下意識去中華文明因子的韓國,沒未來!_風聞
策辩-策辩官方账号-国际热点分析,探究背后套路。8分钟前
出處 | 策辯
人得知道自己從哪裏來,國家亦如是!
2月16日,韓國統計廳發佈韓國2024年人口數據。韓國很高興,2024年出生人口為23.8萬人,較2023年增加8300人,同比增加3.6%,時隔9年止跌回升。
韓國怎麼解釋的呢?
韓國媒體理由説了一大籮筐,總結起來主要有2大點:
一是韓國政府“英明”,政策得力有效果;
二是韓國民眾“有覺悟”,婚姻生育觀開始積極。
不過傻子都知道這是一種暫時現象,如美國紐約時報也關注到了這一消息,毫不留情指出韓國生育率仍然為全球最低,並隱晦指出這必定是短暫波動。
其實2024年出生人口增多,哪有那麼複雜,就5個字:想生龍寶寶!
2024年是甲辰龍年,在中華文明圈龍象徵着吉祥、尊貴和成功,人們普遍認為龍年出生的孩子會擁有非凡的命運,會給家庭帶來好運。因此,許多家庭傾向於在龍年生育孩子。
韓國傳統上同樣有如此認知,2024年在韓國被稱為青龍年,而青龍被視為好運的象徵。
韓國發布相關消息的媒體不少是韓國國家媒體,如韓聯社,信源是韓國官方,他們這種認知,某種程度上反映:該國受美國影響控制,下意識的排斥中華文明因子,否定自己從何而來!
事實上,中華文明才是整個東亞在人類文明歷史長河中,長期領先於世界,面臨危機時又能反覆崛起的根本原因。韓國這種下意識的去中華文明因子的行為,是在自斷未來!
這不是喊口號的大話,而是隨着人工智能加速演進,這個世界越來越意識到的真理——華流才是頂流。
過去一些年,坊間一直有傳言:聯合國文件,中文版是最薄的!
薄意味着什麼?
意味着中文作為有價值信息傳播的載體,效率是最高的。為了再次驗證這個傳言,筆者又搜索了一下。當下搜索工具基本都已經接入AI工具,用以提高效率,其直接羅列答案:
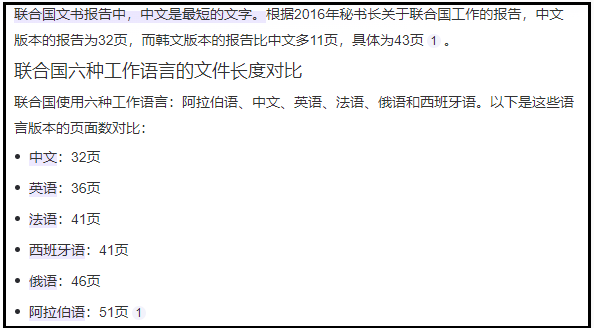
2016年版聯合國秘書長工作報告,各語言版頁數:
中文:32頁;
英文:36頁;
法語:41頁;
西班牙語:41頁;
俄語:46頁;
阿拉伯語:51頁。
因為寫韓國,所以專門問了韓文版,列出的信息是43頁。中文僅僅32頁,傳言不虛。
效率意味着什麼?
成本、競爭力!
這在AI時代,體現得尤為明顯。
想必不少夥伴們用AI工具,已經經常接觸到一個度量單位:tokens。因為這是大模型收費的定價單位,如GPT-4的輸入Tokens每百萬收費2.5美元,輸出Tokens每百萬收費10美元;收費版Deepseek價格為每百萬輸入tokens 2元,每百萬輸出tokens 8元(題外話:拿tokens做錨的話,享受同等服務,人民幣和美元匯率是1:1.25,人民幣1元可以換1.25美元)。
在處理漢字時,通常將每個漢字視為一個獨立的識別單位,即一個token代表一個漢字;而處理英文時,則通常是**,一個Token大約對應0.75個單詞或3-4個字母**。
我們都知道,AI模型的搭建和訓練,需要投建算力中心,投餵海量數據。那麼得出同等有價值信息,這個時候你是否意識到:漢字資料絕對是這個世界效率最高,成本最低的。
所以今年年初幻方量化Deepseek出爐時,讓美國深感挫敗,,覺得天塌了。除了Deepseek開發者天才算法設計外,就是漢語資料信息密度遠比英語資料高得多,從而大幅度減輕了AI數據處理的負擔。
這同樣是有根據的。
美英語言學家自己都有過統計,英語每年新增的專業詞彙量,是漢語的7.6倍。反過來講,同一件事,英語要讓AI明白需要處理的數據量是漢語的7.6倍。只有這樣,AI才能建立完整的認知知識體系。
更讓美英難受的是,漢語底層邏輯實際是二進制(如著名的八卦),絕大數詞彙都是由3000-3500個常用基本漢字組合排列。而英文不斷新造單詞,搜索相關資料給出的答案是年增4000個單詞。

據統計英語詞彙量已經達到了106萬個左右,並且還在不斷增加。漢語雖然每年也增加,但其增加詞彙讓人望文生義,一見便知。
而上述詞彙、文本信息給AI處理,都是要算力,要成本的。所以Deepseek只用了OpenAI不到百分之一的算力,十幾分之一的成本,就搞出了比肩甚至很多領域超過他們的AI大模型。
Deepseek出來後,美國人工智能大模型研究專家進行過對比研究,給出的結論是:漢字模型在處理複雜邏輯時,神經網絡的能耗比英文模型低42%,訓練週期縮短70%。
時間短效率高、能耗還低,中華文明不愧於才是世界頂流!
再注意2016年聯合國秘書長的工作報告,比中文僅差4頁的英文,AI領域都競爭不過,那多了十幾頁的呢?
韓國政府抵制Deepseek,韓國媒體下意識去中華文明因子,捧美國的臭腳,絕對是最錯誤的選擇!