小小河:大模型,國家隊還是別玩了,省點錢_風聞
熊猫儿-52分钟前
大模型預訓練,國家級科研力量全部落敗,所有大學和中科院加在一起都不如100多人的deepseek。大模型推理看起來很簡單,deepseek把模型權重和技術細節、代碼全部開源了,下載下來,買幾台GPU服務部署一下就行了,立刻達到deepseek的技術水平。
實際上呢?做夢。
成功地運營deepseek服務,需要GPU服務器、模型權重、運維人員、知識庫、搜索引擎、變現模式,缺一不可。國家隊都有困難。
GPU服務器最容易理解,向英偉達定貨就行了,至於能不能拿到貨,就看人脈咋樣,出得起多少錢。Deepseek R1滿血版的參數是671B,權重文件是8位精度版,大小710GB。加載到內存裏轉為16位精度,推理質量最好,需要GPU顯存1420GB。每塊GPU的顯存為80GB,部署一套deepSeek R1至少需要18塊GPU。R1版是為大學生數學競賽級別難度的問題準備,推理慢,成本高。V3版適合簡單問題,大小跟R1版相同。
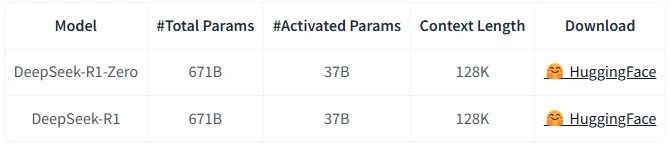
兩個模型各部署一套,需要36塊GPU,每個NVIDIA H100 80GB GPU價格按25000美元計算,共計90萬美元,約合653萬元人民幣。算上其它的硬件,成本算700萬元可以吧。
有人會説,部署量化版模型不行嗎?精度減少到原來的四分之一,成本也降到四分之一。或者部署70B參數的蒸餾模型,甚至最小的1.5B參數模型。打這麼多折扣,回答的質量會大幅下降,deepseek r1會淪為平庸的模型,有沒有就所無謂了。
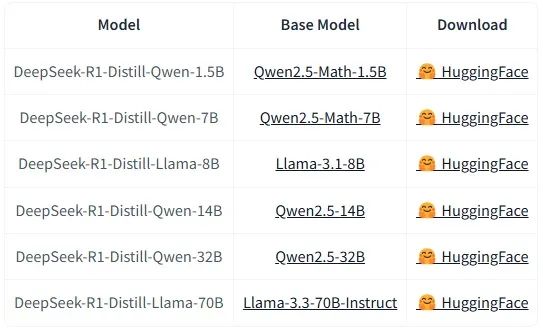
模型權重很容易獲得,有手就能下載,0成本。但要注意,AI大模型是當前科技領域競爭最激烈的賽道,沒有之一。每天都有新的技術進展,即使24小時學習,也永遠看不完。Deepseek R1只是短暫地領先了一個來月,不少指標已經被馬斯克的grok3和阿里的QwQ-32B超過去了。
像OpenAI和谷歌這樣的大公司的模型都閉源,不給你下載。像阿里的通義千問,也是部分開源,落後的開源,先進的留着自用。幾個月之後,投入重金部署的deepseek R1,比不過免費產品,有點尷尬。
運維人員貴,起碼要年薪百萬吧。國家隊、體制內,能開出這麼高的薪水嗎?
知識庫必不可少,光禿禿模型中包含的專業知識有限,必須搭配垂直領域知識庫,例如電視劇的劇情、明星的歷任女朋友、唐詩全集。互聯網公司每天都會生產大量垂直數據,建知識庫簡單。但高校這樣的單位,垂直數據很少,很難建起來大型知識庫。自有數據少,那隻好買搜索引擎的接口了。
按照bing搜索接口的價格,每搜索1千次價格18美元,約130.1184元,每次搜索0.13元。假設大模型每天的訪問人次是100萬,那麼搜索成本是每天13萬元,一年4745萬元。假設deepseek大模型響應每次提問的平均計算時間是3秒(深度思考其實要長得多),那麼需要部署35套模型(1000000*3/24/3600),對應的硬件成本是1.225億元。搜索成本加上硬件成本,一年1.6995億元。
如果只部署1套deepseek R1和1套deepseek v3,那麼每天能支持2.88萬次提問(3600*24/3),每天搜索成本3744元。這麼少的提問量,直接用免費的deepseek不好嗎?
最後一個是變現模式,最難。如果下定決心要做大做強,投入1.7億運營大模型服務,那麼就得考慮賺錢,起碼要回收成本。這個時候,國家隊面對就是deepseek、豆包背後的字節跳動、通義千問背後的阿里、元寶背後的騰訊,競爭得過嗎?虧掉的錢怎麼辦?虧就虧了?
2007年5月,中國移動推出飛信,投入巨大,發短信免費,佔盡先機。2011年1月21日,微信才上線。現在飛信已經下線3年了,僅公開的投資就有30億元,全打水漂。2010年6月,人民日報旗下的國家隊“人民搜索”上線,鄧亞萍掛帥。2013年11月1日,錢花完了,人民搜索下線。
N多事例證明,在互聯網行業,在科技行業,在公平競爭的行業,在不需要行政壟斷的行業,國家隊不行。弄個小的蒸餾模型,蹭點熱度,刷點業績掙點獎金,完全理解,支持。但腦子一熱上滿血版,真心不建議,不折騰就是省錢啊,為全國的打工人省錢。做點好事,別玩了。