DeepSeek崛起讓美國芯片禁令變得毫無意義?_風聞
科技边角料-深挖泛科技、新商业、中概股那点事儿 @科技边角料52分钟前
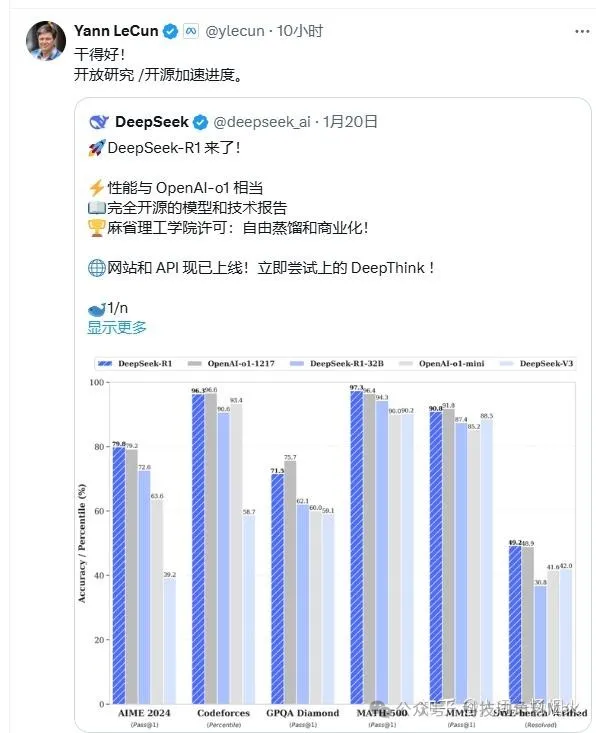
眼下中國大模型技術和產業鏈發展速度有目共睹,Deepseek和阿里巴巴在開源方面已經領先Meta,是世界範圍內開源最強者之一,而且目前國內發佈的推理模型效果基本和o1打平,雖仍弱於o3,但是技術路線走通了追上甚至趕超是必然的,只是時間問題。
DeepSeek的崛起,意味着中國有掌握下一個時代行業標準的機會,或許能也讓美國的芯片禁令,變得毫無意義。
然而有人問,DeepSeek真的會改變全世界AI的競爭格局?

首先,我們先達成個共識,就是AGI不會短期內實現,這個短期是起碼十年以上,那麼就不會有一個全知全能的AGI模型出現,各個行業還是需要一些根據業務需求定製的多種多樣的模型。
其次,訓練模型的只要成本在於預訓練階段,後訓練階段只占算力成本的10%不到。
傳統的 SFT階段,模型只能吸收來自標註樣本的知識,效果很一般,而且容易過擬合。
DeepSeek V3開創了一種新範式:不差錢的理想主義色彩的公司去訓練更大更好的模型,然後開源出來。
各個行業利用這個更大更好的模型去蒸餾各個領域的專用模型。
具體的業務再在蒸餾模型基礎上做微調
如果對模型沒有太多定製化要求的領域,直接調用API
此後整個行業形成了一條分工協作的產業鏈,上下游企業各司其職,各自發揮比較優勢。
DeepSeek這樣的企業有錢有技術,承擔超大模型預訓練
各個行業的龍頭企業有行業知識,有一定算力,做行業領域的蒸餾
各個具體業務組織,具備具體的業務知識和落地場景,做定製化的微調和工程落地
一旦這樣的格局形成,那麼中國的全產業鏈優勢就能發揮了。
算力卡脖子的問題也解決了,反正只有大模型預訓練階段最消耗算力,那麼哪怕走私也能。
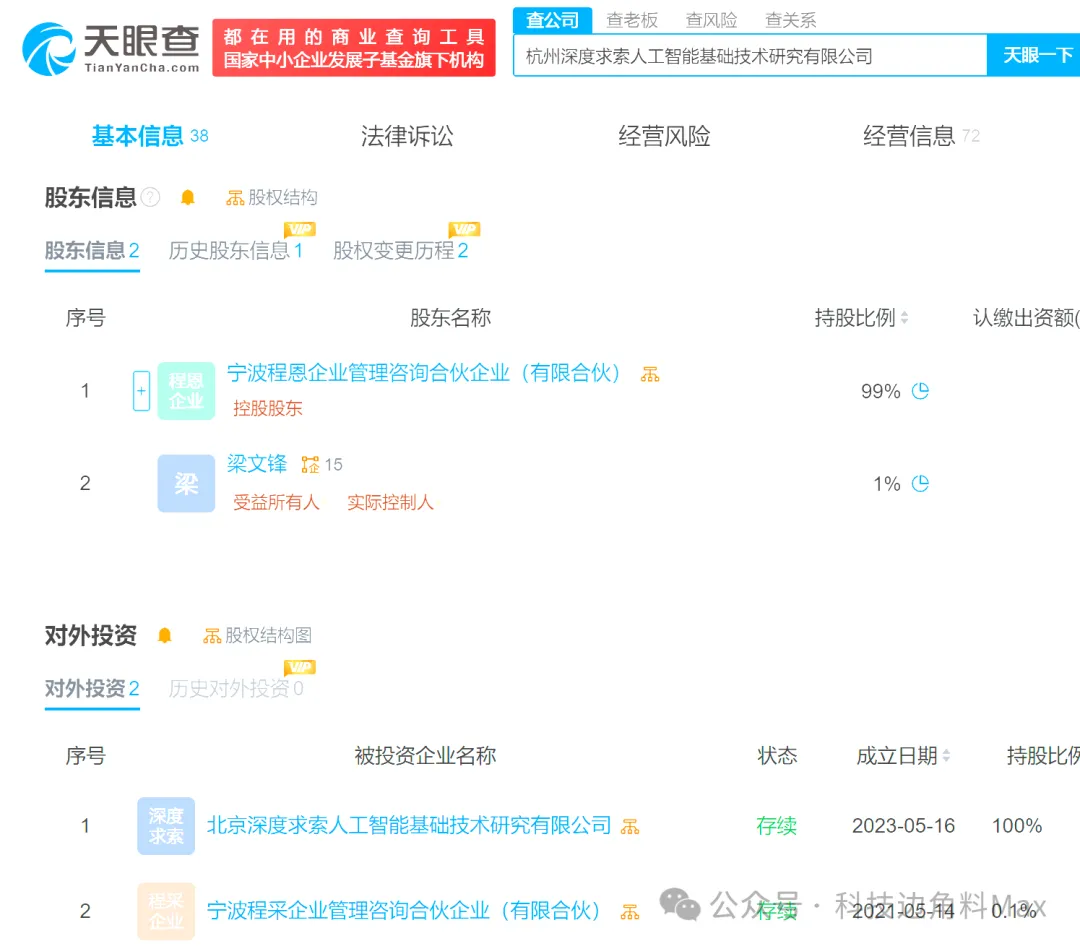
天眼查App顯示,DeepSeek關聯公司杭州深度求索人工智能基礎技術研究有限公司,註冊資本1000萬元,法定代表人裴湉,由寧波程恩企業管理諮詢合夥企業持股99%,梁文鋒持股1%。
究其原因,第一點在於 DeepSeek 開源。
開源在當前是一種正義的大旗,OpenAI 的模型再強,大家也是霧裏看山,OpenAI 從 GPT-3 開始就變成了徹頭徹尾的 ClosedAI,可以説除了引爆這一輪生成式大語言模型的浪潮外,給大家提供一個模糊的圖景外,對開源社區幾乎沒有幫助。
而 DeepSeek 則不然,DeepSeek 不僅完全開源,而且放出了詳細的技術報告;不僅開源了自己最大的 671B R1 模型,還「順帶手」幫大家蒸餾量化好了 1.5B~70B 多個尺寸的模型;不僅是面子上開源,甚至選擇了最寬鬆的 MIT License 協議,允許任何人免費使用、修改、分發,包括用於商業用途。國外很多人為 DeepSeek 舉大旗,願意用户 DeepSeek 為真正的 OpenAI。
LeCun 在蹭 DeepSeek 熱度的時候發了這麼一篇貼子:
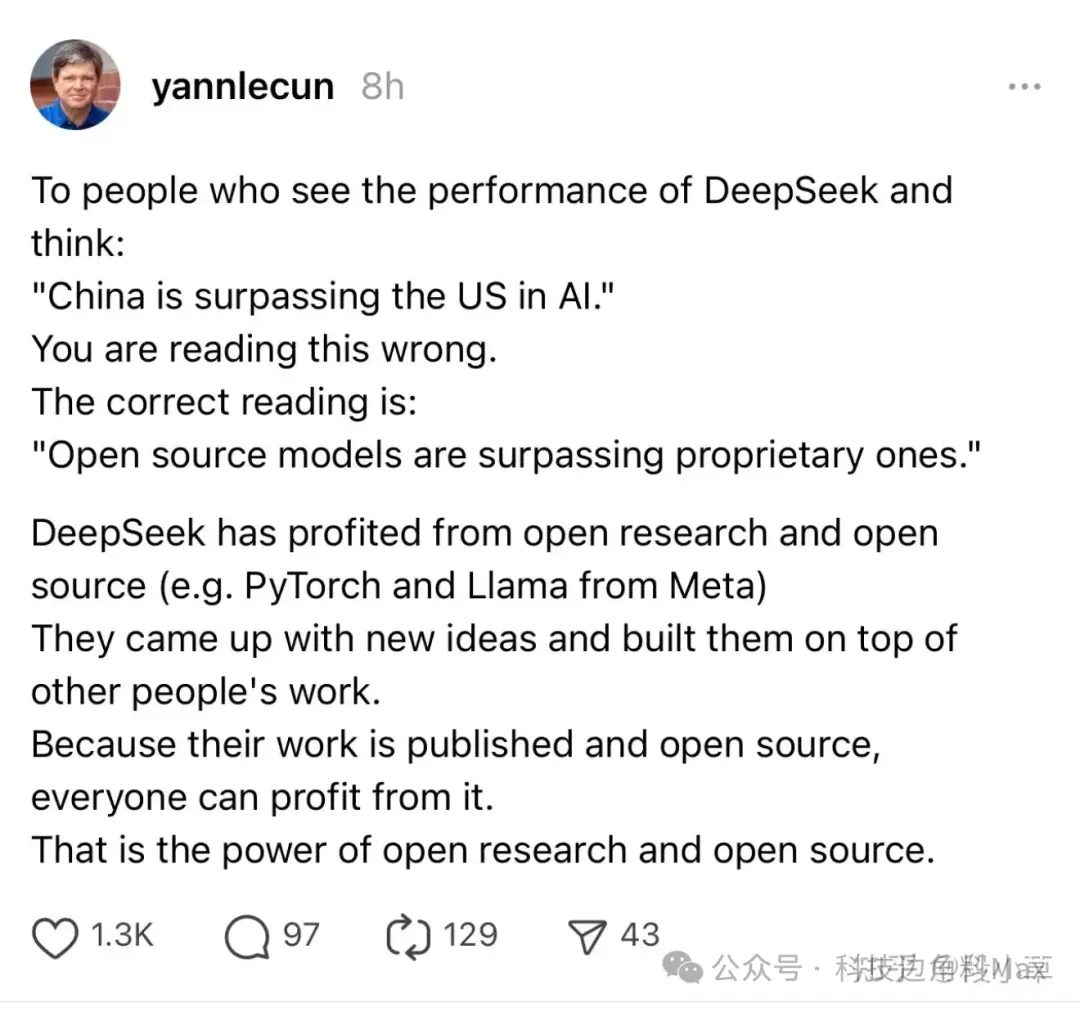
對於那些看到 DeepSeek 表現出色並認為「中國在人工智能上超越了美國」的人,你們理解錯了。正確的理解應該是:「開源模型正在超越私有模型。」。
DeepSeek 受益於開放研究和開源(例如 Meta 的 PyTorch 和 Llama)。他們提出了新想法,並在他人的基礎上進行構建。因為他們的工作是公開發布並開源的,每個人都能從中獲益。
這就是開放研究和開源的力量。
第二,DeepSeek 的訓練成本出乎意料的低。這一點來自於 DeepSeek V3 的技術報告中:DeepSeek V3 總訓練成本為 278.8 萬 H800 GPU 小時,僅 557.6 萬美元。
這是什麼概念呢?一個 Meta 的內部員工匿名爆料説,Meta 的生成式 AI 部門對 DeepSeek 感到恐慌,原因是他們隨便一個管理人員的薪資就超過了 DeepSeek V3 的總訓練成本,他們根本無法向高管解釋這件事。
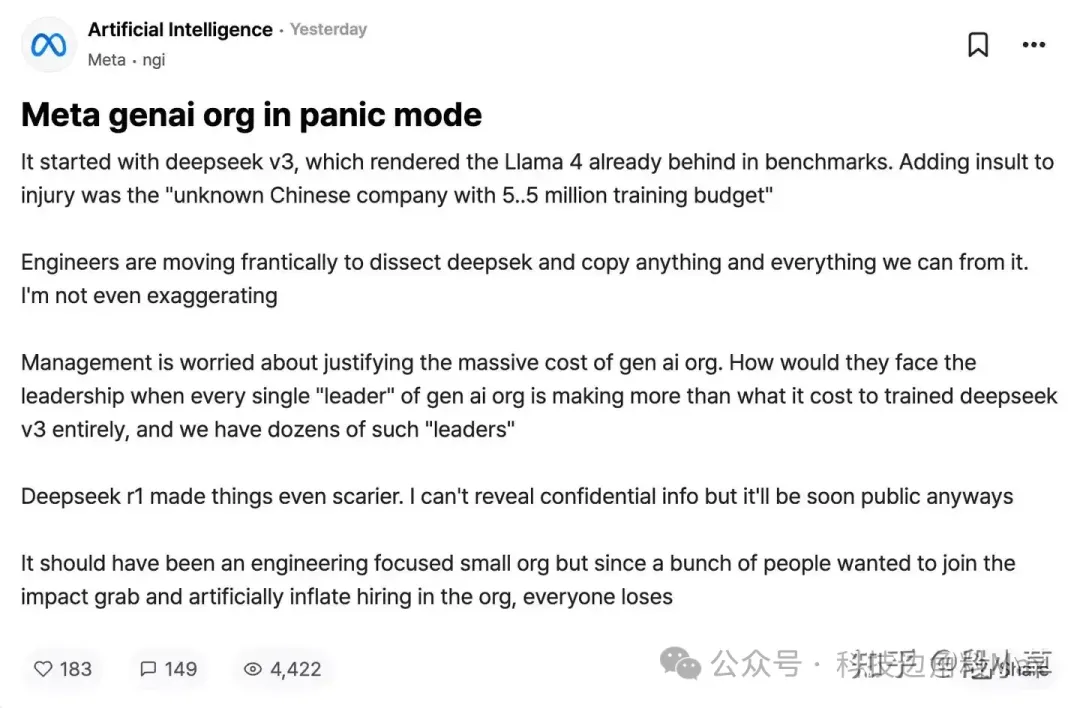
這也是一些人所説的,DeepSeek V3 很大程度上改變了大模型市場的根本邏輯,過去以為非常燒錢的現在發現未必需要。而這背後是來自於 DeepSeek 在架構和 AI Infra 上的創新工作。
第三是 DeepSeek 模型的性能確實強。模型評測具有相當的選擇性,好用不好用也視使用場景而定,不能有某幾個具體的問題去肯定或否定某個模型。DeepSeek V3 能贏 GPT-4o,R1 能贏 o1 也都是某些評測結果。
但我還是要説,考慮到 DeepSeek 免費提供使用,且 API 價格非常便宜,那麼綜合考慮用户使用成本,DeepSeek 的體驗就是 T1 級別的。
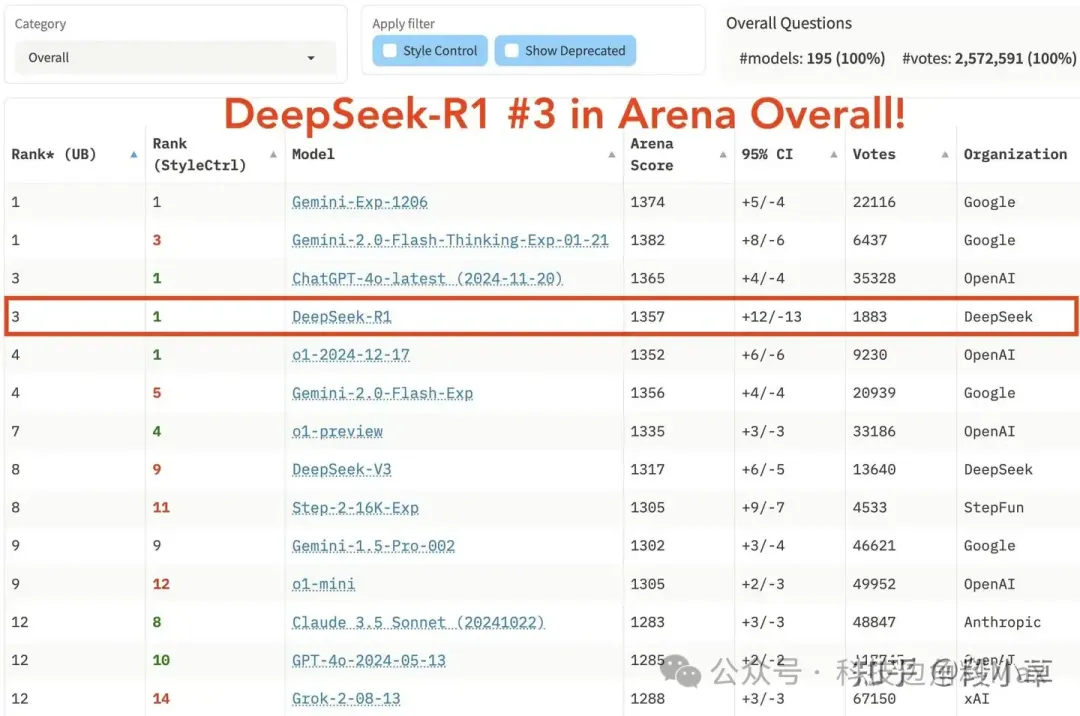
這一點有大模型競技場 Arena 佐證,不過由於 DeepSeek R1 的打分數據量尚少,所以其置信區間相對較大,也意味着成績可能還不太穩定。
第四,DeepSeek 來自幻方量化而不是傳統互聯網大廠,更具理想主義氣息。DeepSeek 創始人梁文鋒這幾天也是關注的焦點,大家説他上新聞聯播,翻出來他以前的發言逐字解讀,頗有種造神的意味。

但 DeepSeek 相比於其他模型,確實商業氣息更少一些,也更像一個小而美的研究機構,而非功利性的 AI 企業。這就天然地帶來了話題上的反差,更容易引起討論。美國現在已經明牌要挑起 AI競賽,特朗普在宣佈 5000 億美元投資的星際之門時説,這些投資如果不流向美國,就很可能會流向中國。這裏非此即彼的競爭意味非常明確,不少人把星際之門解讀為新星球大戰計劃。
不論是白宮對芯片的禁令,還是 OpenAI 等 AI 企業聯合起來的呼籲,都在明確一件事,就是遏制中國的 AI 發展,確保美國的領先地位。
在這個關鍵時刻,中國企業做出了 DeepSeek,這對於國內來説就是很振奮的事情,疊加上前面講到的 DeepSeek 訓練成本極低,在一定程度上也削弱了對高性能顯卡的依賴。
這對於美國來説是不可接受的。但是這件事的的確確真真正正地發生了,這有很有趣了,下一步走向會很微妙,也許 DeepSeek 會成為我們手中的關鍵一招。
當然也意味以後全世界的工程師都可能會從qwen和ds開始學習大模型。如果這個趨勢有幸保持,我們或許可以看到互聯網產業第一次由中國公司掌握基建標準的案例。