杜駿飛 | 奇幻社會的來臨——DeepSeek幻覺與後真相遞歸_風聞
探索与争鸣-《探索与争鸣》杂志官方账号-12分钟前
杜駿飛|南京大學新聞傳播學院教授
本文原載《探索與爭鳴》2025年第3期
具體內容以正刊為準
非經註明,文中圖片均來自網絡

杜駿飛
DeepSeek-R1的出現,固然在使AI產業經歷其“蒸汽機時刻”,但與此同時,R1所代表的推理模型也帶來了一種“幻覺時刻”。
為了判定這一事實,我們來觀察一下主流AI的幻覺數據對比。在AI評估組織Vectara今年3月4日公佈的大語言模型(LLM)幻覺排行榜上,DeepSeek-R1的幻覺率達到了14.3%,這一數據遠高於其V2.5版本的2.4%,而Google Gemini-2.0-Flash-001、Google Gemini-2.0-Pro-Exp、OpenAI-o3-mini-high-reasoning三款幻覺率都低於1%,GPT-4o的幻覺率為1.8%,阿里Qwen2.5-7B-Instruct的幻覺率則為2.8%。
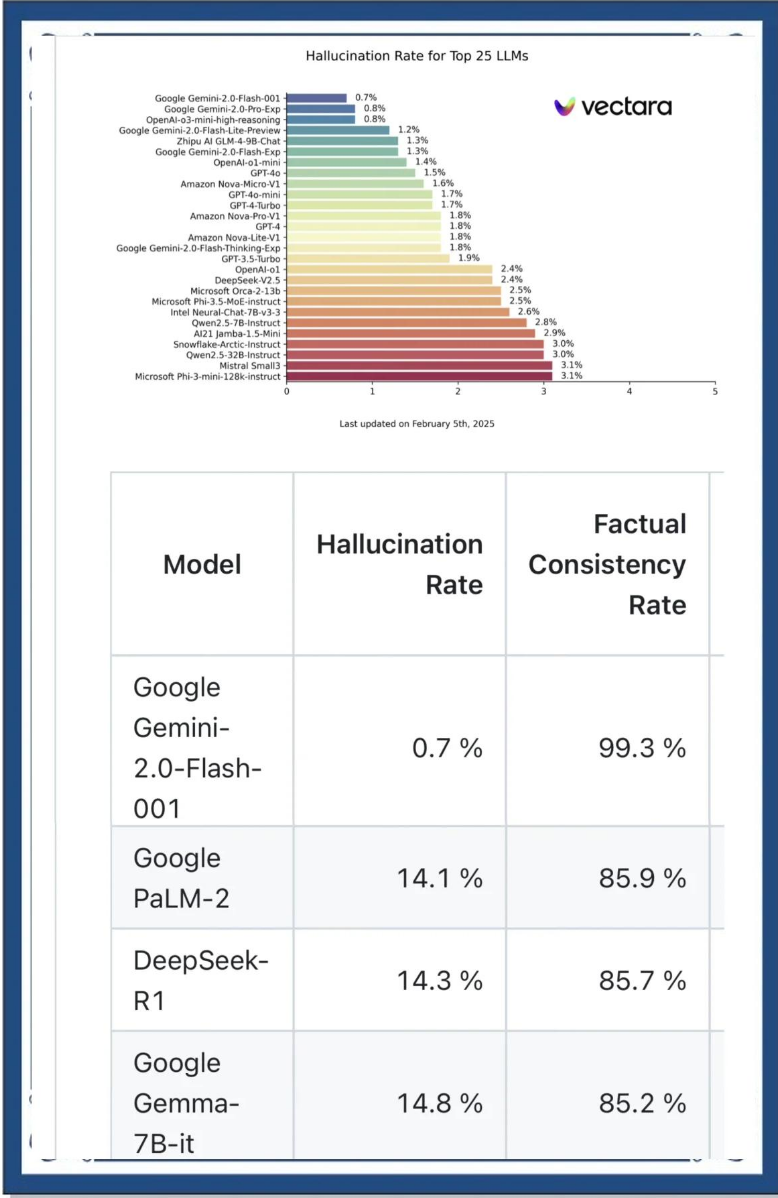
AI評估組織Vectara公佈的大語言模型(LLM)幻覺排行榜
一如許多用户體驗報告所説, R1的確展現出非凡的“思考”能力和流暢對話的能力,目前已被國內外各大平台、各類垂直應用廣泛接入。不過,**R1的推理泛化能力不是沒有代價的,其代價之一便是幻覺流行。**上述所謂幻覺排行榜,形象地説,就是AI避免胡編亂造可能性的排行榜。R1在這一榜單上落後較多,從學術上來説,14.3%的幻覺率,即意味着它平均每7次生成就會有1次幻覺。這不能不使人追問:當DeepSeek的普遍應用遇到R1的高濃度幻覺,這二者疊加的後果是什麼?我的答案是:這一後果極可能溢出AI對話的科學性問題,而抵達更深刻的社會病症。
具體來説,這裏存在着一種 “奇幻社會”的危機:當一種基於神經網絡的推理模型,具有強大的語言生成和上下文感知能力,但可解釋性差、對訓練數據的依賴性強,且後訓練不足時,我們將看到一種AI 幻覺事實氾濫的可能;在一定的社會條件下,人機協同網絡會基於用户需求不斷調用不真實的內容,形成遞歸的內容流,而這將是一個被想象與幻覺所支配的傳播維度;在這一維度上,後真相觀點實際上是更容易遞歸的,而那些廣泛而嚴密的虛假內容則可能危害集體記憶,損害社會的現實感,並延及人類自身。
幻覺及其遞歸問題
AI不能避免幻覺,這不是一個新問題。迄今為止,LLM所依賴的生成機制是“端到端”( E2E),即從輸入到輸出。在機器學習和人工智能的結構中,“端到端”系統直接從原始數據生成最終結果,省略了可見的過程性。也因此,端到端的AIGC被視為“智能黑箱”。
誠然,“端到端”簡化了系統設計,降低了複雜性,依賴大量高質量數據訓練模型,也減少了對人工規則的依賴。但這些因素也必然使得模型的判斷、推理和決策容易出現錯覺和誤差。與此同時,“智能黑箱”也使得AI所生成的內容既缺乏透明性,也缺乏可解釋性。當它輸出真相(準確或真實的信息)時是如此,當它輸出幻覺(不準確或虛構的信息)時,也是如此。
AI幻覺現象在LLM的對話應用中尤為常見,其原因不外乎以下三種。一是訓練數據的侷限。例如,我們可以觀察到,R1在英文世界裏的對話可信度似乎要略高於它在中文世界。二是模型設計的侷限。LLM都基於概率生成內容,這也意味着它並不保證準確性。實際上,**R1的“思維鏈”因更傾向於形成完整的思考過程而可能編造論據。**三是複雜性與不確定性問題。尤其是在開放域任務中,LLM更容易生成不準確的內容,並向人類用户輸出幻覺。
為求驗證,我讓DeepSeek-R1自我評估其幻覺風險水平,它的回答可以概括如下。在事實性問題上,R1的高風險領域是時效性信息(如新聞、科技進展)、小眾領域知識(如冷門歷史事件)。例如,若你問“2023年諾貝爾經濟學獎得主是誰”,R1能準確回答,但若問“2024年某國經濟增長率”,答案則可能不準確。在複雜推理與專業領域,R1的中高風險領域是法律建議、醫療診斷、金融投資建議。例如,若用户問“我的症狀是否代表癌症”,R1的回答可能遺漏關鍵診斷條件,導致誤診。
真正的問題在於,那些高產幻覺的AI應用並不總會遇到具備良好判斷力的用户。如前所述,DeepSeek的普遍應用與高濃度幻覺,這二者疊加的後果是,不真實的內容會被重新上傳到人機交流網絡,填入飢渴的數據池——成為新的中文語料庫。
在這裏,我們主要討論被動幻覺,而未談及人的刻意造假。實際上,人利用AI生成的深度偽造(deepfakes),早已成為當今數字領域的普遍挑戰。2023年,全球排名第一的身份犯罪類型正是AI欺詐(AI-powered fraud)。
考慮到人性中的需求更多地分佈於慾望、情感,而不在事實上,我們或可以判斷:當AI幻覺匯入遞歸計算時,謊言驅逐真相是可能的。
AI幻覺症候羣
這裏所討論的是AI幻覺的遞歸影響,準確地説,是指**由AI生成的虛假信息被其他AI系統、平台或用户反覆引用、傳播和強化,形成自我循環的錯誤信息網絡。**幻覺的遞歸可能導致錯誤信息在多層級、多維度中被持續放大,對社會造成系統性衝擊。
**首先是信息生態系統的污染問題。**例如,一名美國律師使用ChatGPT生成的虛構法律案例提交法庭,險些逃過司法鑑定。不難想象,假如它作為判例再被其他法律AI收錄,可能會污染法律知識庫(如LexisNexis),形成“虛假先例”的遞歸鏈。
**其次是搜索引擎與社交媒體的“錯誤正反饋”問題。**用户將AI生成的虛假內容發佈到互聯網後,可能被搜索引擎索引並提升權重,如果它虛假注引來源,還會被其他AI系統抓取為“權威數據”。例如,2022年,一篇由AI生成的“量子計算機破解比特幣”的虛假文章被多個科技媒體轉載,引發加密貨幣市場的恐慌性拋售。
實際上,我們可以為當下命名一種“AI幻覺症候羣”,它的典型社會症狀包括但不限於:一是假新聞(因為AI幻覺能提供賣點,更契合流量邏輯);二是偽知識(因為AI幻覺能提供符合人慾的信息,更容易欺騙低科學素養人羣);三是學術不端(因為AI幻覺能協助人急功近利,以適應無序的學術環境);四是誹謗信息(因為AI幻覺能提供尖刻、惡俗的攻擊,在一個不良的社會土壤中,它如魚得水,且無往不利);五是金融謠言(因為AI幻覺能為金融產品輔助營銷,並且金融流言及其受害者之間存在着強大的相互選擇性);六是不實宣傳(因為AI幻覺能提供產量驚人、不顧事實的文本,更容易滿足人的虛榮心)。
要言之,AI幻覺症候羣建基於AI自身的技術缺陷,建基於AI傳播的不可逆的遞歸性,建基於當前特定的AI文化與數據環境,建基於大規模用户的AI輔助內容生產,也建基於大批社會公眾的低用户屬性。
要強調的是,這裏的幻覺往往體現為精心構造的邏輯和專業詳實的數據。一些AI對話為了滿足用户的需要,不惜“引經據典”,這很容易讓用户以謊言為真。例如,有用户用自己本地部署的DeepSeek-R1查詢“閘北區的哪吒弄堂在哪裏”,R1稱這條弄堂在共和新路上,命名來源於神話人物哪吒,並且給出了生活環境、文化氛圍等信息;甚至,當用户使用官方網頁打開搜索功能,會得到類似的結果。同樣,假如你要求R1為自己寫小傳和述評,只要稍加一點提示,R1便會滿口諛辭,編造不存在的人生功績——諷刺的是,這些人機共生的非真實信息也都會被上傳到互聯網,成為新的 “數字記憶”。
或許你會認為以上案例無傷大雅,但是,請設想一下,假如有更強大的主體將以上幻覺案例替換為政治、法律、歷史的重大議題呢?毫無疑問,只要AI不革除幻覺,只要我們人類用户仍偏好幻覺,那麼虛假的新聞、傳記、判例都會比單純的事實更容易匯入遞歸鏈。
這也就是為什麼我們説謊言驅逐真相是可能的。因為遞歸效應的存在,非真實信息擁有無限鏡像,而後真相(post-truth)則被海量生成。
後真相與事實末世
看起來,在一個AI輔助交往的時代, AI幻覺比社交媒體和算法推薦系統更可能激發後真相。一個典型的案例是關於“‘80後’死亡率”的新聞,它聲稱“截至2024年年末,‘80後’死亡率突破5.2%,相當於每20個‘80後’中就有1人已經去世”。然而,這一數據與事實嚴重不符。中國人民大學教授李婷指出,其源頭可能為“AI運算偏差”。她在AI大模型中輸入了關於不同年代人口死亡率的問題,大模型根據網絡信息得出了包含“80後”死亡率的錯誤數據。這是典型的AI幻覺問題,而且,以我之見,它還是植根於階層情感需要的遞歸性偏差。
以下,我將從後真相的常見表徵出發,進一步討論AI幻覺激發後真相的內在機理。
**後真相的表徵之一,是在公共輿論和政治討論中,客觀事實對公眾意見的影響力減弱,而情感、個人信念和主觀感受的影響力增強。**而恰好,AI幻覺長於迎合用户的情感和傾向性。
**後真相的表徵之二,是公眾對傳統媒體、政府和科學機構的信任減弱,更依賴個人經驗。**AI對話作為強應用,現在已足以取代搜索引擎和知識社區,久而久之,它或將成為一個更強大、更貼心、更個人化的智能體。顯然,慣於依賴AI尋求結論的粉絲,往往不是傳統媒體、政府和科學機構的用户羣。所謂智能即霸權,正是從人們對於AI(包括其有用的幻覺部分)的無條件依賴開始的。
**後真相的表徵之三,是人類認知中存在確認偏誤,傾向於接受支持己方觀點的信息,這也是社會分化和身份政治使然。**與其他AI對話應用相比,R1更善於迎合用户,它對身份政治的強化,實則是為了更好地貼合用户基於身份認同的偏好。
**後真相的表徵之四,是社交媒體和算法推薦系統是後真相現象的推手,它們強化了用户的既有觀點,形成了“迴音壁”效應。**商業屬性決定了AI主流應用不僅是供給所需,而且要迎合人慾。因此,AI幻覺也將成為最好的精神消費品,無疑,它有望成為最為個人化的“迴音壁”。
**後真相的表徵之五,是時代恐慌導致虛假信息和陰謀論,並因其更容易擴散而削弱事實的影響力。**頗多AI幻覺是因簡化推理所致,當它一味追求服務於用户心理時,標籤化和陰謀論將很適合人機共生。
如果説後真相揭示了現代社會中情感動員對真相的遮蔽,那麼我們可以認為,不加節制的AI幻覺也將促使用户進一步地自我遮蔽。如果説後真相體現了賽博空間中認知秩序的異化,那麼我們可以認為,AI幻覺將進一步扭曲人羣對外部世界的集體意識。如果説後真相的本質是信息傳播邏輯在數字時代的結構化轉型,那麼我們更可以認為,作為強應用的AI幻覺,將憑藉其高滲透率和高説服力引發社會的結構性扭曲。
2023年,馬里蘭大學的馬修·柯申鮑姆在《大西洋月刊》發表文章,提出文本末世(textpocalypse)論,用以定義一場可能由大語言模型和生成式人工智能技術帶來的文本災變。對照柯申鮑姆的這一理論,我們要問的是,在通過調整温度參數、一味追求流暢對話的邏輯下,AI幻覺的遞歸是否將加速這個後真相的世界,並讓我們前行至一個事實的末世(factpocalypse)?——在那裏,謊言、假新聞、人性弱點和機器幻覺將相互激發,削弱人對於事實和可信世界的承認。
從景觀社會到奇幻社會
設想一個這樣的未來:LLM始終未能消除幻覺,而AI用户習慣於消費幻覺、利用幻覺甚至創建幻覺,作為國民應用的AI則持續地協同人生產後真相,那麼,一個“奇幻社會”(the society of the fantasy)便會來臨。
我使用 “奇幻”一詞,是為了與居伊·德波的“景觀”(spectacle)對應。1967年,德波提出了景觀社會(the society of the spectacle)理論, 其思想植根於馬克思主義的異化理論、盧卡奇的“物化”概念以及法蘭克福學派對資本主義的批判。該理論的後續影響,則直抵凱爾納的媒介奇觀論以及鮑德里亞的擬象論。

這裏,我僅結合以上討論,就奇幻社會論與景觀社會論的異同作一提綱挈領的辨析。景觀社會論認為,資本主義社會從“商品堆積”轉向了“景觀堆積”;而奇幻社會論意在指出,智能時代從可視的“景觀”轉向想象的“奇幻”。景觀社會論認為,資本主義社會從商品拜物教發展到景觀拜物教;而奇幻社會論意在指出,智能時代從景觀拜物教發展到奇幻拜物教。景觀社會論認為,所謂景觀社會,是“少數人表演、多數人被動觀看”;而奇幻社會論意在指出,所謂奇幻社會,是“所有人變造、所有人遵照”。景觀社會論認為,景觀社會通過“偽循環時間”(如人為的週期性消費節點) 割裂真實體驗;而奇幻社會論意在指出,奇幻社會通過“AI現實”扭曲真正的現實。
我想借此説明的是,**“奇幻社會”所帶來的一系列問題,既是數據源危機,也是文化、生活、社會信任危機,更是哲學危機。**究其原因,它與AI幻覺的社會症候羣密切相關。也因此,在本題之下,我們不得不溯源至一些技術問題,例如推理模型的泛化,蒸餾模型的簡化,AI應用快速擴散的規模化問題,以及遞歸效應帶來的奇幻病。
以下,試對“奇幻社會” 的發生機制作一完整的闡釋。第一,在人工智能的強應用時代,AI不斷生產內容,也不斷自我調用,人機交流網絡又將生成內容反覆發佈,在跨平台和多模態意義上形成了一個無限遞歸的內容流。第二,一部分AI內容流來自AI幻覺、人為編造以及AI對用户的迎合,由此,AI實際上驅動了被想象與幻覺支配的奇幻傳播。第三,這種奇幻傳播的機制具有自反性和自我強化性。正像後真相可能遠比真相更受歡迎一樣,迎合人性的偽事實、非事實甚至反事實,都可能因其可被建構而比事實有更高的流通效率。第四,一旦相當多的奇幻感知替換現實感知,相當多的奇幻內容替換真實內容,那麼數字記憶的根本性變化便將發生,一個由AI機制所加速的奇幻社會也將來臨。君不見,如今大量作為謊言的AI幻覺正言之鑿鑿,大量人機共謀的虛假言論也正風行一時,而它們的共同之處是:因被喜聞樂見而歷久彌新。
AI仍處於其史前時代,奇幻社會只是技術未來的一種可能。正因為如此,我們才要及早預見其危險的後果:不真實的信息、事實、知識、律令為人所信,為人所行,並因遞歸而不可逆,而這一切都終將長久地影響人類生存——從認識論到實踐論。