從於敏到梁文鋒,當年我們是怎麼搞的氫彈,今天我們就怎麼搞AI_風聞
孤烟暮蝉-时评人-珍惜未来,远离公知1小时前
一、“中國成功進行了原子彈試驗,這是‘自由世界’最黑暗、最富悲劇性的一天”
1964年10月16日,在羅布泊沙漠的深處,在一陣宛如太陽般耀眼的閃光過後,面對着遠方緩緩升起的蘑菇雲,參與596工程的同志們沸騰了,原本安靜的人羣一下子成了歡樂的海洋。而在太平洋彼岸的美國,當中國原子彈橫空出世的消息傳到白宮的橢圓形辦公室裏之後,時任美國總統約翰遜卻陷入了沉默,在沉默良久之後,他終於用一種充滿沮喪的口氣,無可奈何地承認了那個令美帝國主義者痛苦不已的事實:

“中國成功進行了原子彈試驗。這是‘自由世界’最黑暗、最富悲劇性的一天。”

美國總統林登·約翰遜

時隔60年以後,大洋彼岸的又有一羣美國人,他們也經歷了一次和當年約翰遜一樣的至暗時刻。
當地1月23日,在美國匿名職場論壇TB(TeamBlind)上,一名Meta公司員工發佈的一篇帖子一石激起千層浪。在這篇題為《Meta的生成式人工智能部門陷入了恐慌》的文章中,這位Meta公司員工用一種悲哀中又帶着幾分戲謔的語氣如是寫道:
“550萬美元,你們知道這是個什麼概念嗎?Meta公司的生成式AI部門裏頭有很多所謂的‘領導’,他們之中每一個人的年薪都超過了這個數字。我們投入了那麼多錢到底都花到哪兒去了?這些享受着高薪厚祿的所謂‘領導’又該怎麼去向公司高層解釋他們的存在意義呢?DeepSeek就已經足夠可怕了,自它橫空出世以來,我們Mate的工程師都在沒日沒夜地瘋狂對它進行拆解研究,並試圖從中抄襲一切我們能夠抄襲的東西,並希望藉此複製出一個逆向的DeepSeek出來。可都沒等我們抄明白上一個版本呢,中國人就發佈了他們的最新版本DeepSeek-R1,這下事情變得更糟糕了。當對手的更新頻率已經超過了你的抄襲速度的時候,你哪怕不是幹我們這一行的也應該心裏有數了。家人們,還有高手!大的要來了!”
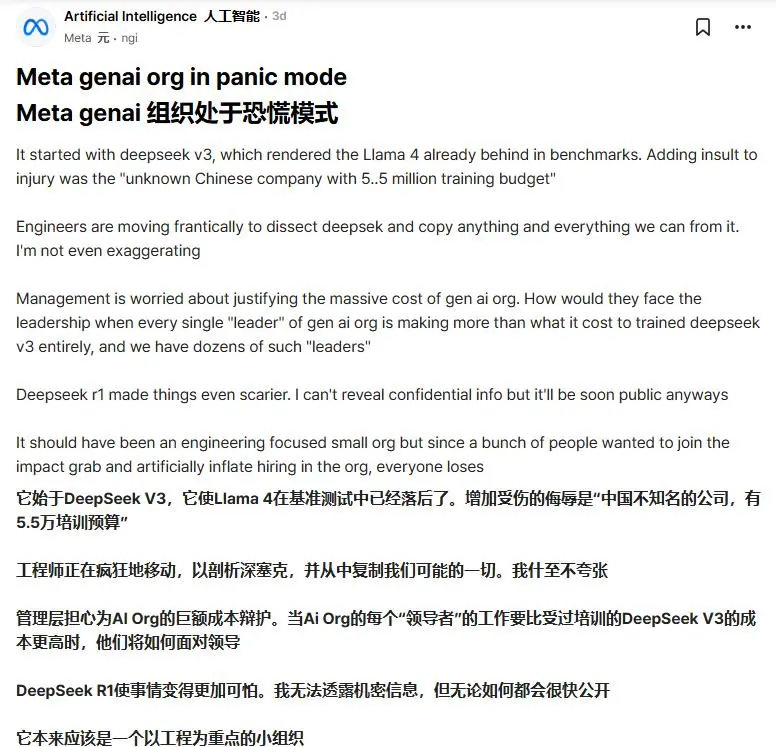
其實不光扎克伯格的Meta,我估計這會兒山姆·奧爾特曼的OpenAI公司也挺焦慮的。因為OpenAI訓練出來的 GPT-4o模型的成本高達1億美元,這個數字幾乎是深度求索訓練同類模型成本的近20倍。

雖然Mate和OpenAI在AI這塊花了比深度求索多得多的錢,但是最後他們搞出來的大語言模型卻並沒有展現出比DeepSeek更強的技術競爭力。毫不誇張地説,在這場沒有硝煙的AI革命中,中國再次復現了“兩彈一星”的奇蹟——既用最低的成本、最高的效率,在最嚴苛的技術封鎖下,完成了對西方霸權的彎道超車。

今天美國宣佈對華禁運高端顯卡,就相當於當年中蘇交惡。蘇聯撤走對華援助專家,妄圖通過這種方式來迫使我們知難而退,但是以鄧稼先和于敏為代表的中國科學家卻選擇迎難而上,最終創造了震驚世界的科技奇蹟。

我現在看深度求索搞出來的DeepSeek模型,很是有種看于敏他們當年搞出來的中國氫彈的感覺。在於敏的團隊提出“于敏構型”之前,全世界都是以美國人最先提出的“泰勒-烏拉姆構型”(簡稱TU構型)作為指導原理開發核聚變武器的,因為氫彈最早就是美國人搞出來的嘛,完了蘇聯和英國也是跟着美國那一套學的。
我們搞氫彈一開始也不例外,在2021年播出的電視劇《功勳》之《無名英雄于敏》中,雷佳音飾演的于敏在劇中有一場戲是這麼演的:項目組根據美國科學期刊刊載的學術論文,大致推斷出了TU構型的原理。



TU構型沒有想象中的那麼複雜,但是有一個缺點——試錯成本太高,以當時中國的國力來説很難承受。如果要通過科學實驗的方式來確認這一技術路徑的可行性,我們至少要花費3年的時間、並付出數億人民幣的成本,這對於當時就吃飯都成普遍問題的中國來説是不可接受的。

二、中美氫彈競賽:你有大力出奇跡,我有四兩撥千斤
在這種情況下,于敏力排眾議,決心帶領團隊獨自摸索出一條適合中國國情的氫彈研製之路。在克服了常人難以想象的重重困難之後,1965年9月,于敏和他的同志們終於在理論研究上取得了突破性進展。


此後,為了驗證方案可行性,他帶領團隊來到了中科院上海華東計算機研究所,動用了當時國內最先進的、同時也是唯一一台能以每秒5萬次的運算速度進行計算的電子計算機。兩個月後,于敏設想的模型在計算機驗算中取得了成功,人類的氫彈理論研究由此在西方模式之外延伸出了一條東方道路。從此之後,美國的TU構型不再是解開製造氫彈難題的唯一方程式,中國的于敏構型猶如長坂坡陣前的常山趙子龍,單槍匹馬,從80萬曹軍的重重包圍之中,浴血殺出。


有關TU構型和于敏構型二者的區別,我就這個問題問了一下DeepSeek,完了它給了我一個我覺得很有意思的回答:
用TU構型來搞氫彈是典型“大力出奇跡”的做事邏輯,這種構型的好處是簡單粗暴,適於量產和造大氫彈。美國的B-41氫彈(2500萬噸TNT)和蘇聯的“沙皇炸彈”(5000萬噸TNT)均基於此設計。
但TU構型也存在一些明顯缺點。該構型好比一家美式連鎖快餐店,採用標準化生產流程,賣的都是預製菜。其中一些重要的食材,比如液態氘,需要超低温保存。你為了保存它還得配一大堆昂貴的冷卻設備。這樣造出來的氫彈成本會很高,而且又笨又重。以美國第一種熱核武器試驗裝置“常春藤麥克”為例,該裝置重達82噸,其中光製冷設備就佔去了一半的重量。

而於敏構型的思路則和TU構型大相徑庭,DeepSeek管這叫“中式四兩撥千斤”。于敏構型對於材料和計算的精度要求極高,相當於用繡花針雕微縮景觀。利用這種技術造氫彈,燃料利用量要比TU構型高得多,而且不依賴複雜的冷卻設備。所以,我們基於于敏構型搞出來的中國第一顆氫彈就比美國的“常春藤麥克”輕巧得多,爆炸當量雖然達到了300萬噸TNT,但是總重卻僅有3噸。
和TU構型相比,利用於敏構型造出來的氫彈具有小而精的特點,這對重量敏感的導彈和飛機特別友好。我國造出來的第一顆實戰化氫彈“狂飆一號”,甚至用強-5強擊機就能掛載。

不僅如此,我們還是在五常之中同時最少搞出氫彈的國家。美國用了8年零6個月,蘇聯用了4年,英國用了4年零7個月,法國用了8年零6個月,而中國只用了2年零8個月。此外,和主導了我國原子彈工程的鄧稼先等人不同,于敏是完全土生土長的中國科學家,他系北大研究生畢業,從未出國留學,但研究水平高得嚇。甚至就連錢三強老爺子都曾對於敏做出過這樣的評價:“于敏填補了我國原子核理論的空白。”

我為什麼要在這裏花這麼長的篇幅向大家介紹這段往事呢?因為我在出這期節目的過程中看到了《科技日報》在今年1月中旬刊登的一篇報道《深度求索大模型:“花小錢辦大事”》,其中有很多細節,讓我越看越覺得有種歷史照進當下的深深感慨:
深度求索訓練出來的DeepSeek-V3模型,相較上一代產品能力得到了大幅提升,但訓練成本有557.6萬美元,僅用了2048塊上一代H800顯卡,耗時不到兩個月。而相比之下,OpenAI僅僅是為了訓練出GPT-4o模型就花了1億美元,用了1萬塊更先進的A100顯卡,花費的時間也是深度求索的好幾倍。

包括創始人梁文鋒在內,深度求索團隊規模僅有139人,而且這些研究人員基本上都是國內頂尖高校的應屆畢業生,又或者是還沒畢業的博四、博五的實習生,也還有一些畢業才幾年的年輕人。在接受採訪的過程中,梁文鋒特別提到,他們搞DeepSeek-V2模型的時候沒有用到海外回來的人,全都是咱中國本土培養出來的苗子。而反觀山姆·奧爾特曼的OpenAI呢?整個團隊僅人員規模就達到了1200人,人員構成複雜,美國本土培養出來的人才並不佔絕對多數,其中甚至還有不少華人面孔。

三、從於敏到梁文鋒,從氫彈到AI,一代中國人有一代中國人的使命和擔當
1995年1月,香港曾經上映過一部名叫《金玉滿堂》的美食賀歲電影,它尾聲部分的高潮情節,有一場戲是這麼演的:滿漢樓和超凡飲食集團之間的滿漢全席大比拼進入到了第三輪,雙方比試的菜餚是猴腦。猴子是保護動物不能吃,所以雙方都只能另闢蹊徑。熊欣欣飾演的超凡飲食集團老闆,雖然廚藝過人、但品性敗壞的黃榮,以羊腦來代替猴腦,並用天九翅和虎鯊牙粉等金貴食材來調味,最後做出了可以媲美猴腦的“齊天大聖會虎鯊”,並且獲得了三位評委的一致好評。

《金玉滿堂》
為了壓倒滿漢樓,黃榮在比賽過程中用盡了各種卑鄙手段。就在最後他自以為勝券在握,滿漢樓的所有權已是自己囊中之物的時候,滿漢樓一羣土生土長的中國廚師,尤其是鍾鎮濤飾演的廖傑和趙文卓飾演的龍崑保,他們硬是頂着各種不利因素,整出了一個令在場所有人都驚掉下巴的絕活:用椰子殼模仿猴子的腦殼,用神乎其神的刀工硬生生把豆腐腦給雕刻成了猴子腦的形狀,然後再用好幾種不同的常食動物腦花來進行混合調味,最後愣是烹調出了足以以假亂真的“生滾猴腦”,驚豔全場。
如今,在中美兩國如今這場你追我趕AI大角逐之中,我似乎也在奧爾特曼、扎克伯格和梁文鋒這些人的身上,看到了熟悉的影子。奧爾特曼、扎克伯格是黃榮,而梁文鋒則是廖傑、龍崑保。事實證明,要想把菜做得出彩,光靠猛堆料和使下三濫的招數是沒用的,得動腦子,得別出心裁,最重要的是,得走正道。

做菜如此,做人做事也一樣。老子説,治大國如烹小鮮,我相信其中的一些哲學道理用來評價中美兩國的治國理政和發展道路也是適用的。
如果在另一個平行世界裏,我們沒有搞出AI,梁文鋒也沒有創建深度求索,而是奧爾特曼他們的OpenAI公司工程師團隊的一員。要是這樣的話,我相信中國人最後還是會研究出屬於我們自己的大語言模型的,只不過那就是《橫空出世》中李幼斌飾演的陸光達(原型是鄧稼先)和蘇聯專家的戲碼了:

《橫空出世》
美國採取極限制裁政策,宣佈禁止對華出口一切高端芯片和顯卡,還要迫害並驅逐美國的中國科研人才。在舊金山教會區的先鋒大廈,OpenAI的總部裏,梁文鋒正在收拾自己的工位,準備不日啓程回國。在回國那天,舊金山下起了大雨,奧爾特曼開着他的布加迪威龍,把梁文鋒送到機場。車停之後,梁文鋒打着傘,兩人緩緩走向候機樓,快到的時候,奧爾特曼一把將傘接過去,然後和梁文鋒説:
“梁,在這個世界上,傘永遠掌握在高個子手中”。


梁文鋒聽罷,一言不發,只是徑直走出傘外,任憑滂沱大雨如何下。梁文鋒的眼神中寫滿了堅毅和不屈,那就是中國的人工智能科研工作者在面對美國同行時最直截了當的回答。

不只是陸光達,在那麼多為了讓祖國的人工智能技術早日趕超世界先進水平的中國科研團隊裏頭,他們之中也應該會誕生一個馮石將軍。每當聊起中美兩國的人工智能競賽,這個馮石就會以一種雖然粗糙,但卻極富生命力的話語來激勵大家:
“人工智能,大語言模型,在今天這個世界上,要想我們不受欺負,那就不能沒有這個東西,所以我們就是砸鍋賣鐵,也得把它搞出來。”

“中國的大語言模型比美國的落後,中國人用美國的ChatGPT還得看人家的臉色。這口氣窩囊啊,我忘不了我們中國的科研工作者被美國算力霸權擠兑欺凌的模樣,他們掙扎着、哀嘆着,還要忍受潤人殖子們的冷嘲熱諷。廣大中國的普通網民更是可憐啊,人家封鎖你大陸的IP地址,你付了錢也不能大大方方地用,被美國抓到了還要封你的號。”
“可儘管這樣,咱屈服了嗎?沒有!咱中國人、中國的科研工作者,從來就沒怕過他美國!應該説,美國是一個美麗的國家,美國有很多善良的人民,可他的政府,還有他的企業,不應該像現在這樣,動不動就要欺負你,讓你就想對他大喊一聲,NO!去你媽的!我就是咽不下這口氣!”

一代人有一代人的使命。
一代人有一代人的擔當。
一代人有一代人咽不下的那口氣。
所以就有了一代人必須去摘下的“兩彈一星”。
橫空出世,莽崑崙,閲盡人間春色。
飛起玉龍三百萬,攪得周天寒徹。
以DeepSeek為代表的國產人工智能大語言模型,正在向我們招手。
看吶,同志們,我們的原子彈、氫彈又到了。