梁文鋒“反對”張一鳴_風聞
字母榜-字母榜官方账号-让未来不止于大59分钟前

眼下最受關注的AI新星、DeepSeek創始人梁文鋒,正在與張一鳴背道而馳的道路上一騎絕塵。
1月28日,DeepSeek發佈新一代多模態大模型Janus-Pro,分為7B(70億)和1.5B(15億)兩個參數量版本,且均為開源。
新模型一經發布,就登上了知名AI開源社區Hugging Face的模型熱門榜。目前,在Hugging Face收錄的40多萬個模型中,熱門榜前五中,DeepSeek獨佔其四。
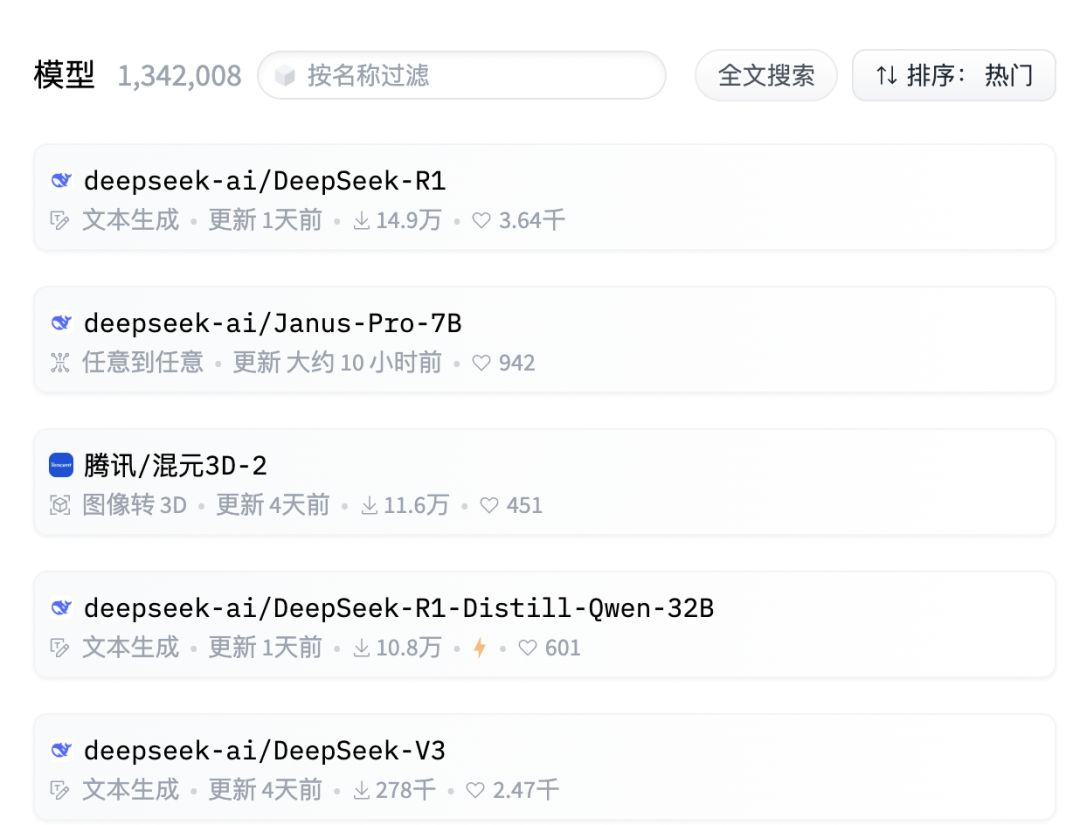
據DeepSeek介紹,相比去年11月發佈的JanusFlow,Janus-Pro優化了訓練策略、擴展了訓練數據,模型也更大,在多模態理解和文本到圖像的指令跟蹤功能方面,均取得重大進步,同時還增強了文本到圖像生成的穩定性。
與先前引發全球AI圈轟動的R1大模型類似,Janus-Pro同樣是“小力出奇跡”的成果。
根據DeepSeek發佈的測試結果,這款文生圖大模型在多項基準測試中表現出色,甚至強於OpenAI旗下的DALL-E 3,以及Stable Diffusion。
亦有用户指出,Janus-Pro談不上全面超越DALL-E 3,後者在許多測試中依然更強,輸出圖像分辨率也明顯優於Janus-Pro的384x384像素。儘管如此,Janus-Pro以70億的最大參數量,與120億參數的DALL-E 3打得有來有回,依然展現了不俗潛力。
“小力出奇跡”的策略,DeepSeek已經屢試不爽。
本月早些時候,DeepSeek發佈R1大模型。作為一款開源模型,R1在數學、代碼、自然語言推理等任務上的性能,號稱可以比肩OpenAI當前最強的o1模型正式版。o1發佈於2024年9月,此前從未被國內AI公司迫近,直到R1橫空出世。
更重要的是,DeepSeek只花費了相當於OpenAI零頭的資金、資源,就拿出了堪與o1比肩的產品。
DeepSeek並未公佈R1的訓練成本。可供參考的是,去年12月底,DeepSeek發佈V3模型,與OpenAI的GPT-4o性能接近,使用2048塊英偉達H800芯片,耗費約560萬美元。相比之下,GPT-4o使用上萬塊英偉達H100芯片(性能優於H800),訓練成本約1億美元。
V3、R1不到一個月接連降生,除了震動業界,也讓AI時代的賣卡王者閃了腰。
1月27日美股交易中,英偉達股價暴跌17%。一天之內,英偉達市值蒸發5940億美元(約合4.3萬億人民幣),相當於跌掉了一個騰訊加一個美團。
但長期來看,芯片依然是AI大模型的發展基石,英偉達作為這一領域技術壁壘最堅固的公司,“賣鏟者”的長期價值依然堅挺。
面對DeepSeek 衝擊波和其“小力出奇跡”的方法論,篤信並踐行“大力出奇跡”的字節跳動難免有點尷尬。
自從2023年大舉進軍AI大模型以來,字節一邊揮舞着支票簿,全球大手筆求購芯片;一邊快速擴充AI業務矩陣,先後發佈十幾款大模型,外加十幾個AI應用。無論是資金、資源、人才投入,還是AI產品矩陣和業務條線的數量,字節均遙遙領先其他國內大廠。
時至今日,字節在AI大模型領域的“大力出奇跡”收到了一些效果。根據量子位智庫的數據,截至2024年11月底,字節旗下豆包APP的累計用户超1.6億,日活躍用户接近900萬,全球範圍內僅次於ChatGPT。
但“小力出奇跡”的DeepSeek,讓字節看似無可置疑的“大力”打法遭遇“破壁人”。
字節此前依靠“大力出奇跡”,在短視頻、電商、本地生活、遊戲、AI等領域開疆拓土。但DeepSeek證明,在技術創新的加持下,“小力”同樣可以創造“奇蹟”,這不僅揭示了一條新的技術路線,也藴含着新的商業哲學。
在這一層意義上,梁文鋒隔空“反對”張一鳴。DeepSeek不僅在AI技術和產品上打破了舊思維,也在不經意間點破了**“大力出奇跡”並非放諸四海皆準的商業真理。**
A
在Janus-Pro發佈前,“小力出奇跡”的R1追平了o1,已經讓一眾科技大佬驚歎不已。同樣“小力”的Janus-Pro,有多厲害?
先看成本。
根據DeepSeek披露的信息,新模型使用一種輕量級的分佈式訓練框架,1.5B參數模型大約需要使用128張英偉達A100芯片訓練7天,體量更大的7B參數模型則需要256張A100芯片,以及14天訓練時間。
以此推算,依靠大幅壓縮芯片使用量和訓練時間,Janus-Pro的模型訓練成本(不含購買芯片等費用)可低至數萬美元,相當於一輛新能源車的價格。
在大模型訓練成本動輒以億為單位的大環境中,區區數萬美元,太省錢了。
再看性能。
據介紹,Janus-Pro是一種自迴歸框架,它將多模態理解和生成統一起來,將視覺編碼解耦,以實現多模態理解和生成。它通過將視覺編碼解耦為單獨的路徑來解決以前方法的侷限性,同時仍然使用單一、統一的轉換器架構進行處理。這種解耦不僅緩解了視覺編碼器在理解和生成中的角色衝突,還增強了框架的靈活性。
倘若看不懂上面這些拗口的技術名詞,不妨參考DeepSeek提供的幾個實例。
文生圖方面,輸入“一條金色的尋回犬安靜地躺在木質門廊,周圍灑滿秋天落葉”,或是“一個有雀斑的年輕女人戴着草帽,站在金色麥田中”,Janus-Pro生成的圖片都像模像樣。
至於圖生文,扔給Janus-Pro一張黃昏湖景照片,**提問“猜猜這是哪裏”,Janus-Pro能夠判斷出這是杭州西湖,**甚至點出了圖中著名景點三潭印月島。
最後看落地。
Janus-Pro繼承了DeepSeek的優良傳統:開源。它使用MIT協議(限制最少的開源協議之一),個人、中小企業可以省不少錢。另有AI開發者認為,由於模型體量小,Janus-Pro可以在PC端安裝、本地運行,有望進一步降低使用成本。
DeepSeek再度證明,**“小力”做出來的東西,並不意味着技術落後、產品拉胯,更不一定摳摳搜搜,**三步一個付費提示,五步一個月卡優惠。
而在時間維度上,“小力”甚至並不一定會比“大力”跑得更慢。
根據公開信息,DeepSeek於2024年前後推出Janus,同年11月迭代至JanusFlow。兩個月後,Janus-Pro上線,在部分指標上已經具備與DALL-E 3扳手腕的能力。
Janus-Pro橫空出世,揭示了大模型的各項成本——尤其是芯片成本——是可以被大幅壓縮的。或者説,OpenAI、谷歌、字節們打慣了富裕仗,過於“奢侈”和依賴“大力出奇跡”了。

有趣的是,在創下美國上市公司有史以來最大的市值蒸發幅度後,英偉達回應稱,“DeepSeek是一項卓越的人工智能進展”,同時不忘給自己做廣告,稱“推理過程需要大量英偉達GPU和高性能網絡”。
被別人隔空暴打,還得強顏歡笑,對老黃來説也是頭一遭。
B
Janus-Pro再度展示DeepSeek“小力出奇跡”的威力。相比之下,國外秉持“大力出奇跡”的OpenAI,近期卻多少有點兒翻車。
比如文生視頻大模型,去年2月OpenAI掏出Sora震驚全場,隨後卻是長達10個月的“閉門造車”。中美兩國的AI公司紛紛趁機追趕。
到了12月,Sora總算正式上菜,價格昂貴,效果卻一言難盡,被不少用户吐槽甚至不如開源模型。谷歌抓住機會,掏出自家的Veo 2與Sora對比,貼臉嘲諷。
儘管丟掉了先發優勢,OpenAI仍然沒有放棄堆芯片、堆算力的“大力”路線。
前幾天,OpenAI拉着軟銀、甲骨文等公司,宣佈要成立AI公司“星際之門”,未來四年投資5000億美元,用於AI基礎設施。OpenAI“一生黑”馬斯克第一時間潑冷水,聲稱“他們實際上沒有錢”,並言之鑿鑿稱軟銀能夠確保的資金遠低於100億美元。
與OpenAI相比,**字節對於“大力出奇跡”的玩法更加精通,**效果也好得多。
比如字節AI的核心產品——豆包大模型,在知識、代碼、推理等多項公開測評基準上,最新的1.5 Pro版本得分優於GPT-4o,以及DeepSeek-V3。換言之,豆包1.5 Pro的性能同樣位列全球大模型第一陣營。
不過,字節為AI大模型投入的成本同樣驚人。
就在DeepSeek成為焦點的這幾天,字節被曝出今年將投入超120億美元用於AI基礎設施。其中,55億美元將被用於購買芯片,68億美元將被用於海外投資。
字節隨後回應稱,相關消息並不準確。字節非常重視AI領域的發展與投入,但相關預算與規劃傳聞並不正確。
AI大模型技術仍處於快速迭代階段,公司投入巨資研發、訓練的新模型,可能幾個月甚至幾個星期後就不再領先。這意味着,如果字節沿着“大力出奇跡”的思路做AI,每年都需要砸下巨資。
這或許也從側面解釋了,字節發展AI大模型,為何從一開始就格外注重商業化。

背靠抖音、今日頭條、飛書等業務板塊,字節AI大模型不愁找客户,豆包使用量節節攀升。字節火山引擎總裁譚待曾透露,去年5月豆包大模型日均tokens為1200億,12月15日突破4萬億,7個月裏增長超過33倍。
另據界面援引知情人士言論稱,豆包大模型經過多次降價後,毛利潤率依然為正;豆包1.5 Pro的毛利潤率高達50%。
但上述知情人士透露,由於研發投入巨大,字節AI大模型業務仍處於虧損。只有持續擴大應用側的模型調用規模,才能長期攤銷掉研發成本。也就是説,字節仍然需要繼續推動**“降價-拉來更多客户-獲得更高收入-提高利潤空間-降價”**的飛輪。
相比之下,DeepSeek背靠的幻方量化是國內頂級私募之一,並不缺少資金。但DeepSeek不僅不燒錢,還想辦法改進技術來省錢,最終實現“小力出奇跡”。
DeepSeek去年初露崢嶸後,OpenAI的奧特曼在社交媒體上發帖,暗中吐槽V3大模型缺少真正的創新,只是在複製有效的東西。
從技術角度來看,奧特曼這番話未必毫無道理;但從技術理念和企業哲學來看,DeepSeek無疑給AI大模型領域注入了新鮮空氣。它不僅**“小力出奇跡”,更“節省出奇蹟”“開源出奇跡”。**這套不講“傳統武德”的組合拳,已經讓買芯片、堆算力的外國同行閃了腰,也讓字節的“大力出奇跡”路線值得再度審視。
C
字節是“大力出奇跡”打法的受益者。如今,DeepSeek卻成了它的“破壁人”。
“大力出奇跡”打法的基本邏輯是,找到最熱的賽道,快速推出產品,然後注入遠超對手的資金和流量,將其“催熟”,從而佔據優勢市場地位、獲得超額回報。字節的主要業務——今日頭條、抖音、TikTok等業務,都在“大力”的推動下,成為各自領域的領頭羊。
2024年,字節的“大力出奇跡”依然在延續。

圖源:AI製作
比如紅果短劇,據QuestMobile測算,2024年3月,紅果短劇的MAU約為5400萬;當年11月,已經突破1.4億,淨增約9000萬。一年增長近億MAU,紅果短劇顯然離不開抖音乃至整個字節的託舉。
在海外,號稱“海外版小紅書”的Lemon8,也在TikTok面臨危局時大規模投流,下載量暴增,一度被視為字節的海外B計劃。
而在AI領域,浙商證券在去年底的一份報告中估算,2024年字節在AI上的資本開支高達800億元,接近百度、阿里和騰訊的總和(約 1000 億元)。**預計2025年,這一數字將翻倍至1600億元,**其中AI算力採購900億元,數據中心基建和網絡設備則佔700億元。
字節“大力出奇跡”吃過不少敗仗,比如遊戲、教育、PICO等。但作為字節的底層方法論之一,“大力出奇跡”並沒有被捨棄。同時,紅果短劇等新產品的成功,也證明這套方法論仍然有效。
但“大力出奇跡”要想充分發揮威力,需要外部環境存在這樣的特徵:技術創新的重要性,遠不如資金資源。
在技術發展平穩期,企業往往會發現自己身處這樣的環境。近些年,移動互聯網技術基本沒有大突破,哪家公司錢更多、資源更豐富,就更有能力搶佔更多市場和利潤。“大力出奇跡”不僅有效,幾乎成為不得不選的答案。
但**一旦技術有了飛躍式突破,資金資源就會退居次席。**這樣的故事,已經在新能源車、商業航天領域發生過,如今正在AI大模型賽道重演。
在這一層意義上來説,“小力出奇跡”的DeepSeek,打破了字節乃至中國互聯網的執念和迷思。R1等新模型的強力表現,讓技術再度壓倒流量、資金、人力等,成為企業和行業發展的主要驅動力。
家底豐厚的DeepSeek並非被迫省錢,而是有意控制投入,將“小力出奇跡”視為一種更高層次的商業哲學,而非應對資金緊張的舉措。這也意味着,大模型並非只是“大廠遊戲”。中小廠完全可以用更少的芯片和費用,做出更好的產品,進而得到市場和投資者的認可。
相對應的是,AI大模型公司的發展潛力和投資價值,也不應與所持有的芯片數量強綁定。“小力出奇跡”的價值不僅在於技術,也讓大廠主導的“大力”商業邏輯和價值體系發生動搖。
在科幻小説《三體》中,人類為了應對外星威脅,炮製各類耗費巨大的戰略計劃,卻被小小的“破壁人”一語點破。而在商業世界中,忙於“大力出奇跡”的字節、OpenAI們,正在與DeepSeek扮演的“破壁人”正面相遇。
參考資料:
字母榜,《DeepSeek推翻兩座大山》
騰訊科技,《省錢也是技術活:解密DeepSeek的極致壓榨術》
人人都是產品經理,《霸榜全球 AI 產品 Top100、重啓 App 工廠,熟悉的字節跳動又回來了》
鞭牛士,《字節跳動今年計劃斥資120億美元用於AI芯片》
鈦媒體,《DeepSeek除夕炸場!開源多模態模型發佈,僅128顆A100訓練,英偉達市值減4.3萬億》