宇樹和智元爆火背後:人類是如何給機器人注入靈魂的?_風聞
知危-知危官方账号-1小时前
宇樹機器人在春晚跳了一場秧歌之後,人們對人形機器人的關注度開始空前高漲。
而就在前天( 3 月 11 日 ),“ 華為天才少年 ” 稚暉君所創立的創業企業智元機器人發佈了基於 GO-1 具身智能大模型的智元機器人靈犀 X2 。
靈犀 X2 給我們展現了它行走、小跑、騎自行車、溜滑板、縫線、語音聊天、俏皮的小動作等等生動的行為。
你可能會發現,最近兩年人形機器人的發展速度變得很快,機器人越來越像一個有靈魂的 “ 人 ”。
那麼,一個有趣的問題來了:人類是如何給機器人 “ 注入靈魂 ” 的呢?
首先,我們要先明白 “ 機器人為什麼不會摔倒 ”,明白了這一點,你就知道了機器人是如何運動的。
秘訣在於:大扭矩和平衡術。
機器人的運動,最簡單的方式,可以分解為本體運動和肢體運動。
肢體運動包括身體各個關節的旋轉、肢體的伸縮等,這就相當於將肢體運動分解為了旋轉運動和直線運動。

而直線運動,是可以通過旋轉運動來表達的,比如擰螺絲,就是通過旋轉運動達成了直線運動。

所以,你可以把機器人一切的運動都看作是一系列旋轉運動組成的,而達成這些旋轉運動,通過電機就可以實現。

而這之中,又有一個比較關鍵的點:在機械臂的工作使用中,通常需要有足夠大的扭矩,尤其對人形機器人來説,大扭矩的意義特別廣泛。
有了大扭矩,機械臂可以施加更強的力,用於舉起重物,也能在承載重物時保持穩定,抗干擾能力加強,比如搬運機器人。
由於轉速降低( 功率=扭矩*轉速,功率相同時扭矩越大轉速越低 ),可以精準控制旋轉角,從而進行精密操作,同時能夠克服組織阻力,比如精密手術機器人。
而最重要的一點是,對於行走、爬坡或跨越障礙,大扭矩意味着機器人能夠克服地面摩擦、重力和其他阻力,確保穩定的運動。
有了大扭矩這個先決條件,接下來就是平衡術。
本體運動可以理解為是機器人通過肢體運動與環境交互( 比如摩擦、推力等 )實現的質心的平移、旋轉運動,從而達到包括行走、跑動甚至後空翻等目的。
想簡單理解這個概念,你可以現在站起來走幾步,並且只關注自己的其中一隻腳,比如右腳,會發現過程是這樣的:
右腳邁出並落在前方;
身體圍繞着前方落腳點,向前 “ 甩出去 ”;
直到身體被 “ 甩 ” 的快失去平衡了,左腳突然出現,幫你撐住身體。
這個過程,其實很像一個倒立的鐘擺向前方一 “ 甩 ” 一 “ 甩 ” 地擺動。

沒錯,在機器人動力學中,確實也會將人形機器人簡化為一個線性倒立擺模型,即著名的 LIPM 模型,它能很好地抓住人形機器人運動的基本規律。
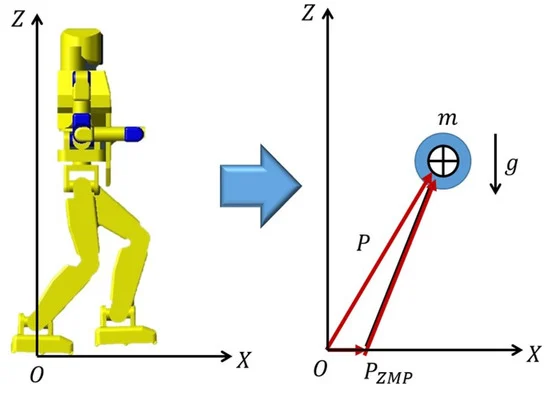
在這個模型中,假設機器人所有重量集中在一個質心點上,用無質量的杆撐在地面上,在行走時保持質心高度不變。
這時,在地面上存在一個點,圍繞這個點可以計算出所有水平方向的力矩之和為零,稱之為零力矩點,即 ZMP ( Zero Moment Point )。
零力矩點説明機器人不會圍繞這個點上的平行於這個平面的軸旋轉。( 可以理解為不會旋轉着摔倒在地 )
如果你覺得這樣理解太抽象,你可以看看花滑運動員,他們的身體如果圍繞身體豎直方向的力矩之和是不為零的,那麼其就會開始旋轉。

大概理解了什麼是 ZMP 之後,我可以告訴你一個公式,這個公式就是機器人行走時的 “ 倒立擺 ” 公式:
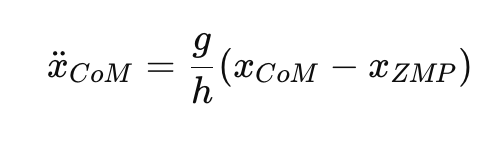
你不需要理解這個東西,你只需要知道我們把 “ 行走 ” 這件事轉化成了一個方程,想要走好路,我們要做的就是解方程。
不過,LIPM 模型很簡單,他是一個比較理想的模型,生活中很難有完全近似於這個簡單模型的運動。比如機器人的速度變化過大,質心變化過大( 比如亂蹦亂跳或跳舞 ),或質心不穩定( 比如抓握物品或身上掛着不穩定的器件 ),都會讓實際情況脱離模型,帶來很大的平衡難題。
所以,你會看到早期的機器人都用小碎步行走,這樣可以保持更加平穩的速度以及更小的加速度,從而偏移程度小,更容易保持平衡。而機器人用彎曲的膝蓋行走,可以讓質心保持在相同高度,更加適配這個極簡的模型,也就避免了更多複雜因素的引入。
從以上討論中,我們也可以對運動有一個新的認識角度。
行走並不是時刻保持着平衡狀態,而是不斷處於一隻腳製造失衡而另一隻腳消除失衡的動態平衡過程,從而推動機器人前進。

LIPM 模型討論的是對機器人運動的限制因素,但在實際運動中,機器人當然並不是按照方程完全被動地行走的,而是先規劃一個參考 ZMP 的路線,再按照計算的質心位置和加速度實際去行走,確保在這過程中,實際的 ZMP 與參考 ZMP 儘可能重合,從而保持平衡。
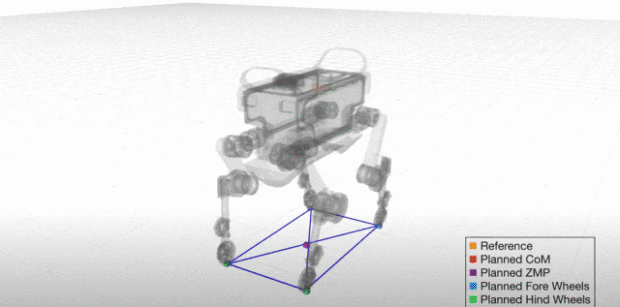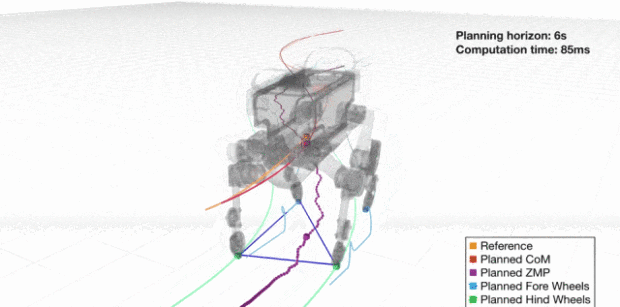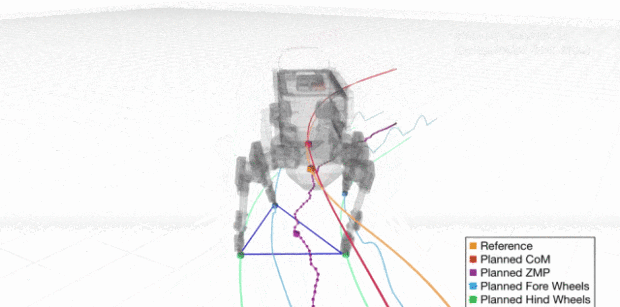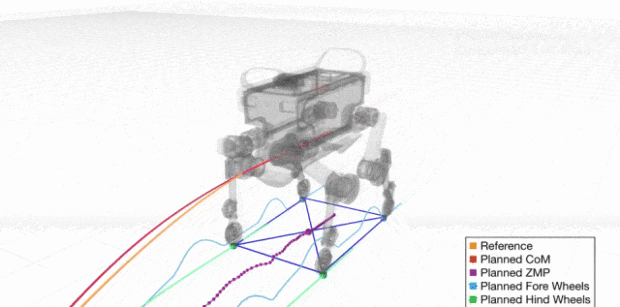
而機器人要在任意時刻保持平衡,就需要保持 ZMP 點( 上圖機器人身體下方標記的一個點 )位於支撐多邊形內。支撐多邊形可以簡單理解為上圖機器人的接觸地面的腳圍成的多邊形。
這太複雜了,看到這裏你可能快要暈了,不過沒關係,機器自己也不理解,所以,注入靈魂的步驟開始了:我們試圖讓機器自己學會理解如何去走路、做動作。
行走、奔跑等基本的運動行為一般是通過經典 AI 算法強化學習訓練得到的,早年一直不用 AI 技術、成本降不下來的波士頓動力現在也在用強化學習來訓練 Spot 機器人和 Atlas 機器人。
強化學習的原理大致是,比如**機器人在行走時,如果採用了正確的步伐或者沒有摔倒,就提供獎勵,如果採用了錯誤的步伐或者摔倒了,就進行懲罰。**這在遊戲的語境中很容易理解,吃豆人吃到豆子了就有獎勵,被幽靈抓住了就有懲罰。
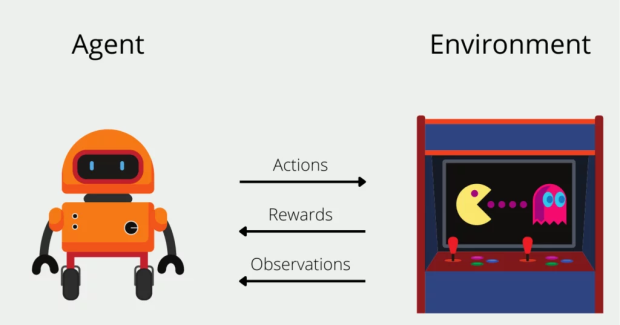
同樣,機器人接收到獎勵信號,就會強化當前的行為,接收到懲罰信號,就會弱化當前行為。
強化學習基本是機器人學習的底層配置了,但它也有非常大的缺點。
機器人又有太多的方式或動作來完成同一個任務,也就是動作空間太大。
這就像是在一個非常龐大地圖的開放式遊戲中,沒有特定的任務指引,只能靠一點一點的摸索來獲取反饋,這樣固然有非常大的創新自由度,比如AlphaGo能夠採用人類意想不到的方式來走棋。
他的弊端是資源消耗特別大,而且也有可能讓機器人用意想不到的方式獲取獎勵。
比如靈犀 X2 機器人訓練時會有 “ 抽象 ” 的行走方式,這些方式能夠滿足 “ 前進 ” 這一目標,但顯然不是我們想要的行為,這種現象通常被稱為 “ reward hacking ”。
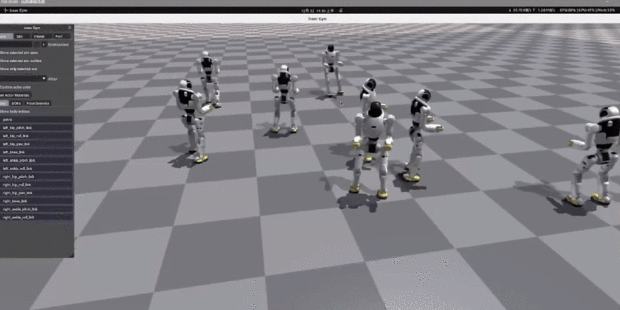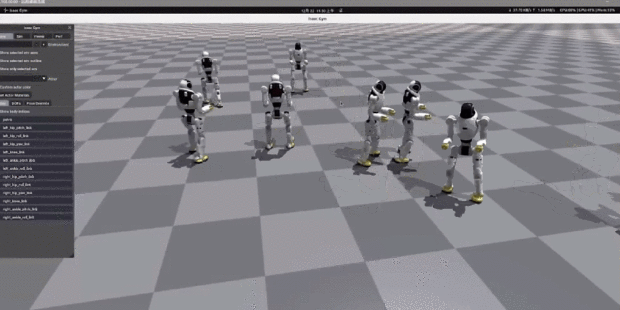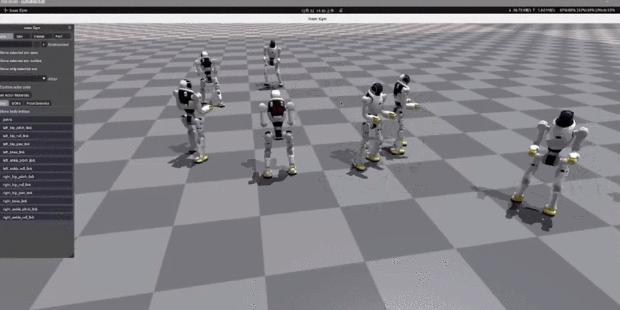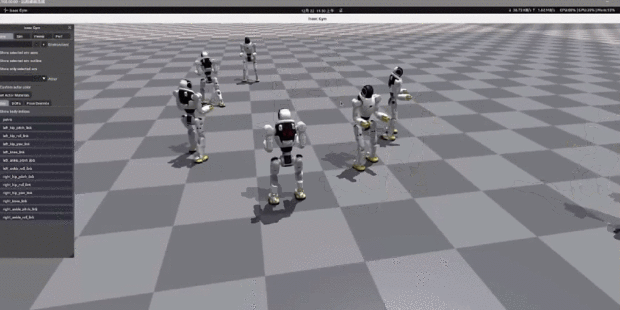
如今,人形機器人有一個發展趨勢就是自由度越來越大,比如手指數量和關節數量越來越多,對於具有越來越多自由度的人形機器人,每個狀態下可以採取的動作數量呈指數級增長。
下圖所示的很古早的本田機器人有 30 個自由度 ( DOF ),每個自由度都需要在每個時刻發出命令。即使每個 DOF 的命令只有三個可能的值( 例如前進、後退和無 ),但在每個狀態下都可以採取 3^30 種不同動作的組合。

這就讓機器人採用錯誤行為的概率( 即便能夠達到相同目標 )極大。
於是,人們提出了 “ 模仿學習 ” 這一概念來彌補不足,它讓機器人通過觀察其它機器人或人類的動作來學習,這樣就把動作到任務目標的路徑都規劃好了,甚至不需要設置獎勵。

圖源:https://human2robot.github.io/
模仿學習極大縮小了動作空間,並避免了無效的探索。
這相當於把原來開放性極大的強化學習,改造成了一個類似圖像識別的監督學習算法。甚至跳舞、打乒乓球等更加具備人類特性的行為也是通過模仿學習實現的。
但,模仿學習也會遇到一個核心問題。
Agent 在學習時直接模仿了專家提供的動作,而不管交互的最終結果,就好像一個學徒只按照師傅提供的簡單場景來開車,一般只需要按部就班地操作就行,一旦在現實中實操,就容易出錯。
人們也嘗試了不同的解決方法,比如,交互式模仿學習。Agent在測試時如果出錯了或遇到了學習範圍以外的場景,會向人類專家詢問,然後人類專家使用準確的動作重新標記 Agent 收集的數據。
到這裏,你應該能明白,數據,是一個非常重要的點。
從過去一年的進展看來,智元機器人可能就是希望用模仿學習結合超大規模數據把 “ 通用 ” 一路走到黑。
首先是做了 AgiBot World,一個百萬級的機器人真機實操數據集,主打專業性。
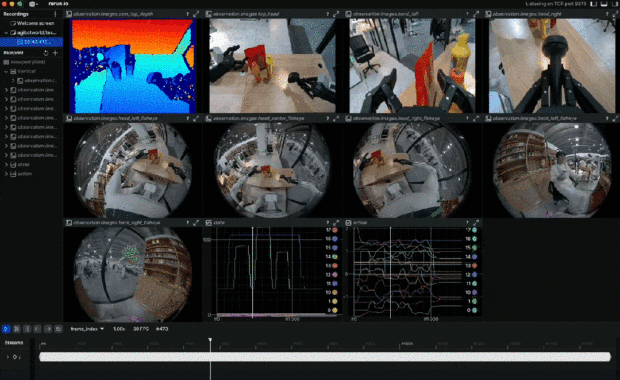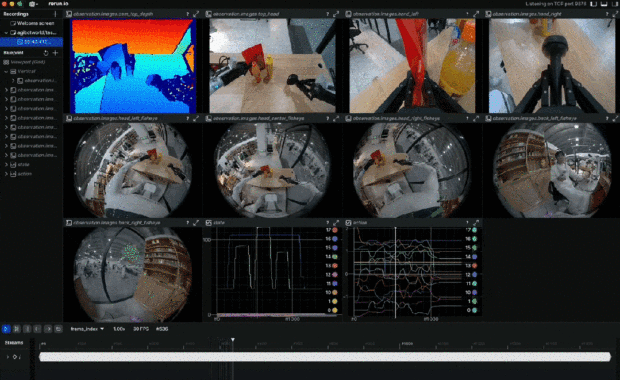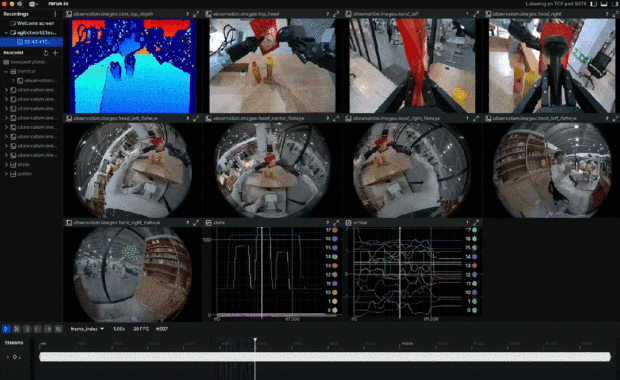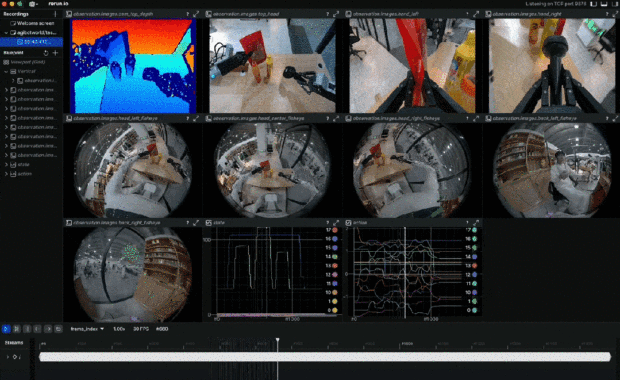
它包含的基礎動作多,比如抓取、放置、推、拉等基礎操作,以及攪拌、摺疊、熨燙等複雜動作;場景又多樣,覆蓋家居、餐飲、工業、商超、辦公;數據模態豐富,360 度無死角視覺感知,以及六維力傳感器和高精度觸覺傳感器的數據,後者對於精準操控的訓練必不可少。
在可視化視圖下,可以看到機器人所感知的數據形態,其中包含了每時每刻的 360 度 RGB 圖像、深度圖、以及此時的動作狀態。
然後他們還做了 AgiBot Digital World,更大規模的機器人虛擬仿真框架和開源數據集,主打隨機性。
首先是保持了接近真機數據的模態豐富性,然後又能在同樣的任務下,生成大量的隨機因素。

生成不相關的因素,目的是為了讓神經網絡知道,在一個任務下,哪些是相關的,哪些是不相關的,畢竟神經網絡過於脆弱敏感,幾個意料之外的像素就能讓它大吃一驚,忘了自己是誰、來自哪裏、要去哪兒。
機器人如果沒有接觸到這些隨機因素,也就缺少了 “ 否定 ” 的能力,加入隨機因素能很好解決這個問題。
只是再多的隨機化也不能彌合虛擬和現實的差距( sim2real gap ),現實的複雜性遠超我們想象。
怎麼彌合這種差距呢?關鍵在於知識共享。
神經網絡的中間層能學習到一個表徵空間,表徵空間隱含了觀察現象背後的底層知識,雖然還不能完全理解它,但將這一層進行共享,就可以將其中的知識技能進行遷移,這一點是在深度學習奠基者Yoshua Bengio很早期的論文 “ Representation Learning: A Review and New Perspectives ” 中就提出來的深刻洞察。
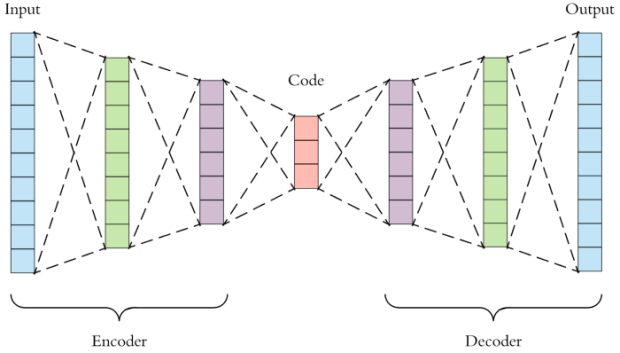
比如在這項研究中,機器人就學習了一種知識共享的方式。
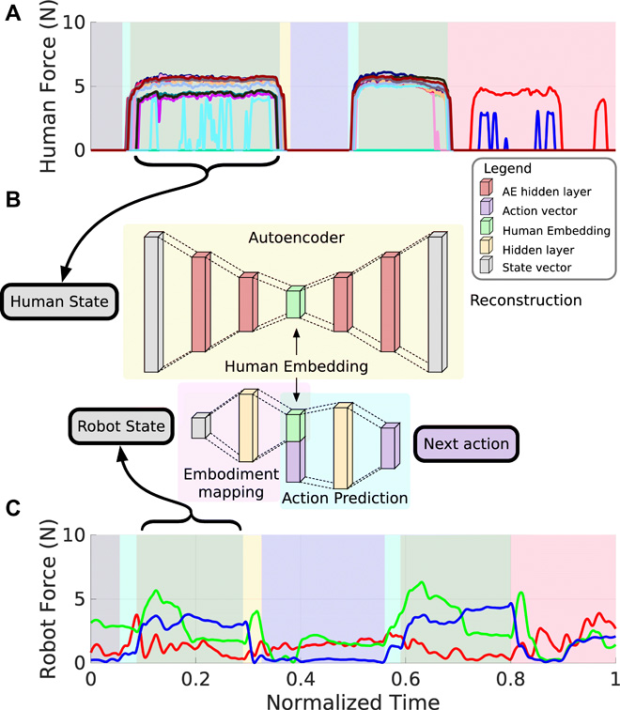
圖源:https://www.science.org/doi/10.1126/scirobotics.aay4663
在開藥瓶任務中,機器人從人類演示中學習怎麼擰瓶蓋。
人類動作的觸覺數據,通過神經網絡轉化為表徵 A,A 再轉化為如何擰瓶蓋的高級決策。
對於不同類型的機器人動作的觸覺數據,則通過另一個神經網絡,映射到 A,這相當於是一個低級動作識別模型。
**這樣就將機器人的低級動作識別連接到了人類的高級決策,讓機器人可以想象自己是人類來學習怎麼擰瓶蓋。**在實驗中,機器人無需訓練就能使用這些如何擰瓶蓋的高級決策。
人們對這種知識共享的根本理解還處於初步階段,神經網絡還是很神秘,目前其實是從宏觀到微觀的方式逐步被結構化的,怎麼結構化取決於專業領域的特點和你的需求。

但表徵空間的共享是一種非常有想象力的方法。
它表明在表徵空間內,任意模態的數據都是可以連接的,這就為不同領域的知識遷移和融合提供了橋樑,很自然地也包括不同類型的機器人的技能遷移、通用大語言模型與專用機器人模型的知識融合等。
特別是,一個不成熟的領域的 AI 模型,可以通過成熟的領域的 AI 模型通過很小的訓練量就能夠得到。
這便是預訓練的另一個理解視角。
有研究就表明,在大語言模型的表徵空間內,相似的虛擬和現實的機器人操作圖像在表徵空間中更加靠近( 下圖中的綠框和紫框圖像 ),而不同的虛擬和現實的機器人操作圖像在表徵空間中就會離得更加遠( 下圖中的藍框和紅框圖像 )。
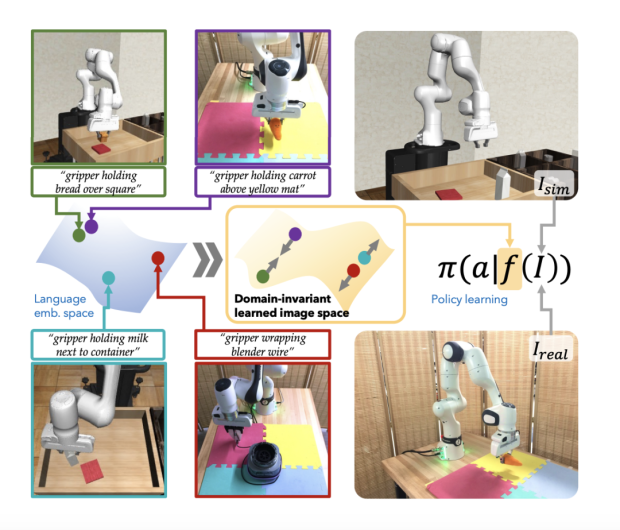
圖源:https://arxiv.org/pdf/2405.10020
所以,通用大模型更廣泛的現實世界知識有望彌合機器人領域依賴虛擬數據造成的虛擬和現實的差距。
比如在智元機器人 GO-1 具身智能大模型中,視覺大語言模型識別視覺輸入,然後調用行動規劃專家和動作專家來生成下一步動作。
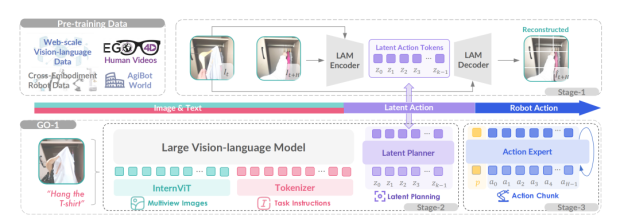
圖源:https://agibot-world.com/blog/agibot_go1.pdf
在模型設計中,其核心仍然是知識共享和複用,視覺大語言模型將知識共享給了行動規劃專家和動作專家,行動規劃專家也將知識共享給了動作專家。
模仿學習結合超大數據集是一條極簡而有效的道路,不能證明是最優的,但確實潛力極大,或許有望復刻機器人領域的 ChatGPT 時刻。
總之,簡單來説,大模型的突破,大概率會帶來人形機器人的突破,做 AI,就是在做機器人的靈魂。
撰文:流大古
編輯:大餅
參考資料:
https://www.science.org/doi/10.1126/scirobotics.abd9461
https://human2robot.github.io/
https://arxiv.org/pdf/2309.02473
https://arxiv.org/pdf/1206.5538
https://arxiv.org/pdf/2405.10020
https://agibot-world.com/blog/agibot_go1.pdf
https://mp.weixin.qq.com/s/vG_VQcDYPojg-1DZ9DXoGQ
https://mp.weixin.qq.com/s/wj0Pb5g20fvILOxJz95LBg
https://mp.weixin.qq.com/s/WGIBdd5zdsjXyU02YSSCYA
https://zhuanlan.zhihu.com/p/452704228
https://www.wired.com/story/boston-dynamics-led-a-robot-revolution-now-its-machines-are-teaching-themselves-new-tricks/?utm_source=chatgpt.com