從Tesla到Blackwell,英偉達如何改寫HPC規則_風聞
半导体产业纵横-半导体产业纵横官方账号-赋能中国半导体产业,我们一直在路上。1小时前
據摩根大通此前預計,英偉達將在大會上推出Blackwell Ultra芯片(GB300),並可能披露Rubin平台的部分細節。此次大會還將聚焦AI硬件的全面升級,包括更高性能的GPU、HBM內存、更強的散熱和電源管理,以及CPO(共封裝光學)技術路線圖。
在黃仁勳的演講到來前,我們來看看這些年中英偉達推出的系列架構,和他們背後的故事。
1999年底,英偉達推出了第一款GPU(Graphic Process Unit,圖形處理單元)Geforce 256,將完整的渲染管線集成進硬件,提供了不錯的加速效果。但這款產品還很難稱之為處理器,因為它尚不具備任何可編程能力。2001年隨着DX8引入可編程頂點着色器的概念,英偉達才在Geforce 3中添加了Vertex Processor,使GPU可以編程了。隨後,越來越多的可編程着色器被DX和OpenGL引入,以滿足渲染開發者的算法需求。
在GPU設計之初,並非針對深度學習,而是圖形加速,在英偉達推出CUDA架構之前,GPU並無太強對深度學習運算能力的支持。真正用來作為人工智能算力支持的GPU,不是普通的顯卡,而是GPGPU(General-Purpose Computing on Graphics Processing Units)即通用計算圖形處理器,這是一種用於處理非特定需求(通用類型)計算目的的算力單元(芯片)。
隨着GPU具備了可編程能力,其用於並行計算的天賦被髮掘出來。當時,很多大學和研究機構都在嘗試用GPU做一些科學計算。
2003年的SIGGRAPH大會上,許多業界泰斗級人物發表了關於利用GPU進行各種運算的設想和實驗模型。SIGGRAPH會議還特地安排了時間進行GPGPU的研討交流。但當時的開發者只能利用着色器編程語言開發程序,必須將計算資源映射為渲染概念才能使用,非常麻煩。因此亟需一種針對GPU並行計算的編程語言。此時,正在斯坦福讀博的Ian Bark看到這一需求,投身到Brook(一套用於並行計算的編程語言,後被AMD收購)的研發中,成為GPU並行計算軟件棧的先行者。2004年,他以實習生的身份加入英偉達,並於兩年後開發出CUDA。
渲染需求變得越來越多樣化,並行計算業務正含苞待放,Tesla G80架構正是在這樣的歷史背景下被設計出來,成為英偉達改變自身命運的重要轉折點。
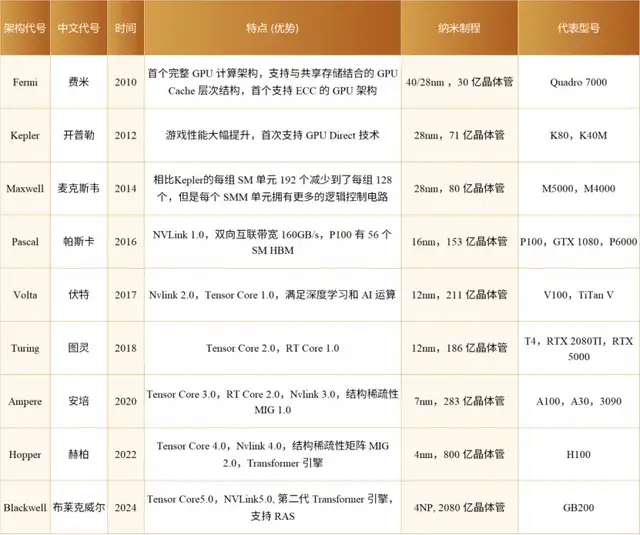
2006年,英偉達推出了Tesla架構的第一代(G80),開啓了GPU通用計算探索。Tesla架構之前的顯卡也經歷了幾代的發展,但基本上是圖形顯卡。而它採用全新的CUDA架構,支持使用C語言進行GPU編程,可以用於通用數據並行計算。這成為英偉達改變自身命運的重要轉折點。Tesla G80是第一款實現CUDA架構的GPGPU,開啓了一個並行加速的時代。G80是有史以來最偉大的GPU變革產物之一,首批產品GeForce 8800 GTX/GTS於2006年11月發佈。之後,英偉達又在第一代基礎上推出了Tesla架構的第二代(GT200),其雙精度的FMA運算速度30FMA ops/ clock,提升了8倍多。
就在G80-G200這兩代產品上,英偉達花了大約三年時間積累了大量的用户體驗反饋,招募了Bill Dally作為首席科學家,最終推出了Fermi這個劃時代的產品,這是第一款帶有L1 Cache、ECC糾錯,面向超級計算機的架構,從這一代開始,英偉達涉足超級計算機的野心開始暴露無遺,在發佈的時候拉來了多位超級計算機行業的重要人物站台。
2010年,英偉達公司正式推出了Fermi全新架構。這款架構不僅僅是一個簡單的硬件更新,而是被英偉達定義為首款專門為計算任務而設計的GPU。換句話説,英偉達通過Fermi架構重新定義了GPU的概念,旨在加速並行計算的性能。與此同時,這款架構還具備了強大的圖形渲染能力,使其在圖形處理方面同樣表現出色。而GF100是第一款基於Fermi架構的GPU,集成32億個晶體管,專為下一代遊戲與通用計算應用程序而優化的全新架構,實現了所有DirectX 11硬件功能,包括曲面細分和計算着色器等。
G80是對統一圖形與計算處理器應有面貌的最初願景。隨後的GT200擴展了G80的性能與功能。而GF100,這是一個專為下一代遊戲與通用計算應用程序而優化的全新架構的GPU。Fermi這一代架構展現了英偉達全力押注通用並行計算的決心。倘若説Tesla G80僅僅是小試身手,那麼Fermi則正式吹響了全面進軍計算產業的號角。
02英偉達佈局高性能計算
之後,英偉達大致保持了兩年更新一次架構的頻率,不斷推陳出新。
2012年,英偉達推出Kepler架構。這是首個支持超級計算和雙精度計算的GPU架構。得益於28nm的先進製程技術,Kepler在性能和功耗方面實現了質的提升。Kepler GK110具有2880個流處理器和高達288GB/s的帶寬,計算能力比Fermi架構提高3-4倍。Kepler架構的出現使GPU開始成為高性能計算的關注點。
2014年,英偉達發佈的Maxwell架構是先前Kepler架構的升級版,採用台積電28nm工藝製程。彼時移動設備興起,對低功耗、高性能GPU需求大增,同時需要優化GPU在不同應用場景的適應性,Maxwell架構應運而生。首款基於Maxwell架構的GPU為GM107,專為筆記本和小型(SFF)PC等功率受限的使用場合而設計,採用台積電28nm工藝製程,芯片尺寸148平方毫米,集成18.7億個晶體管。針對流式多處理器採用全新設計稱為SMM,GM107核心的每核心效能提升了35%,每瓦功耗比提升了一倍,支持DirectX 12。首款基於GM107GPU的顯卡是GeForce GTX750Ti。
2016年,Pascal架構推出,用於接替上一代的Maxwell架構。基於Pascal架構的GPU使用16nm FinFET工藝、HBM2、NVLink等新技術。這是首個為了深度學習而設計的GPU,支持所有主流的深度學習計算框架。Pascal架構核心陣容強大,包括GP100(3840個CUDA Core和60組SM單元)和GP102(3584個CUDA Core和28組SM單元)兩大核心。Pascal GP100具有3840個CUDA核心和732GB/s的顯存帶寬,但功耗只有300W,比Maxwell架構提高50%以上。
Pascal架構剛剛推出之際,深度學習正發展的如火如荼。業界出現了很多針對神經網絡的專用加速器,無論在能效和麪效上都碾壓GPU,這讓英偉達倍感壓力。為了應對競爭,英偉達一反之前兩年一代架構的迭代節奏,次年就推出了專門針對神經網絡加速的GPU架構Volta。Volta架構引入了Tensor Core(張量核心)專門加速矩陣運算,提升深度學習計算效率;支持NVlink 2.0,提高了數據傳輸速度,增強了多GPU協作能力,提升系統整體性能。Volta GV100具有5120個CUDA 核心和900GB/s的帶寬,加上640個張量核心,AI計算能力達到112 TFLOPS,比Pascal架構提高了近3倍。Volta的出現標誌着AI成為GPU發展的新方向。
緊隨其後,在一年後的2018年,英偉達發佈了Turing架構,進一步增強了Tensor Core的功能。Turing架構不僅延續了對浮點運算的優化,還新增了對INT8、INT4、甚至是Binary(INT1)等整數格式的支持。這一舉措不僅使大範圍混合精度訓練成為可能,更將GPU的性能吞吐量推向了新的高度,較Pascal GPU提升了驚人的32倍。此外,Turing架構還引入了先進的光線追蹤技術,新增了Ray Tracing核心(RT Core)。Turing TU102具有4608個CUDA核心、576個張量核心和72個RT核心,支持GPU光線追蹤,代表了圖形技術的新突破。
2020年,Ampere架構的推出再次刷新了人們對Tensor Core的認知。Ampere架構新增了對TF32和BF16兩種數據格式的支持,進一步提高了深度學習訓練和推理的效率。同時,Ampere架構引入了對稀疏矩陣計算的支持,在處理深度學習等現代計算任務時,稀疏矩陣是一種常見的數據類型,其特點是矩陣中包含大量零值元素。傳統的計算方法在處理這類數據時往往效率低下,而Ampere架構通過專門的稀疏矩陣計算優化,實現了對這類數據的高效處理,從而大幅提升了計算效率並降低了能耗。Ampere GA100 GPU具有6912個CUDA核心、108個張量核心和hr個RT核心,比Turing架構提高約50%。Ampere架構在人工智能、光線追蹤和圖形渲染等方面性能大幅躍升。
03英偉達全面引領AI時代
2016年,黃仁勳親手將第一台DGX-1超級計算機送給了OpenAI。而在2022年年底,OpenAI發佈了ChatGPT生成式大語言模型,其驚豔的自然語言處理能力成為深度學習發展歷程中劃時代的里程碑。而在這波AI革命中,英偉達作為“賣鏟人”,發佈了H100 GPU,憑藉着最新的Hopper架構,H100成為地表最強並行處理器。
H100是英偉達第九代數據中心GPU,集成了800億個晶體管,專為大規模AI和HPC計算而生。Hopper架構標誌性的變化是新一代流式多處理器的FP8張量核心(Tensor Core),這一創新進一步加速了AI訓練和推理過程。值得注意的是,Hopper架構去除了RT Core,以便為深度學習計算騰出更多空間。此外,Hopper架構還引入了Transformer引擎,這使得它在處理如今廣泛應用的Transformer模型時表現出色,進一步鞏固了英偉達在深度學習硬件領域的領導地位。
同時,NVIDIA Grace Hopper超級芯片將NVIDIA Hopper GPU的突破性性能與NVIDIA Grace CPU的多功能性結合在一起,在單個超級芯片中與高帶寬和內存一致的NVIDIA NVLink Chip-2-Chip(C2C)互連,並且支持新的NVIDIA NVLink切換系統,CPU和GPU、GPU和GPU之間通過NVLink進行連接,數據的傳輸速率高達900 GB/s,解決了CPU和GPU之間數據的時延問題,跨機之間通過PCIe 5.0進行連接。NVIDIA Grace Hopper超級芯片架構是高性能計算(HPC)和AI工作負載的第一個真正的異構加速平台。
2024年,英偉達推出的Blackwell架構為生成式AI帶來了顯著的飛躍。相較於H100 GPU,GB200超級芯片在處理LLM推理任務時,性能實現了高達30倍的驚人提升,同時在能耗方面也實現了高達25倍的優化。其中GB200超級芯片能夠組合兩個Blackwell GPU,並與英偉達的Grace中央處理單元配對,支持NVLink-C2C互聯。Blackwell還引入了第二代Transformer引擎,增強了對FP4和FP6精度的兼容性,顯著降低了模型運行時的內存佔用和帶寬需求。此外,還引入了第五代NVLink技術,使每個GPU的帶寬從900 GB/s增加到1800 GB/s。
英偉達的GPU架構經歷了一系列針對深度學習優化的重大創新和升級,每一次進步都在推動深度學習技術的邊界。這些架構的發展不僅體現了英偉達在硬件設計方面的前瞻性,也為深度學習的研究和應用提供了強大的計算支持,促進了AI技術的快速發展。
值得注意的是,去年英偉達CEO黃仁勳在接受採訪時表示,英偉達工程師正在開發接下來的兩代產品,“將按照一年一代的節奏完成”。此前,英偉達按照平均兩年一次的更新頻率升級GPU架構,對產品性能進行大幅提升。
明日,英偉達會如何刷新人們的想象,令人期待。