接入DeepSeek,百度掀起AI大模型低價風暴_風聞
源Sight-源Sight,关注互联网前沿生态和新兴商业。1小时前
 文源 | 源Sight
文源 | 源Sight
作者 | 王言
整整一個春節過後,DeepSeek的熱度依然居高不下。為了加速行業大模型的落地,DeepSeek系列模型已在國內外多家主流雲平台完成上架部署。
與此同時,DeepSeek也打破了大模型賽道參與者一直以來所堅守的信仰,一場以“低成本、高效率”為核心的AI普惠革命,拉開帷幕。
一個最直觀的例子是,相比傳統AI訓練模式,DeepSeek能在相同任務下,大幅降低對計算資源的需求,從而降低硬件投入成本。這也是DeepSeek在能夠提供媲美ChatGPT-o1服務的同時,但又無需用户付費的底氣所在。
也是因此,2025年也成為AI大模型不斷降本增效的一年。在DeepSeek的刺激下,不少國內外廠商宣佈上線DeepSeek大模型,並開始拿出真金白銀,以高性價比服務吸引更多用户。
作為國內AI先行者,百度無疑是最為特別的一個。
01
摩爾定律在大模型的效力
如果要在國內找到一家深度參與大模型商業化的平台,百度一定位列其中。
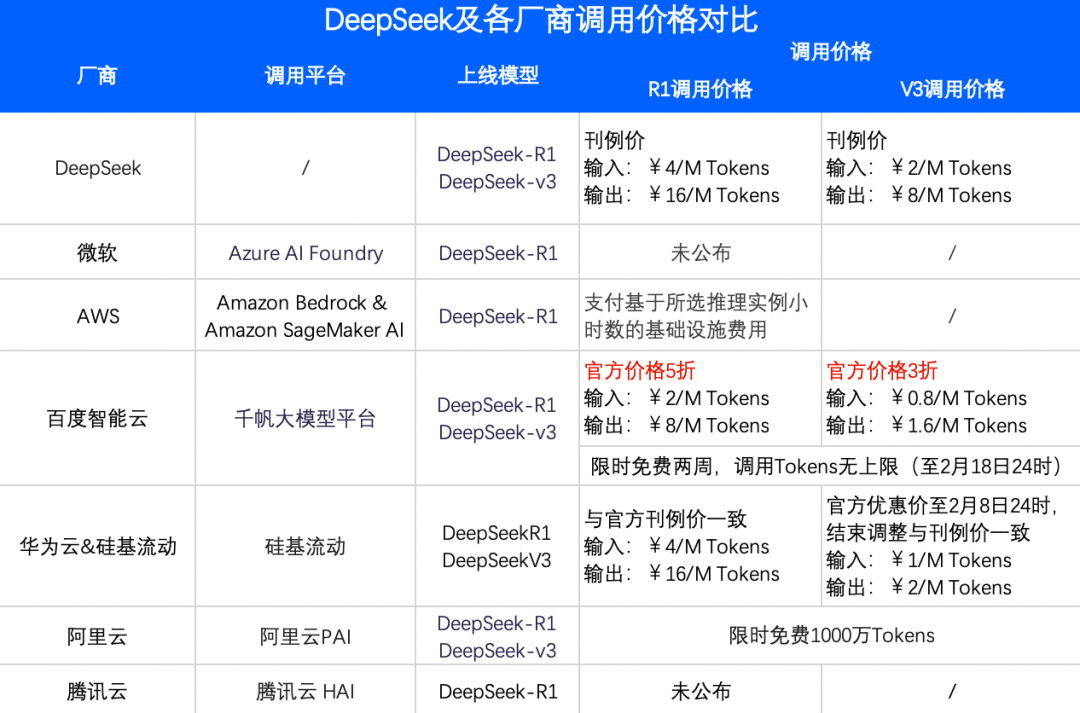
2月3日,百度智能雲宣佈,其千帆平台正式上架DeepSeek-R1和DeepSeek-V3模型,並推出了超低價格方案——價格僅為DeepSeek-V3官方刊例價的三折,DeepSeek-R1官方刊例價的五折。此外,用户還可以享受限時免費服務。
百度智能雲稱,此次接入的模型已全面融合千帆推理鏈路,集成百度獨家內容安全算子,實現模型安全增強與企業級高可用保障,同時支持完善的BLS日誌分析和BCM告警,助力用户安全、穩定地構建智能應用。
 據公開數據,DeepSeek-R1的整體成本約為OpenAI o1模型的1/30。這一數據如同地震一般,顛覆了全球相關從業者的信仰。
據公開數據,DeepSeek-R1的整體成本約為OpenAI o1模型的1/30。這一數據如同地震一般,顛覆了全球相關從業者的信仰。
被稱為“日本AI研究第一人”的東京大學教授松尾豐,就在近日表示,DeepSeek技術很出色,性能與運營“ChatGPT”的美國OpenAI接近,每次發佈新的AI模型,都會發表論文,詳細説明模型採用了什麼樣的技術,以及花費心思實施的改進之處。
松尾豐還稱讚了DeepSeek以開源方式進行公開的做法。其1月發佈的最新模型“R1”,進行了提升推理能力的強化學習,最終展現出了與OpenAI的o1同等的推理性能。
同時,如何提供更加便捷、高效、經濟的產品體驗,成為AI大模型相關企業在競爭中拔得頭籌的關鍵。
此次百度智能雲千帆平台推出超低價格方案的背後,是其嘗試降低用户AI模型試錯成本的嘗試,也符合當前AI技術普惠化的趨勢。
根據市場調研和諮詢公司Gartner發佈的數據,到2027年,企業使用的AI模型中,將有一半以上具有特定行業或業務功能,而在2023年這一比例僅為不到1%。
不過,從模型訓練到應用開發的過程中,耗費大量資金、堆砌算力所造成的投入成本高、短期收益不明顯等問題,是企業實現將大模型進行業務場景化落地的主要挑戰。降低技術成本,才是推動創新實現落地的主要動力。
2月11日,“世界政府峯會”在阿聯酋迪拜開幕。百度創始人李彥宏在會上表示,在AI領域或IT行業,大多數創新都與降低成本有關。如果成本降低一定比例,生產力也隨之提高同樣比例。
“在今天,創新速度比以往都快得多。根據摩爾定律,每18個月,性能就會翻倍而價格減半。如今,大模型推理成本每年降低90%以上。”李彥宏説。
02
已經有人掀起低價風暴
對比目前已經宣佈上架DeepSeek的雲廠商以及官方刊例調用價格,百度智能雲服務的價格具有較大優勢。同時,百度智能雲也在進一步豐富平台AI模型生態,為用户提供更多元和強大的模型選擇。
總體來看,相比其他廠商,百度針對當前的市場需求提出了極具“效價比”的方案,幫助用户在產品效果、性能以及成本之間實現平衡。
據瞭解,百度智能雲千帆ModelBuilder,是百度智能雲推出的與大模型相關的平台,為用户提供模型調用、模型效果調優等服務。百度智能雲千帆ModelBuilder提供高效價比的文心模型及開源模型服務,以及模型效果調優的一站式工具鏈,包含數據加工、模型精調、模型評估、模型量化。
在DeepSeek以中國式效率打破全球AI大模型以資本和算力主導的高成本壁壘後,行業的整體生態發生了顯著的變化。
對比目前已經宣佈上架DeepSeek的廠商,以及直接通過官方進行調用的價格,百度智能雲調用R1對比官方刊例價為五折,調用V3對比官方刊例價為三折,全網最低。
可以説,在DeepSeek催化下,相比盲目地“燒錢”和堆積算力,以合理成本獲得可靠的產品體驗更為重要。
 而在當前的路線下,百度智能雲的產品和服務,已經在市場上取得了顯著的效果。
而在當前的路線下,百度智能雲的產品和服務,已經在市場上取得了顯著的效果。
根據官方數據,目前百度智能雲千帆大模型平台,已幫助客户精調了3.3萬個模型、開發了77萬個企業應用。這些應用,涵蓋了金融、政務、汽車、互聯網泛科技等多個領域,為企業客户提供了便捷、高效、經濟的大模型使用和開發體驗。
而從行業角度來看,百度的高效價比方案,不僅平衡了自身投入成本,也為整個行業提供了新的思路和方向。
03
AI大模型的技術“拉力賽”
縱觀全球AI競爭,除了保持更低成本的算力之外,擁有更高性能,也是相關企業保證自身領先地位的重要手段。
有效降低模型調用價格,提供更具效價比的方案,離不開百度智能雲強大且高效的算力支持,以及在推理引擎性能優化技術、推理服務工程架構創新和推理服務全鏈路安全保障上的深度融合。
這其中,百度的自研萬卡集羣,是其實現算力降本的關鍵。
如果將目光拉至全球大模型的競爭全景下,可以看到,單集羣萬卡已成為相關企業必不可少的配置。
畢竟,萬卡集羣可持續降低千億參數模型的訓練週期,實現AI原生應用的快速迭代。同時,萬卡集羣也支持多任務併發能力,通過動態資源切分,單集羣可同時訓練多個輕量化模型,通過通信優化與容錯機制,提升集羣綜合利用率,實現訓練成本指數級下降。
2月初,百度智能雲宣佈點亮崑崙芯三代萬卡集羣,這也是國內首個正式點亮的自研萬卡集羣。崑崙芯三代萬卡集羣,不僅為百度帶來堅實的算力支持,也有望推動模型的降本趨勢。
在推理引擎性能方面,基於自身在大模型推理性能優化方向的技術積累,百度智能雲針對DeepSeek模型MLA結構的計算,進行了極致的性能優化。並通過計算、通信、內存不同資源類型算子的有效重疊,以及高效的Prefill/Decode分離式推理架構,在核心延遲指標TTFT/TPOT滿足SLA的條件下,實現模型吞吐的大幅度提升,顯著降低模型推理成本。
在推理服務層面,百度智能雲也進行了深入的優化與創新,針對推理架構做了嚴格的推/拉模式的性能對比。同時,百度智能雲經驗證拉模式在請求處理的成功率、響應延時以及吞吐量等關鍵指標上,均展現出更為卓越的性能。
為了進一步提升系統的穩定性和用户體驗,百度智能雲巧妙地設計了一種請求失敗的續推機制,這顯著增強了系統的容錯能力和服務SLA達標率。
同時,針對多輪對話和system設定等場景中存在重複Prompt前綴的情況,百度智能雲實現了主流的KV-Cache複用技術,並輔以全局Cache感知的流量調度策略。這一舉措,有效避免了Token KV的重複計算,從而大幅降低推理延遲,提高了推理吞吐。
此外,針對用户所關注的安全保障方面,平台基於百度自身長期的大模型安全技術積累,集成獨家內容安全算子,實現模型安全增強與企業級高可用保障。
同時,在大模型全生命週期數據安全與模型保護機制的基礎下,千帆平台上的模型均擁有使用安全的安全保障;基於在安全方面的專項優化,確保DeepSeek-R1&DeepSeek-V3模型的企業用户在使用過程也具有更高的安全性。
在如今的大模型競爭態勢下,AI大模型的技術“拉力賽”愈演愈烈,擁有高性能且更低成本的算力,始終是企業實現產品普及,保證領先地位的重要手段。
在致力於提供效價比服務的策略下,百度智能雲的商業化落地正在不斷加速,百度大模型的商業模式也有望進一步完善。
部分圖片來源於網絡,如有侵權請告知刪除