可靈2.0文生視頻發佈:10塊錢5秒,但效果值得_風聞
知危-知危官方账号-16分钟前
就在今天下午兩點,快手正式發佈了可靈 2.0。
作為國內文生視頻的口碑一哥,可靈生成的 AI 視頻在各大視頻平台都被創作者們廣泛應用,這次的升級發佈會吸引到了很大的關注。
從昨天官方發出的預告片就基本可以猜出,可靈 2.0 主打運動能力。
果不其然,在可靈 2.0 更新後,官方也如此解釋:可靈 2.0 的優勢在於高質量運動和指令響應。
於是,知危編輯部速速搞了一個黃金會員來試玩。
一開始,編輯部真的被可靈 2.0 的費用驚到了:一個 5s 的片段,竟然就要 100 靈感值。要知道,可靈文生圖最高清的只需要 1 個靈感值一張,可靈 1.6 的 5s 視頻只需要 35 靈感值,新版足足貴了 2 倍。換算成人民幣,可靈 2.0 一個 5s 視頻大概 10 塊錢。
當然,貴不一定是它的問題,如果生成結果足夠好,也就值了。
參考可靈 2.0 發佈會中強調的重點,我們主要測試了可靈 2.0 的這些特點:運動速度、運動幅度、複雜運動、時序響應、多模態編輯。
我們根據每個特點測試了 1 到 2 個視頻,然後看每個視頻能不能體現這些基礎特性:指令遵循、電影美學、精準風格化等。
首先是運動速度和運動幅度,我們來測試一個跑車場景。
參考圖:

提示詞:
跑車在蜿蜒道路上高速行駛,偶爾過彎時輪胎打滑,攝像機從空中移動到車輛後方追蹤沿海公路上行駛的跑車。
相機從空中持續追蹤跑車,與車輛背後保持 5 米距離,保持車輛在畫面中心。
道路兩側景觀快速後退,海面波光粼粼。
汽車廣告電影風格,景色壯觀,色彩鮮明,動感強烈。
生成結果如下:

這個生成結果不算差,但在這麼卷的 AI 視頻賽道里,這個結果也就中規中矩,跑車速度不夠快,沒有高速行駛的動態感,像是飄在公路上,背景變化幅度小,汽車表面的光影效果也一般,最後是沒有按照提示詞第一句將鏡頭做轉移。
有可能是提示詞過於複雜了,讓 AI 手忙腳亂。我們換一個場景,測試第一人稱視角的過山車場景。
參考圖:

這次把提示詞寫得簡單些:
過山車列車先爬上高點,然後從高點開始急速下降,車廂隨軌道高速移動。
第一人稱視角,相機飛行在半空中,跟隨過山車後方全程運動。
刺激遊樂設施體驗風格,色彩鮮豔,畫面快速運動感強,高清晰度,陽光照射產生閃光效果。
生成結果如下:

這次的結果很不錯!不僅實現了先升再下降的高速大幅度運動,遠處的景觀比如比如藍色海盜船、紅色屋頂小房子、摩天輪都以合理的方式拉近了物理距離。當然手稍微有點小崩,可以理解,瑕不掩瑜。
我們再換一個場景,測試電影中常見的追逐場景。
參考圖:

提示詞:
主角穿越賽博朋克世界的鬧市進行追逐,背景環境不斷變化。
主角奔跑速度均勻,不時回頭,表情緊張。
相機保持與主角相同速度跟隨,略微搖晃增加緊張感。
場景從擁擠市場變為狹窄小巷,再到開闊廣場,人羣散開。
動作電影風格,節奏緊湊,色調對比強烈,光影變化明顯。
生成結果如下:

這個效果也很棒,除了主角運動速度很快之外,還展了背景運動的大幅度變化。在主角回頭和轉身瞬間的背景模糊,和回頭後的場景的切換,都很有電影的感覺。不過有個有些滑稽的小缺點是,提示詞中只是讓主角 “ 不時回頭 ”,結果他卻直接轉身了。
追逐戲只有一個人怎麼夠刺激,再加一個。
參考圖:

提示詞:
兩名未來戰士在霓虹長廊裏前後追逐。
前方戰士快步疾跑,後方戰士窮追不捨,動作緊張有序。
鏡頭不斷變換焦點:先對準前方逃跑者,再聚焦後方追擊者。
環境光線閃爍,節奏感強烈,但場景本身保持相對穩定。
寫實電影質感,展示快速視角切換帶來的逼真動感。
生成結果如下:

這回真的翻車了,沒有實現焦點的切換,可靈 2.0 還給前面的戰士賦予了 “ 電子穿梭 ” 的能力,穿梭的戰士又從後方的戰士出現,一時間不知道誰在追誰。可能模型對 “ 未來戰士 ” 的理解就是會有這樣的超能力,視頻乍一看有些怪,細看你別説還有點像某種刻意的設定……
要體現速度,也許只靠人工動力還是太渺小了,得藉助萬有引力的力量。
我們再換一個測試場景,看一下山坡能帶來多大的速度感。
參考圖:

提示詞:
專業滑雪者從雪山頂峯滑下陡峭斜坡,速度超級快。
滑雪者身體前傾,雙腿靈活控制方向。
相機從滑雪者後方跟隨下滑,保持適當距離,偶爾切換到側面。
滑雪道兩側雪松輕微搖晃,雪花隨風飄動。
冬季運動廣告風格,明亮雪景,藍白色調為主,陽光反射效果。
生成結果如下:

效果還是不錯的,滑雪的速度有逐漸變快,雪橇踩過的雪花飛濺效果挺合理,遠景變化也沒毛病。遺憾的是,知危沒捨得花 200 靈感值來生成 10s 的視頻,不然速度肯定能更快。
山坡釋放的萬有引力勢能還是有限,我們到天上去。
參考圖:

提示詞:
跳傘者從高空飛機跳出並自由落體。
相機從跳傘者視角轉為外部觀察視角,跟隨自由落體過程穿過雲層。
雲層迅速接近,地面景觀從模糊變得清晰,風吹動衣物。
極限運動紀錄片風格,高清晰度,大場景展示,視覺衝擊力強。
生成結果如下:

非常神奇,跳傘運動員先是消失,然後在穿過一朵雲之後又出現,疑似發生了 “ 量子隧穿 ” 現象。
不過,這裏要中肯的説一句,編輯部內部反思了一下,我們的提示詞可能表述的不夠好,讓模型誤以為 “ 最開始畫面看跳傘者的人,也是一個跳傘者 ”,這樣生成的視頻的狀態就可以合理解釋了。
測試完了運動速度和運動幅度,接下來我們看一下複雜運動,這一維度主要針對主體本身的動作是否足夠複雜多樣。
比如,我們可以讓這個小哥來跳一跳專業的機械舞,把動作都設定好。
參考圖:

提示詞:
一位街舞舞者站在城市廣場上。
首先,他迅速做出一個機械舞的定格動作,關節鎖定;然後立即過渡到一個波浪式的胸部和手臂律動;最後馬上完成一個下蹲後彈跳並做出定格手勢的動作。
保持Hip-Hop節奏感和街舞特有的力量感。
相機初始保持中景拍攝,隨後在波浪動作時輕微環繞舞者,最後在彈跳動作時切換為微慢動作並適當拉近,捕捉定格瞬間。
色彩對比鮮明,舞者動作線條清晰,重要動作環節有輕微強調效果,整體節奏感強。
生成結果如下:

小哥確實展現了很多個街舞動作,主要在後半部分,比如提示詞提到的手臂律動、下蹲後彈跳、定格手勢,運鏡上展現了先環繞再拉近然後慢動作的效果。缺點就是觀感上和機械舞沒啥關係,甚至也不怎麼像街舞。可能給主體安排了過多的動作,AI 也見招拆招學會 “ 偷工減料 ” 了。
我們再加大動作難度,安排兩個舞者來跳探戈舞。
參考圖:

提示詞:
一對專業舞者在舞台上表演激情探戈舞。
舞者從靜止姿勢開始,展開一系列協調精準的舞步。
相機在舞者周圍環繞,時而靠近時而遠離,捕捉動作細節。
舞台燈光隨舞蹈節奏變化,背景燈光閃爍。
舞蹈電影風格,動作流暢精準,情感表達強烈,燈光戲劇化。
生成結果如下:

雖然看起來會有很多槽點,但忽略女舞者在轉身的時候有點過於 “ 着急 ”,總體來看舞者的動作還是很優美而專業的,運鏡也沒毛病。通常來説存在兩個主體交互的場景出錯概率都很大,至少這個案例中要接近完美已經不遠了。
複雜運動測試完,我們再看看可靈 2.0 的時序響應能力如何,時序響應即按照指令一個接一個地執行的能力,知危主要測試了做飯的場景,並直接進行了文生視頻的操作。
提示詞:
一位女廚師站在現代化廚房的料理台前,料理台上放着西紅柿,雞蛋,調料瓶,平底鍋,油,爐子等,平底鍋已經放置在爐子上加熱。
她迅速拿起一個西紅柿開始切片;
然後立即將切好的西紅柿倒入平底鍋中;
最後她馬上拿起旁邊的調料瓶往鍋中撒調料。
整個動作序列必須在5秒內流暢完成,沒有中斷或停頓,動作之間的轉換自然連貫。
生成結果如下:

額,看起來廚師拿起西紅柿沒有切,而是當成雞蛋一樣敲碎了放進去,然後在放調料的時候因為瓶蓋太緊了沒來得及打開時間就結束了。
或許我們的要求太苛刻了,要完成這些動作只用 5s 還是太緊張了,那就咬咬牙,給廚師 10s 的時間吧。我們來看看結果如何:
比之前好了一些,但是手撕番茄的毛病還是沒改,那調料瓶的時候調料瓶抽搐了一下,但是時序上的遵循確實是沒毛病。不過我們認為可能是我們短時間內要求的動作太多了。為了讓可靈 2.0 更好地完成順序指令,建議動作還是少一些,簡單一些。
最後,我們測試一下新版中比較有趣的多模態編輯功能。這個功能類似於 Gemini Flash 2.0 和 GPT-4o 的局部編輯功能,只不過這一次是視頻,複雜度更高。多模態編輯不支持使用可靈 2.0,我們用可靈 1.6 來測試。
借用推特網友的現成視頻( 基於可靈 2.0 ),我們來做個微調。
首先是這個網友製作的摩托車越野的場景:
我們用下圖中的摩托車來替換原來的摩托車:

在 “ 替換元素 ” 選項下,先標記你需要替換的區域,基本上點擊一個摩托車的關鍵點,可靈就能識別出你要修改的是摩托車。
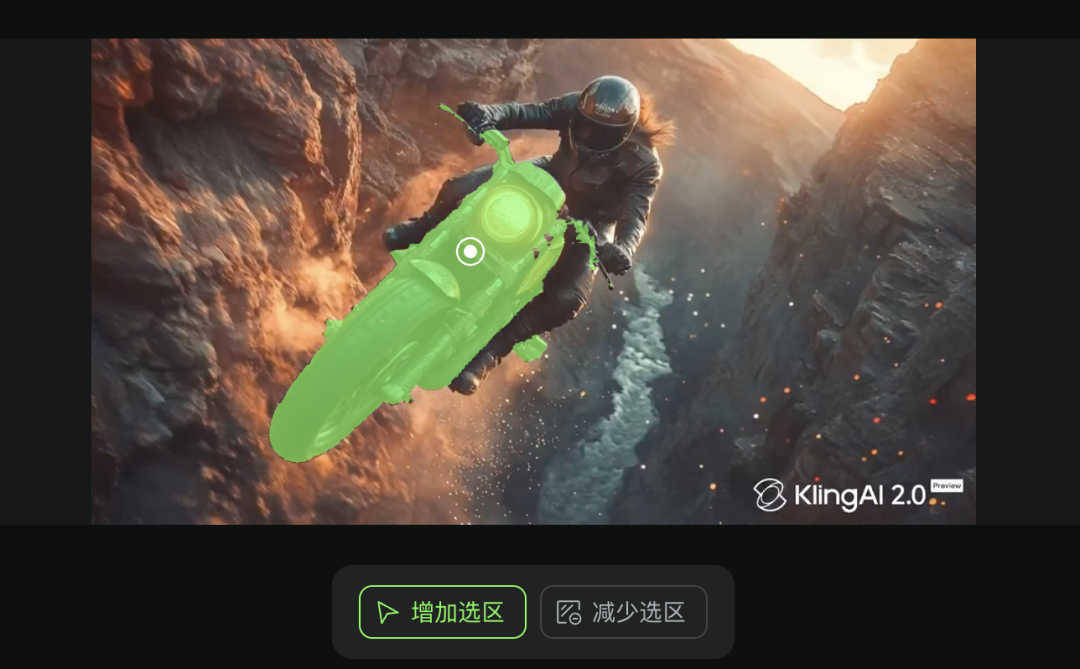
另外,多模態編輯的提示詞格式也很有趣,為了讓指代更加精準,提示詞已經不是純文本的形式了,而是結合了圖像和文本元素的語句。
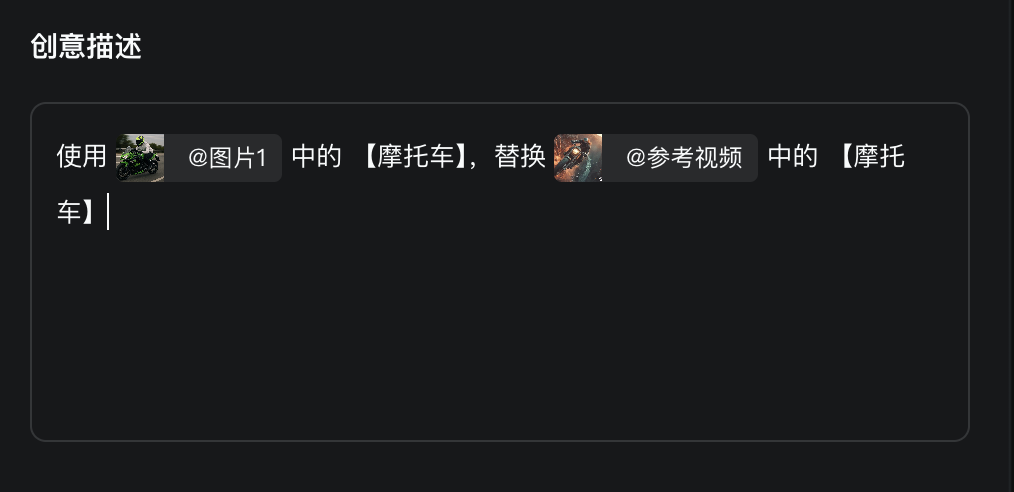
生成結果如下:
動作一致性是很高的,就是 AI 順道把頭盔和衣服也換過來了。
我們再換一個視頻,這次採用 “ 增加元素 ” 的編輯方式。
這次是一個摩托車極限跑酷的場景:
視頻有 10s,但多模態編輯只支持 5s 視頻,就裁剪為一半,然後融入這個元素:

提示詞:
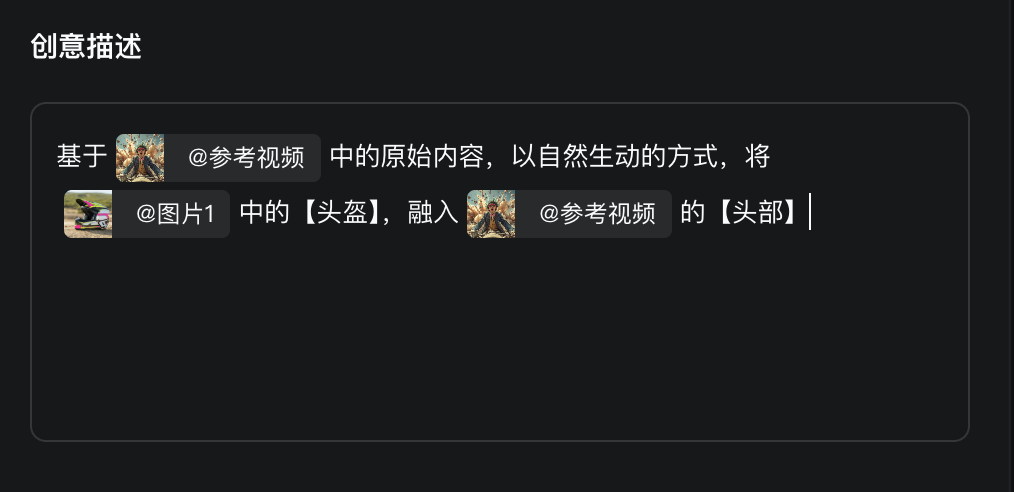
生成結果如下:
頭盔完美地戴上了,整體一致性也很強,就是運動員身體動作和背景動態都有些收斂了。
好了,測試完畢。
總體來看,可靈 2.0 還是有很多可圈點之處的,特別是運動效果和多模態編輯。比如背景變化能保證合理性和大幅度,單主體運動成功率比較高。指令遵循雖然不會 100% 成功,但實現的指令密度還是挺高的。也帶來了不少的意外驚喜,比如追逐戲中小哥的回頭瞬間,探戈舞的動作標準度。
雙主體乃至多主體運動是很有潛力的,只是失敗率太大的話,會很費錢。多模態編輯倒是能給你省省錢,畢竟一次只需要 50 靈感值,而且提示詞的設置精準度很高,這一點值得給個大讚。
多模態編輯生成結果的運動、動態、外觀有較高的一致性,細節上的偏差在所難免。至於時序響應,他的確遵循了時序,但是動作翻車了,不知道是不是我們短時間安排的動作太多了,導致有些翻車。
對了強調一下,知危的測試不代表可靈 2.0 的平均水平,本次整體安排的測試案提示詞給的都比較複雜,相機的變化幅度太大。你可以理解為針對新特性的一種極限測試,如果你稍微降低一些要求,效果會好不少。
最後提醒一下,如果你在生成時發現 5s 視頻能帶來不錯的效果,那麼可以嘗試再生成一個 10s 的,可能有驚喜。如果 5s 視頻效果差,也可能是時長不夠,AI 來不及完成,如果有 10s 完成概率就大得多,非常建議嘗試。
總之,中肯地講,10 塊錢換這樣的 5s 視頻,還算是值得的。