硅谷不眠夜:DeepSeek為何震動美國科技界?_風聞
大眼联盟-38分钟前
中國“神秘力量”震動美國科技圈?
瞭望 2025年01月27日 13:57 ◆ 近日,國產AI DeepSeek在中國、美國的科技圈受到廣泛關注,甚至被認為是大模型行業的最大“黑馬”,在外網,DeepSeek被不少人稱為“神秘的東方力量”
瞭望,贊25◆ 在不到30天的時間裏,DeepSeek先後發佈了DeepSeek-V3和DeepSeek-R1兩款大模型,性能與國外頂尖大模型相當,而其成本與動輒數億甚至上百億美元的國外大模型項目相比堪稱低廉,被稱為AI界的“拼多多”
◆ DeepSeek與外國大模型巨頭閉源的路徑不同,採用開源模式
來源丨環球時報-環球網記者 劉揚、環球時報-環球網特約記者 任重、中國新聞社綜合自DeepSeek官方微信 澎湃新聞 每日經濟新聞 界面新聞 財聯社 廣州日報 證券時報等
1月27日,DeepSeek應用登頂蘋果美國地區應用商店免費APP下載排行榜,在美區下載榜上超越了ChatGPT。同日,蘋果中國區應用商店免費榜顯示,DeepSeek成為中國區第一。
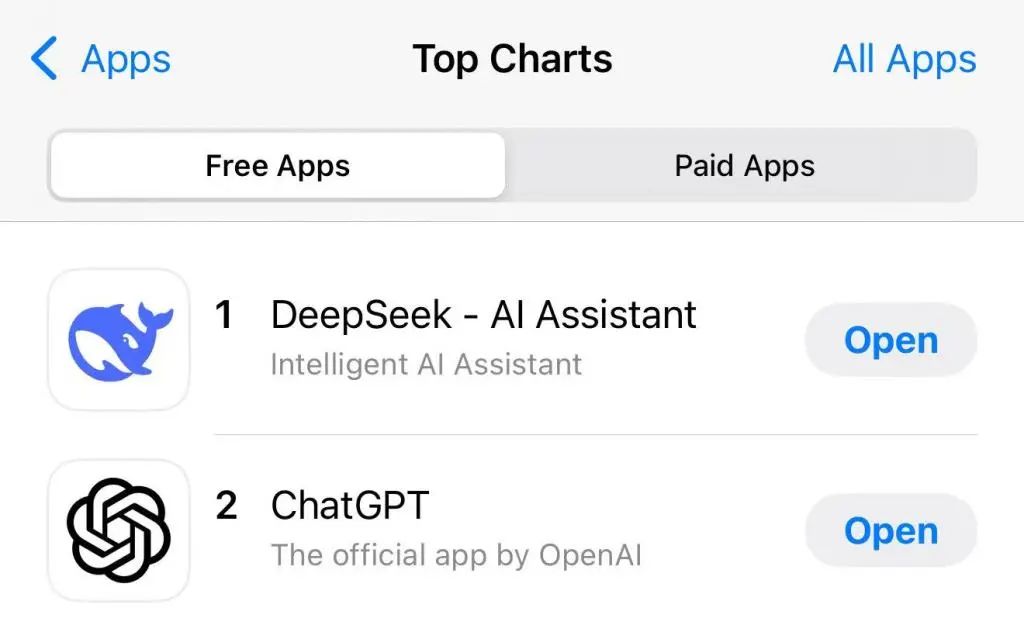
蘋果美國區應用商店
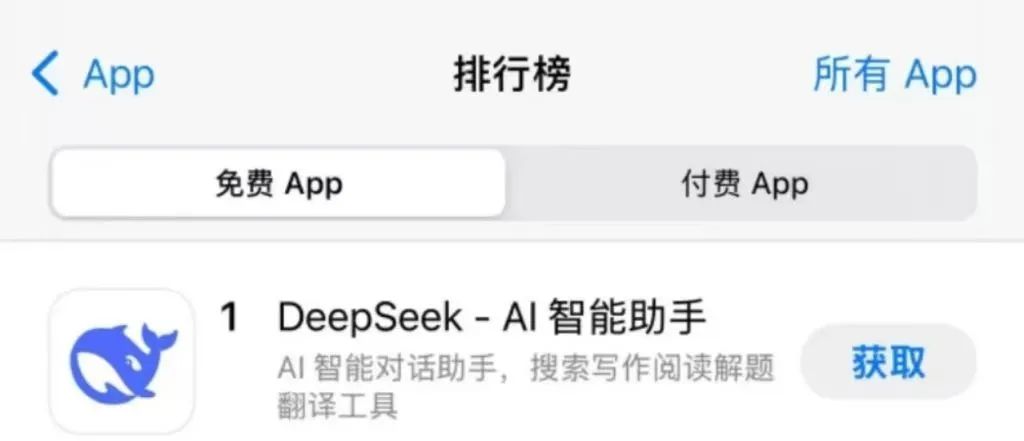
蘋果APP Store中國區免費榜
1月27日
相關微博熱搜刷屏



遊戲科學創始人、CEO,《黑神話:悟空》製作人馮驥高度評價DeepSeek:可能是個國運級別的科技成果。

DeepSeek是啥?
DeepSeek,全稱杭州深度求索人工智能基礎技術研究有限公司,成立於2023年7月17日,是一家創新型科技公司,專注於開發先進的大語言模型(LLM)和相關技術。
去年12月DeepSeek-V3發佈後,AI數據服務公司Scale AI創始人Alexander Wang就發帖稱,DeepSeek-V3是中國科技界帶給美國的苦澀教訓。“當美國休息時,中國(科技界)在工作,以更低的成本、更快的速度和更強的實力趕上。”
不到一個月之後,今年1月20日,DeepSeek正式開源R1推理模型。
據DeepSeek介紹,其最新發布的模型DeepSeek-R1在後訓練階段大規模使用了強化學習技術,在僅有極少標註數據的情況下,極大提升了模型推理能力。在數學、代碼、自然語言推理等任務上,性能比肩OpenAI o1正式版。
這一模型發佈後,引發了海外AI圈眾多科技大佬的討論。例如,英偉達高級研究科學家Jim Fan就在個人社交平台上公開發表推文表示:“我們正身處這樣一個歷史時刻:一家非美國公司正在延續OpenAI最初的使命——通過真正開放的前沿研究賦能全人類。看似不合常理,但最有趣的結局往往最可能成真。”

DeepSeek回答問題時,有時會先講一下自己的思考過程
DeepSeek為何突然爆火?
26日,DeepSeek出現了短時閃崩現象。不少網友反映,使用時遇到 “服務器繁忙” 的提示。
對此,DeepSeek回應稱,當天下午確實出現了局部服務波動,但問題在數分鐘內就得到了解決。**此次事件可能是由於新模型發佈後,用户訪問量激增,服務器一時無法滿足大量用户的併發需求。**不過,官方狀態頁並未將這一事件標記為事故。
據瞭解,此前DeepSeek在美區榜單的排名並無特別突出表現,處於穩步上升階段,但未進入前十。此次突然躥升,與其近期一系列突出表現有直接關係。
據廣州日報報道,**“DeepSeek爆火的原因主要可以歸結為兩點:性能和成本。”**薩摩耶雲科技集團首席經濟學家鄭磊告訴記者。DeepSeek解釋稱,R1在後訓練階段大規模使用了強化學習技術,在僅有極少標註數據的情況下,極大提升了模型推理能力。這種卓越的性能不僅吸引了科技界的廣泛關注,也讓投資界看到了其巨大的商業潛力。
更為關注的是,DeepSeek R1真正與眾不同之處在於它的成本——或者説成本很低。DeepSeek的R1的預訓練費用只有557.6萬美元,僅是OpenAI GPT-4o模型訓練成本的不到十分之一。同時,DeepSeek公佈了API的定價,每百萬輸入tokens 1元(緩存命中)/4元(緩存未命中),每百萬輸出tokens 16元。這個收費大約是OpenAI o1運行成本的三十分之一,也因此,DeepSeek被稱為AI界的“拼多多”。
鄭磊直言,DeepSeek對硬件市場產生了重大影響,因為它可能會降低人工智能模型的硬件成本,從而推動人工智能技術的發展。
團隊不到140人,都來自國內頂尖高校
DeepSeek之所以能取得這些創新並非一日之功,而是“孵化”數年之久,長期謀劃後的結果。DeepSeek創始人梁文鋒也是頭部量化私募幻方量化的創始人。Deepseek充分利用了其幻方量化積累的資金、數據和卡。
梁文鋒本科、研究生畢業於浙江大學,擁有信息與電子工程學系本科和碩士學位。2008年起,他開始帶領團隊使用機器學習等技術探索全自動量化交易。2023年7月,DeepSeek正式成立,進軍通用人工智能領域,至今從未對外融資。
此前,OpenAI前政策主管、Anthropic聯合創始人Jack Clark認為DeepSeek僱用了“一批高深莫測的奇才”,對此,梁文峯在接受自媒體採訪時曾透露過,並沒有什麼高深莫測的奇才,都是來自Top高校的畢業生、沒畢業的博四、博五實習生,還有一些畢業才幾年的年輕人。
從目前已有的媒體公開報道中可以看出,**DeepSeek團隊最大的特點是名校、年輕,**即使是團隊Leader級別,年紀也多在35歲以下。不到140人的團隊,工程師和研發人員幾乎都來自清華大學、北京大學、中山大學、北京郵電大學等國內頂尖高校,工作時間都不長。
延伸閲讀
專家解讀:中國新AI大模型為何火爆全網
近日,一個名為DeepSeek(深度求索)的中國AI初創公司成為國內外人工智能(AI)大模型領域熱議話題。在不到30天的時間裏,DeepSeek先後發佈了DeepSeek-V3和DeepSeek-R1兩款大模型,其成本與動輒數億甚至上百億美元的國外大模型項目相比堪稱低廉,而性能與國外頂尖大模型相當。同時,DeepSeek與外國大模型巨頭閉源的路徑不同,採用開源模式。中國這家公司的發展模式與成果讓硅谷高度關注,多家西方主流媒體紛紛發文感嘆“中國AI模型震驚硅谷”,甚至引發了國內外多家知名廠商與機構連夜嘗試復現DeepSeek成果的“熱潮”。DeepSeek的發展具有哪些特點?是否對國產大模型的發展路徑以及創新思路帶來一些啓示?《環球時報》記者26日採訪了多位人工智能領域的專家。
“OpenAI o1經濟實惠且開放的競爭對手”
DeepSeek公司本月20日發佈大模型R1,並表示“在數學、代碼、自然語言推理等任務上,性能比肩OpenAI o1正式版”,引發外媒特別是美國媒體高度關注這家中國公司及其最新大模型成果。
“中國便宜、開放的人工智能模型 DeepSeek讓科學家興奮不已。”《自然》雜誌24日以此為題稱,中國研製的大語言模型DeepSeek-R1令科學家們興奮不已,它被認為是OpenAI o1等“推理”模型的經濟實惠且開放的競爭對手。
《紐約時報》24日以“中國人工智能初創企業DeepSeek如何與硅谷巨頭競爭”為題報道稱,能做到上述成績本已是一個里程碑,但DeepSeek-V3大模型背後的團隊描述了一個更大的進步。他們在訓練該系統時只用了先進人工智能公司所用的高度專業化計算機芯片的一小部分。中國工程師稱,他們只花了約600萬美元以及約2000個英偉達專用芯片就完成了新模型的訓練,無論資金以及芯片使用規模都遠低於世界領先的人工智能公司。
“這不是中國追趕美國的問題,而是開源追趕閉源的問題”
DeepSeek備受關注,除了性價比超高,還有另一個原因:開源。連日來,網絡上已經出現了一波復現DeepSeek的熱潮。加州大學伯克利分校、香港科技大學、知名人工智能公司HuggingFace等紛紛成功復現,只用強化學習,沒有監督微調,甚至只用幾十美元的成本就能完成復現。
美國紅迪網25日稱,中國DeepSeek的模型是開源的,這是令人興奮的真正原因。基本上,他們將製造這些東西的知識免費提供給全世界,確保沒有人能夠真正壟斷它。中國公司基本上與美國公司的做法完全相反。你能看到OpenAI、Anthropic或谷歌開源任何強大的模型嗎?到目前為止,我們從他們那裏得到的只是皮毛。Meta是唯一一家對開源大模型做出重大貢獻的西方大公司,但他們將來可能不會開源其最好的模型。被譽為“深度學習三巨頭”之一的Yann LeCun(楊立昆)在社交平台X上表示,這不是中國追趕美國的問題,而是開源追趕閉源的問題。
北京郵電大學人機交互與認知工程實驗室主任劉偉在接受《環球時報》記者採訪時表示,大模型三大核心要素是數據、算法、算力,Deepseek使用較少的數據、較少的算力,通過算法的優化實現了與國外知名大模型等效甚至更優的效果,這是非常值得肯定的。同時還要看到它是開源的,可以供全球希望使用這一大模型的用户來使用和復現。
清華大學新聞學院、人工智能學院教授瀋陽26日對《環球時報》記者表示,DeepSeek的大模型是全球開源大模型當中相當優秀的一款,是混合使用多種先進技術實現超越傳統預訓練技術的創新突破。他結合自身使用的感受談了這款大模型的幾個優點。一是它把目前提升AI大模型能力的方法進行了工程上的微創新組合。二是DeepSeek公佈了相關論文,整個過程可以讓大家去復現,這就是開源的力量。三是DeepSeek的推理過程,有自身的創新。瀋陽作為AI領域的研究者,使用AI超過3萬次,他認為,DeepSeek跟美國的AI相比,還有很多中國元素在裏面,如中國網絡當中的一些熱詞。
提升推理能力
對於Deepseek的發展模式為國內大模型發展以及創新提供了怎樣的重要啓示,劉偉認為,“創新不是規劃出來的,需要市場、專業機構通過長時間的研究來另闢蹊徑,尤其是一些長期關注垂直領域的商業公司可以通過對技術路徑的反思、對市場發展的嗅覺,來找到更好的創新點。OpenAI最初的發展過程也是這樣,並不是美國官方與科技巨頭砸重金規劃出來的。”
日前,OpenAI、軟銀等公司公佈了“星際之門”計劃,要在4年中砸5000億美元來加速美國人工智能的發展。劉偉強調,這種集中人力、財力、物力,再給予政策傾斜的發展路徑,在未來研究方向與研究結果方面都存在一定的不確定性。“還是要鼓勵國內更多商業公司、科研院所聚焦自身的研究領域,找到適合自己的創新與發展路徑。”
瀋陽表示,在AI發展歷史中,新的突破往往是由不顯眼的工程創新與科學探索共同驅動的。這種趨勢在DeepSeek的成果中得到了深刻體現,它不僅突破了傳統的訓練方式,也為推理能力的提升帶來了全新的視角。“儘管它的成就尚處於一個階段性水平,但其工程貢獻和理論創新已經為未來的AI發展奠定了重要基礎。”瀋陽認為,DeepSeek團隊在基礎模型預訓練方面的貢獻,不僅是在技術層面上的突破,更在於其工程方法的精細與高效。DeepSeek的這種工程創新,標誌着AI模型訓練的一個全新階段,這不僅降低了開發成本,也為其他公司提供了可借鑑的路徑。同時,DeepSeek的核心創新還體現在推理能力的提升上,尤其是通過相關算法創新來推動模型的自然推理能力,證明了AI領域的一種潛力——無須大量昂貴的思維鏈標註,模型依然能夠湧現出推理能力。
瀋陽認為,DeepSeek的成功也讓我們看到了未來AI產業的發展方向:更多的開源創新、硬件與軟件的深度協同,以及對模型開發成本與推理能力的不斷優化。同時,我們也必須看到,**DeepSeek雖然取得了顯著的階段性成果,要想在未來發展道路上實現進一步突破,仍然需要面對許多深層次的挑戰,**例如需要更多的原創性訓練數據和算法創新。
硅谷不眠夜:DeepSeek為何震動美國科技界?
DeepSeek 給硅谷帶來的震撼還在持續,並不見降温的跡象。如果和幾個月前的《黑神話·悟空》在歐美受到的追捧相比,DeepSeek 的出現可謂是“石破天驚”,充滿了各種不可能、不合理。它講述了一個如何在層層封鎖、勁敵環伺的背景下鐵樹生花的故事,讓美國精心設置的人工智能技術小院高牆展現出了坍塌的風險。
“我們正生活在一個特殊的時代:一家非美國公司在真正踐行着 OpenAI 最初的使命——開展真正開放的前沿研究,為所有人賦能。這看似不合常理,但最富戲劇性的往往最可能發生。”這是英偉達高級研究科學家 Jim Fan 在社交媒體上發出的感慨。
就在最近,這家一年多前還名不見經傳的中國 AI 公司,以其新發布的推理大模型 R1 在全球 AI 界掀起了一場風暴。這個模型不僅在性能上比肩甚至超越了 OpenAI 的 o1,並完全開源,且以極低的成本實現了這一突破。這一事件迅速觸動了美國科技界的神經。
圖丨Google 新聞首頁推薦內容(來源:Google)
微軟 CEO Satya Nadella 在達沃斯世界經濟論壇上直言:“DeepSeek 新模型的表現令人印象深刻,尤其是在模型推理效率方面。我們必須認真對待來自中國的這些發展。”Scale AI 的 CEO Alexandr Wang 甚至將其稱為一款“震撼世界的模型(earth-shattering model)”。“我們發現 DeepSeek…… 的性能與美國最好的模型不相上下。”

圖丨 Alexandr Wang 相關採訪(來源:CNBC)
事實上,DeepSeek-R1 的出現確實引發了硅谷的一場小型地震。沃頓商學院教授 Ethan Mollick 對 R1 的內部思考過程讚歎不已:“DeepSeek 的原始思維鏈非常迷人。它真的讀起來就像一個人在大聲思考。既迷人又奇特”。著名風險投資人、Mosaic 瀏覽器聯合發明人馬克·安德森也表示:“DeepSeek R1 是我見過的最令人驚歎和印象深刻的突破之一,作為開源項目,這是給世界的一份重要禮物。”這種開源精神甚至讓一位軟件工程師將“OGOpenAI.com”域名重定向到了 DeepSeek,以此暗示 DeepSeek 更像早期的 OpenAI,踐行着開源 AI 的理念。
圖丨相關推文(來源:X)
最直接的衝擊體現在同樣倡導開源的 Meta 上。據美國匿名職場社區 teamblind 爆料,DeepSeek 的一系列動作已經讓 Meta 的生成式 AI 團隊陷入恐慌。一位 Meta 員工在帖子中寫道:“工程師們正在瘋狂地分析 DeepSeek,試圖從中複製任何可能的東西。這一點都不誇張。”更令他們擔憂的是,“當生成式 AI 組織中的每個‘領導’的薪資都比訓練整個 DeepSeek-V3 的成本還要高,而我們有好幾十個這樣的‘領導’時,他們要如何面對高層?”
儘管 Meta 的首席 AI 科學家 Yann LeCun 強調,這不應被解讀為“中國在 AI 領域超越美國”,而是“開源模型正在超越專有模型”。然而,扎克伯格隨後的舉措還是暴露了 Meta 的焦慮:宣佈加速研發 Llama 4,計劃投資 650 億美元擴建數據中心,並部署 130 萬枚 GPU 以“確保 2025 年 Meta AI 成為全球領先模型”。
圖丨扎克伯格在相關貼文中附上的 2 吉瓦數據中心位置圖(來源:Facebook)
艾倫人工智能研究所的研究科學家 Nathan Lambert 稱,“在這一點上,Meta 絕非個例”他認為,**R1 的發佈標誌着推理模型研究的一個重要轉折點。**在此之前,推理模型一直是工業研究的重要領域,但缺乏一篇開創性的論文。**就像 GPT-2 對預訓練的重要性,或者 InstructGPT 對後訓練的影響一樣,我們一直在等待一個推理模型研究的里程碑。**Lambert 指出:“推理研究和進展現在已經鎖定——預計 2025 年將有巨大的進展,而且更多將是公開的。”
那麼,是什麼讓 DeepSeek-R1 如此特別?R1-zero 採用的訓練策略證明了僅通過強化學習(RL,Reinforcement Learning),無需監督式微調(SFT,Supervised Fine-Tun-ing),大模型也可以有強大的推理能力。Hyperbolic 聯合創始人兼 CTO Yuchen Jin 將這一突破與 AlphaGo 進行類比:“就像 AlphaGo 使用純 RL 下了無數盤圍棋並優化其策略以獲勝一樣,DeepSeek 正在使用相同的方法來提升其能力。2025 年可能會成為 RL 的元年。”
不過,R1-Zero 在可用性方面存在的一些小問題表明,要訓練出一個出色的推理模型,需要的不僅僅是大規模的 RL。
在 R1-Zero 的基礎上,團隊針對 R1 採用了一個四階段的訓練方案:首先是對合成推理數據進行“冷啓動”監督微調;其次是對推理問題進行大規模強化學習訓練,直到收斂;第三是對 3/4 的推理問題和 1/4 的一般查詢進行拒絕採樣,開始向通用模型過渡;最後是混合推理問題和一般偏好調整的強化學習訓練。這個過程不僅實現了高效的訓練,還保持了模型的可讀性和最終性能。
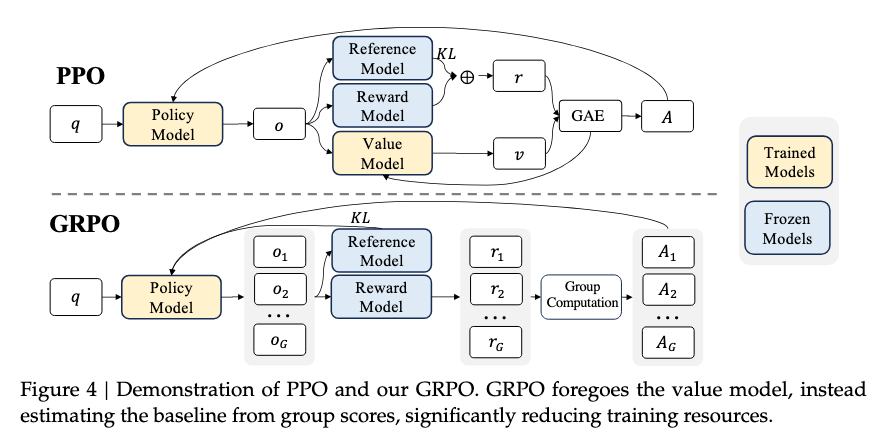
圖丨 DeepSeek 採用的 GRPO(Group Relative Policy Optimization)算法框架(來源:arXiv)
更關鍵的是,DeepSeek 通過創新性的方法,在有限的計算資源下實現了這些突破。正如微軟 AI 前沿研究實驗室首席研究員 Dimitris Papailiopoulos 所説,R1 最令人驚訝的是其工程簡單性:“DeepSeek 追求準確的答案,而不是詳細説明每個邏輯步驟,這顯著減少了計算時間,同時保持了高效率。”
儘管 R1 備受關注,DeepSeek 仍然相對神秘。創立於 2023 年 7 月的 DeepSeek 一直是一家低調的公司。公司創始人梁文鋒畢業於浙江大學信息與電子工程專業,此前創立了管理約 80 億美元資產的對沖基金幻方量化(High-Flyer)。與 OpenAI 的 Sam Altman 類似,梁文鋒的目標也是構建通用人工智能(AGI)。
DeepSeek 的成功與其獨特的發展策略密不可分。在美國實施芯片出口管制之前,梁文鋒就收購了大量英偉達 A100 芯片。據有關媒體報道,公司庫存超過 1 萬塊,而 AI 研究諮詢公司 SemiAnalysis 創始人 Dylan Patel 預估這個數量至少是 5 萬塊。這種前瞻性的佈局為該公司的技術突破奠定了基礎。
更重要的是,面對芯片限制,DeepSeek 將挑戰轉化為創新機遇。美國西北大學計算機科學博士生、前 DeepSeek 員工 Zihan Wang 告訴《麻省理工科技評論》:“整個團隊熱衷於將硬件挑戰轉化為創新機會。”他補充説,在 DeepSeek 工作期間,他能夠獲得充足的計算資源並有自由進行實驗,“這是大多數應屆畢業生在任何公司都不會得到的待遇。”
這種創新精神體現在效率的提升上。在 2024 年 7 月接受採訪時,梁文鋒承認中國公司在 AI 工程技術方面相對落後:“我們必須消耗兩倍的計算力才能達到相同的結果。再加上數據效率差距,這可能意味着需要四倍的計算力。我們的目標是不斷縮小這些差距。”梁文鋒本人也深度參與研究過程,與團隊一起進行實驗。
而 DeepSeek 最終找到了減少內存使用和加快計算速度的方法,同時沒有明顯犧牲準確性。
實際上,中國公司在這方面已經形成了某種共識,他們不僅追求效率,而且也在越來越多地擁抱開源原則。阿里雲已發佈了超過 100 個新的開源 AI 模型,支持 29 種語言,涵蓋編程和數學等各種應用。據中國信息通信研究院的白皮書顯示,全球 AI 大語言模型數量已達 1,328 個,其中 36% 來自中國,使中國成為僅次於美國的第二大 AI 技術貢獻國。
“這一代中國年輕研究者特別認同開源文化,因為他們從中獲益良多,”塔夫茨大學技術政策助理教授 Thomas Qitong Cao 説。
卡內基國際和平基金會的 AI 研究員 Matt Sheehan 則指出:“美國的出口管制反而逼得中國公司不得不想辦法提高效率,把有限的算力用到極致。考慮到算力短缺,我們可能會看到更多企業開始抱團取暖。”
“在 AI 行業出現一定的分工是很自然的事情,也更節省資源,”Cao 補充説,“AI 發展得太快了,中國企業必須保持靈活才能適應。”
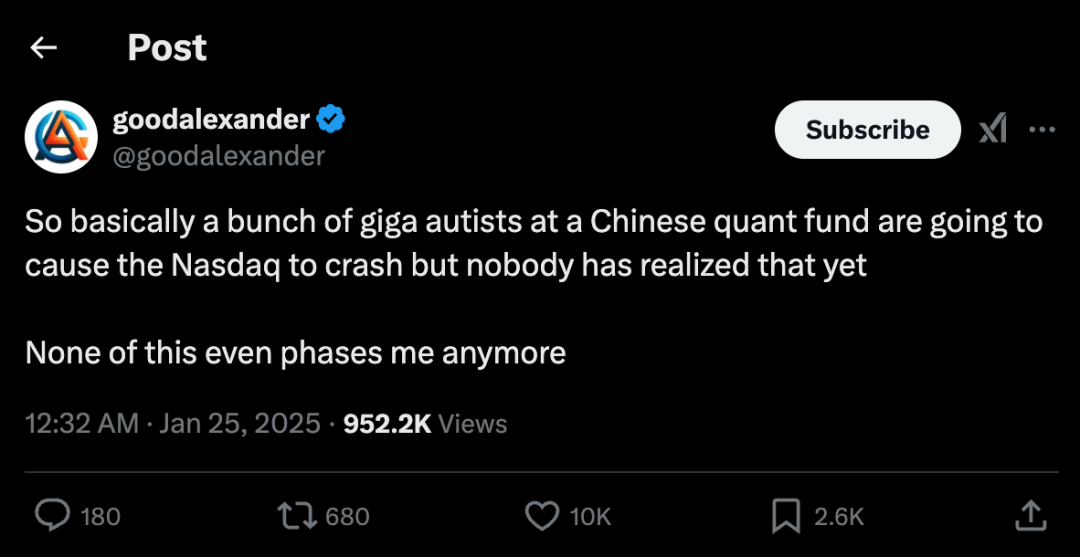
圖丨相關推文(來源:X)
隨着 DeepSeek 等中國公司在 AI 領域的崛起,全球 AI 競爭格局正在發生微妙變化。**如果中國公司能夠以更低的成本實現同等或更好的性能,而且這些模型還大都開源,美國公司賴以維持的技術優勢和高估值可能會受到挑戰。**這種擔憂已經反映在英偉達等 AI 概念公司的股價上,有分析師甚至指出:“事實上,中國量化基金的一羣超級天才將導致納斯達克崩盤,但目前還沒有人意識到這一點。”
不過,現在就高呼“中國 AI 已經超越美國”或“遙遙領先”還為時過早。如清華大學計算機系長聘副教授劉知遠所説:“DeepSeek 的突破確實證明了中國 AI 通過有限資源的極致高效利用,實現以少勝多的獨特優勢,中美 AI 差距正在縮小。”
但現在還遠未到“勝券在握”的時候。劉知遠認為:“AGI 新技術還在加速演進,未來發展路徑還不明確。中國仍在追趕階段,已經不是望塵莫及,但也只能説尚可望其項背。在別人已經探索出的路上跟隨快跑還是相對容易的,接下來如何在迷霧中開拓新路,才是更大的挑戰。”
從大疆到宇樹,再到當紅的 DeepSeek,越來越多的中國科技公司成為美國科技界繞不過去的熱門話題,一方面體現出中國公司在供應鏈優勢下對成本的極致敏感,這加速了技術民主化的趨勢;更體現出技術競爭的魅力,如果切換一下視角則會發現,硅谷這段時間感受到的震撼則是過去兩年中國同行的常態。
瞭望/ DeepTech深科技