DeepSeek R1來了,追平o1!它現在不但比OpenAI開放,也比它有活力_風聞
心之龙城飞将-昨天 21:33
DeepSeek R1來了,追平o1!它現在不但比OpenAI開放,也比它有活力新浪財經APP舉報縮小字體放大字體收藏微博微信分享55來源:硅星人Pro
{kind=link}
 頭圖由豆包生成。提示詞:一條海底大鯨魚,賽博朋克,金屬發光。
頭圖由豆包生成。提示詞:一條海底大鯨魚,賽博朋克,金屬發光。
作者|王兆洋
在DeepSeek V3一個月前驚豔亮相後,它背後的“能量來源”DeepSeek R1系列正式發佈。
1月20日,DeepSeek在Huggingface上上傳了R1系列的技術報告和各種信息。
按照DeepSeek的介紹,它這次發佈了三組模型:1)DeepSeek-R1-Zero,它直接將RL應用於基座模型,沒有任何SFT數據,2)DeepSeek-R1,它從經過數千個長思想鏈(CoT)示例微調的檢查點開始應用RL,和3)從DeepSeek-R1中蒸餾推理能力到小型密集模型。
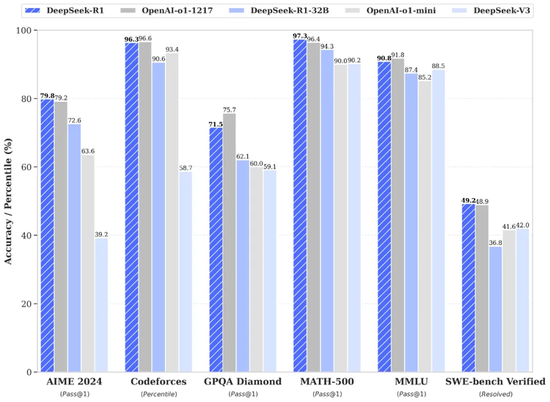
DeepSeek-R1在AIME2024上獲得了79.8%的成績,略高於OpenAI-o1-1217。在MATH-500上,它獲得了97.3%的驚人成績,表現與OpenAI-o1-1217相當,並明顯優於其他模型。在編碼相關的任務中,DeepSeek-R1在代碼競賽任務中表現出專家水平,在Codeforces上獲得了2029 Elo評級,在競賽中表現優於96.3%的人類參與者。對於工程相關的任務,DeepSeek-R1的表現略優於OpenAI-o1-1217。
 “RL is all you need”
“RL is all you need”
此次技術報告裏披露的技術路線,最讓人驚歎的是R1 Zero的訓練方法。
DeepSeek R1 放棄了過往對預訓練大模型來説必不可少甚至最關鍵的一個訓練技巧——SFT。SFT(微調)簡單説,就是先用大量人工標準的數據訓練然後再通過強化學習讓機器自己進一步優化,而RL(強化學習)簡單説就是讓機器自己按照某些思維鏈生成數據自己調整自己學習。SFT的使用是ChatGPT當初成功的關鍵,而今天R1 Zero完全用強化學習取代了SFT。
而且,效果看起來不錯。報告顯示,隨着強化學習訓練過程的進行,DeepSeek-R1-Zero 的性能穩步提升。比如,“在 AIME 2024 上,DeepSeek-R1-Zero 的平均 pass@1 得分從最初的 15.6% 躍升至令人印象深刻 71.0%,達到與 OpenAl-o1-0912 相當的性能水平。這一重大改進突顯了我們的 RL 算法在優化模型性能方面的有效性。”
但R1 zero本身也有問題,因為完全沒有人類監督數據的介入,它會在一些時候顯得混亂。為此DeepSeek用冷啓動和多階段RL的方式,改進了一個訓練流程,在R1 zero基礎上訓練出更“有人味兒”的R1。這其中的技巧包括:
冷啓動數據引入—— 針對 DeepSeek-R1-Zero 的可讀性和語言混雜問題,DeepSeek-R1 通過引入數千條高質量的冷啓動數據進行初始微調,顯著提升了模型的可讀性和多語言處理能力;
兩階段強化學習——模型通過兩輪強化學習不斷優化推理模式,同時對齊人類偏好,提升了多任務的通用性;
增強型監督微調——在強化學習接近收斂時,結合拒絕採樣(Rejection Sampling)和多領域的數據集,模型進一步強化了寫作、問答和角色扮演等非推理能力。
可以看出來,R1系列與GPT,甚至OpenAI的o系列看起來的做法相比,在對待“有監督數據”上都更加激進。不過這也合理,當模型的重點從“與人類的交互”變成“數理邏輯”,前者是有大量的現成的數據的,但後者很多都是停留在腦子裏的抽象思考,沒有現成數據可以用,而尋找那些奧數大師們一個個羅列和標註他們腦子裏的解題思路,顯然又貴又耗時。讓機器自己產生某種同樣存在它自己腦子裏的數據鏈條,是合理的做法。
論文裏另一個很有意思的地方,是R1 zero訓練過程裏,出現了湧現時刻,DeepSeek把它們稱為“aha moment”。
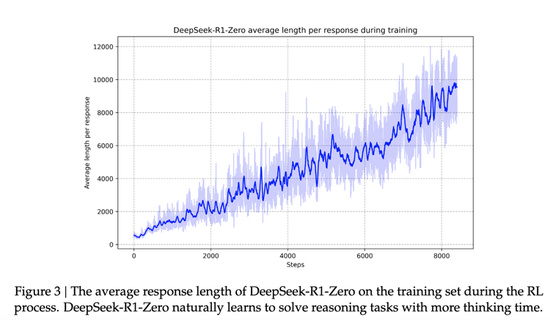 技術報告裏提到,DeepSeek-R1-Zero 在自我進化過程中展現了一個顯著特點:隨着測試階段計算能力的提升,複雜行為會自發湧現。例如,模型會進行“反思”,即重新審視並評估之前的步驟,還會探索解決問題的替代方法。這些行為並非通過明確編程實現,而是模型與強化學習環境交互的自然產物,大大增強了其推理能力,使其能夠更高效、更精準地解決複雜任務。
技術報告裏提到,DeepSeek-R1-Zero 在自我進化過程中展現了一個顯著特點:隨着測試階段計算能力的提升,複雜行為會自發湧現。例如,模型會進行“反思”,即重新審視並評估之前的步驟,還會探索解決問題的替代方法。這些行為並非通過明確編程實現,而是模型與強化學習環境交互的自然產物,大大增強了其推理能力,使其能夠更高效、更精準地解決複雜任務。
“它突顯了強化學習的力量和美麗:與其明確地教模型如何解決問題,我們只需為其提供正確的激勵,它就會自主地開發先進的問題解決策略。這一“頓悟時刻”有力地提醒了強化學習在解鎖人工智能新水平方面的潛力,為未來更自主、更適應的模型鋪平了道路。”
蒸餾,蒸餾,歡迎大家一起來蒸餾
在DeepSeek的官方推文裏,所有介紹的重點並不在R1模型技巧或R1模型榜單成績,而是在蒸餾。
“今天,我們正式發佈 DeepSeek-R1,並同步開源模型權重。DeepSeek-R1 遵循 MIT License,允許用户通過蒸餾技術藉助 R1 訓練其他模型。DeepSeek-R1 上線API,對用户開放思維鏈輸出,通過設置 `model=‘deepseek-reasoner’` 即可調用。DeepSeek 官網與 App 即日起同步更新上線。”
這是它官方發佈的頭幾句話。
DeepSeek在R1基礎上,用Qwen和Llama蒸餾了幾個不同大小的模型,適配目前市面上對模型尺寸的最主流的幾種需求。它沒有自己搞,而是用了兩個目前生態最強大,能力也最強大的開源模型架構。Qwen 和 Llama 的架構相對簡潔,並提供了高效的權重參數管理機制,適合在大模型(如 DeepSeek-R1)上執行高效的推理能力蒸餾。蒸餾過程不需要對模型架構進行復雜修改,減少了開發成本。而且,直接在 Qwen 和 Llama 上進行蒸餾訓練比從頭訓練一個同規模的模型要節省大量的計算資源,同時可以複用已有的高質量參數初始化。
這是DeepSeek打的一手好算盤。
而且,效果同樣不錯。
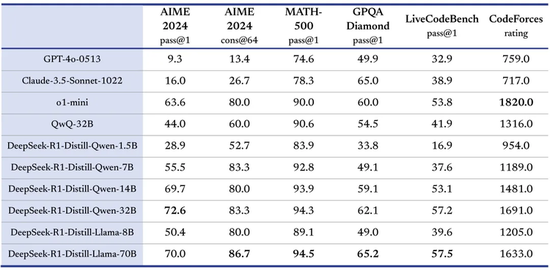 “我們在開源 DeepSeek-R1-Zero 和 DeepSeek-R1 兩個 660B 模型的同時,通過 DeepSeek-R1 的輸出,蒸餾了 6 個小模型開源給社區,其中 32B 和 70B 模型在多項能力上實現了對標 OpenAI o1-mini 的效果。”
“我們在開源 DeepSeek-R1-Zero 和 DeepSeek-R1 兩個 660B 模型的同時,通過 DeepSeek-R1 的輸出,蒸餾了 6 個小模型開源給社區,其中 32B 和 70B 模型在多項能力上實現了對標 OpenAI o1-mini 的效果。”
此外,在技術方向上,這也給業界帶來啓發:
對小模型來説,蒸餾優於直接強化學習:從 DeepSeek-R1 蒸餾得到的小模型在多個推理基準(如 AIME 2024 和 MATH-500)上的表現優於直接對小模型進行強化學習。大模型學到的推理模式在蒸餾中得到了有效傳遞。
DeepSeek比OpenAI更有活力
如果簡單來概括R1系列的發佈,DeepSeek用巨大的算力和各類資源,訓練了一個強大的底層模型——這個叫做R1 zero的模型,在訓練過程裏直接拋棄了GPT系列為代表的SFT等預訓練技巧,直接激進地幾乎全部依賴強化學習,造出了一個僅靠自己反思就擁有泛化能力的模型。
然後,因為全是“自我反思”學出來的能力,R1 zero有時候會顯得學的有點雜而混亂了,為了能夠讓人更好使用,DeepSeek用它自己的一系列技巧來讓它和真實的場景做了對齊,改造出一個R1。
然後在此基礎上,不是自己蒸餾小模型而是用幾個最流行的開源框架蒸餾出來了幾個最合適尺寸的模型。所有這些都開源給外界參考和使用。
整個過程裏,DeepSeek顯示出很強的自己自成一派的技術路線和風格。而這種路線正在和OpenAI正面交鋒。
OpenAI的o系列此前陸續傳出的訓練方法上,對於“對齊”基本延續着GPT系列形成的風格,此前一名OpenAI負責訓練安全和對齊部分的研究員曾對我們透露,他們內部,所謂安全和與人類對齊,其實和提高模型能力是同一件事。但後來隨着o3的預告,同時發生的就是這些人類安全對齊機制的研究員的集體離職。這也讓這家公司的創新變得遮遮掩掩,外部看來就是慢下來,且活力減少了。
這樣的對比,也讓DeepSeek在這個階段的異軍突起顯得更讓人期待。它比OpenAI更有活力。
從DeepSeek R系列來看,它的對齊放在了R1這個模型的訓練階段裏,而R1 zero更像是隻追求用最極致的強化學習方法自己練出強大的邏輯能力。人類反饋説喜不喜歡它,這些信息並沒有太被混在最初R1 zero裏面一起訓練。
這繼續在把“基礎模型”的能力和實際使用的模型分開,最初GPT3和InstructGPT其實就是這樣的思路,只不過當時是基礎能力和人類偏好分開兩階段完成,現在是更抽象的基礎邏輯能力和更強調實用性能和性價比的偏好。這也是為什麼V3之前被發現在文科類的能力上不強的原因。
所以,與“追上o1”相比,DeepSeek R1 zero證明出來的能力,和用它蒸餾出來的V3的驚豔,以及這次它又用Llama和Qwen蒸餾出來的幾個小參數模型表現出來的能力,才是這一系列動作的關鍵。
在與人類交互這件事上,ChatGPT因為有GPT4提供的基礎能力後,實現了突破,但OpenAI選擇立刻閉源,這樣就只有它自己能突破。在泛化出強大的數理推理能力這件事上,DeepSeek V3因為有DeepSeek R1的強大涌現才實現突破,而DeepSeek則把它開源,選擇讓大家都能一起突破。
DeepSeek對OpenAI的威脅是真實的,接下來的“比拼”會越來越有意思。