正面硬剛OpenAI現役最強模型,國產AI一夜捲到硅谷_風聞
乌鸦智能说-1小时前
這兩天,中國AI公司讓全球AI圈再次興奮了一把。
起因是,DeepSeek和 Kimi幾乎同時分別官宣了全新推理模型——R1和k1.5。
讓業內驚訝的是, DeepSeek-R1和 Kimi k1.5的性能都相當“能打”。
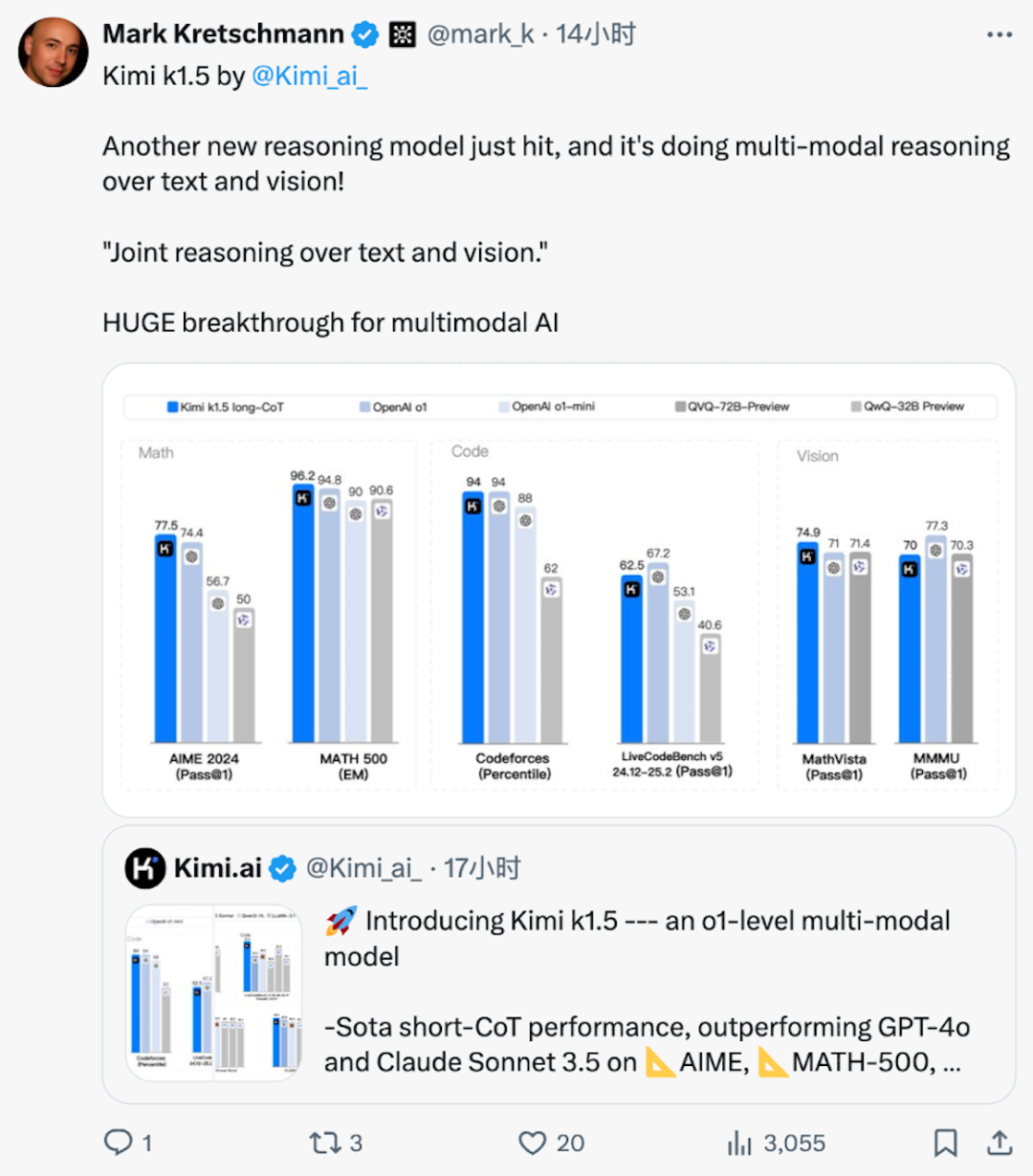
其中,文本推理模型DeepSeek-R1的性能追上o1正式版,關鍵模型還是開源的。而Kimi k1.5的文本和視覺多模態推理性能也已經全面追上現役全球最強模型——OpenAI o1正式版。
具體來説,在Long-CoT(思維鏈)模式下,Kimi k1.5的數學、代碼、視覺多模態、通用推理能力,達到了長思考SOTA模型OpenAI o1滿血版的水平。這也是全球範圍內,首次有OpenAI之外的公司達到。而在Short CoT模式下,Kimi k1.5大幅領先GPT-4o和Claude 3.5的水平。
值得一提的是,在發佈k1.5模型的同時,Kimi還首次公佈了詳細的模型研發技術報告。透過這份技術報告,我們也能夠從中找到一些k1.5模型的實踐經驗。
**/ 01 /**中國雙子星再次炸場硅谷,性能比肩OpenAI o1
雖然DeepSeek R1和Kimi k-1.5有不少相似之處,比如都是以強化學習(RL)為核心驅動力。但從具體技術路線上,兩者卻又有着很多不同。
在兩個模型發佈的第一時間,英偉達AI科學家Jim Fan詳細對比了兩個模型的相似處和差異點。他發現,,Kimi和Deepseek的研究成果相似的地方在於:
1、不需要像MCTS那樣複雜的樹搜索。只需將思維軌跡線性化,然後進行傳統的自迴歸預測即可;
2、不需要需要另一個昂貴的模型副本的價值函數;
3、無需密集獎勵建模。儘可能依賴事實和最終結果。
而兩者的差異點在於:
1、DeepSeek採用AlphaZero方法-純粹通過RL引導,無需人工輸入,即“冷啓動”。Kimi採用AlphaGo-Master方法:通過即時設計的CoT跟蹤進行輕度SFT預熱。
2、DeepSeek權重是MIT許可證;Kimi K1.5是閉源模型。
3、Kimi在MathVista等基準測試中表現出強大的多模式性能,這需要對幾何、智商測試等有視覺理解(DeepSeek目前只能識別文字,不支持圖片識別)。
4、Kimi的論文在系統設計上有更多細節:RL基礎設施、混合集羣、代碼沙箱、並行策略;以及學習細節:長上下文、CoT 壓縮、課程、採樣策略、測試用例生成等。
當然,除了這些技術細節外,迴歸市場層面,之所以DeepSeek與Kimi發佈推理模型能夠引發如此高的關注,一個核心原因是,相比過去發佈的類o1-preview模型,這兩家公司發佈的都是滿血版o1。
無論是數學,還是代碼基準測試分數,DeepSeek與Kimi的得分都接近甚至超過OpenAIo1模型。
與Deepseek不同的一點是,Kimi k1.5是OpenAI之外首個多模態o1。
Kimi k1.5在文本和視覺數據上進行訓練,使其能夠同時處理文本和視覺數據。這種多模態能力使得模型能夠聯合推理文本和圖像信息,從而在多模態任務中表現出色。
例如,在視覺問答(Visual Question Answering,VQA)和數學推理任務中,模型能夠通過理解和分析圖像內容來生成準確的答案。這種多模態設計不僅擴展了模型的應用範圍,還提升了其在複雜任務中的表現能力。
Kimi k1.5出色的多模態能力,也引發了業內的熱議。在X平台上,知名AI博主Mark Kretschmann大呼,“這是多模態AI的巨大突破。“
 第三,短模型能力全面領先,在短思考模式(short-CoT)模式下,數學能力無論是gpt-4o還是claude3.5-sonnet都遠不如Kimi 1.5,尤其是在AIME榜單上,Kimi 1.5有60.8,而最高模型裏最高的只有39.2,堪稱斷層式碾壓。
第三,短模型能力全面領先,在短思考模式(short-CoT)模式下,數學能力無論是gpt-4o還是claude3.5-sonnet都遠不如Kimi 1.5,尤其是在AIME榜單上,Kimi 1.5有60.8,而最高模型裏最高的只有39.2,堪稱斷層式碾壓。
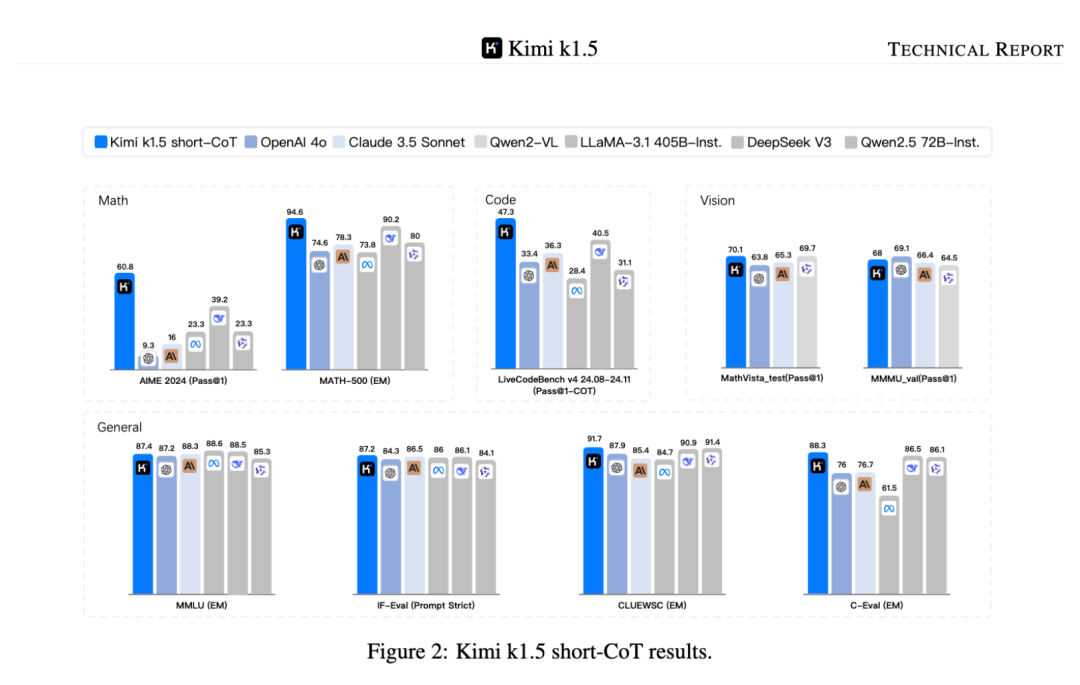 除了數學能力外,在代碼視覺多模態和通用能力等場景下,Kimi 1.5也超越了目前的開源模型。
除了數學能力外,在代碼視覺多模態和通用能力等場景下,Kimi 1.5也超越了目前的開源模型。
在強勁的模型性能背後,肯定有很多人關心,這個滿血版o1水平的模型究竟是如何實現的?對此,月之暗面也大方公開了Kimi 1.5模型的相關訓練技術細節。
/ 02 /****“long2short“訓練方案引人關注
在Kimi k1.5技術報告裏,最大的亮點莫過於“Long2Short”訓練方案,其方法是先讓長CoT模型學會長鏈式思維,再將“長模型”與“短模型”進行合併,然後對短模型進行額外的強化學習微調,進而顯著提升短推理路徑模型的性能。
具體來説,主要有以下四種方法:
模型合併:之前都是通過模型合併來提高模型的泛化性,k1.5發現long-cot模型和short-cot模型也可以合併,進而提高輸出效率,中和輸出內容,並且無需訓練。
最短拒絕採樣:對於模型輸出結果進行n次採樣(實驗中n=8),選擇最短的正確結果進行模型微調。
DPO:與最短拒絕採樣類似,利用long-cot模型生成多個輸出結果,將最短的正確輸出作為正樣本,而較長的響應(包括:錯誤的長輸出、比所選正樣本長1.5倍的正確長輸出)作為負樣本,通過構造的正負樣本進行DPO偏好學習。
Long2Short的強化學習:在標準的強化學習訓練階段之後,選擇一個在性能和輸出效率之間達到最佳平衡的模型作為基礎模型,並進行單獨的long-cot到short-cot的強化學習訓練階段。在這一階段,採用長度懲罰,進一步懲罰超出期望長度,但保證模型仍然可能正確。
Long2Short方案的優勢在於,最大化保留原先長模型的推理能力,避免了常見的“精簡模型後能力減弱”難題,同時有效挖掘短模型在特定場景下的高效推理或部署優勢。
這意味着,即使在有限的計算資源下,模型也能表現出良好的推理能力。
對於這種獨特的訓練方法,國外AI從業人士也給了很高的評價:
”long2short方法很有趣。首先,它顯示了將思維先驗從長期CoT模型轉移到短期CoT模型的潛力。這對於提高有限測試時token預算的性能非常有用。他們表明,與DPO和模型合併等其他方法相比,它可以獲得最高的推理效率。“
**/ 03 /**推理模型,或成大模型競爭分水嶺
過去三個月裏,能明顯感受到,Kimi在推理模型上進化速度之快。
2024年11月,他們首次推出的數學推理模型K0-math,就展現出了在數學領域的領先性。
12月,Kimi發佈了視覺思考模型k1,在k0-math的基礎上,k1 的推理能力不僅大大提升,還突破了數學題的範圍,更解鎖了強大的視覺理解能力。
現在,Kimi又往前進了一步,推出了推理能力更強大的k1.5。
從產業維度看,這事的意義不僅在於模型性能的升級,也直接影響產業競爭格局的變化。由於數據瓶頸和成本等原因,預訓練scaling law的魔法正在面臨着更多的考驗。
而o1被認為是提升模型智能的新路徑。正如OpenAI研究科學家Noam Brown所説,相比預訓練的鉅額投入,測試時間計算的成本相對較低,且算法改進空間巨大,具有巨大的提升潛力。
也就是説,大模型升級正在經歷從預訓練到後訓練+測試時計算的範式轉換。
從這個角度上説,“o1”類模型將是下一步國內一線實驗室角逐的分水嶺。誰能儘快做出自己的“o1”,誰才有資格繼續留在牌桌。毫無疑問,隨着DeepSeek R1和Kimi k-1.5模型的發佈,月之暗面和幻方已經拿到了一張門票。
考慮到o1大大提升模型解決複雜問題的能力,將推動模型進入越來越多垂直領域,從數學、編程開始,進入到法律、科研、金融、諮詢等領域。在這個過程中,國內大模型在商業化層面取得更多的突破也值得期待。
文/林白
