馬斯克剛發Grok-3,DeepSeek就貼臉開大!_風聞
大眼联盟-27分钟前
來源:網羅燈下黑
太刺激了,2025 年的 AI 大戰已經開始貼身肉搏,刺刀見紅了!
馬斯克今天不是發佈號稱地球上最聰明 AI 的 Grok-3 嗎,他這邊早早就開始預告,結果 OpenAI 掌門人奧特曼在發佈會之前,就在 X 上透露即將開源 GPT o3 系列模型,還暗示 GPT-4.5 已讓測試者摸到 AGI 門檻。
玩截胡是吧?這還不算完。
馬斯克這邊剛嘚瑟完 xAI 的 Grok-3,發佈會結束還沒到 1 個小時呢,這邊 DeepSeek 直接甩出核彈級論文,發佈顛覆行業的原生稀疏注意力技術 NSA,創始人梁文鋒親自掛帥署名!

這不是明擺着把馬斯克標成汪峯來打了嗎,就是不讓上頭條!
這篇論文到底説了啥呢,我自然讓 DeepSeek 來解讀了一下:

其實這個解讀已經比較通俗易懂了,不過還是有點硬,想讓它再解釋一下,它就又罷工了。
好吧,我結合着它的解釋和自己的理解,來給大家再簡單過一遍:
1.
這篇論文的核心貢獻叫做 ‘原生稀疏注意力’(Native Sparse Attention,NSA)。要理解它為什麼重要,得先知道當前大模型的致命傷:
1. 長文本 = 算力黑洞
現在所有大模型處理長文本,都在用 ‘全注意力機制’,比如讓大模型讀整本《三體》,它每個字都要看,帶來的後果就是速度慢還燒顯卡,64k 字能吃掉 80% 算力。
但實際上,我們人類並不這麼讀書:我們看長文章時會自動跳讀、抓重點、記框架,就比如公眾號文章會標粗標紅,也是為了幫助讀者抓重點。
而這個時候大模型這傻小子還在死磕每個標點符號。
2. 現有方案的妥協
目前市面上的大模型解決方案其實都是在打補丁:
滑動窗口法:只看當前段落附近的文字(類似你讀書時用手指指着看) → 容易漏掉全局信息;
隨機抽樣法:隨便抽幾句話分析 → 可能錯過關鍵線索;
事後壓縮法:先完整讀一遍再刪減 → 本質上還是浪費了第一遍的算力。
而 DeepSeek 的 NSA 技術,試圖從底層重建這個過程。
2.
它要教會大模型像人類一樣閲讀,把 ‘選擇重點’ 的能力直接植入 AI 的基因。
第一步:分塊壓縮
把長文本切成 512 字的小塊,比如把一本小説按章節拆分。對每個塊做 ‘縮略圖提取’:用 AI 自動生成該塊的語義摘要,類似讀書時先看目錄。
第二步:動態篩選
讓 AI 自主決定哪些塊需要細讀,比如選中 16 個關鍵章節。
篩選標準通過訓練自動優化,相當於教 AI 什麼信息值得關注。
第三步:局部深挖
逐字分析:對選中的關鍵塊啓用全注意力機制;
防止斷章取義:同時用滑動窗口覆蓋周邊內容;
這相當於給 AI 裝了個智能探照燈:既能掃描全局,又能聚焦重點。
3.
這可不是簡單的優化,而是範式轉移,直接拿論文數據來説話吧:
1. 效率革命
訓練速度提升 9 倍:在 64k 文本長度下,訓練耗時從全注意力機制的 100% 降到 11%。
推理速度提升 11.6 倍:處理同長度文本,所需計算資源不到原來的十分之一。
2. 能力躍遷
長文本理解質變:在 ‘大海撈針’ 測試中(從 6.4 萬字裏找特定事實),準確率 100% 碾壓傳統方案,要知道全注意力機制才 35%啊,太變態了!
最狠的是數學推理暴打傳統模型!在 AIME 奧數題上,NSA 加持的模型正確率飆到 14.6%,把全注意力模型 9.2% 按地上摩擦 —— 説明這技術真能讓 AI 更聰明,不是單純省算力。
3. 成本重構
同等算力下可處理 10 倍長的文本,或用 1/10 的算力達到相同效果。這直接動搖了大模型必須靠堆顯卡的行業邏輯:以前訓練長文本得燒機房,現在用 NSA 能省下幾卡車顯卡錢!
4.
為什麼説這事比 Grok-3 更重要?
馬斯克的 Grok-3 宣傳的是:首個突破 1400 分的模型 、 首個十萬卡集羣訓練出來的模型 ,大概率還是在走 ‘擴大參數規模 + 增加數據量’ 這種大力出奇跡的老路。而 DeepSeek 的論文指向一個更本質的問題:
當前大模型的架構,可能從根子上就錯了。我們一直用 ‘全注意力機制’ 是因為它簡單粗暴有效,但NSA 技術的意義在於:
證明稀疏注意力可以端到端訓練,傳統方案只能訓練後裁剪;
首次實現算法與硬件的深度協同,直接針對 GPU 內存特性優化;
從算法設計到硬件適配全鏈路打通,論文裏連怎麼在顯卡上 ‘卡 BUG’ 省內存都寫得明明白白,擺明了要落地商用。
5.
如果 NSA 技術普及,將徹底打開長文本場景的商業化大門,需要處理百萬字級文本的場景,終於有了可行的 AI 方案。
我們可能會在 1-2 年內看到:
文檔助手:上傳 1000 頁的行業報告,AI 能在 10 秒內提煉出核心趨勢和風險點;
教育革命:學生用 AI 快速解析百萬字文獻將不再是夢;
代碼開發:AI 真正理解整個代碼庫的架構,而不只是片段補全;
內容審核:平台能即時分析超長視頻的完整上下文,而不只是截取片段。
更重要的是,中國團隊這次搶到了算法創新的先手 —— 在注意力機制這個最核心的領域,我們第一次提出了被國際學界認可的基礎架構改進。
(沒想到,第一次看論文看得這麼心潮澎湃的)
X 上的網友已經開啓嘲諷模式了:

結語
過去幾年,大模型的競爭像是 軍備競賽:比參數、比數據量、比顯卡數量。但 DeepSeek 的論文揭示了一個趨勢:下一階段的勝負手,在於對基礎組件的重新發明。
DeepSeek 這條路子走對了。
就像燃油車時代比的是發動機排量,電動車時代卻開始比拼電池管理算法 —— 當行業意識到算力不是唯一壁壘時,真正的創新才剛剛開始。
至於馬斯克的 Grok-3?它或許很強大,但至少在今天,這場對話的主動權,握在了重新定義遊戲規則的人手裏。
馬斯克用20萬張卡練出的Grok 3能超越DeepSeek嗎
“2月18日,馬斯克所言“地球上最聰明的人工智能”終於亮相,其旗下人工智能公司xAI正式發佈其新一代的大語言模型Grok 3,馬斯克本人也在社交平台X上同步開啓直播演示。
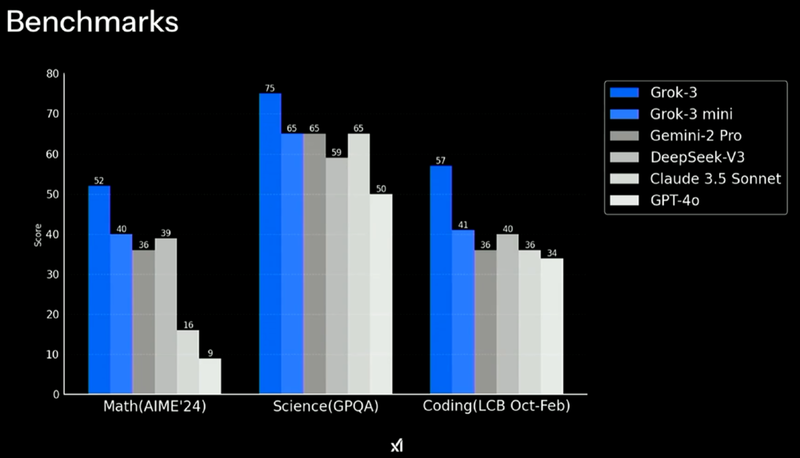
據直播介紹,Grok 3已超越目前市場上所有已發佈的人工智能。在官方公佈的測試數據中,其在數學推理、科學邏輯推理以及代碼寫作等方面表現均優於ChatGPT-4o、DeepSeek-V3等競品。
。
Grok大模型是馬斯克旗下的xAI公司推出的人工智能模型,其命名源自美國科幻作家羅伯特·海因萊因的小説《異鄉異客》(Stranger in a Strange Land)。該系列第一款大模型Grok 1於2023年11月面世,2024年該模型參數量擴展至3140億,遠超GPT-3.5的1750億。2024年8月,Grok 2大模型發佈,在Grok 1基礎上全面升級,並在X平台上面向用户免費使用。而此次直播推出的Grok 3,據工程師表示,其所涉及的訓練是Grok 2的10倍,且Grok 3已經在xAI內部運行了2周。
據悉,Grok 3訓練所用GPU總量為20萬個,在第一階段通過10萬個GPU進行訓練,耗時144天,而第二階段的92天中,所用GPU數量拓展到了20萬個。此前據報道,印度已啓動一個有超過1.8萬個GPU的公共計算設施,將對初創公司、研究人員和開發者開放,以促進其國內人工智能發展以及本國大語言模型的訓練。相較之下,xAI的Grok 3訓練所用GPU總量已遠超印度國家級項目GPU總量10倍不止。龐大的算力規模成為Grok 3加速問世的最大助力,也讓xAI在日益激烈的市場競爭底氣十足。
在直播活動中,xAI的工程師展示了Grok 3的使用,如現場生成一段太空發射的3D動畫的代碼、製作一款融合“寶石迷陣”和“俄羅斯方塊”的遊戲,Grok 3均表現良好,這也證明了該模型對於複雜知識具有良好的理解。馬斯克表示,Grok 3的功能比Grok 2強大一個數量級。
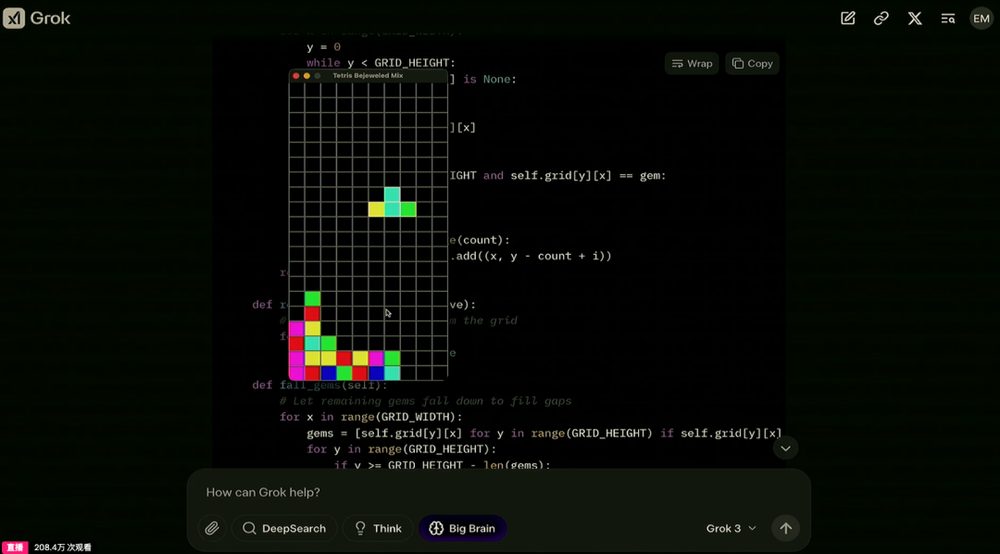
面對Grok 3的極佳表現,有知名博主Alexandr Wang表示,Grok 3是世界上新的最佳模型,其在聊天機器人競技場中排名第一,且遙遙領先。Amjad Masad也表示Grok 3似乎是最先進的尖端模型,他認為考慮xAI的處境,該模型的發佈無疑是巨大成就。知名播客主持人Lex Fridman同樣對該模型印象深刻,表達了對該模型的稱讚。
而Grok 3所帶來的騷動,實際上比該模型的正式面世要來得早。
此前,DeepSeek在世界範圍內掀起熱潮。由於DeepSeek-R1模型的優秀表現,以及其代表的低成本訓練路線,人們一度開始討論全球AI話語權的歸屬問題。儘管人工智能行業尚處於羣雄逐鹿的階段,但是DeepSeek-R1模型無疑為這個世界帶來巨大沖擊。
繼DeepSeek爆火之後,2月13日,OpenAI首席執行官奧特曼發佈博文,宣佈準備推出GPT-4.5和GPT-5,並公佈路線圖。
同樣在2月13日,馬斯克在迪拜世界政府峯會上表示xAI將推出新一代模型Grok 3,並盛讚其“強到讓人感到害怕”。而這也引發了人們對Grok 3的猜測,以至於討論AI話語權可能再度扯向西方。
至此,一場有關人工智能模型的“三國殺”已見雛形。
作為xAI的重要市場競爭對手,OpenAI對Grok 3的反應也引起人們的注意。在今日馬斯克的直播活動開始之前,奧特曼在社交平台X發佈消息,稱GPT-4.5已進入測試階段,並稱其體驗“接近通用人工智能(AGI)”,而這一行為被外界視為對Grok 3的緊急“狙擊”。
相比於明星產品DeepSeek-R1,“推理+測試時間計算”中,在數學推理、科學邏輯推理和編程三個方面,Grok 3 Reasoning Beta版本綜合得分分別為93、85、79,均高於DeepSeek-R1的80、71和65。最新AIME 2025性能測試中,Grok 3 Reasoning Beta版本有93分,高於DeepSeek-R1。前特斯拉人工智能總監、OpenAI創始團隊成員Andrej Karpathy通過提前體驗指出,Grok 3模型確實可以做到DeepSeek-R1做不到的事。而單純從測試數據看,Grok 3確實做到了比DeepSeek-R1略好。
儘管Grok 3在測試中成績優秀,但是仍有分析表現,在 “推理+測試時間計算” 這一測試中,相比於o3-mini(high)或DeepSeek-R1,Grok 3的數學性能並沒有顯著優勢。馬斯克表示,Grok 3仍處於早期訓練階段,未來將持續優化。
據瞭解,自今日起,X平台Premium Plus訂閲用户將率先獲得Grok 3訪問權限。此外,xAI還推出了名為Super Grok的獨立訂閲服務,但尚未公開定價。馬斯克還表示,目前xAI的工程師團隊正在訓練Grok 3的迷你版本,並指出“迷你版的訓練時間更長,有時表現略好於Grok 3推理模型。”
自Grok 3開始,馬斯克“再無AI比Grok更優秀”的預言能否成真?以目前AI的更新速度而言,當真難以定論。但就該模型的表現來看,在人工智能的牌局上,馬斯克確實甩出了有分量的“大牌”。
來源:網羅燈下黑/虎嗅網