大模型推理更可能是概率模式匹配?北大團隊從蒙特卡洛語言樹的新視角解讀GPT_風聞
量子位-量子位官方账号-1小时前
GPT-Tree團隊 投稿
量子位 | 公眾號 QbitAI
思維鏈(CoT)為什麼能夠提升大模型的表現?大模型又為什麼會出現幻覺?
北大課題組的研究人員,發現了一個分析問題的新視角,將語言數據集和GPT模型展開為蒙特卡洛語言樹。
具體來説,數據集和模型分別被展開成了Data-Tree 和GPT-Tree 。
結果,他們發現,現有的模型擬合訓練數據的本質是在尋求一種更有效的數據樹近似方法(即)。
進一步地,研究人員認為,大模型中的推理過程,更可能是概率模式匹配,而不是形式推理。
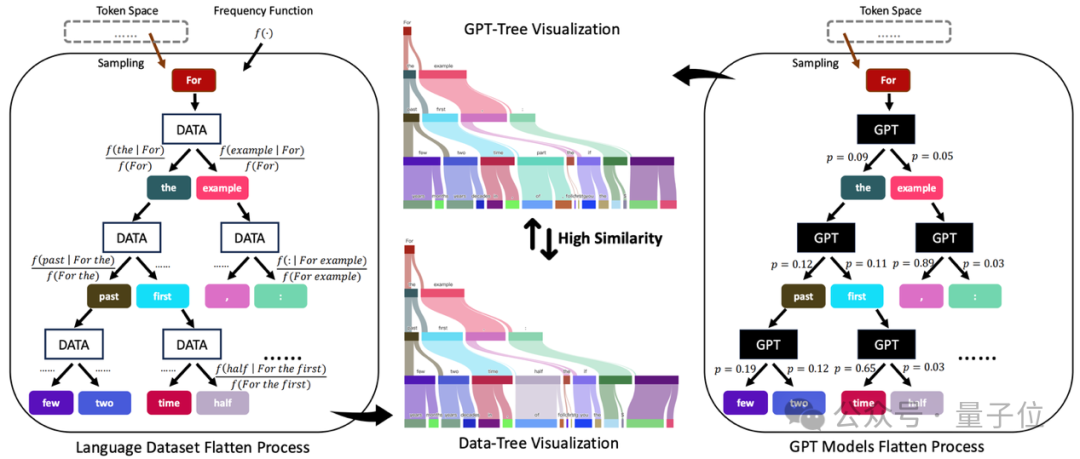
將數據和模型拆解為蒙特卡洛樹
在預訓練過程中,大模型通常學習的是如何預測下一個token(也就是將每個token的似然進行最大化),從而對大規模數據進行無損壓縮。
其中, 是優化上述似然得到的模型參數。
作者發現,任何語言數據集****都可以用蒙特卡洛語言樹(簡稱“Data-Tree”)完美地表示,參數化為。
具體來説,作者採樣第一個token作為根節點(例如“For”),枚舉其下一個token作為葉子節點(例如“the”或“example”),並計算條件頻率()作為邊。
重複這一過程,就可以得到被語言數據集扁平化的“Data-Tree”。形式上,Data-Tree滿足以下條件:
其中,代表頻率函數, 代表第個token。作者從理論上證明了Data-Tree的是上述最大似然的最優解。換句話説,最大化似然得到的模型參數最終都在不斷靠近。
類似的,作者提出任意的類GPT模型****也可以展開成另一顆蒙特卡洛語言樹(簡稱“GPT-Tree”),參數化為。
為了構建GPT-Tree,作者也從token空間採樣第一個token 並將其輸入到GPT,然後記錄其第二個token 以及其概率分佈│。
接着,作者枚舉所有的第二個token,並將輸入到GPT並得到第三個token 。
重複這一過程,就可以得到GPT展開後的“GPT-Tree”。
蒙特卡洛樹視角下的新發現在將數據和模型展開後,作者有了新的發現,並用新的視角解釋了一些模型現象。
下圖是對GPT-X系列模型和Data-Tree的樹形可視化結果,其中每列代表不同token,每行代表不同的模型,最後一行代表Data-Tree。
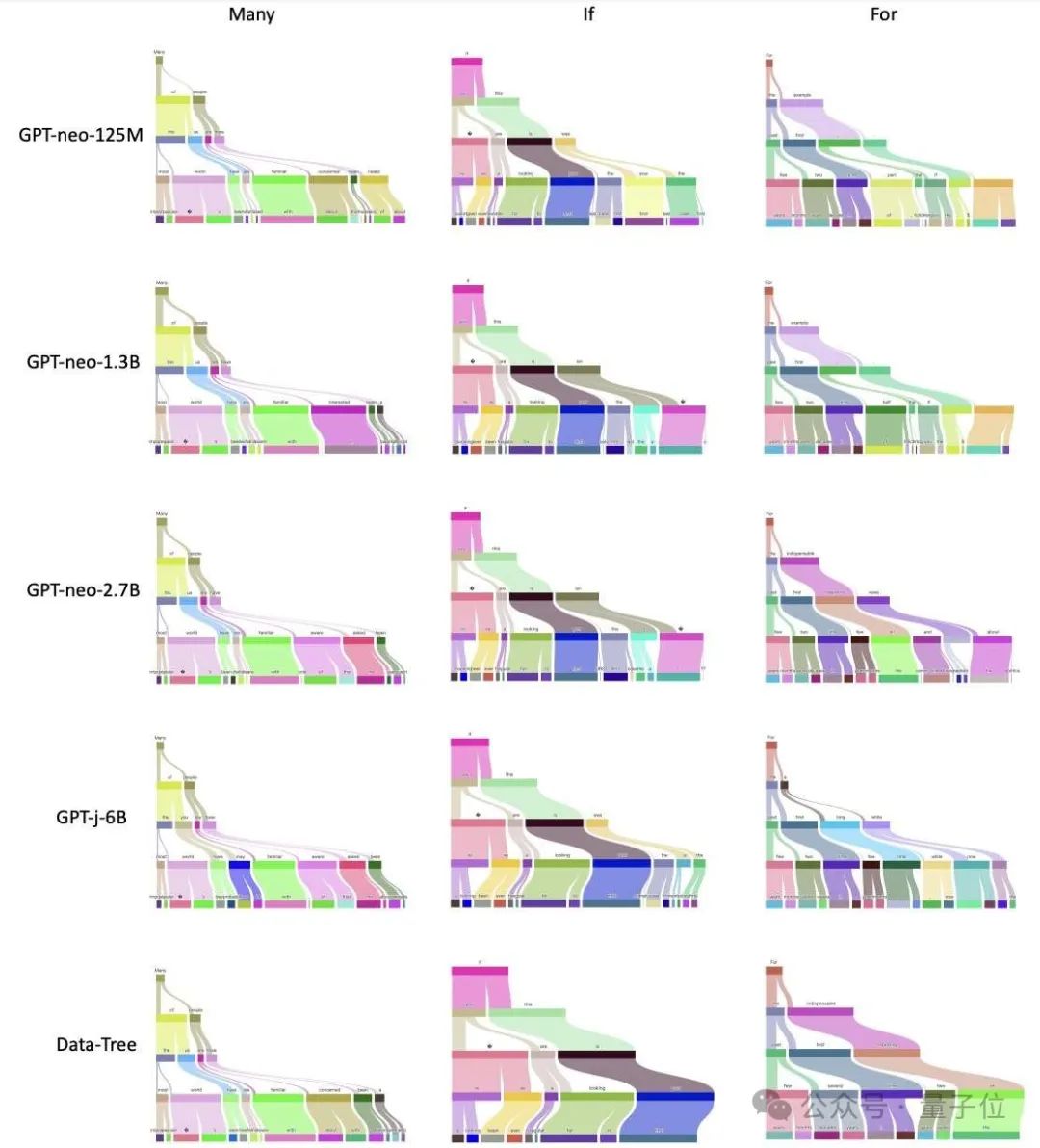
GPT模型逐漸收斂於數據樹
作者發現,在同一數據集(the Pile)上訓練的不同語言模型(GPT-neo-X系列模型)在GPT-Tree可視化中具有顯著的結構相似性。
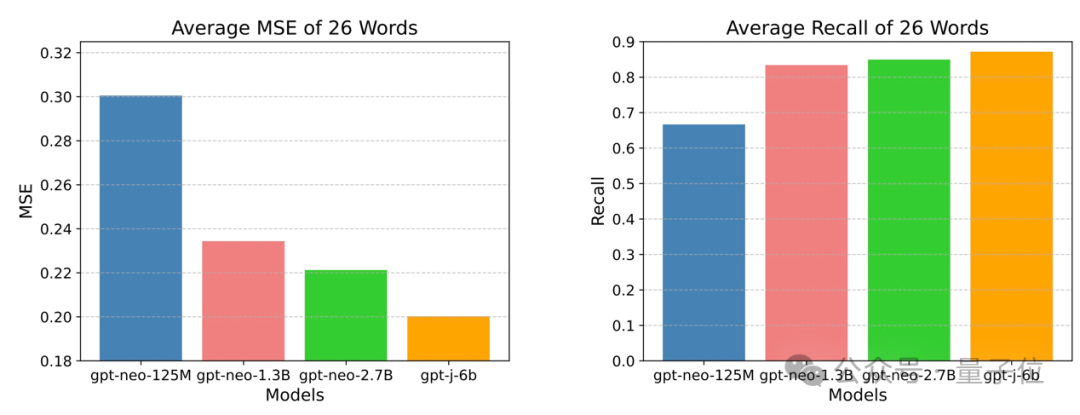
通過對這一結果進行進一步量化,作者發現,GPT模型越大,越接近 Data-Tree,超過87%的GPT輸出token可以被Data-Tree召回。
這些結果表明,現有的語言模型本質上尋求一種更有效的方法來近似數據樹,這可能證實了LLM的推理過程更可能是概率模式匹配而不是形式推理。
理解token-bias現象和模型幻覺
Token-bias現象首次發現於賓夕法尼亞大學Bowen Jiang等人的研究(arXiv:2406.11050),並被蘋果公司的Iman Mirzadeh等人進行了進一步的研究(arXiv:2410.05229)。
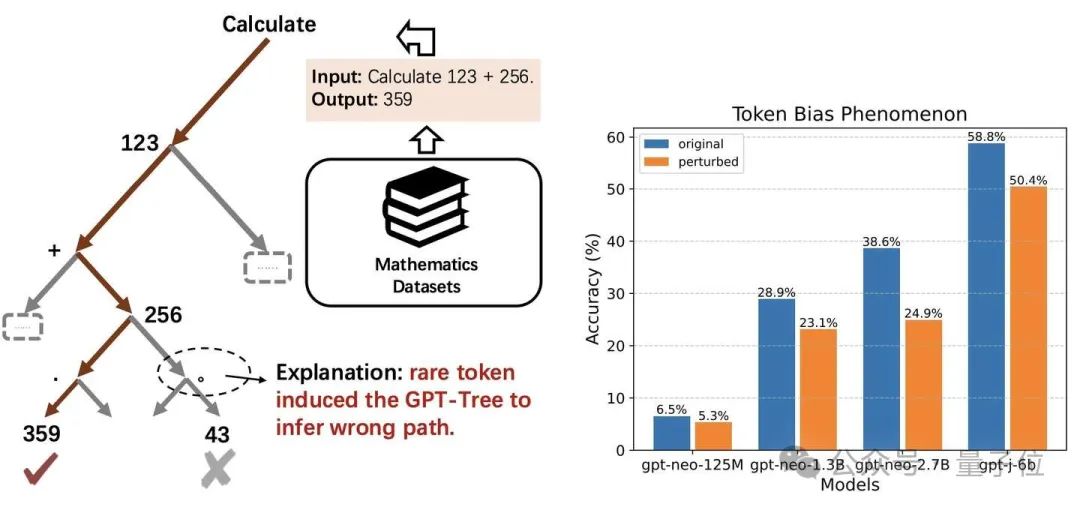
例如對於一個簡單的數學計算問題,“Calculate 123 + 256.”,將最後一個 token“.”擾動成“。”,模型就會錯誤地回答為“43”。
作者認為,token-bias是由於一些罕見的token誘導GPT-Tree推斷錯誤的路徑。
作者通過評估21076對QA測試對中不同模型的原始(藍色條)和擾動(橙色條)精度進一步量化了這一現象。
擾動最後一個token後,所有模型的準確性都顯著下降。
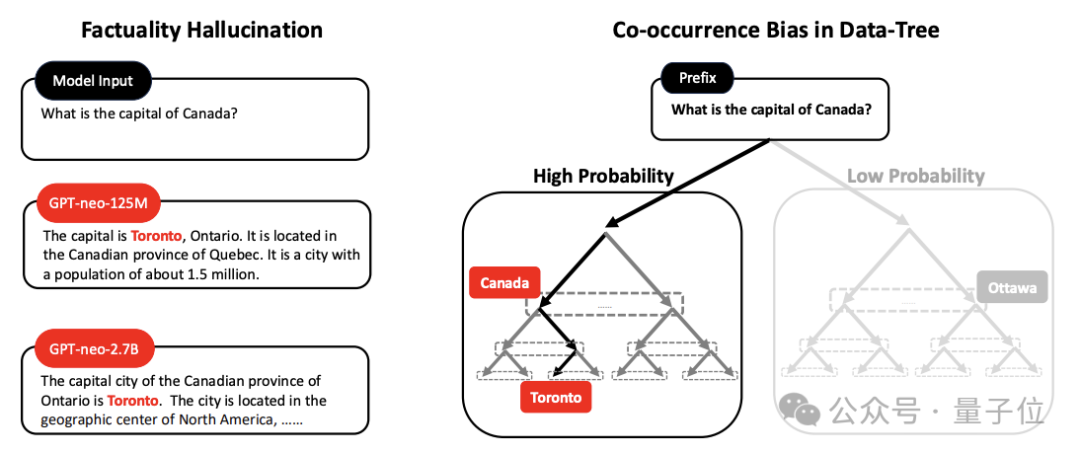
而至於模型幻覺,作者認為這是由數據樹的共現偏差造成。
如下圖所示,訓練數據表現出多倫多和加拿大這兩個術語的高頻共現,導致模型嚴重傾向於這些語料庫,從而錯將多倫多認為是加拿大首都。
理解思維鏈的有效性
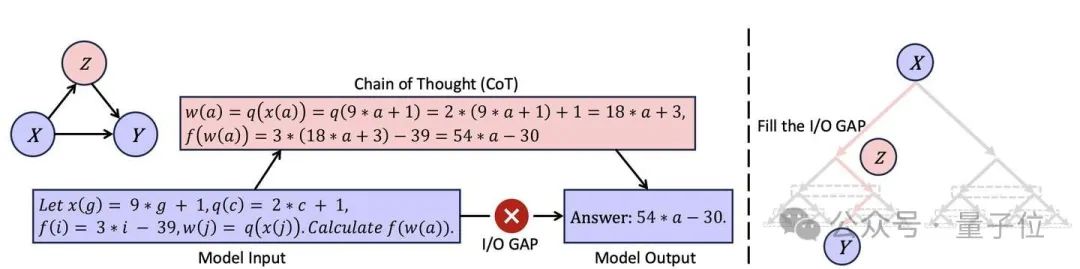
在蒙特卡洛樹的視角下,思維鏈的有效性也有了新的解釋。
對於一些複雜的問題,輸入X和輸出Y之間存在明顯的 Gap,使得GPT模型難以直接從X中輸出Y。
從GPT-tree的視角來看,輸入X位於父節點,輸出Y位於比較深的葉節點。
思維鏈的原理就是試圖彌補這一缺口,即試圖尋找路徑Z來幫助GPT模型更好的連接X和Y。
論文地址:
https://arxiv.org/abs/2501.07641
項目主頁:
https://github.com/PKU-YuanGroup/GPT-as-Language-Tree