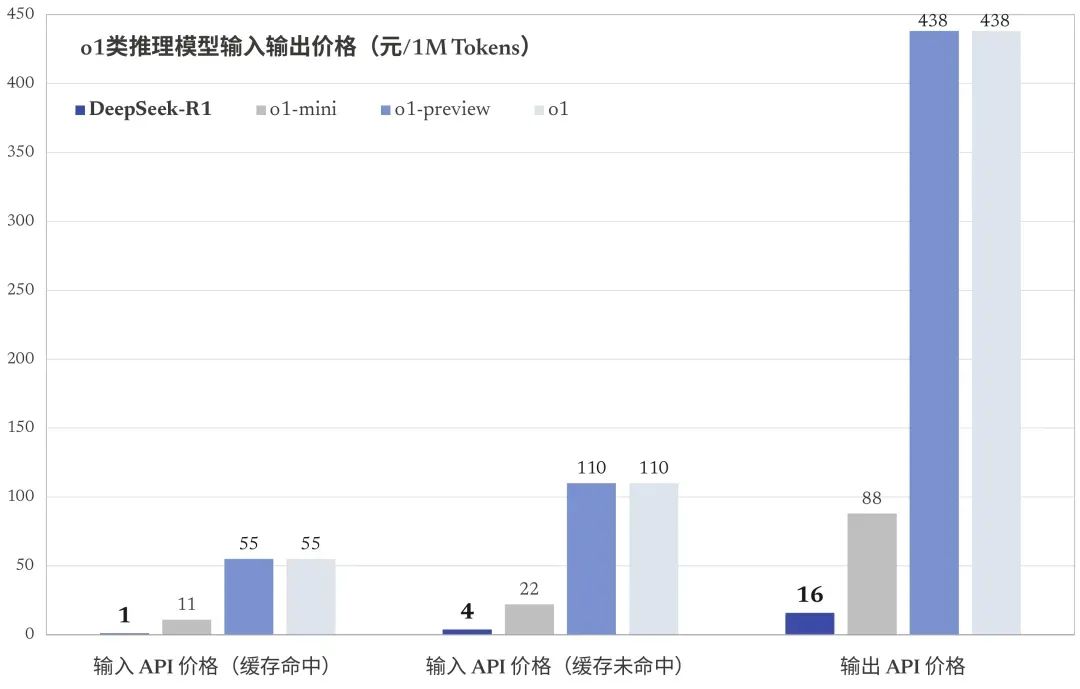
圖中深藍色柱子代表 DeepSeek-R1,剩下的灰色、淺藍、青淺灰分別是 OpenAI o1 不同版本的價格。|來源:DeepSeek
第三波「秀肌肉」體現在開源開放**。**DeepSeek-R1 開源模型權重幾乎是選擇了最開放的許可證和用户協議,開源 License 統一使用 MIT,產品協議明確可「模型蒸餾」,主打一個讓大家多多來基於它做二次開發、集成。DeepSeek 甚至主動給大家示範引導將 R1 作為教師模型來蒸餾出一個更小但仍有實力的模型,「通過 DeepSeek-R1 的輸出,蒸餾了 6 個小模型開源給社區,其中 32B 和 70B 模型在多項能力上實現了對標 OpenAI o1-mini 的效果」。
事實上**,模型開源選擇不同的 License 背後大有學問,這直接體現不同模型廠商的開放程度,更體現開源背後的目的和策略。**比如像 Llama、Qwen、GPT-2 等模型就不止開放權重,還開放了模型訓練的源代碼,這可能是為了追求衍生模型的繁榮。而 DeepSeek-R1 選擇只開放權重,但換成了標準化、寬鬆的 MIT License,更多還是為了讓更多開發者能用起來,感受 DeepSeek-R1 的能力。
我們再來通過幾大主流測試基準來感受一下 DeepSeek-R1 的實力。「性能對齊 OpenAI-o1 正式版 DeepSeek-R1 在後訓練階段大規模使用了強化學習技術,在僅有極少標註數據的情況下,極大提升了模型推理能力。在數學、代碼、自然語言推理等任務上,性能比肩 OpenAI o1 正式版。」
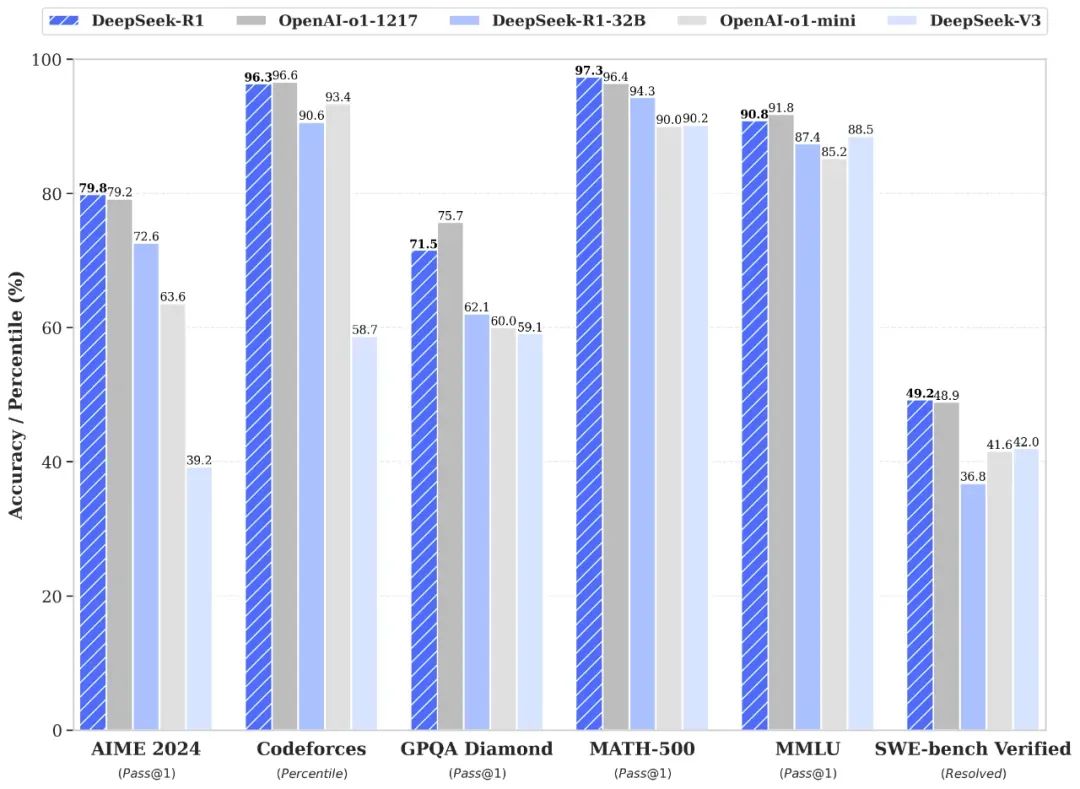
圖片來源:DeepSeek
對於 DeepSeek-R1 帶來的直觀感受,硅基流動聯合創始人楊攀表示,不止模型能力和性能出色,最近兩個模型 (R1 和 V3) 在訓練技術和模型底層架構上都做了領先全球的創新,而且其論文開放程度也震驚了業界。
在一併公開的模型技術報告中,DeepSeek 將「DeepSeek-R1」訓練技術全部公開,「旨在促進技術社區的充分交流與創新協作」。

根據技術報告,硅基流動創始人&CEO 袁進輝稱,DeepSeek-R1 是無人區的探索和發現。|來源:即刻
對於開源模型加技術報告,開源社聯合創始人林旅強此前向極客公園表示,開源是最好的「秀技術肌肉」的方式,同時「有的開源模型只開源、不講他是怎麼做的,但是合乎大家期待的開源模型是要搭配技術報告,等於是發 paper 了。開源模型不夠的,因為模型是黑盒子,技術報告會説明一些東西。DeepSeek 他們是很透明地把他的技術報告拿來公開,即使一定程度還是會捂着掖着,但是已經是開得比較有態度。今天全球範圍的學術派還是會認為,你把一個東西做出來再以開源的方式,是有學術追求的。」
如果 DeepSeek 的目標是真正達到 AGI,就不斷需要把踩過的坑、做過的事情開放出來,讓大家少走一點彎路,開放才能讓整個行業更快達到 AGI,他補充道。
最後,我們來隨機看一些用户實測評價(截圖來源:X.com):
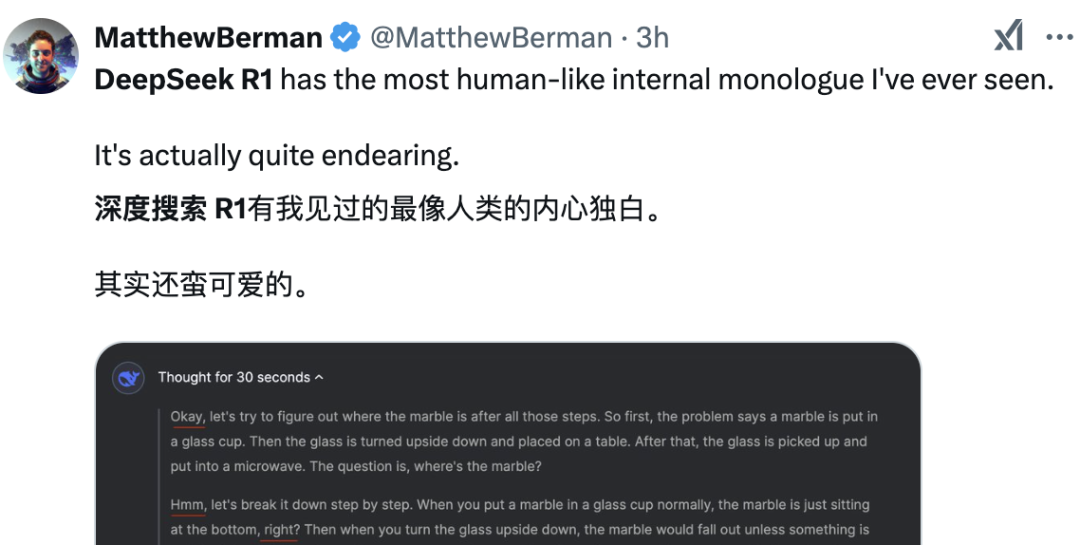

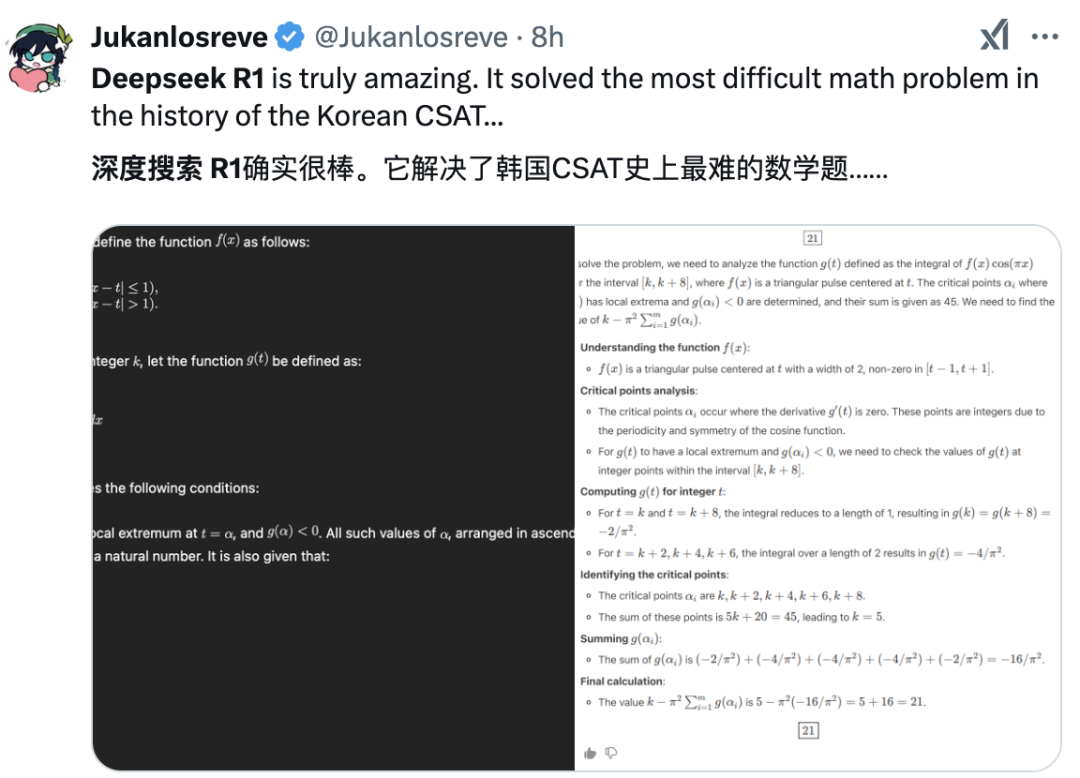
Twitter 用户盛讚 R1 的實力|圖片來源:X
02
DeepSeek,還有什麼
驚喜是我們不知道的?!
儘管昨晚 DeepSeek-R1 的發佈引發了「這才是 Open AI 吧」「東方的 OpenAI」等一片稱讚。但 DeepSeek 強得非常紮實、全面。
去年在 2024 年 11 月 20 日發佈 DeepSeek-R1-Lite 預覽版時,美國著名半導體與 AI 諮詢機構 Semianalysis 創始人 Dylan Patel 就坐不住了,第一時間下場「提醒」大家:他們有 5 萬張 H100GPU!請不要以為他們只有 1 萬張 A100!
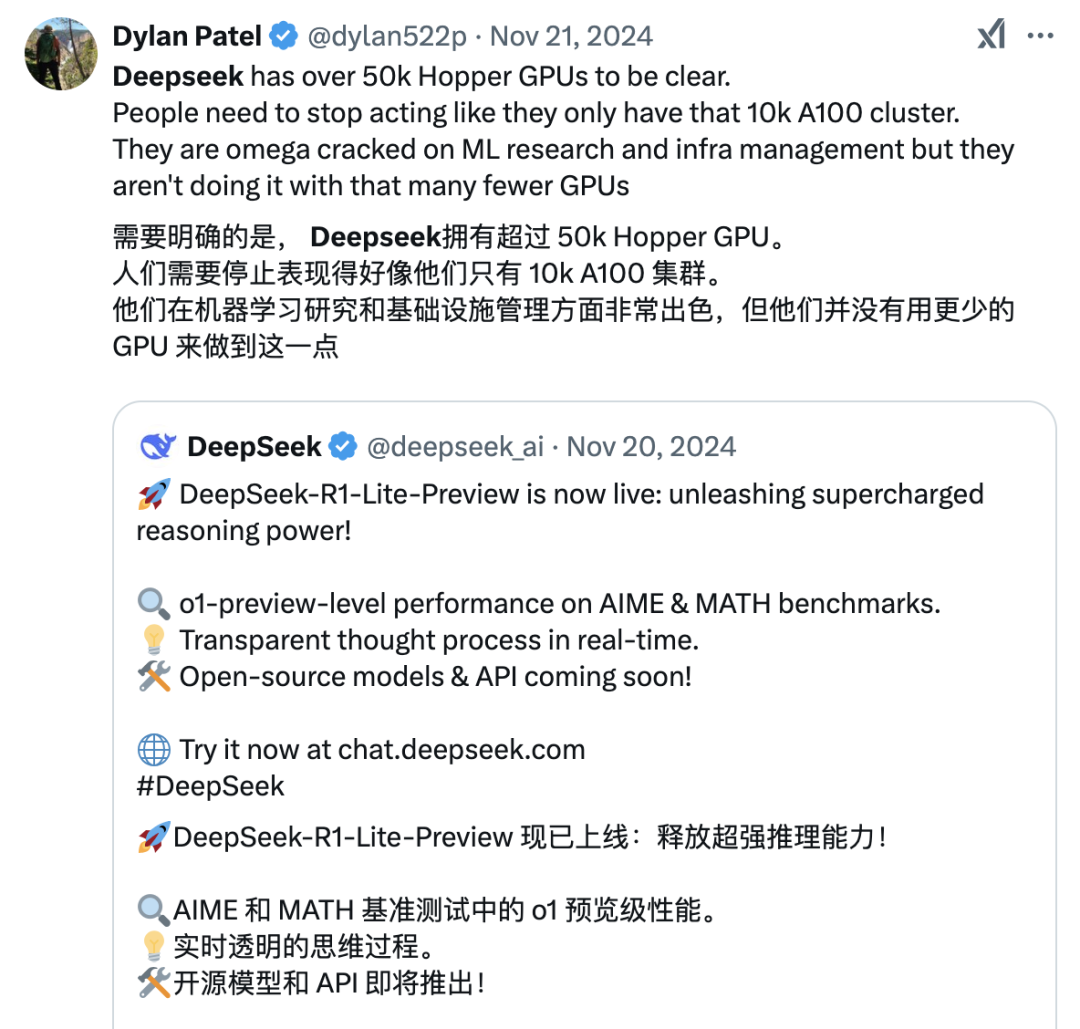
因為眾所周知的原因,這大概率不是事實,卻能反映 DeepSeek-R1-Lite 的強悍到讓行業緊張。
一個月後,DeepSeek 上線並同步開源了媲美 GPT-4o 和 Claude 3.5 Sonnet 的模型「DeepSeek-V3」,並附上了詳實的技術報告。這一次,**幾乎驚動了整個硅谷AI圈。**卡神(OpenAI 創始團隊、前 Tesla AI 總監 Andrej Karpathy)、Alexandr Wang(Scale.ai 創始人)、田淵棟(Meta AI 科學家)、賈揚清(Lepton AI 創始人)……人均一句「難以置信」。就連 Sam Altman 都忍不住出來酸一把「復刻已經被驗證過奏效的東西是容易的」。

DeepSeek-V3 發佈後,Sam Altman 疑似喊話 DeepSeek。|截圖來源:X.com
隨着模型性能逐漸走向全球第一梯隊,DeepSeek 也迎來了新的發展契機。
過去一年半,DeepSeek 專注於模型和研究,但從今年開始,DeepSeek 着手做應用了。
2025 年 1 月 15 日,DeepSeek 推出移動端 AI 助手「DeepSeek」App。目前看,DeepSeek App 跟網頁版功能一致,主要有兩個功能:聯網搜索和深度思考,主打一個簡潔,聊天記錄也會同步顯示在手機端和網頁端,尚未針對移動端進行特定功能的打磨,也沒有市面上 AI 助手類 App 豐富、fancy 的功能,更像是一個能讓你在手機上體驗 DeepSeek 最新模型的入口。

DeepSeek App 展示圖|來源:Apple Store
對此,一位投資人向極客公園解釋 DeepSeek 開始做應用背後可能的戰略轉向:「前期 DeepSeek 靠自己的算力優勢積累出了模型技術的領先度。後期要補數據,發 App 是補數據的手段之一。接入用户數據和場景,可以幫助他更好地進行模型能力的迭代和升級。」
同時,有了 DeepSeek-R1 和其他模態、類型越來越好的模型,可以期待未來 DeepSeek 在比如代碼模型/應用裏有更激進的表現,驚喜才剛剛開始。
*頭圖來源:視覺中國
本文為極客公園原創文章,轉載請聯繫極客君微信 geekparkGO