DeepSeek衝擊全球!各方評論及股市回應_風聞
大眼联盟-42分钟前
1月27日週一,DeepSeek衝擊全球算力,A股寒武紀大跌,日本半導體股下挫,美股納指期貨領跌。截至發稿,寒武紀持續走低跌近10%,成交額超39億元。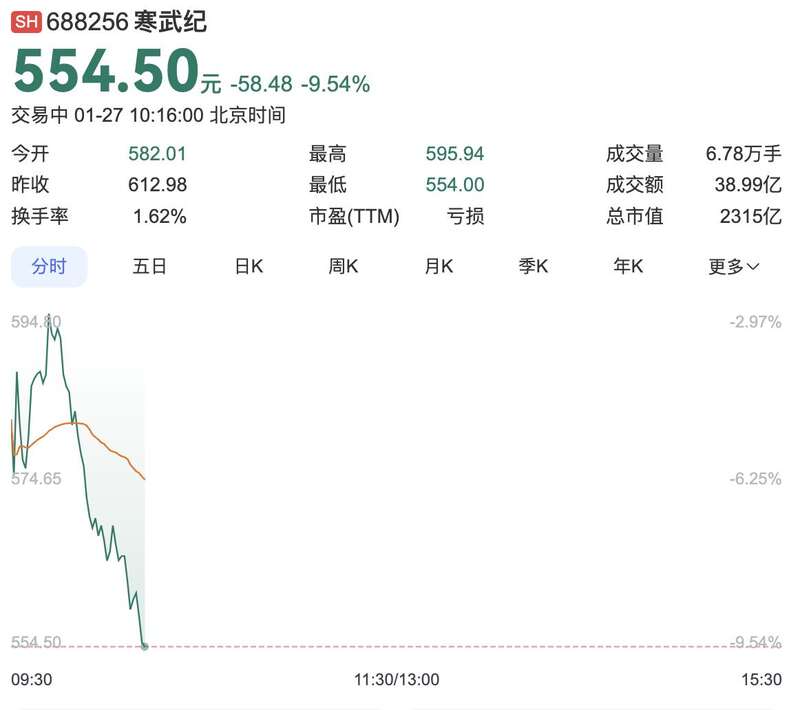
日經225指數盤中一度轉跌,現漲0.033%。軟銀集團股價一度下跌5.4%,創下11月1日以來的最大跌幅;東京電子和Disco均跌超3%;英偉達的測試設備供應商愛德萬測試跌8.2%。
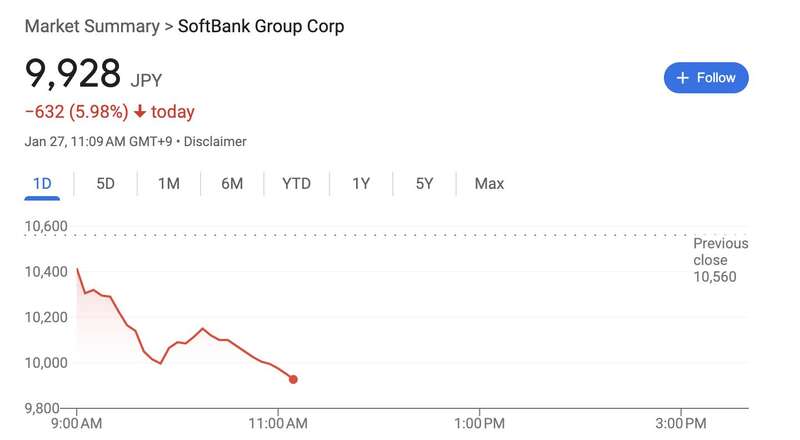
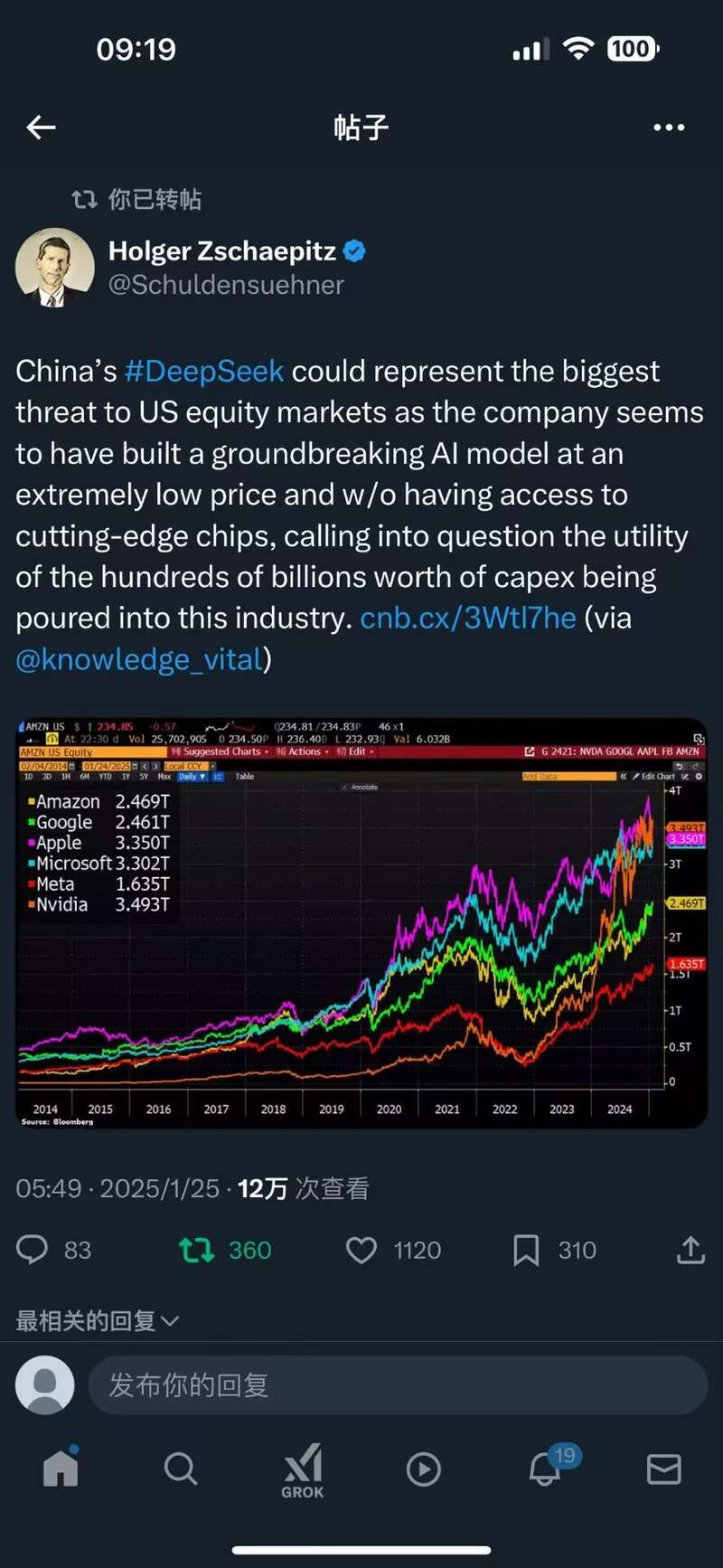
上週,日本半導體股和受益於特朗普“星際之門”項目所帶動的市場樂觀情緒,表現尤為突出。然而週末,DeepSeek爆火,算力邏輯受到衝擊,導致今日日本半導體股下挫。分析師Holger Zschaepitz表示:“中國的DeepSeek可能代表了對美國股市最大的威脅,因為該公司似乎以極低的價格建立了一個突破性的人工智能模型,而無需依賴最先進的芯片,這引發了對數百億美元資本支出是否有用的質疑,這些資金正被投入到這個行業中。 ”
MIT技術評論到《連線》,從VentureBeat到CNBC,各大媒體紛紛對這家中國AI初創公司投以高度關注。這家成立於2015年的公司,因其新發布的開源模型R1在性能和成本效率上的突破性表現,引發了整個AI行業的廣泛討論。

總結起來,外媒的關注主要有三點。首先是核心技術創新方面,DeepSeek採用了獨特的“思維鏈”推理架構。
據MIT技術評論報道,R1模型通過重新設計訓練流程,在保持高準確性的同時顯著降低了內存佔用和計算開銷。其次是對美國芯片管制失效的討論。
面對美國收緊的芯片出口管制,DeepSeek採取了雙管齊下的應對策略。
一方面,公司提前儲備了大量英偉達A100芯片;另一方面,通過創新性地結合高性能和低功耗芯片,開發出更高效的訓練方案。《連線》雜誌評價這種方式"重塑了AI模型的基礎架構"。
最後一點,從全球AI格局來看,DeepSeek的成功正在改變行業發展路徑。
VentureBeat指出,這打破了此前OpenAI、Anthropic和Google主導的專有閉源模型競爭格局。CNBC認為,這種低成本、高效能的創新模式,正在挑戰美國通過大規模資本投入推動AI發展的傳統路徑。讓我們來具體看看各大媒體是如何評價這一現象的。

MIT技術評論:美國出口限制未能如預期般削弱中國AI能力
DeepSeek的成功尤為令人矚目,因為中國人工智能公司面臨着日益嚴峻的美國芯片出口管制。
然而,早期證據顯示,這些制裁措施並未如預期般削弱中國的AI能力,反而迫使像DeepSeek這樣的初創公司在效率、資源共享和合作方面進行創新。
為了開發R1,DeepSeek必須重新設計其訓練過程,以減輕GPU的負擔。該公司使用的是英偉達為中國市場定製的GPU,其性能被限制在頂級產品的半速。
因此,DeepSeek不得不通過技術創新來克服這些硬件瓶頸。
微軟AI前沿研究實驗室的首席研究員迪米特里斯·帕帕利奧普洛斯表示,令他最為驚訝的是R1的工程簡潔性。“DeepSeek更注重準確答案,而不是詳細列出每一個邏輯步驟,這大大減少了計算時間,同時保持了高效性。”
訓練大語言模型需要一支高水平的研究團隊和大量的計算資源。
著名企業家、前谷歌中國總裁李開復曾在接受媒體採訪時表示,只有“前排玩家”才有能力投入到構建基礎模型的工作中,因為這一過程資源消耗極大。加之美國的芯片出口管制政策,局勢變得更加複雜。
然而,DeepSeek的成功恰恰源於這種困境。
早在美國製裁預期到來之前,該公司就提前囤積了大量的英偉達A100芯片,數量可能超過1萬顆甚至5萬顆。正是基於這一戰略性的資源積累,DeepSeek才能夠利用這些高性能芯片和低功耗芯片的組合,開發出其創新性的AI模型。
DeepSeek通過創新,找到了一種既能減少內存使用又能加快計算速度的方法,且不會顯著影響準確性。
卡內基國際和平基金會AI研究員馬特·希恩表示:“美國的出口管制實際上將中國公司逼入了一個角落,它們必須在有限的計算資源下更加高效。這將促使更多的AI企業通過更精細的資源分配和協作生存下來。”
《連線》:DeepSeek正向西方AI巨頭髮起挑戰
事實上,在許多關鍵指標上,如性能、成本和開放性等方面,DeepSeek正在向西方AI巨頭髮起挑戰。
DeepSeek的成功凸顯了美中科技冷戰中的一個意外結果。美國的出口管制嚴重限制了中國科技公司在西方方式上與AI競爭的能力——即通過不斷購買更多芯片並延長訓練時間來無限擴展。因此,大多數中國公司將重點放在下游應用上,而不是打造自己的模型。
但通過最新的發佈,DeepSeek證明了贏得競爭的另一種方式:通過重塑AI模型的基礎結構,使用有限的資源更加高效。
悉尼科技大學的副教授Marina Zhang解釋道:“與許多依賴高端硬件的中國AI公司不同,DeepSeek專注於最大化軟件驅動的資源優化。DeepSeek擁抱開源方法,匯聚集體智慧並促進協同創新。這種方式不僅緩解了資源限制,還加速了前沿技術的開發,使DeepSeek與更封閉的競爭者有所不同。”
DeepSeek願意與公眾分享這些創新,贏得了全球AI研究社區的廣泛好感。對於許多中國AI公司而言,開發開源模型是追趕西方同行的唯一途徑,因為開源能夠吸引更多的用户和貢獻者,進而幫助模型成長。
“他們現在已經證明,尖端模型可以用相對較少的資金甚至更低的資源來打造,而當前的模型構建規範仍然有很大的優化空間,”Marina Zhang表示。“未來,我們肯定會看到更多的類似嘗試。”
VentureBeat:DeepSeek打亂了AI模型市場格局
DeepSeek R1的問世,已經徹底打亂了AI模型市場的格局。
之前幾個月,OpenAI、Anthropic和Google之間一直在爭奪最強的專有模型,而Meta也常常推出“差不多”的開源競爭者。但這一次的不同之處在於,DeepSeek位於中國,這個與美國關係複雜的“競爭友好”國,其科技行業直到目前為止一直被視為遜色於硅谷。因此,DeepSeek的迅速崛起引發了美國和西方科技圈的廣泛擔憂,許多科技從業者開始懷疑OpenAI以及整個“大科技”戰略,即通過投入更多資金和算力(GPU)來推動更強大模型的誕生。
然而,一些西方科技領袖對DeepSeek的崛起表達了積極的看法。Netscape瀏覽器聯合創始人、著名風險投資公司Andreessen Horowitz(a16z)的普通合夥人馬克·安德森發帖稱:“DeepSeek R1是我見過的最令人驚歎和印象深刻的突破之一——作為開源,它是送給世界的巨大禮物!”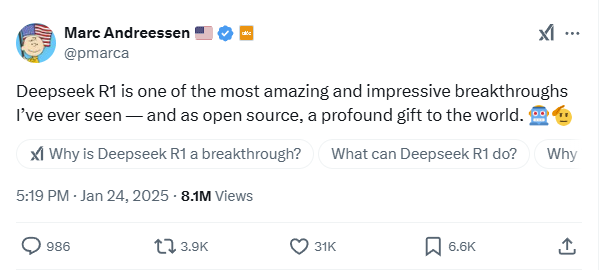
MetaAI研究部門FAIR首席科學家楊立昆也稱:“對於那些看到DeepSeek表現後認為:‘中國在AI上超過了美國’的人:你們的解讀錯了。正確的理解是:‘開源模型超過了專有模型。’DeepSeek受益於開放研究和開源(例如Meta的PyTorch和Llama)。他們提出了新的想法,並在其他人工作的基礎上構建。由於他們的工作是公開的,所有人都可以從中受益。這就是開放研究和開源的力量。”
即便是Meta的創始人和CEO馬克·扎克伯格似乎也想通過自己的帖子來回應DeepSeek的崛起。
他在Facebook上承諾,Meta今年發佈的新版本開源AI模型家族Llama將成為“領先的最先進模型”。
扎克伯格寫道:“2025年將是AI發展的關鍵年份。我預期Meta AI將成為領先的助手,為超過10億人服務,Llama 4將成為領先的最先進模型,我們將打造一個AI工程師,開始為我們的研發工作貢獻越來越多的代碼。為了支撐這一目標,Meta正在建設一個2GW+的數據中心,它的規模足以覆蓋曼哈頓的大部分區域。我們將在2025年上線約1GW的計算能力,年底時將擁有超過130萬顆GPU。我們計劃今年投資600-650億美元的資本支出,同時大幅擴展我們的AI團隊,並且我們擁有繼續投資的資本。這個努力規模巨大,未來幾年將推動我們的核心產品和業務,釋放歷史性的創新,並延續美國的技術領導地位。讓我們一起努力打造!”
CNBC:中國新興AI模型威脅美國主導地位
DeepSeek的崛起引發了硅谷的恐慌,因為它發佈的AI模型不僅能超越美國頂尖技術,且成本遠低於美國同行,使用的芯片也遠不如美國的高端產品強大。
這一進展讓人擔憂美國在人工智能領域的全球領先地位是否正在縮小,同時也質疑了大型科技公司在AI模型和數據中心建設上投入鉅額資金的策略。
微軟CEO薩提亞·納德拉在達沃斯世界經濟論壇上表示:“看到DeepSeek的新模型,令人印象深刻,尤其是在它們如何有效地構建開源模型,推理時的計算非常高效,計算資源使用得非常優化。我們應該非常認真地對待中國在這一領域的進展。”
Benchmark公司的普通合夥人Chetan Puttagunta則表示:“DeepSeek通過一種叫做‘蒸餾’的方法,利用一個大模型來幫助小模型在特定領域變得更智能。這實際上非常具備成本效益。”
Perplexity公司CEO阿拉文·斯里尼瓦斯也指出:“需求是發明之母。因為DeepSeek必須找到解決辦法,最終它們創造出了更高效的技術。”
華爾街見聞/AI未來指北