CPU,最強科普!_風聞
半导体行业观察-半导体行业观察官方账号-专注观察全球半导体最新资讯、技术前沿、发展趋势。52分钟前
我們都認為 CPU 是計算機的“大腦”,但這究竟意味着什麼呢?數十億個晶體管在計算機內部是如何運作的?在這個由四部分組成的系列文章中,我們將重點介紹計算機硬件設計,介紹計算機運行的來龍去脈。
本系列將涵蓋計算機架構、處理器電路設計、VLSI(超大規模集成)、芯片製造以及計算的未來趨勢。如果您一直對處理器內部工作原理的細節感興趣,請繼續關注 - 這是您入門所需瞭解的內容。
計算機架構基礎
CPU 實際上做什麼?
讓我們從高層次開始,瞭解一下處理器的功能以及構建模塊如何在功能設計中組合在一起。這包括處理器核心、內存層次結構、分支預測等。首先,我們需要對 CPU 的功能有一個基本定義。
最簡單的解釋是,CPU 遵循一組指令對一組輸入執行某些操作。例如,這可能是從內存中讀取一個值,將其添加到另一個值,最後將結果存儲回內存中的不同位置。它也可能是更復雜的操作,例如如果前一次計算的結果大於零,則將兩個數字相除。
當你想要運行一個程序(比如操作系統或遊戲)時,程序本身就是一系列供 CPU 執行的指令。這些指令從內存中加載,在簡單的處理器上,它們會逐一執行,直到程序完成。雖然軟件開發人員使用 C++ 或 Python 等高級語言編寫程序,但處理器無法理解這些語言。它只能理解 1 和 0,所以我們需要一種方法來以這種格式表示代碼。
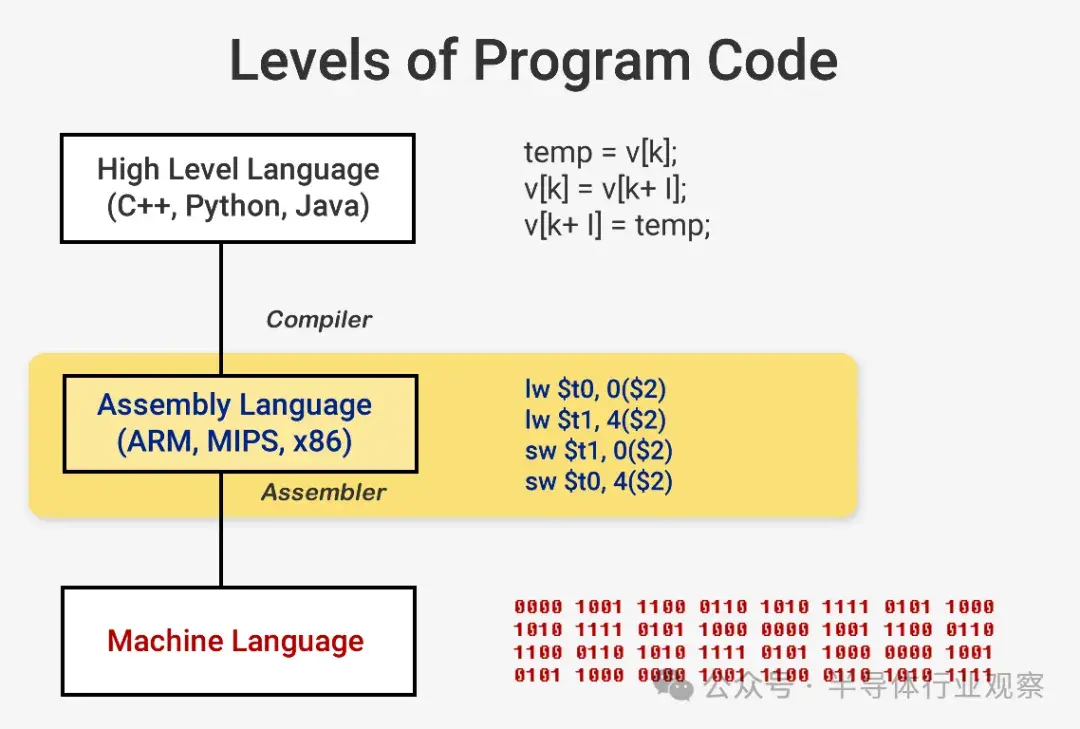
程序被編譯成一組低級指令,稱為彙編語言,是指令集架構 (ISA) 的一部分。這是 CPU 構建來理解和執行的指令集。一些最常見的 ISA 是 x86、MIPS、ARM、RISC-V 和 PowerPC。就像用 C++ 編寫函數的語法與用 Python 編寫執行相同操作的函數不同一樣,每個 ISA 都有自己的語法。
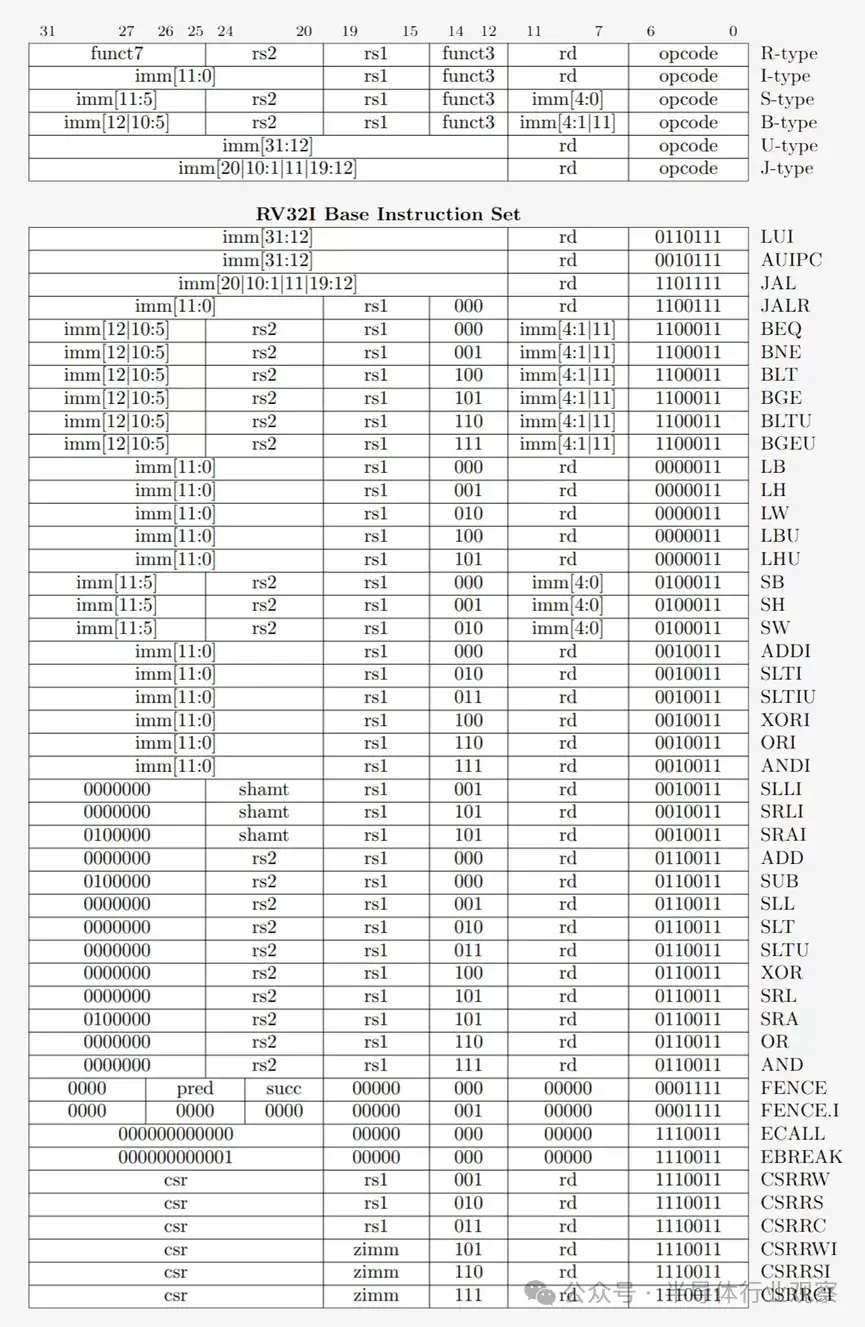
這些 ISA 可以分為兩大類:固定長度和可變長度。RISC-V ISA 使用固定長度指令,這意味着每條指令中一定數量的預定義位數決定了它是哪種類型的指令。這與使用可變長度指令的 x86 不同。在 x86 中,指令可以以不同的方式編碼,並且不同部分的位數也不同。由於這種複雜性,x86 CPU 中的指令解碼器通常是整個設計中最複雜的部分。
固定長度指令由於其規則結構而更容易解碼,但限制了 ISA 可以支持的指令總數。雖然 RISC-V 架構的常見版本有大約 100 條指令並且是開源的,但 x86 是專有的,沒有人真正知道存在多少條指令。人們通常認為有幾千條 x86 指令,但確切的數字並不公開。儘管 ISA 之間存在差異,但它們都具有基本相同的核心功能。
現在我們準備打開電腦並開始運行程序。指令的執行實際上有幾個基本部分,這些部分通過處理器的多個階段進行分解。
獲取、解碼、執行:CPU 執行週期
第一步是將指令從內存中提取到 CPU 中開始執行。第二步,對指令進行解碼,以便 CPU 能夠確定它是哪種類型的指令。指令有很多種類型,包括算術指令、分支指令和內存指令。一旦 CPU 知道它正在執行哪種類型的指令,指令的操作數就會從內存或 CPU 中的內部寄存器中收集。如果你想將數字 A 加到數字 B,那麼在你真正知道 A 和 B 的值之前,你無法進行加法。大多數現代處理器都是 64 位的,這意味着每個數據值的大小為 64 位。
CPU 獲得指令的操作數後,將進入執行階段,在此階段對輸入執行操作。這可以是將數字相加、對數字執行邏輯運算,或者只是傳遞數字而不進行修改。計算結果後,可能需要訪問內存來存儲結果,或者 CPU 可以只將值保存在其內部寄存器之一中。存儲結果後,CPU 將更新各個元素的狀態並繼續執行下一條指令。
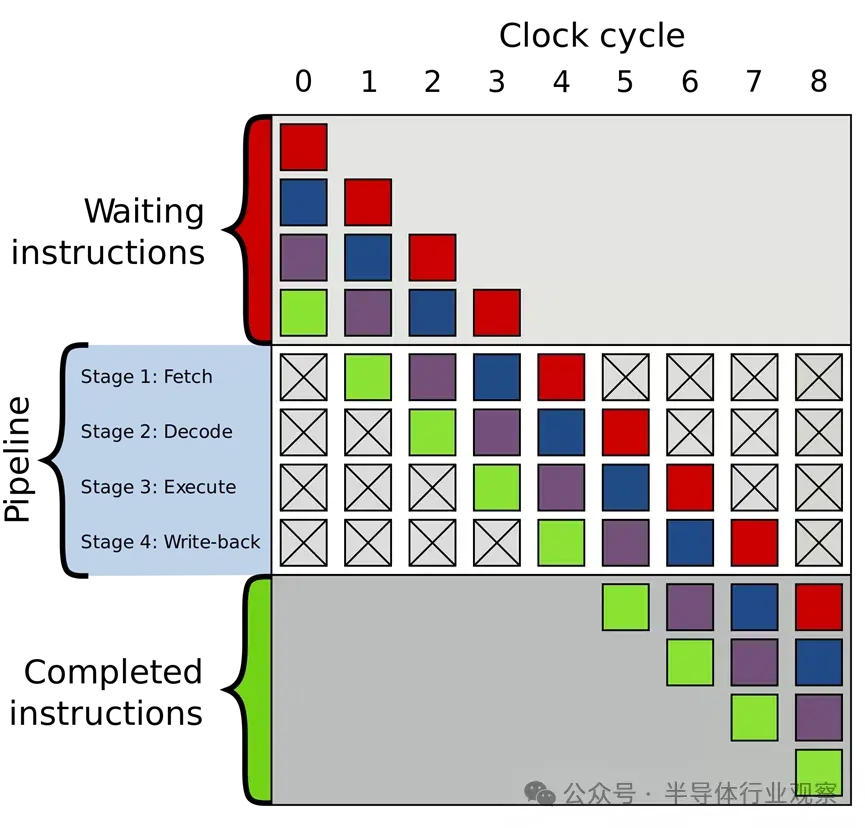
當然,這種描述是一種極大的簡化,大多數現代處理器會將這幾個階段分解為 20 個或更多個較小的階段,以提高效率。這意味着,儘管處理器每個週期都會啓動和完成幾條指令,但任何一條指令從開始到結束可能需要 20 個或更多個週期才能完成。這種模型通常被稱為管道,因為需要一段時間才能填滿管道並讓液體完全通過管道,但一旦填滿,就會得到恆定的輸出。
無序執行和超標量架構
指令的整個週期是一個非常嚴密編排的過程,但並非所有指令都可能同時完成。例如,加法非常快,而除法或從內存加載可能需要數百個週期。大多數現代處理器都是亂序執行的,而不是在一條慢速指令完成時讓整個處理器停滯。
這意味着它們將確定在給定時間內執行哪條指令最有利,並緩衝其他尚未準備好的指令。如果當前指令尚未準備好,處理器可能會在代碼中向前跳轉,查看是否有其他指令已準備好。
除了無序執行之外,典型的現代處理器還採用所謂的超標量架構。這意味着,在任何時候,處理器都在流水線的每個階段同時執行許多指令。它還可能等待數百條指令開始執行。為了同時執行許多指令,處理器內部將擁有每個流水線階段的多個副本。
如果處理器發現兩條指令已準備好執行,且它們之間沒有依賴關係,它就會同時執行這兩條指令,而不是等待它們分別完成。這種做法的一個常見實現稱為同步多線程 (SMT),也稱為超線程。英特爾和 AMD 處理器通常支持雙向 SMT,而 IBM 已開發出支持多達八路 SMT 的芯片。
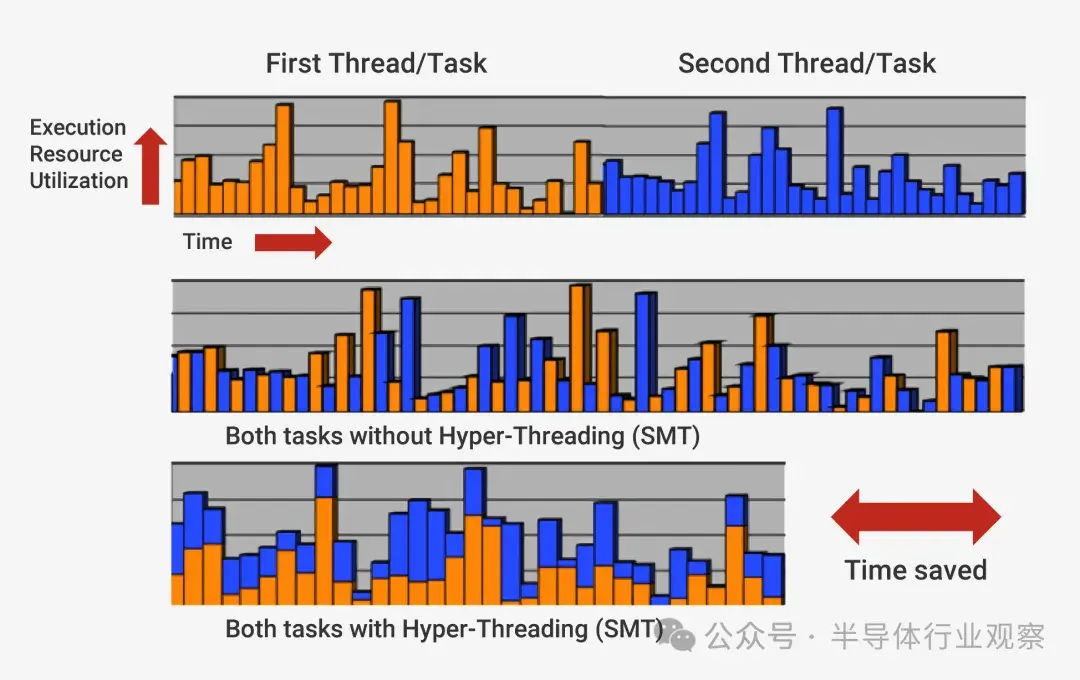
緩存:加速內存訪問
緩存的用途常常令人困惑,因為它們就像RAM或SSD一樣存儲數據。然而,緩存的不同之處在於它們的訪問延遲和速度。儘管 RAM 非常快,但對於 CPU 來説,它的速度太慢了。RAM 可能需要數百個週期才能響應數據,處理器將無事可做。如果數據不在 RAM 中,則可能需要數萬個週期才能訪問 SSD 上的數據。沒有緩存,我們的處理器將陷入停頓。
處理器通常有三級緩存,形成所謂的內存層次結構。L1 緩存最小且速度最快,L2 緩存居中,L3 緩存最大且速度最慢。層次結構中緩存上方是小型寄存器,用於在計算期間存儲單個數據值。這些寄存器是系統中速度最快的存儲設備,速度快了幾個數量級。當編譯器將高級程序轉換為彙編語言時,它會確定利用這些寄存器的最佳方式。
當 CPU 從內存請求數據時,它首先檢查該數據是否已存儲在 L1 緩存中。如果是,則只需幾個週期即可快速訪問數據。如果不存在,CPU 將檢查 L2,然後搜索 L3 緩存。緩存的實現方式通常對內核透明。內核只會在指定的內存地址請求一些數據,並且層次結構中擁有該數據的任何級別都會做出響應。隨着我們進入內存層次結構的後續階段,大小和延遲通常會增加幾個數量級。最後,如果 CPU 在任何緩存中都找不到它要查找的數據,那麼它才會轉到主內存 (RAM)。
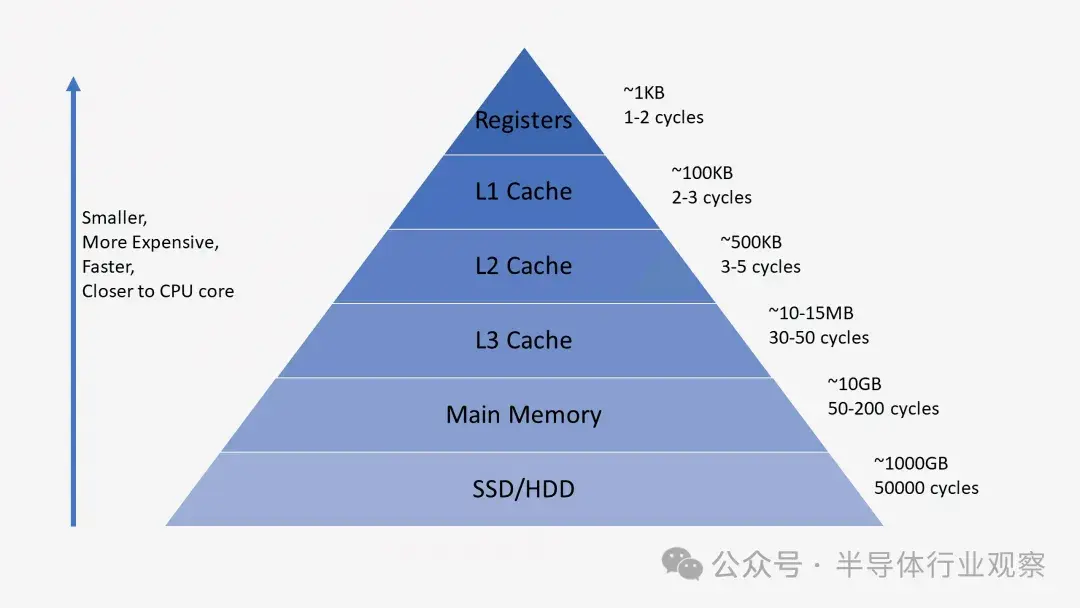
當處理器執行代碼時,它最常使用的指令和數據值將被緩存。這顯著加快了執行速度,因為處理器不必不斷進入主內存來獲取所需的數據。我們將在本系列的第二和第三部分中進一步討論這些內存系統的實際實現方式。
還值得注意的是,雖然三級緩存層次結構(L1,L2,L3)仍然是標準,但現代 CPU(例如 AMD 的Ryzen 3D V-Cache)已經開始加入額外的堆疊緩存層,這往往會在某些情況下提高性能。
分支預測和推測執行
除了緩存之外,現代處理器的另一個關鍵構建塊是準確的分支預測器。分支指令類似於處理器的“if”語句。如果條件為真,則執行一組指令,如果條件為假,則執行另一組指令。例如,您可能想要比較兩個數字,如果它們相等,則執行一個函數,如果它們不同,則執行另一個函數。這些分支指令非常常見,可以佔程序中所有指令的約 20%。
從表面上看,這些分支指令似乎不是什麼問題,但實際上,它們對於處理器來説非常具有挑戰性。由於在任何時候,CPU 都可能同時執行十到二十條指令,因此知道要執行哪些指令非常重要。可能需要 5 個週期來確定當前指令是否為分支,再需要 10 個週期來確定條件是否為真。在此期間,處理器可能已經開始執行數十條其他指令,甚至不知道這些指令是否是正確的執行指令。
為了解決這個問題,所有現代高性能處理器都採用了一種稱為推測的技術。這意味着處理器會跟蹤分支指令並預測是否會執行分支。如果預測正確,處理器已經開始執行後續指令,從而提高性能。如果預測不正確,處理器將停止執行,丟棄所有錯誤執行的指令,並從正確點重新啓動。
這些分支預測器是機器學習的早期形式之一,因為它們會隨着時間的推移適應分支行為。如果預測器做出太多錯誤猜測,它會進行調整以提高準確性。數十年來對分支預測技術的研究已使現代處理器的準確率超過 90%。
雖然推測允許處理器執行就緒指令而不是等待停滯的指令,從而顯著提高性能,但它也帶來了安全漏洞。現在臭名昭著的 Spectre 攻擊利用了分支預測中的推測執行錯誤。攻擊者可以使用特製代碼誘使處理器推測執行泄露敏感內存數據的指令。因此,推測的某些方面必須重新設計以防止數據泄露,從而導致性能略有下降。
在過去的幾十年裏,現代處理器的架構有了顯著的進步。創新和巧妙的設計帶來了更高的性能和更好的底層硬件利用率。然而,CPU 製造商對其處理器內部的具體技術高度保密,因此不可能確切知道內部發生了什麼。話雖如此,處理器工作的基本原理在所有設計中都保持一致。英特爾可能會添加他們的秘密武器來提高緩存命中率,AMD 可能會添加一個高級分支預測器,但它們都完成了同樣的任務。
CPU的設計過程
現在我們已經瞭解了處理器的工作原理,是時候深入瞭解它們的內部組件及其設計方式了。本文是我們關於處理器設計系列文章的第二部分。
晶體管:處理器的組成部分
您可能知道,處理器和大多數其他數字技術都是由晶體管組成的。最簡單的理解方法是將晶體管視為具有三個引腳的可控開關。當柵極打開時,電流可以流過晶體管;當柵極關閉時,電流無法流動。它類似於牆上的電燈開關,但尺寸更小、速度更快,並且由電控。
現代處理器使用兩種主要類型的晶體管:pMOS 和 nMOS。nMOS 晶體管允許電流在柵極充電或設置為高電平時流動,而 pMOS 晶體管允許電流在柵極放電或設置為低電平時流動。通過以互補的方式組合這兩種類型的晶體管,我們可以創建 CMOS 邏輯門。我們不會在本文中深入討論晶體管物理工作原理的複雜細節,但我們會在本系列的第 3 部分中介紹它。
邏輯門是一種簡單的設備,它接受輸入、執行操作並輸出結果。例如,AND 門僅在所有輸入都打開時才打開其輸出。反相器(或 NOT 門)僅在輸入關閉時才打開其輸出。通過組合這兩個門,我們可以創建一個 NAND(“非 AND”)門,除非所有輸入都打開,否則它會打開其輸出。其他邏輯門包括 OR、NOR、XOR 和 XNOR,每個門都具有不同的邏輯功能。
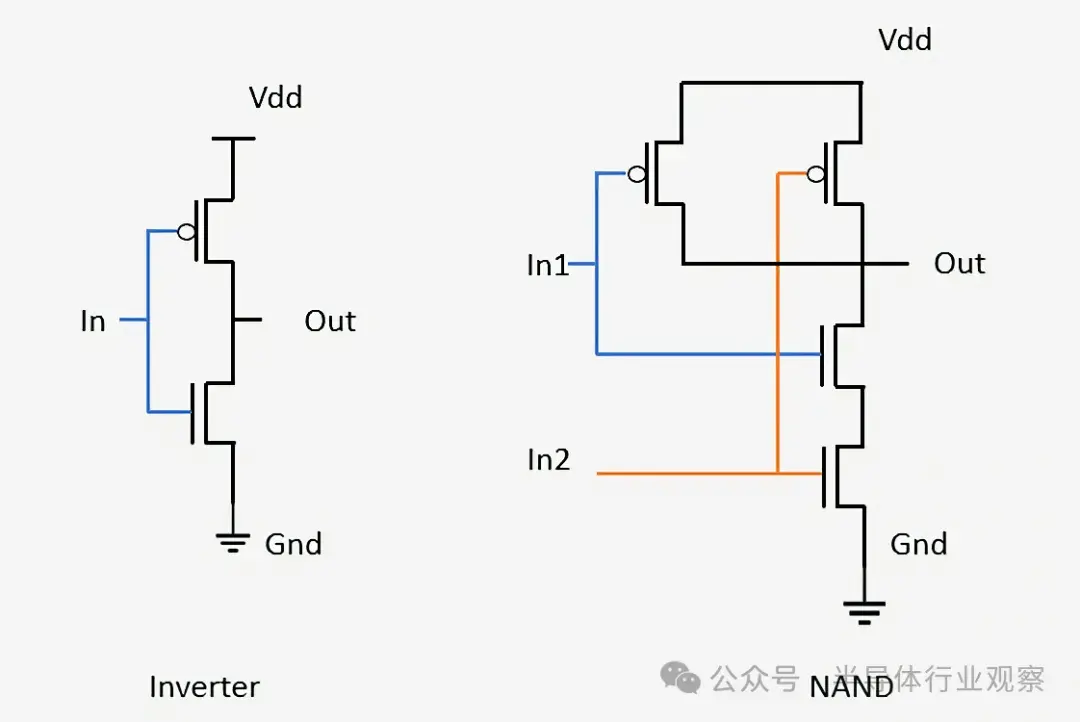
看看 NAND 門,我們發現它需要四個晶體管,只要至少一個輸入關閉,輸出就會保持開啓。同樣的原理也用於設計更先進的邏輯門和處理器內的其他電路。
從邏輯門到功能單元
邏輯門等簡單組件很難想象如何將它們轉變成一台功能齊全的計算機。這一設計過程包括將多個邏輯門組合起來,以創建執行特定功能的小型設備。然後,這些小型設備連接起來,形成更復雜的功能單元,最終形成一個功能齊全的處理器。集成這些單個組件的過程與構建現代芯片的方法相同——唯一的區別是,當今的芯片包含數十億個晶體管。
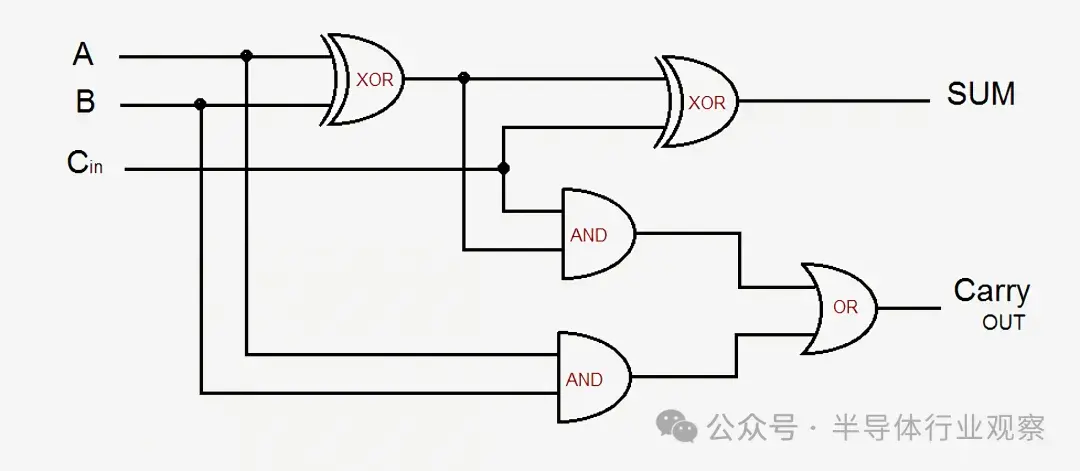
舉個簡單的例子,我們來看一個 1 位全加器。該電路接受三個輸入(A、B 和進位輸入)併產生兩個輸出(總和和進位輸出)。基本設計由五個邏輯門組成,多個加法器可以連接在一起以創建任意大小的加法器。現代設計通過優化邏輯和進位信號對此進行了改進,但基本原理保持不變。
如果 A 或 B 之一打開(但不能同時打開),或者如果 A 和 B 同時打開或同時關閉時有進位輸入信號,則 Sum 輸出打開。進位輸出信號稍微複雜一些:當 A 和 B 同時打開時,或者如果有進位輸入且 A 或 B 之一打開時,該信號有效。要連接多個 1 位加法器並形成更寬的加法器,我們只需將前一位的進位輸出連接到當前位的進位輸入。電路越複雜,邏輯就越混亂,但這是將兩個數字相加的最簡單方法。雖然現代處理器使用更先進的加法器,但基本概念保持不變。
將一系列這樣的門組合起來對輸入執行某些功能稱為組合邏輯。不過,這種邏輯並不是計算機中唯一存在的邏輯。如果我們無法存儲數據或跟蹤任何事物的狀態,它就沒什麼用。為此,我們需要具有存儲數據能力的順序邏輯。
存儲數據:SRAM 和 DRAM
順序邏輯是通過仔細連接反相器和其他邏輯門來構建的,這樣它們的輸出就會反饋到門的輸入。這些反饋迴路用於存儲一位數據,稱為靜態 RAM或 SRAM。它被稱為靜態 RAM,而不是 DRAM 中的動態 RAM,因為存儲的數據始終直接連接到正電壓或地。
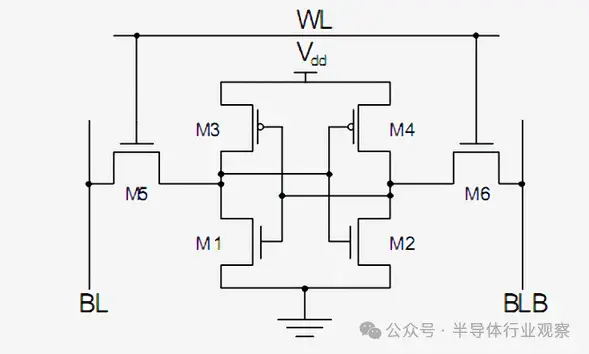
實現單個 SRAM 位的標準方法是使用如下所示的 6 個晶體管。頂部信號標記為 WL(字線),是地址,啓用後,存儲在此 1 位單元中的數據將發送到標記為 BL 的位線。BLB 輸出稱為位線條,只是位線的反轉值。您應該能夠識別這兩種類型的晶體管,並且 M3 和 M1 與 M4 和 M2 一起形成反相器。
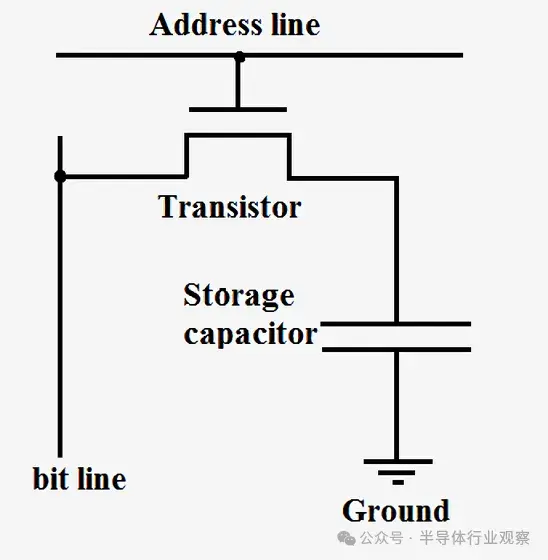
另一方面,動態 RAM 將數據存儲在微型電容器中,而不是使用邏輯門。之所以稱為動態 RAM,是因為電容器的電壓可以動態變化,因為它不連接到電源或地。單個晶體管用於訪問存儲在電容器中的數據。
由於 DRAM 每比特僅需一個晶體管,且具有高度可擴展的設計,因此可以密集封裝並以較低成本生產。然而,DRAM 的一個缺點是電容器中的電荷太小,需要不斷刷新。這就是為什麼當您關閉計算機時,電容器會耗盡,RAM 中的數據會丟失。
時鐘信號和頻率
現在我們知道了某些處理器組件的構造方式,我們需要弄清楚如何連接所有組件並使其同步。處理器中的所有關鍵組件都連接到時鐘信號,該信號以預定義的間隔(稱為頻率)在高電平和低電平之間交替。處理器內部的邏輯通常在時鐘從低電平變為高電平時切換值並執行計算。通過同步所有組件,我們可以確保數據在正確的時間到達,從而防止處理器出現故障。
您可能聽説過,增加處理器的時鐘速度(稱為超頻)可以提高性能。這種性能提升來自以比最初設計速度更快的速度切換處理器內部的晶體管和邏輯。由於每秒的週期數更多,因此可以完成更多工作,從而提高性能。但是,這隻能在一定程度上起作用。

增加處理器的供電電壓可以加快晶體管的切換速度,但只能在一定程度上加快。如果施加的電壓過高,處理器可能會過熱或燒壞。提高頻率或電壓總是會導致產生更多熱量和更高的功耗。這是因為處理器功率與頻率成正比,與電壓的平方成正比。要估算處理器的功耗,可以將每個晶體管視為一個小電容器,每當它改變狀態時都必須充電或放電。
電源管理和效率
供電是處理器設計中非常重要的一個方面,在某些情況下,芯片的一半物理引腳專門用於供電或接地。有些芯片在滿負荷時可能會消耗超過 150 安培的電流,而且必須小心管理所有這些電流。從這個角度來看,CPU 每單位面積產生的熱量比核反應堆還要多。
現代處理器中的時鐘信號約佔總功耗的 30-40%,因為它非常複雜,必須同時驅動多個組件。為了節省能源,大多數低功耗設計都會在不使用時關閉芯片的某些部分。這可以通過關閉時鐘(一種稱為“時鐘門控”的技術)或完全切斷電源(稱為“電源門控”)來實現。

説到效率,現代處理器的耗電量越來越大。為了解決這個問題,許多設計師除了優化單個芯片的性能外,還採用了芯片。芯片是分段式處理器,這意味着不是將每個組件整合到單個單片芯片中,而是將不同的部分製造成單獨的小芯片。例如,CPU 可能具有單獨的高效核心和電源核心,可根據工作負載打開或關閉。這種模塊化方法允許從最新制造方法中受益最多的組件縮小尺寸,從而提高製造效率並使更多組件能夠裝入同一處理器中。
處理器是如何設計的
設計芯片中的每個晶體管、時鐘信號和電源連接似乎非常繁瑣和複雜,事實確實如此。儘管英特爾、高通和 AMD 等公司擁有數千名工程師,但他們不可能手動設計芯片的每個方面。為了組裝如此規模的芯片,他們使用各種先進的工具來生成設計和原理圖。
這些工具通常會對組件的功能進行高級描述,並確定滿足這些要求的最佳硬件配置。人們越來越傾向於使用高級綜合 (HLS),它允許開發人員在代碼中指定他們想要的功能,然後讓計算機找出如何在硬件中最佳地實現它。這種抽象不僅可以加速開發,還可以實現更快的迭代和大規模優化。
最近,人工智能驅動的設計技術開始徹底改變芯片開發。谷歌、Nvidia 和 Synopsys 等公司已將機器學習模型集成到芯片佈局和佈局規劃中,大大減少了高效放置數十億個晶體管所需的時間。人工智能現在在優化電源效率、時序分析甚至自動錯誤檢測方面發揮着作用——幫助工程師在製造之前發現設計缺陷。
處理器設計中的驗證
就像您可以通過代碼定義計算機程序一樣,設計人員也可以通過代碼定義硬件。Verilog 和 VHDL 等語言允許硬件設計人員表達他們正在製作的任何電路的功能。這些設計會進行仿真和驗證,如果一切順利,它們就可以合成到組成電路的特定晶體管中。雖然驗證可能看起來不像設計新的緩存或核心那麼引人注目,但它卻更為重要。
驗證新設計通常比製造實際芯片本身花費更多的時間和金錢。公司在驗證上花費如此多的時間和金錢是因為一旦芯片投入生產,就無法修復它。對於軟件,你可以發佈補丁,但硬件在大多數情況下不是這樣工作的。
例如,英特爾在 20 世紀 90 年代末的奔騰芯片浮點除法單元中發現了一個漏洞,最終導致英特爾損失了相當於今天的 20 億美元。相反,過去十年中,我們看到了許多芯片安全漏洞案例,其中一些漏洞已通過製造商發佈的微代碼和固件更新得到修復。然而,這些修復的代價是性能或品牌聲譽的下降。
您可能很難理解一個芯片如何擁有數十億個晶體管以及它們都起什麼作用。當您將芯片分解成各個內部組件時,事情會變得容易一些。晶體管構成邏輯門,邏輯門組合成執行特定任務的功能單元,這些功能單元連接在一起形成我們在第 1 部分中討論的計算機架構。
大部分設計工作都是自動化的,而且隨着人工智能驅動的工具加速芯片開發的關鍵環節,現代處理器的複雜性不斷增加。不過,這應該會讓你對你購買的新 CPU 到底有多麼複雜和精密有新的認識。
芯片佈局和物理構建
在前面,我們介紹了計算機架構以及處理器的高層工作原理和單個芯片組件的設計和實現。現在,在第這部分中,我們將更進一步瞭解架構和原理圖設計如何轉化為物理芯片。
晶體管類型:nMOS 和 pMOS
正如我們之前所討論的,處理器和所有其他數字邏輯電路都是由晶體管構成的。晶體管是一種電子控制開關,可以通過向柵極施加或去除電壓來打開或關閉。我們之前介紹了兩種主要類型的晶體管:
nMOS 器件,當柵極打開時允許電流流動。
pMOS 器件,當柵極關閉時允許電流流動。
處理器的基本材料是硅,晶體管就嵌入其中。硅被歸類為半導體,因為它既不是完全導體,也不是完全絕緣體——它介於兩者之間。
摻雜:將硅轉變成有用的電路
為了通過添加晶體管將硅晶片變成功能電路,工程師使用了一種稱為摻雜的工藝。該工藝涉及將精心挑選的雜質引入硅基板以改變其導電性。
目標是改變電子的行為方式,以便我們能夠控制它們。就像有兩種類型的晶體管一樣,也有兩種相應的摻雜類型。
如果我們添加精確控制數量的電子供體元素,如砷、銻或磷,我們就可以創建一個n 型區域。由於應用這些元素的硅區域現在擁有過量的電子,因此它將帶負電。這就是 n 型名稱和nMOS中“n”的由來。
通過向硅中添加硼、銦或鎵等電子受體元素,我們可以創建一個帶正電的p 型區域。這就是 p 型和pMOS中的“p”的由來。將這些雜質添加到硅中的具體過程稱為離子注入和擴散,它們超出了本文的範圍。
現在我們可以控制硅某些區域的電導率,我們可以結合多個區域的特性來創建晶體管。
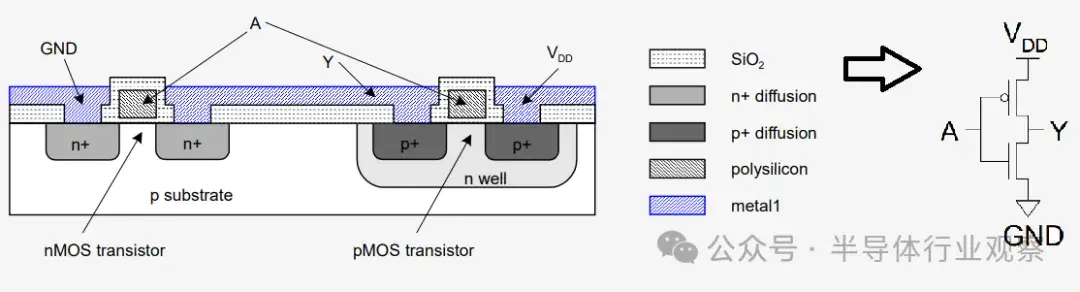
晶體管的作用
集成電路中使用的晶體管稱為 MOSFET(金屬氧化物半導體場效應晶體管),有四個連接。我們控制的電流流過源極和漏極。在 n 通道器件中,電流通常流入漏極並從源極流出,而在 p 通道器件中,電流通常流入源極並從漏極流出。
Gate 是用來打開和關閉晶體管的開關。最後,設備的 Body 與處理器無關,因此我們在此不討論它。
晶體管的工作原理以及不同區域如何相互作用的技術細節非常複雜,足以填滿一門研究生課程,因此我們將重點關注基礎知識。
一個有用的類比是河流上的吊橋。汽車,也就是晶體管中的電子,會從河的一邊流到另一邊,也就是晶體管的源極和漏極。以 nMOS 器件為例,當柵極未充電時,吊橋處於升起狀態,電子無法流過通道。當我們放下吊橋時,我們在河上形成了一條道路,汽車可以自由移動。晶體管中也會發生同樣的事情。給柵極充電會在源極和漏極之間形成一個通道,允許電流流動。
光刻:在硅上印刷電路圖案
為了精確控制硅片上不同 p 和 n 區域的位置,英特爾和台積電等製造商使用一種稱為光刻的工藝。這是一個極其複雜、多步驟的過程,各大公司花費數十億美元完善它,以製造更小、更快、更節能的晶體管。想象一下一台超精密打印機,用於將每個區域的圖案繪製到硅片上。
隨着晶體管尺寸的縮小,傳統的深紫外 (DUV) 光刻技術已達到極限。為了繼續縮小尺寸,業界採用了極紫外 (EUV) 光刻技術,該技術使用較短波長的光(約 13.5 納米)來創建更精細、更高精度的圖案。EUV 可實現更密集的晶體管封裝,並減少所需的掩蔽步驟,從而提高製造效率。
將晶體管裝入芯片的過程始於純硅晶片,在爐中加熱,在晶片頂部生長一層薄薄的二氧化硅。然後將感光光刻膠聚合物塗在二氧化硅上。通過將特定波長的光照射到光刻膠上(目前通常使用 EUV 來處理最先進的節點),我們可以剝離想要摻雜的區域的光刻膠。這是光刻步驟,類似於打印機將墨水塗在頁面的某些區域,只是規模要小得多。
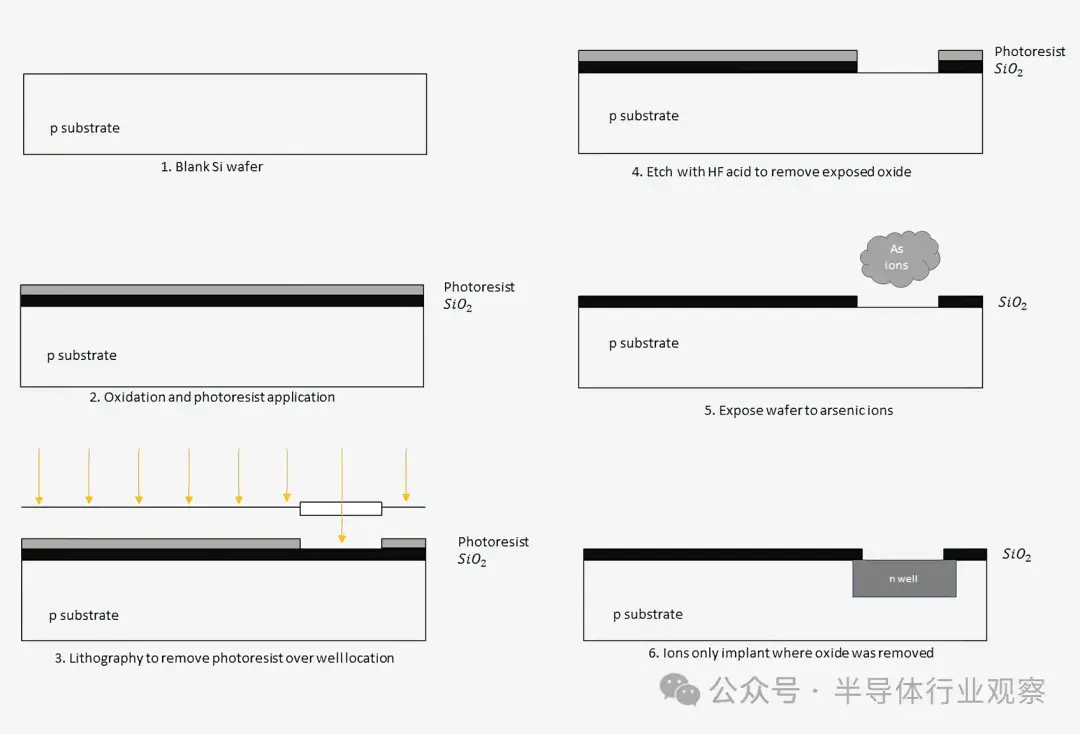
這種掩蔽、成像和摻雜的過程重複了數十次,以慢慢構建半導體中的每個特徵層。一旦完成基礎硅層,就會在上面製造金屬連接,以將不同的晶體管連接在一起。我們稍後會詳細介紹這些連接和金屬層。
製造過程
當然,芯片製造商不會只製造一個晶體管。當設計出新芯片時,他們會為製造過程的每個步驟生成掩模。這些掩模將包含芯片上數十億個晶體管的每個元件的位置。多個芯片組合在一起,並在單個芯片上一次性製造。
晶圓製造完成後,單個芯片就會被切割並封裝。根據芯片的大小,每個晶圓可能容納數百個或更多芯片。通常,生產的芯片越強大,芯片就越大,製造商從每個晶圓中得到的芯片就越少。
我們很容易認為我們應該製造出功能強大、擁有數百個內核的巨型芯片,但這是不可能的。目前,阻礙我們製造越來越大的芯片的最大因素是製造過程中的缺陷。現代芯片有數十億個晶體管,如果其中一個部件損壞,整個芯片可能需要丟棄。隨着處理器尺寸的增加,芯片出現故障的可能性也會增加。
工藝節點和大規模晶體管制造
公司從製造過程中獲得的實際良率是嚴格保密的,但 70% 到 90% 之間是一個不錯的估計。公司通常會過度設計芯片,增加額外的功能,因為他們知道有些部件不會起作用。例如,英特爾可能會設計一款 8 核芯片,但只將其作為 6 核芯片出售,因為他們估計有一兩個內核可能會損壞。缺陷數量異常少的芯片通常會被擱置一旁,以便在稱為裝箱的過程中以更高的價格出售。
與芯片製造相關的最大營銷術語之一是特徵尺寸或工藝節點。例如,台積電目前正在努力實現“2nm”工藝。然而,在過去十年左右的時間裏,工藝節點尺寸已經與晶體管的任何實際物理特徵(如柵極長度、金屬間距或柵極間距)失去了真正的關係。相反,它更像是一種節奏和營銷術語,用於指代日益先進的製造技術。
就在幾年前,7nm 和 10nm 還被認為是開創性技術。如今,Apple 已在其部分 SoC 中使用 3nm 工藝,而 Nvidia 在其最新 GPU 中使用 5nm 工藝。但這些數字實際上意味着什麼?傳統上,特徵尺寸是指晶體管漏極和源極之間的最小寬度。隨着技術的進步,晶體管不斷縮小,從而實現了更高的晶體管密度、更好的性能和更高的能效。
在研究這些工藝節點時,需要注意的是,不同的公司對其尺寸的定義不同。因此,一家制造商的 5nm 工藝可能生產出尺寸與另一家制造商的 7nm 工藝相似的晶體管。此外,同一製造工藝中並非所有晶體管的尺寸都相同。設計師可能會根據特定的性能要求故意製造一些比其他晶體管更大的晶體管。
自動化設計和優化
對於給定的設計過程,較小的晶體管切換速度更快,因為它們需要更少的時間來對柵極進行充電和放電。然而,由於它們的電流處理能力降低,它們只能驅動有限數量的輸出。如果特定電路需要驅動高功率負載(例如輸出引腳),其晶體管必須大得多。在某些情況下,輸出晶體管可能比內部邏輯晶體管大幾個數量級。

不過,設計和製造晶體管只是芯片的一半。我們需要根據原理圖構建導線來連接所有東西。這些連接是使用晶體管上方的金屬層實現的。想象一下一個多層高速公路立交橋,有上坡道、下坡道和相互交叉的不同道路。這正是芯片內部發生的事情,儘管規模要小得多。不同的工藝在晶體管上方會有不同數量的金屬互連層。
隨着晶體管越來越小,需要更多的金屬層才能路由所有信號。據報道,台積電的 5nm 工藝有 15 個金屬層。想象一下 15 層的垂直高速公路立交橋,你就能理解芯片內部的路由有多複雜。
下面的顯微鏡圖像顯示了由七層金屬層形成的晶格。每層都是平的,隨着層數的增加,層數會變大,以幫助降低電阻。每層之間都有稱為通孔的小金屬圓柱體,用於跳轉到更高的層。每層的方向通常與下面的層交替,以幫助減少不必要的電容。奇數金屬層可用於建立水平連接,而偶數層可用於建立垂直連接。

現代 CPU 設計的複雜性
當公司想要製造新芯片時,他們會從製造公司提供的標準單元開始設計。例如,英特爾或台積電將為設計師提供邏輯門或存儲單元等基本部件。然後,設計師可以將這些標準單元組合成他們想要製造的任何芯片。然後,他們會將芯片晶體管和金屬層的佈局發送給代工廠(將原始硅變成功能芯片的地方)。這些佈局被轉換成掩模,用於我們上面介紹的製造過程。接下來,我們將看看對於一個極其基本的芯片來説,這個設計過程可能是什麼樣的。

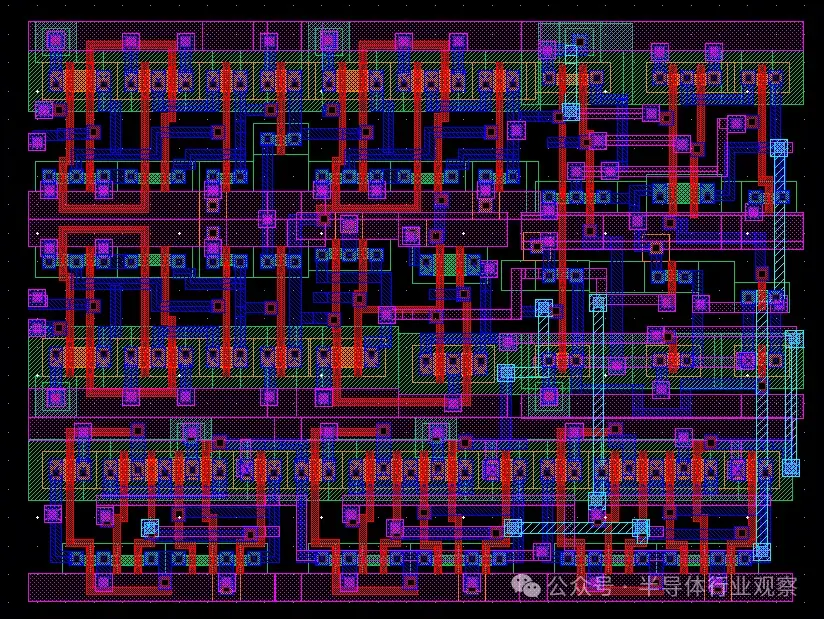
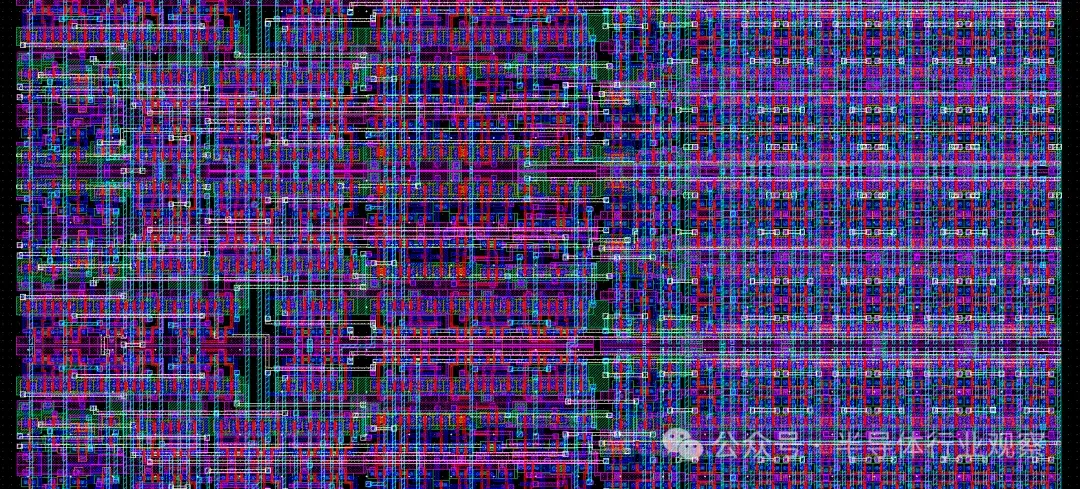
即使規模如此之小,其複雜性也是顯而易見的。現在,想象一下設計一個具有兆字節緩存、多個內核和超過 20 個流水線階段的 64 位 CPU 的挑戰。考慮到當今的高性能 CPU 包含多達 50 億到 100 億個晶體管和十幾層金屬層,毫不誇張地説,它們比這個基本設計複雜數百萬倍。
這應該能讓你更好地理解為什麼現代 CPU 如此昂貴,以及為什麼 AMD 和 Intel 的產品發佈間隔如此之長。新芯片的開發週期通常需要 3 到 5 年,從最初的設計到上市。一些進步,如人工智能驅動的芯片設計(如第 2 部分所述)和小芯片架構,可能會略微加快開發時間。然而,這仍然意味着當今最快的芯片是在幾年前設計的,我們要等到幾年後才能看到採用當今最先進製造技術的芯片。
至此,我們對處理器製造的深入研究就結束了。
計算機架構和設計的發展方向?
儘管每一代處理器都不斷改進和逐步升級,但很長時間以來,處理器都沒有出現任何改變行業的進步。從真空管到晶體管的轉變是革命性的。從單個元件到集成電路的轉變是另一次重大飛躍。然而,自那以後,還沒有出現過如此大規模的範式轉變。是的,晶體管變得更小,芯片變得更快,性能呈指數級增長,但我們開始看到收益遞減。
於是,行業開始探索不同的解決方案。
由於各公司不會公開分享其研究或當前技術的細節,因此很難確定計算機 CPU 內部究竟是什麼。但是,我們可以研究正在進行的研究和行業趨勢,以瞭解事態的發展方向。
摩爾定律 125 年來的發展
處理器行業最著名的概念之一是摩爾定律,該定律指出芯片上的晶體管數量大約每 18 個月翻一番。這一定律長期有效,但現在已經明顯放緩——可以説已經走到了盡頭。
晶體管已經變得如此之小,以至於我們正在接近物理學的基本極限。對於傳統的硅基 CPU,摩爾定律實際上已經結束。晶體管的縮小速度已大大降低,導致英特爾、AMD 和台積電等芯片製造商將重點轉向先進封裝、芯片架構和 3D 堆疊。
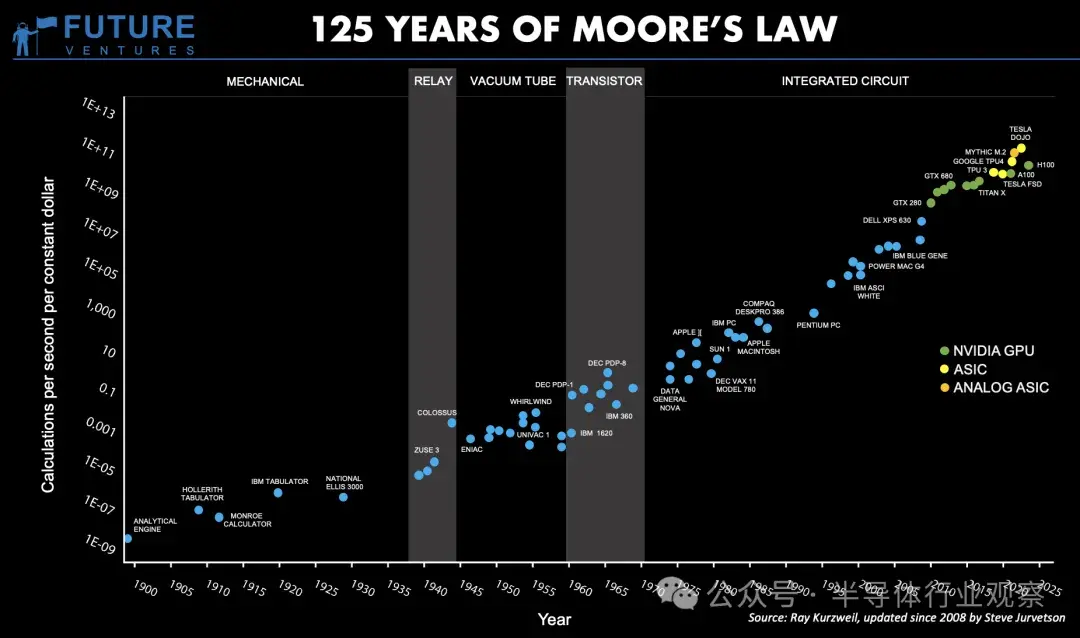
這種細分的一個直接結果是,公司開始增加核心數量而不是頻率來提高性能。這就是我們看到八核處理器而不是 10GHz 雙核芯片成為主流的原因。除了增加更多核心之外,幾乎沒有多少增長空間。
量子計算
另一方面,量子計算是一個未來具有巨大發展空間的領域。我們不會假裝自己是這方面的專家,而且由於這項技術仍在開發中,所以真正的“專家”並不多。為了消除任何誤解,量子計算並不是能在現實生活中提供 1,000fps 的渲染速度之類的東西。目前,量子計算機的主要優勢在於它允許使用以前無法用傳統計算機處理的更先進的算法。

這項技術距離主流還有十年或二十年的時間(取決於你問誰),那麼我們現在在實際處理器中開始看到哪些趨勢呢?有幾十個活躍的研究領域,但我將談及一些我認為最具影響力的領域。
高性能計算趨勢和人工智能
異構計算是影響我們的一個日益增長的趨勢。這是一種在單個系統中包含多個不同計算元素的方法。我們大多數人都以系統中專用 GPU 的形式從中受益。
CPU 可高度定製,能夠以合理的速度執行各種計算。另一方面,GPU 專門用於執行矩陣乘法等圖形計算。它在這方面非常擅長,並且比 CPU 在這些類型的指令上快幾個數量級。通過將某些圖形計算從 CPU 轉移到 GPU,我們可以加快工作量。任何程序員都可以通過調整算法來輕鬆優化軟件,但優化硬件要困難得多。
然而,GPU 並不是加速器變得普遍的唯一領域。隨着 AI 和機器學習工作負載的增加,我們看到定製 AI 處理器的數量激增。例如,Google 的張量處理單元(TPU) 和 Nvidia 的張量核心是專為深度學習計算而設計的。同樣,AMD 的Instinct MI300和英特爾的Gaudi AI加速器正在塑造 AI 格局,為訓練和推理工作負載提供更專業的性能。
除了人工智能之外,專用加速器現在已成為移動和雲計算不可或缺的一部分。大多數智能手機都配備了數十個硬件加速器,旨在加速非常具體的任務。這種計算方式被稱為“加速器之海”,例如加密處理器、圖像處理器、機器學習加速器、視頻編碼器/解碼器、生物識別處理器等。
隨着工作負載變得越來越專業化,硬件設計師正在將更多的加速器整合到他們的芯片中。AWS 等雲提供商現在為開發人員提供 FPGA 實例,以加速雲端的工作負載。雖然 CPU 和 GPU 等傳統計算元素具有固定的內部架構,但 FPGA(現場可編程門陣列)卻非常靈活 - 它幾乎就像可編程硬件,可以配置為滿足特定的計算需求。
例如,如果您想加速圖像識別,您可以在硬件中實現這些算法。如果您想模擬新的硬件設計,您可以在實際構建之前在 FPGA 上對其進行測試。雖然 FPGA 比 GPU 提供更高的性能和能效,但它們的性能仍然不如定製的 ASIC(專用集成電路),這些 ASIC 由 Google、Tesla(Dojo)和 Cerebras 等公司開發,用於優化深度學習和 AI 處理。
