文心4.5/X1海外爆火,中國模型站起來了_風聞
蓝鲨硬科技-1小时前
“紮根應用,創造價值”
作者 | 黃 煒
編輯 | 盧旭成
3月16日,百度拋出了兩款核彈級產品——文心大模型4.5以及文心大模型X1。
按照百度的設定,文心大模型4.5,是一款多模態基礎大模型,擅長生成及解讀圖片、視頻,能解答多領域問題;文心大模型X1,是一款深度思考模型,在邏輯推理、複雜計算及工具調用等方面表現尤為出色。
根據Benchmark測評,文心大模型4.5的多項基準測試成績優於GPT4.5、DeepSeek-V3,在平均分上以79.6分高於GPT4.5的79.14。簡單來説,百度文心4.5和X1大模型就是當前世界上最強的中文大模型。
百度給這兩款模型的定價是,普通用户登錄文心一言官網即可免費體驗。企業及開發者可在百度智能雲千帆大模型平台調用新模型,文心大模型4.5的API輸入價格為0.004元/千tokens,輸出0.016元/千tokens;文心大模型X1為輸入0.002元/千tokens,輸出0.008元/千tokens。
兩款模型一經發出,不僅國內AI圈子迎來大地震,連海外都“震感”強烈。
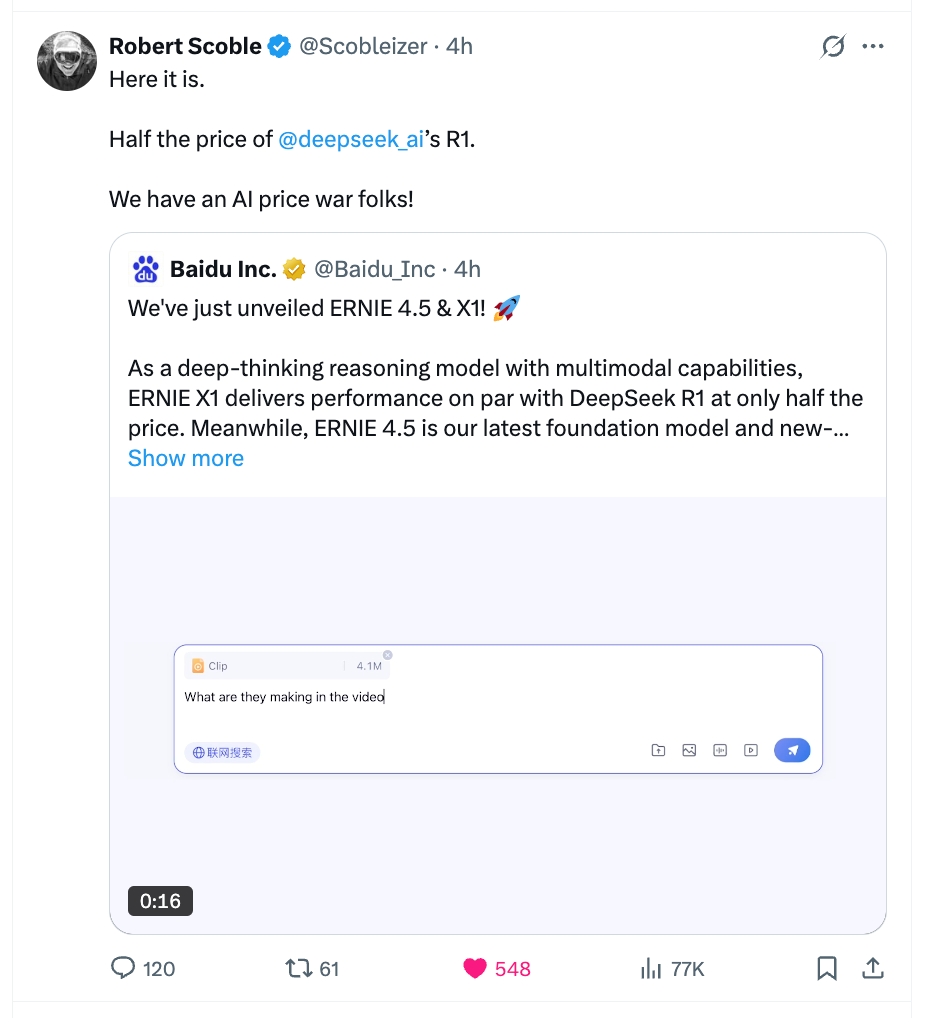
東南亞“超級應用”Grab的首席產品官Philipp Kandal不顧週末,發推稱:“百度在週日都殺瘋了,文心大模型4.5和 X1剛剛發佈——其評估水平可與GPT-4.5/Deepseek R1媲美,而且API定價極具競爭力。可惜還沒有英文註冊渠道,不然我真想試試……”
全世界最著名的科技記者Robert Scoble也感嘆:“只要DeepSeek R1的一半價格,我們要打一場AI價格世界大戰了。”
 藍鯊硬科技也第一時間對百度的兩款新模型進行了測試。經過親身體驗,我們發現,Benchmark的評分沒有騙人,百度的兩款新模型是當之無愧的最強中文模型。但隨着測試深入,我們意識到,測評拿下高分,還只是百度AI野望的一小步。
藍鯊硬科技也第一時間對百度的兩款新模型進行了測試。經過親身體驗,我們發現,Benchmark的評分沒有騙人,百度的兩款新模型是當之無愧的最強中文模型。但隨着測試深入,我們意識到,測評拿下高分,還只是百度AI野望的一小步。
過去兩年半,當國內多數AI公司都在“向OpenAI看齊”,也有一些百度這樣的異類,選擇了走自己的大模型發展之路。而現在,當一箇中國大模型廠商,能以OpenAI百分之一的API調用價格,提供性能相當的基礎大模型,似乎終於證明了中國創業者並不缺乏創新能力。
正如李彥宏所言:“創新不能被計劃,你也不知道創新何時到來,你所能做的就是營造一個有利於創新的環境……”
 一把瑞士軍刀
一把瑞士軍刀
百度文心4.5和X1大模型給我的第一體感是“這玩意兒真像一把瑞士軍刀”,可玩性比市面上其他模型都更高。
可玩性首先體現在對圖片和視頻的理解上。
經常使用大模型的用户都清楚,理解並識別圖片和視頻,是大模型的絕對短板。舉個例子,我們經常在社交媒體刷到一些冷門電影片段,卻不知道它出自哪部電影。這時如果去問大模型,大模型要麼給出一個錯誤的答案,要麼直接回答“無法識別”。
比如我選取的電影截圖《賽德克·巴萊》,這是一部台灣電影,講述了1930年台灣原始部落賽德克族反抗日本侵略者的故事,獲得過第48屆台灣金馬獎。
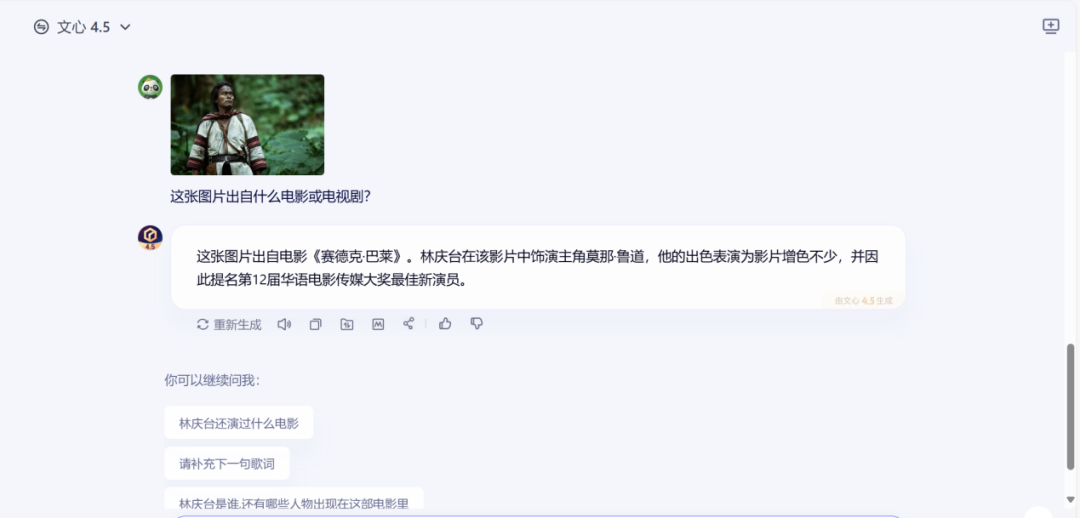 在詢問百度文心4.5模型後,它不僅準確識別了電影名稱,還補充回答了主角的真實姓名和飾演角色。
在詢問百度文心4.5模型後,它不僅準確識別了電影名稱,還補充回答了主角的真實姓名和飾演角色。
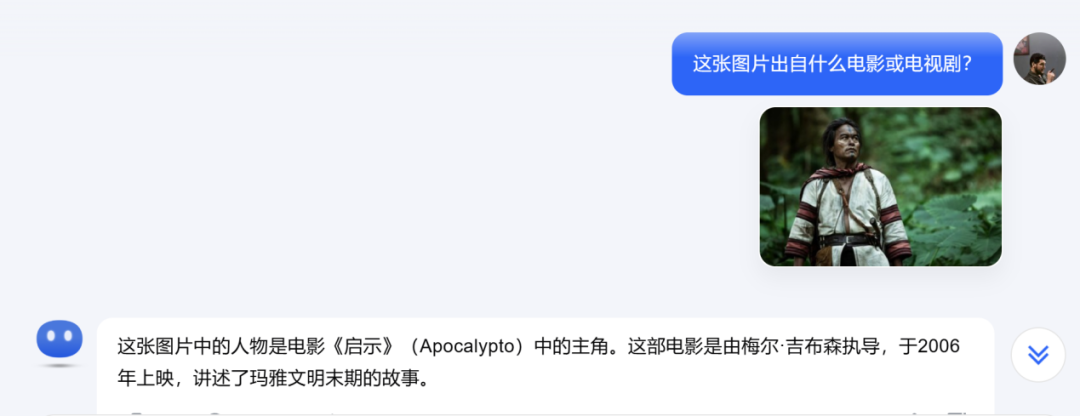
而如果用同樣的截圖去問市面上其他主流模型,它們要麼無法識別圖片,要麼就回答是美國電影《啓示錄》(Apocalypto)。
《啓示錄》是美國導演梅爾·吉布森的經典作品,講述的也是原始部落反抗侵略的故事,只不過故事主角是瑪雅人,發生時間在瑪雅文明末期(16世紀)。與我想找的《賽德克·巴萊》,相差足有400年。
 除了圖片識別,文心4.5模型還支持視頻識別和產出。比如輸入一段6秒的九寨溝風景片段,並詢問距離,模型能很快識別視頻內容,並給出旅行建議。
除了圖片識別,文心4.5模型還支持視頻識別和產出。比如輸入一段6秒的九寨溝風景片段,並詢問距離,模型能很快識別視頻內容,並給出旅行建議。
 大模型能理解視頻內容,實在令人興奮。
大模型能理解視頻內容,實在令人興奮。
在當前這個短視頻時代,有太多視頻問題需要模型解答。
比如刷到一個風景如畫的視頻,想知道究竟是何處景點;刷到某個動漫片段,想知道名字入坑補番;看到一個萌寵視頻,想了解這隻狗狗是什麼品種……這些需求都需要一個“懂”視頻的大模型。
但在以往,主流模型根本沒有視頻輸入選項,用户只能根據視頻,輸入模糊文字或者圖片提問,得到的結果也不盡如人意。
**造成上述現象的主因是——缺乏模型的多模態能力。**所謂多模態,通俗來説,就是用不同方式表現信息。可以是文字,也可以是圖片,短視頻,或者音頻。
之前的很多大模型,都是通過拼接多個模型擁有了多模態能力,屬於非原生多模態模型。這種模型往往只能做些表面或字面理解,很容易忽略細節信息,導致推理輸出不連貫甚至矛盾。
而百度則是原生的多模態大模型,原生多模態大模型更能敏鋭捕捉圖像背景、小物體或微小的文本信息,綜合理解跨模態的幽默、諷刺等深層含義,使得推理結果連貫,更符合人類邏輯。
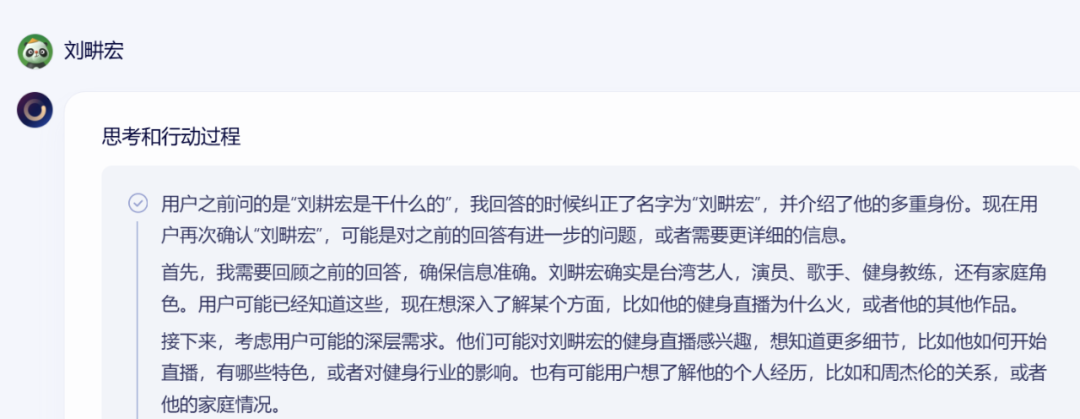
測試過百度大模型的多模態能力後,我決定給它上點強度,問了一個簡短但不簡單的問題“劉畊宏是幹什麼的?”這個問題的難度在於,劉畊宏有演員、歌手、健身教練、網紅等多個身份,並且近一個月職業狀態有更新。很難界定他的職業範圍。
如果把這個問題拋給其他大模型,它們的概括比較籠統,劉畊宏的職業狀態也停留在三年前。
 同樣的問題,去問文心4.5模型,它不僅列出了按時間順序劉畊宏各個時期的代表作:《頭文字D》、《爸爸去哪兒5》等,還詳細描述了劉畊宏健身主播生涯爆火的經歷和遭遇的困難。最關鍵的,文心4.5模型連劉畊宏2025年2月與無憂傳媒解約,之後簽約新MCN機構的消息都沒有漏掉。邏輯清晰地完成了我的指令。
同樣的問題,去問文心4.5模型,它不僅列出了按時間順序劉畊宏各個時期的代表作:《頭文字D》、《爸爸去哪兒5》等,還詳細描述了劉畊宏健身主播生涯爆火的經歷和遭遇的困難。最關鍵的,文心4.5模型連劉畊宏2025年2月與無憂傳媒解約,之後簽約新MCN機構的消息都沒有漏掉。邏輯清晰地完成了我的指令。
 為了徹底難倒百度的新模型,我決定從題設開始,就給它一個錯誤的信息。我將模型切換成百度X1,將問題改成“劉耕宏是幹什麼的?”故意將“劉畊宏”的“畊”字錯寫成“耕”,這是一個我自己在寫稿時都經常犯的錯誤。但百度X1模型第一時間發現了名字有誤,並且識別了是提問者筆誤的可能。
為了徹底難倒百度的新模型,我決定從題設開始,就給它一個錯誤的信息。我將模型切換成百度X1,將問題改成“劉耕宏是幹什麼的?”故意將“劉畊宏”的“畊”字錯寫成“耕”,這是一個我自己在寫稿時都經常犯的錯誤。但百度X1模型第一時間發現了名字有誤,並且識別了是提問者筆誤的可能。
 在我改正劉畊宏的名字後,百度X1甚至還會“炫耀”自己糾正了我的筆誤,並進一步推測我的需求是“希望瞭解更詳細的劉畊宏信息”。此刻我甚至感覺,自己正在與一個有“真情實感”的人類對話,而不是面對一個按照既定程序回答問題的機器。畢竟,機器怎麼會有“炫耀”這種情緒,還能推測我的需求呢?
在我改正劉畊宏的名字後,百度X1甚至還會“炫耀”自己糾正了我的筆誤,並進一步推測我的需求是“希望瞭解更詳細的劉畊宏信息”。此刻我甚至感覺,自己正在與一個有“真情實感”的人類對話,而不是面對一個按照既定程序回答問題的機器。畢竟,機器怎麼會有“炫耀”這種情緒,還能推測我的需求呢?
 實用是檢驗模型的唯一標準
實用是檢驗模型的唯一標準
隨着對百度文心4.5和X1大模型的體驗逐漸深入,我愈發覺得以往行業對大模型的討論,似乎搞錯了重點。
拋開開源閉源的爭論,實用才應該是檢驗模型好壞的唯一標準。但在工作中,現在的大模型實在讓人不太敢用。
國際出版集團Wiley最近對70多個國家的4946名研究人員進行了一項調查——AI對撰寫稿件、審查論文和進行同行評議等是否有用?
近三分之二的研究人員提到,不太相信AI處理複雜任務的能力,如識別文獻中的研究空白、選擇投稿期刊、推薦審稿人,或是建議相關引用文獻等。81%的受訪者還表示,他們擔憂AI的準確度和隱私風險。
各國研究員們的擔憂,存在於每一位試圖將AI引入工作流的人之中。
比如讓大模型生成一篇彙報材料,雖然模型能在幾秒鐘內生成一篇文稿,但沒人敢直接上交,因為這篇文稿中必然存在大模型“胡編亂造”的內容,既可能是偽造數字,也可能是編造時間,或虛構人物。
這種被業界稱為“幻覺”的現象,阻礙着AI進一步深入工作場景。畢竟,沒人敢拿自己的飯碗賭AI是否又在“一本正經地胡説八道”。
但在深度體驗過百度文心4.5和X1大模型後,我發覺其幻覺現象得到了明顯改善。
就在上個月,一條AI製造的駭人新聞在社交媒體廣泛傳播——“截至2024年末,80後死亡率突破5.2%,每20個80後中就有1人已經去世”,很多自媒體稱,數據來源是第七次人口普查的“權威數據”。後經上海網絡闢謠介紹,這條假數據的最初來源很可能是和AI對話所得,後經自媒體擴散形成輿論風波。
當把同樣的問題拋給百度模型,其不僅提供了第七次人口普查的真實數據“七普數據顯示,2019年11月至2020年10月,30-39歲(80後)死亡人數為19.35萬,佔該年齡段總人口的0.087%。”還列出了引用信息來源,以及中國人民大學李婷教授的研究結果,證明網傳的5.2%死亡率,存在嚴重錯誤。
 大模型幻覺減少,靠的是百度RAG(檢索增強)的基本功。依託在搜索領域的深厚積累,百度自研了一套兼顧“檢索-理解-生成”檢索增強系統,能夠生成準確率更高、時效性更好的答案,降低大模型的幻覺。
大模型幻覺減少,靠的是百度RAG(檢索增強)的基本功。依託在搜索領域的深厚積累,百度自研了一套兼顧“檢索-理解-生成”檢索增強系統,能夠生成準確率更高、時效性更好的答案,降低大模型的幻覺。
除了保證內容和數據的真實性,一個實用的大模型還應該是個“多面手”。因為在當今職場,一個文員就要會寫材料、寫會議紀要、做圖、做報表、做PPT等十八般武藝,大模型要真正提供生產力,也需要提升“綜合能力”。
為了測試百度X1大模型的綜合能力,我根據上週自己的實際工作要求“據案例圖片,生成一張婦女節宣傳海報,感謝婦女同志對公司的貢獻,並生成一段朋友圈文案。”
有趣的是,百度X1大模型將自己的思考過程也展示了出來——第一步,調用圖片理解工具識別圖片內容,並根據我的意圖,進行詳細的步驟規劃;第二步,使用圖片生成工具,生成了一張卡通婦女節宣傳海報。
 根據百度官方的解釋,多工具調用是文心X1的特色之一。目前上線的工具包括高級搜索、文檔問答、圖片理解、AI繪圖、代碼解釋器、網頁鏈接讀取、TreeMind樹圖、百度學術檢索、商業信息查詢、加盟信息查詢等。
根據百度官方的解釋,多工具調用是文心X1的特色之一。目前上線的工具包括高級搜索、文檔問答、圖片理解、AI繪圖、代碼解釋器、網頁鏈接讀取、TreeMind樹圖、百度學術檢索、商業信息查詢、加盟信息查詢等。
根據親身體驗,用户不必選擇具體的工具,大模型就能根據用户的指令,智能選擇對應的工具。
