我們用最近很火的DeepSeek挑戰了物理所出的競賽題,結果... | 內附答案_風聞
中科院物理所-中科院物理所官方账号-1小时前
近日,我國“深度求索”公司發佈的具備深度思考和推理能力的開源大模型DeepSeek-R1受到了全世界的關注。在DeepSeek-R1之前,美國OpenAI公司的GPT-o1,Athropic公司的Claude,Google公司的Gemini,都號稱具備了深度思考和推理能力。這些模型在專業人士和吃瓜網友的五花八門的測試中,表現的確是驚才絕豔。特別引起我們興趣的,是Google的專用模型AlphaGeometry在公認高難度的國際奧林匹克數學競賽中取得了28/42的成績,獲得銀牌。學生時代我們也接觸過奧數,深知能在此類國際奧賽中獲銀牌的選手,無一不是從小就體現出相當數學天賦,且一路努力訓練的高手。能夠達到這個水平的AI,稱其為具備了強大的思考能力並不過分。自打那之後,我們就一直好奇,**這些強大的AI,它們的物理水平又如何?**是不是以後就不用招研究生和博士後了?
1月17日,中科院物理所在江蘇省溧陽市舉辦了“天目杯”理論物理競賽。我們命題組完成了這份試卷的出題工作。七道題除一道外,都不是從現成的題庫或考題中改編節選的,我們三個對這套試卷比較滿意,覺得它既不像傳統考試題一樣盯着個別知識點考,也不像高中競賽題一樣需要很多技巧和熟練度,而更像實際科研中碰到的具體技術問題。競賽前的某天,我們和幾個朋友一起吃飯,其中一位AI的重度用户知道了我們出了這份題,就問有沒有測試過AI的表現?我們覺得這個建議很有意思,於是決定在競賽後,測試幾個有代表性的大模型。
所謂來得早不如來得巧。1月20日,當我們剛結束競賽回到北京,正趕上DeepSeek-R1發佈引爆了AI圈,它自然成了我們測試的首選模型。此外我們測試的模型還包括:OpenAI發佈的GPT-o1,Anthropic發佈的Claude-sonnet。下面是我們測試的方式:
1.整個測試由8段對話完成。
2.第一段對話的問題是“開場白”:交代需要完成的任務,問題的格式,提交答案的格式等。通過AI的回覆人工確認其理解。
3.依次發送全部7道題目的題幹,在收到回覆後發送下一道題,中間無人工反饋意見。
4.每道題目的題幹由文字描述和圖片描述兩部分組成(第三、五、七題無圖)。
5.圖片描述是純文本方式,描述的文本全部生成自GPT-4o,經人工校對。
6.每個大模型所拿到的文字材料是完全相同的(見附件)。
上述過程後,對於每個大模型我們獲得了7段tex文本,對應於7道問題的解答。以下是我們採取的閲卷方式:
1.人工調整tex文本至可以用Overleaf工具編譯,收集編譯出的PDF文件作為答卷。
2.將4個模型的7道問題的解答分別發送給7位閲卷人組成的閲卷組。
3.閲卷組與“天目杯”競賽的閲卷組完全相同,且每位閲卷人負責的題目也相同。舉例:閲卷人A負責所有人類和AI答卷中的第一題;閲卷人B負責所有人類和AI答卷中的第二題,等等。
4.閲卷組彙總所有題目得分。
結果如何呢?請看下錶。
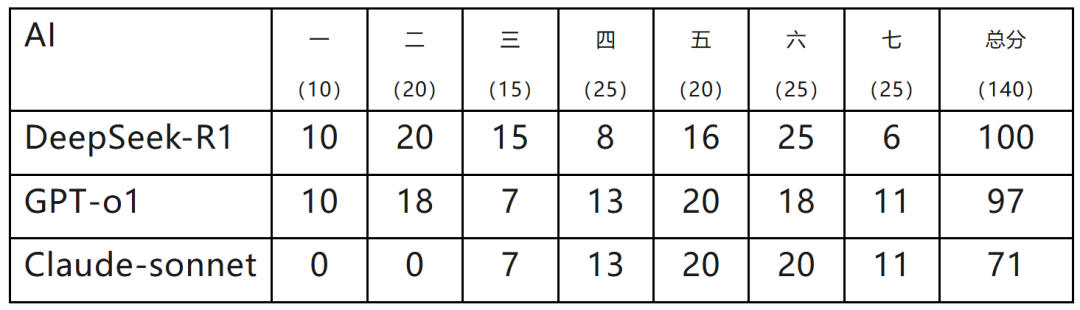
結果點評:
1.DeepSeek-R1表現最好。基礎題(前三題分數拿滿),第六題還得到了人類選手中未見到的滿分,第七題得分較低似乎是因為未能理解題幹中“證明”的含義,僅僅重述了待證明的結論,無法得分。查看其思考過程,是存在可以給過程分的步驟的,但最後的答案中這些步驟都沒有體現。

2.GPT-o1總分與DeepSeek相差無幾。在基礎題(二題、三題)中有計算錯誤導致的失分。相比於DeepSeek,o1的答卷更接近於人類的風格,因此以證明題為主最後一題得分稍高。

3.Claude-sonnet可謂“馬失前蹄”,在前兩題中連出昏招打了0分,但後續表現跟o1相當接近,連扣分點都是類似的。

4.如果將AI的成績與人類成績相比較,則DeepSeek-R1可以進入前三名(獲特優獎),但與人類的最高分125分仍有較大差距;GPT-o1進入前五名(獲特優獎),Claude-sonnet前十名(獲優秀獎)。
最後想聊幾句閲卷的主觀感想。首先是AI的思路是真的好,基本上沒有無法下手的題,甚至很多時候一下子就能找到正確的思路。但跟人類不同的是,它們在有正確的思路後,會在一些很簡單的錯誤裏面打轉。比如通過看R1的第七題思考過程,就發現它一早就知道要用簡正座標來做,能想到這一步的考生幾乎100%求解出了正確的簡正座標(一個簡單的矩陣對角化而已),但是R1似乎是在反覆的猜測和試錯,到最後也沒有得到簡正座標的表達式。還有就是所有的AI似乎都不理解一個“嚴密”的證明究竟意味着怎樣的要求,似乎認為能在形式上湊出答案,就算是證明了。AI如同人類,也會出現許多“偶然”錯誤。比如在正式的統一測試前,我們私下嘗試過多次,很多時候Claude-sonnet可以正確解出第一題的答案,但正式測試的那次它就偏偏做錯了。出於嚴謹,我們也許應該對同一道題測試多次然後取平均,但實在是有點麻煩……

除了上面AI的測試結果,這次我們還發布了本次試題的參考答案。我們當然是故意比試題遲幾天發佈答案的,想讓大家先自己挑戰一下。在每道題的解答後,我們還加入了一小段“編後”,有命題人對這道題的評價,以及一些引申的思考等。我們希望答案可以幫助不會做的同學學習,也能引發會做的同學進一步的思考。
附件中我們提供了:
1.所有向大模型發問的輸入文本(txt),
2.每個大模型給出的原始答案文本(txt)和人工整理出的答卷(PDF),
3.命題組提供的標準答案。
最後感謝“字節跳動”的AI“豆包”對本文的修改~
春節快樂,學習進步,工作順利!
冬令營組委會
乙巳年正月初二