針對馬斯克的grok3,DS老梁又扔出算法王炸!_風聞
观察者网用户_2244-除了胜利,我们已经无路可走。43分钟前
在馬斯克的 Grok 3 發佈會反覆與 DeepSeek 進行比較之後,DeepSeek 不語,只是又在 X 上公佈了一項新的技術成果。
 圖丨相關推文(來源:X)
圖丨相關推文(來源:X)
由 DeepSeek 聯合創始人梁文鋒親自掛名的研究團隊,在 arXiv 上發表了一篇題為“Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention”的論文,提出了一種全新的注意力機制架構 NSA(Native Sparse Attention,原生稀疏注意力)。
熟悉 DeepSeek-R1 的用户都知道,這款模型雖然在許多方面表現出色,但比較遺憾的一點在於,其輸入上下文能力方面相對不足。而這次發佈的 NSA 架構就主要致力於解決當前大模型長文本處理中的關鍵瓶頸問題。
在傳統注意力機制中,當序列長度達到 64K 時,注意力計算可能佔用總延遲的 70-80%,這種計算開銷已經成為制約模型性能的重要因素。
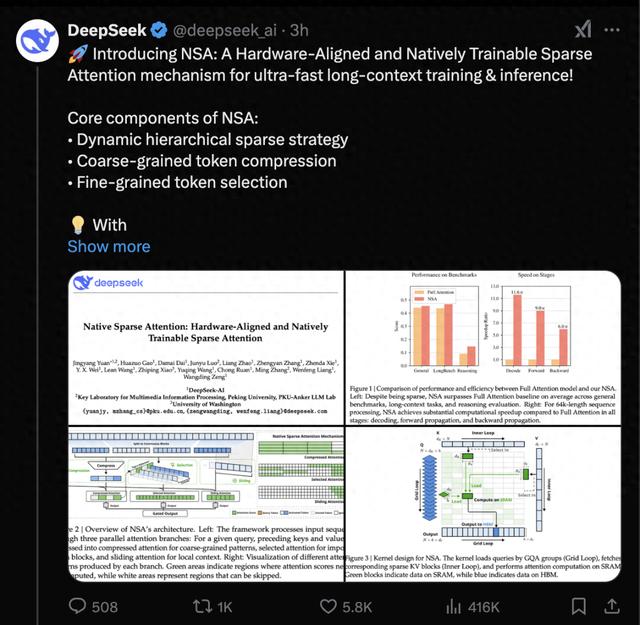
**NSA 的核心技術創新主要體現在兩個方面。首先是其獨特的分層稀疏注意力設計。**該架構將輸入序列按時間維度劃分為連續的 block,並通過三條並行的注意力分支進行處理:壓縮注意力(Compressed Attention)通過可學習的 MLP 將每個 block 壓縮成單一表示,用於捕獲粗粒度的全局信息;選擇性注意力(Selected Attention)則保留最重要的 fine-grained token 信息;滑動窗口注意力(Sliding Attention)用於處理近期的局部上下文。這種分層設計使得模型能夠在保持表達能力的同時大幅降低計算複雜度。
 圖丨 NSA 架構概覽(來源:arXiv)
圖丨 NSA 架構概覽(來源:arXiv)
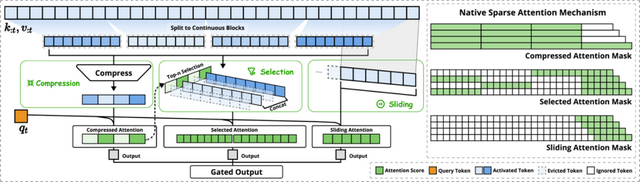
**第二個創新點在於其硬件友好的實現優化。**研究團隊基於 Triton 開發了專門的 kernel,通過“Group-Centric Data Loading”策略,將同一 GQA(Grouped-Query Attention)組內的所有 query head 同時加載到 SRAM 中處理。這種設計不僅最大化了 Tensor Core 的利用率,還通過優化的循環調度消除了冗餘的 KV 數據傳輸。特別是在處理 block 化的稀疏注意力時,NSA 採用了連續的內存訪問模式,這與現代 GPU 架構高度契合。
值得一提的是,NSA 突破性地實現了端到端的可訓練稀疏注意力。與現有方法往往在推理階段才引入稀疏化不同,NSA 從預訓練階段就開始使用稀疏注意力機制。這種“原生”設計使得注意力模塊能夠與模型其他組件協同優化,形成更優的稀疏模式。為了支持穩定訓練,研究團隊還為三條注意力分支設計了獨立的 key 和 value 參數,這種設計雖然帶來了輕微的參數開銷,但有效防止了局部模式對其他分支學習的干擾。
 圖丨 NSA 的內核設計(來源:arXiv)
圖丨 NSA 的內核設計(來源:arXiv)
在具體實現上,NSA 在處理 64K 長度序列時,每個解碼步驟只需要加載 ⌊(s-l)/d⌋ 個壓縮 token、nl’ 個選擇性 token 和 w 個近鄰 token,其中 s 是緩存序列長度,l 是 block 長度,d 是滑動步長,n 是選擇的 block 數量,w 是滑動窗口大小。這種設計使得內存訪問量隨序列長度的增長維持在一個較低水平,從而實現了接近理論極限的加速效果。
研究團隊對 NSA 進行了全方位的性能驗證。實驗採用了一個基於 GQA 和 MoE(Mixture-of-Experts)的 27B 參數 backbone,包含 30 層網絡結構,隱藏維度為 2560。為確保實驗的可比性,研究團隊採用了與全量注意力模型完全相同的訓練流程,包括在 270B token 的 8K 長度文本上進行預訓練,隨後使用 YaRN 方法在 32K 長度文本上進行延續訓練和監督微調。
在通用能力評測中,NSA 展現出了超出預期的表現。在涵蓋知識、推理和編程能力的九項基準測試中,包括 MMLU、MMLU-PRO、CMMLU、BBH、GSM8K、MATH、DROP、MBPP 和 HumanEval,NSA 在七項上超越了全量注意力基線。尤其值得關注的是在推理相關任務上的顯著提升,如在 DROP 任務上提升了 4.2 個百分點,在 GSM8K 上提升了 3.4 個百分點。這一結果表明,稀疏注意力的預訓練不僅沒有損害模型能力,反而通過過濾無關注意力路徑增強了模型的推理性能。
 圖丨全注意力基線和 NSA 在一般基準測試上的預訓練性能比較(來源:arXiv)
圖丨全注意力基線和 NSA 在一般基準測試上的預訓練性能比較(來源:arXiv)
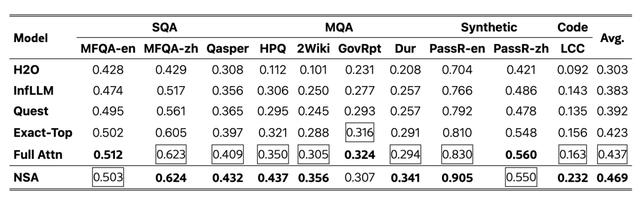
在長文本處理能力的專項測試上,NSA 的優勢更為突出。在 64K 長度的“大海撈針”測試中,NSA 實現了全位置的完美檢索準確率。在 LongBench 評測集上,NSA 的平均得分達到 0.469,顯著超過了包括全量注意力在內的所有基線方法。具體來看,在多跳問答任務 HPQ 和 2Wiki 上分別提升了 8.7 和 5.1 個百分點,在代碼理解任務 LCC 上提升了 6.9 個百分點,在段落檢索任務 PassR-en 上提升了 7.5 個百分點。
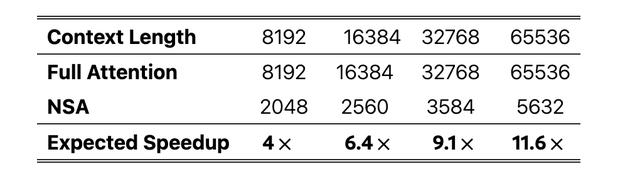 圖丨解碼期間每次注意力操作的內存訪問量(來源:arXiv)
圖丨解碼期間每次注意力操作的內存訪問量(來源:arXiv)
在推理能力的深入測試中,研究團隊還探索了 NSA 在進階數學推理方面的表現。通過從 DeepSeek-R1 模型蒸餾數學推理能力,在 10B 個 32K 長度的數學推理軌跡上進行監督微調後,NSA 在美國邀請數學競賽基準測試上取得了顯著進展。在 8K 上下文限制下,NSA 比基線模型提升了 7.5 個百分點;在擴展到 16K 上下文時,仍保持了 5.4 個百分點的優勢。這一結果驗證了 NSA 在保持長程邏輯依賴方面的獨特優勢。
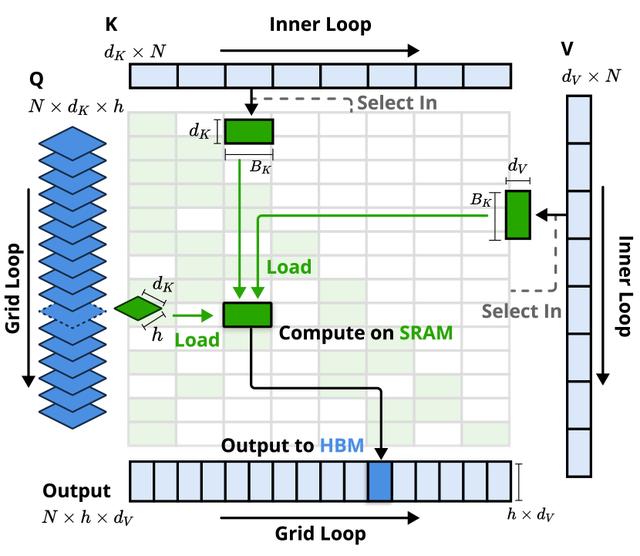
在計算效率方面,NSA 的表現同樣令人矚目。在 64K 序列長度的場景下,在解碼、前向傳播和反向傳播三個階段分別實現了 11.6 倍、9.0 倍和 6.0 倍的加速比。更重要的是,這種加速優勢會隨着序列長度的增加而進一步擴大,這對於未來更長上下文的處理提供了可行方案。
儘管 NSA 取得了顯著的成果,但也還存在幾個值得深入探索的方向。比如,稀疏注意力模式的學習過程還有優化空間。目前的方案雖然實現了端到端訓練,但如何讓模型學習到更優的稀疏模式,特別是在更大規模模型上的表現,還需要進一步研究。此外,NSA 提供的 Triton 實現為業界提供了很好的參考,但在實際部署中,還需要考慮不同硬件平台的適配、推理服務的穩定性等問題。
不過,NSA 的表現已經證明:通過精心的算法設計和硬件協同優化,我們可以在保持模型性能的同時顯著提升計算效率,其出現無疑又為整個開源 AI 社區提供了寶貴的參考。
參考資料:
1.https://arxiv.org/abs/2502.11089