AI的下一步,是從模型裏偷知識_風聞
酷玩实验室-酷玩实验室官方账号-1小时前
6500萬美元,是外界估算的GPT4訓練成本,這只是使用GPU的費用,還不包括人工等。
557萬美元,是DeepSeek-V3的訓練成本,同樣只是GPU費用,但在效果上,不僅可以按着GPT4的頭打,也順道超過了GPT4-Turbo和GPT4o這兩個繼任者。
50美元,是AI教母李飛飛團隊的做出s1模型的成本,不僅成本低,性能還強,據説它的數學能力已經可以媲美DeepSeek-R1。

我看了下閒魚,H100的租賃價格已經降低到了20塊,如果按照這個價格,現在只需要170人民幣,就完成了s1的微調,隨着芯片更新,這個數字還會越來越低。
被媒體誤讀,但是主流
50美元就能做出媲美DeepSeek-R1的大模型,不是哥們,現在的大模型門檻這麼低了嗎?我少吃一頓燒烤,就能訓練出一個比肩DeepSeek的大模型?

這是又一次的"AI炸裂體"的表演,還是説大模型的進化速度,已經比特朗普加關税還快了?


當我仔細看完這篇論文後,這應該是又一次“AI炸裂體”的勝利。事實上,50美元並不是什麼訓練的成本,而是它們基於阿里Qwen2.5-32B微調出的s1的費用。
具體怎麼實現的呢?它們先從58000個來自16個領域的問題中,精挑細選出1000個,然後用交給谷歌的Gemini Flash Thinking推理模型,然後把這些問題以及思考的過程,作為微調的數據,投餵給Qwen,最終讓一個普通大模型,點開了推理技能樹。比如下面這個回答,你可以看到,針對“raspberry中有幾個r”的問題,它經過多輪思考後的,給出了正確答案。(s1還有讓模型強制思考的技術創新,這裏因為篇幅,不做展開)

用人話講,李飛飛的團隊就是把一道預製菜,重新回鍋調味,做出了堪比私房菜的味道!説它們自己從零開始,用5毛錢,買點爛菜葉子,做出一道佳餚,的確是有點過於"震驚"和“炸裂”了。
蒸餾,主打一個省錢
蒸餾不是啥新鮮事,大家熟悉的DeepSeek-R1在發佈時,官方團隊同時也準備了許多自己蒸餾的模型。經過蒸餾的模型,效果都得到了很大的提升。
它們採用Qwen系列作為基底模型,通過蒸餾的方式,讓320億參數的小模型,就達到遠超OpenAI的o1-mini的效果。
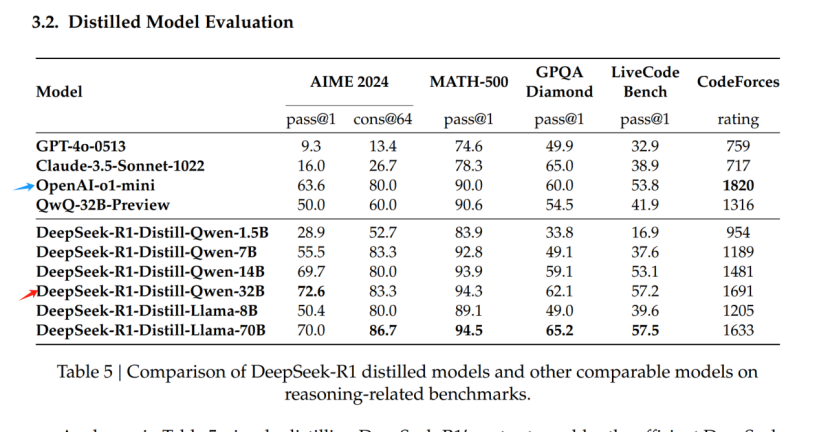
這是啥概念呢?就你手裏4090的顯卡來説,它足以輕鬆跑動DeepSeek蒸餾出的320億的量化模型,也就是説,4090不僅能幫助你以影視級通關黑神話,還能每個月幫你省出20美元的OpenAI會員費。
什麼你手裏沒有4090?很好,讓我們一起説出那句經典的台詞:Nvidia xxxx You。

對於行業內的用户來講,蒸餾帶來的好處,要比這20美元多得多。要知道,隨着模型的參數逐漸增多,它的使用成本也隨着水漲船高。
6710億,是DeepSeek-R1的參數量,要運行它,至少需要配備8張H100顯卡的服務器,按照現在的市場價,成本大概在200萬左右,但如果用蒸餾過的模型,就像前面説的,4090就行,如果追求回答的精度和併發數,1張H100也足夠應付了,整體成本不會超過20萬。
比如我想創業,創辦一個戒色網站,需要一個聊天機器人,不僅用來回答戒色網友的各種疑問,還需提出可執行方案,如果用6710億參數的版本,可能一次回答需要耗費2塊錢,而用蒸餾過後的模型,只需要2毛錢,成本就是差這麼大。
而創辦戒色網站的另外一個問題是,我需要讓大模型給出的回答,要有自己的特色。
一般情況下,這需要大量的人工來清洗數據,然後對模型進行微調,一個流程走下來,也是一筆不小的花費。

調整模型是目前的主旋律
可以看到,在AI大模型狂奔了3年後,蒸餾+微調已經取代參數,成為了當下主需求。
打造一款像DeepSeek這樣的模型很難,但調整模型也一點都不簡單。除了需要有一個專門數據清洗,整理團隊,還要有專門的模型工程師團隊,入門的門檻很高了。
不過就在剛剛結束的Create大會上,百度智能雲千帆模型開發平台全新升級,在模型服務層面,目前千帆平台上有超過100多個模型;在模型開發層面,千帆平台可以提供全面的模型開發工具鏈,支持深度思考模型、多模態模型的定製和模型蒸餾。

這啥概念呢?首先,在千帆上,你基本上能看到市面上所有的可用模型,除了自己的文心繫列,從國內的DeepSeek,Qwen系列,到國外的Llama;模態上也是包含了文本,圖像,視頻,語音,比如在這裏,就能看到可靈,Vidu這樣的視頻SOTA模型。並且它們還承諾,只要新的模型出來,24小時內上線。

其次,你想做一些模型上的調整,在這裏鼠標點點,就可以成為全鏈路的工作。像前面説的蒸餾,微調,以前可能需要一個工程師團隊才能搞定,而利用智能雲千帆模型開發平台,一切都是開箱即用。
目前在智能雲平台上做模型開發的企業不在少數,比如智聯招聘。招聘一直是AI落地的最佳場景之一,旗艦模型參數大,調用成本高,推理速度也上不來。

於是它們利用了智能雲模型開發平台上的一鍵蒸餾,用DeepSeek-R1作為教師模型,把參數更少的ERNIE Speed作為的學生模型。利用教師模型生成的幾千個有關招聘的問題,進行蒸餾,最終就得到了一個性能媲美DeepSeek-R1的小模型。
不僅成本降低了1/3,模型回答的速度和併發數量也上來了。可以説,利用蒸餾降低成本,是AI時代創業非常重要的一環。
如何打造專業模型
除了蒸餾降低成本,如何基於企業自己的數據,打造出專業模型,實現需求上的對齊。
比如招聘行業,每個公司都有自己對業務的理解,並且這部分往往是不公開的。基於公開數據訓練的大模型,肯定是無法達到公司的個性化需求。
這個時候,就需要人工對模型進行微調,以前都需要人工來判斷回答的質量,而現在利用智能雲平台上的基於強化學習的微調(RFT),人工這部分就由裁判模型取代,實現了全流程的自動化。
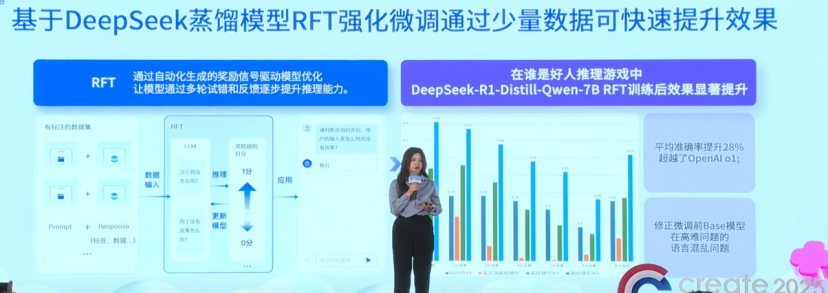
這樣一來,不僅效率高了,模型的泛化也有很大的提升。
事實上,除了文本模型,圖像模型,聲音模型都是模型開發的熱門,比如我想要做個自己的遊戲,如何利用Stable Diffusion打造出自己畫風的美術資產,做人工智能客服,如何克隆出不同的聲音,都是模型開發中的環節。
有了百度智能雲千帆的模型開發平台,不僅囊括了以上的所有過程,還覆蓋到了模型開發的全週期,想要什麼樣的模型,登錄到智能雲,就可以自己打造。
AI時代創業,需要給模型開發
隨着AI爆發進入到第三年,模型的回答越來越變得可用了,無論是什麼事兒都可以問的DeepSeek-R1,還是史密斯吃麪不再鬼畜的可靈,都在説明模型產出的內容已經追平甚至超過人類。
這點從IDC的報告中也能看出來,2023年,訓練和推理的算力比例是6:4,而到了2027年,這個比例會變為3:7,隨着模型成熟,更多的算力都用在了模型開發,推理上。但到底如何合理開發,增加效率,是目前模型行業中的問題。圍繞這個問題,中國信通院跟百度智能雲合作,在今年上半年啓動了大平台落地實踐報告的研究工作。
根據在Create大會『如何訓練專精模型』分論壇上,中國信息通信研究院人工智能研究所平台與工程化部主任曹峯主任的介紹,大模型平台落地實踐報告正式撰寫完成,圍繞着大模型建設、使用、管理三步落地路線進行了梳理,很快會通過公眾號的形式和大家見面,感興趣的小夥伴可以去蹲下。
今年,行業內的研究,也從研發更強的模型,轉移到了如何更有效的利用模型。可以看出,現在的行業內最大的痛點,已經轉移到了模型開發上。這次Create大會上的百度智能雲千帆模型開發平台就是瞄準了這個行業痛點,提出的一個很好的解決方案。
它的出現,很好的助力創意的快速落地,降低了門檻。尤其是在智能體爆發的今年,之前爆火出圈的Manus,據説每個任務要消費2美元的算力,如果按1萬個用户,每個用户每天執行3個任務來算,Manus團隊每天支出的成本在6萬美元。
如果它們像智聯招聘一樣,通過模型開發平台,蒸餾出更適合不同子任務的模型,那麼節省下的成本,是非常可觀的。
AI時代,創意和創業的界限一直在模糊,創業的起點,也正在從"需要敲開紅杉資本大門"的焦慮,退化成"蹲廁所刷手機突然靈光一現"的戲劇性轉折。
這次百度智能雲模型開發平台的升級,意味着給AI創業加了更多的助推器,畢竟現在連模型調優都進入了預製菜時代。