傳言:DeepSeek R2參數暴漲至1.2萬億、便宜97.3%!美股或將巨震!_風聞
大眼联盟-1小时前
DeepSeek R2細節流出,參數直接飆到1.2萬億,還把成本砍到了骨折價!

剛剛,一份來自韭研公社的爆料刷屏了整個AI圈——
DeepSeek R2被曝即將發佈,參數規模達到驚人的1.2萬億,並首次採用Hybrid MoE 3.0架構,實現了動態激活780億參數。

而成本呢?
相比GPT-4 Turbo暴降97.3%,這幾乎是AI模型的白菜價了。
Aliyun的實際測試數據指出,DeepSeek R2在長文本推理任務中,每單位token的成本大幅下降,真是AI界的降維打擊。
Aryan Pandey(@AryanPa66861306) 對此性能表現表示了極度的興奮:
DeepSeek R2將單位成本削減97.3%,即將發佈。自主研發的分佈式訓練框架,把華為Ascend 910B芯片集羣利用率推到了82%,FP16精度算力實測達到512PetaFLOPS,接近同規模A100集羣91%的性能(華為實驗室數據)。
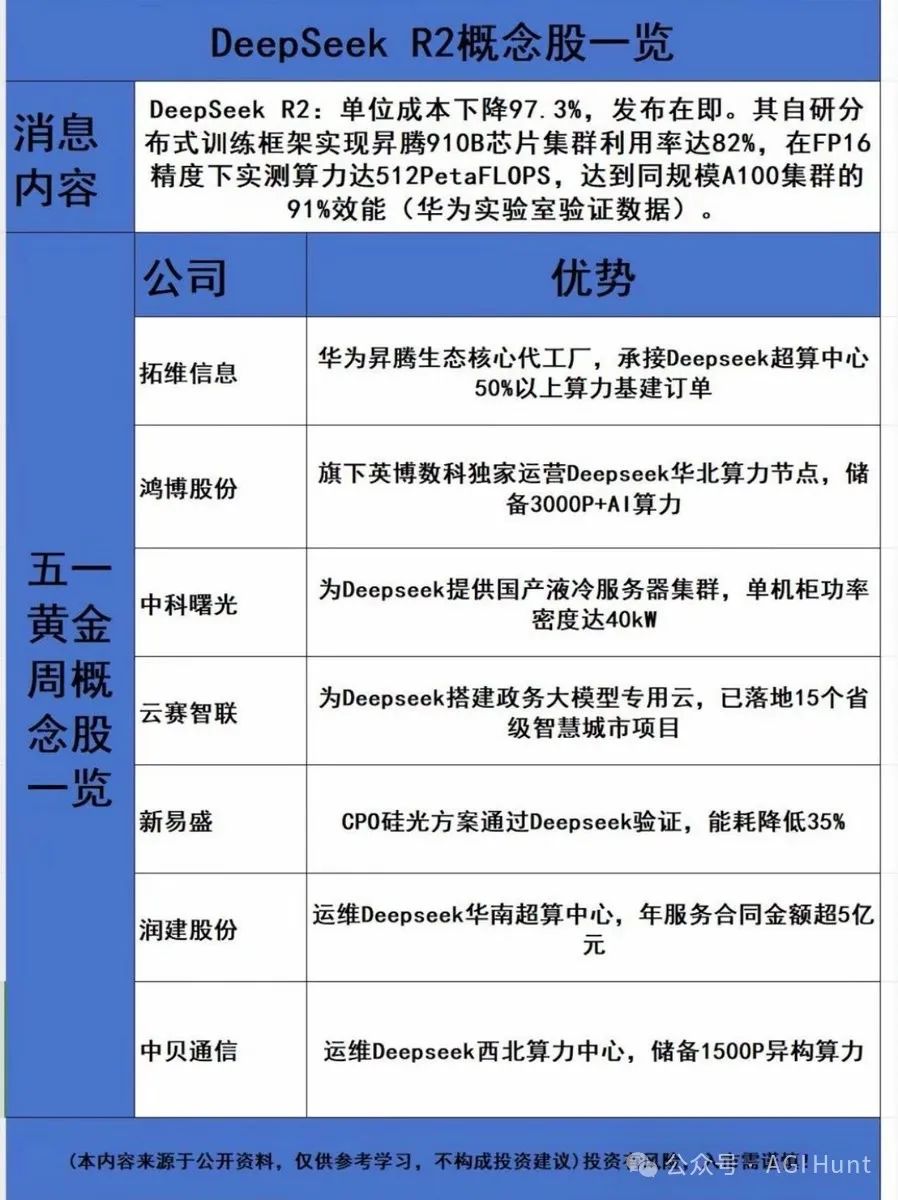
不僅參數猛增,DeepSeek R2這次的多模態能力更是驚人:
視覺理解模塊採用ViT-Transformer混合架構,在COCO數據集物體分割任務中精準度達到92.4% mAP,超過CLIP模型整整11.6個百分點。
此外,工業質檢場景方面也表現搶眼。
它採用自適應特徵融合算法,在光伏EL缺陷檢測中的誤檢率降到了極低的7.2E-6,甚至醫療診斷能力也已超過人類專家,胸部X光片多病種識別準確率高達98.1%,完勝協和醫院專家組的96.3%。
最不可思議的是,DeepSeek R2在8bit量化壓縮模式下,還能將模型體積壓縮83%,精度損失小於2%,這為終端部署打開了大門。
這些亮眼的數據讓推特炸開了鍋,紛紛稱為瘋狂、大東西、太猛了!
不過,自稱最權威的DeepSeek粉絲 Teortaxes▶️ (DeepSeek 推特🐋鐵粉 2023 – ∞)(@teortaxesTex) 卻給狂熱的氣氛潑了點冷水:
我已經説過,除了確認這些公司存在並可能與DeepSeek有合作外,其它爆料我並不相信。
而最初分享這一消息的 Deedy(@deedydas) 也承認了這點:
這些只是傳言,圖片內容實際上是用Claude翻譯自泄露文件。
但即使傳言屬實度待確認,這也阻止不了網友們開始瘋狂想象。
Jeff Brines(@JeffBrines) 就對美國企業表示擔憂:
如果是真的,這會不會對Nvidia造成巨大沖擊?
Alice Le Portier(@SeekingAlphaQ) 更加直白:
如果中國的半導體供應鏈變得有競爭力,美國的半導體公司可能會稀釋,嚴重限制美企從AI大潮中獲得的壟斷收益。
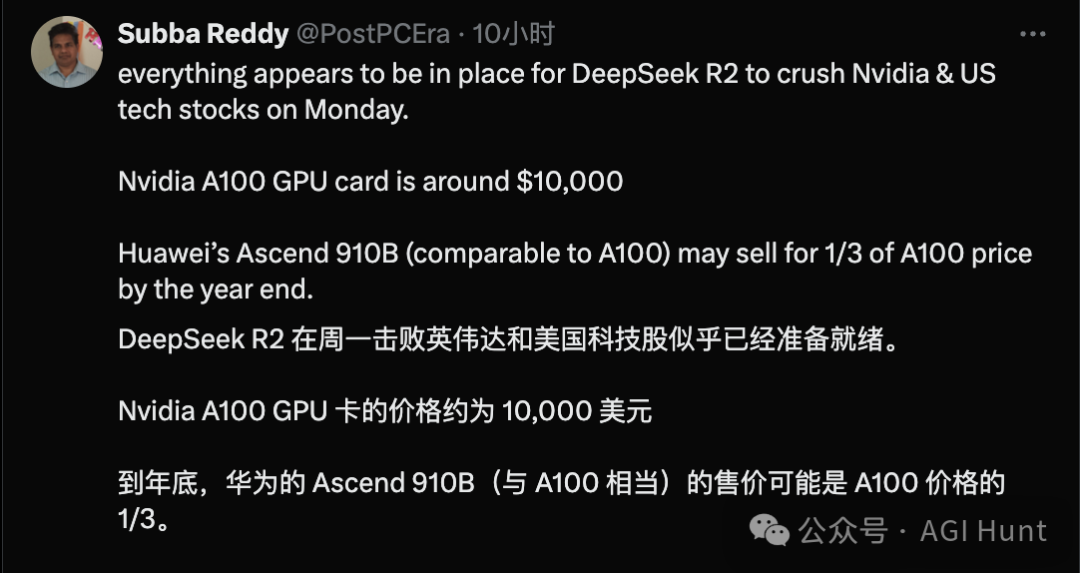
甚至有網友 Subba Reddy(@PostPCEra) 直接斷言:
如果是真的,Nvidia和美股週一可能遭遇一波暴擊。畢竟A100的GPU卡售價大約1萬美元,而華為的Ascend 910B年底可能只要A100三分之一的價格。
當然,也有網友直接將DeepSeek R2定義為「AI冷戰」的新武器。
LIGHT ⇌ SIGNAL//FORM(@AITrailblazerQ) 評論得十分激烈:
DeepSeek R2不僅是便宜的模型,更是一場主權壓縮戰,背後有官方的支持,其目的是瓦解美國AI優勢。
Haha Packet(@haha_packet) 也是秀起了語言的藝術進行嘲諷:
對啊,開源模型都很邪惡。快來保護那些閉源的億萬富豪吧!
而AI圈著名樂觀派 çelebi(@celebi_int) 的觀點很簡單:
如果是真的,這才是正確的世界線!
雖然眾説紛紜,但DeepSeek R2如果真的能在技術和成本上達成這些突破,這無疑會是AI行業的一次重大洗牌。
或許,AI大戰的序幕正悄然拉開。
這個五一,或將不同尋常!
AGI Hunt