阿里開源的新視頻模型,沒準會成為中國 Adobe_風聞
知危-知危官方账号-50分钟前
昨晚,阿里巴巴正式開源了 All in one 的視頻編輯大模型通義萬相 Wan2.1-VACE,而這個模型,沒準能讓阿里在視頻製作領域成為中國未來的 Adobe 。
為什麼這麼説呢?在介紹 VACE 之前,我們先鋪墊一些視頻生成類模型產品的現狀。
這類產品給大眾最深的印象通常是即時生成帶來的驚豔感。不僅僅是生成質量,其抽卡特性使得每次相同輸入有不同結果輸出的體驗猶如盲盒般有趣。
不過,對於把 AI 當作生產力的專業羣體,抽卡只是工作的第一步,實際上他們經常崩潰於二次、多次編輯階段。
想象一個場景,一家初創公司想要在社交媒體上發佈一條 30 秒的新品宣傳短片。這家公司的產品是一台便攜式咖啡機,目標受眾是城市白領和旅行愛好者,員工希望讓 AI 幫忙完成短片的製作。這樣的需求在實踐中僅僅靠 AI “ 一次性輸出 ” 素材 ” 或 “頻繁抽卡”,是永遠是行不通的。
因為設計需求本身會在第一次生成開始就不斷變化,比如市場部提出的亮點( “ 快速萃取 ”、“ USB-C 供電 ”、“ 輕量化 ” )常常在後續會議中被臨時調整。此外,好的創意需要反覆打磨,比如畫面節奏、文案語氣、鏡頭切換等,只有看了初稿後才知道“對不對味”。
如果 AI 只能一次性產出結果,則任何後期修改都會很困難甚至相當於重來。所以只有具備多輪交互和可編輯性後,創作週期才能大大縮短,同時保持創意靈活性,AI 才能成為真正的生產力工具。
因此,密切的人機交互目前是最契合 AI 發展的路線,但想做到這一點,非常的難。
比起文字,像素類的對象生成的可控性顯然要更加難。不考慮語義約束或物理約束,以狀態數比較來看,一句 10 個 token 的文本,以 GPT-4 為例,其詞表大小約為 10^5,那麼總狀態數是 (10^5)^10=1.0×10^50。對於彩色 RGB 視頻( 每個像素 3 個 RGB 通道,每個 RGB 通道 256 個取值,共 768 個取值 ),比如128x128像素,3秒10幀的視頻,共491520個像素,潛在狀態數為768^491520,其狀態數數量級遠遠大於文本。
這也就不難理解為什麼視頻生成產品目前普遍速度慢且貴,而這其實也更體現二次編輯相對於無腦抽卡的效率和成本優勢了。
現階段,圖像、3D 的生成可控性已有不錯進展,但視頻的可控生成僅在近期才有肉眼可見的成果。而且主流的相關產品仍有較大的侷限性,這其實對創意落地的限制性很大。
通義萬相團隊向知危表示,視頻生成與編輯面臨較大挑戰:
視頻生成與編輯的碎片化問題:傳統的視頻生成或編輯方法通常針對單一任務( 如文生視頻、參考生成、對象替換 ),缺乏統一框架,導致不同任務需獨立的模型,鏈路串聯效率低下、推理成本高。
可控性不足:現有方法難以同時支持多維度或多任務編輯( 如主體、內容、結構同時參考 ),用户無法像編輯文本一樣靈活地調整視頻。
高質量內容生成需求:短視頻、影視行業需要高保真、高一致性的視頻生成,而現有模型易出現幀間閃爍、語義不一致等問題。
以專業 P 圖軟件為例,一款設計軟件之所以能在緊張的生產流程中真正派上用場,關鍵在於它提供了種類繁多、可按需組合的工具生態:從修補畫筆、內容感知填充,到通道混合器、位圖/矢量蒙版,再到動作腳本和第三方插件,幾乎每一種創意訴求都能找到對應 “ 利器 ”。
這讓設計師能夠在不同項目階段靈活切換思路與技法,無需跳出工作界面就能完成。
而昨晚,阿里巴巴正式開源的通義萬相Wan2.1-VACE,就在AI視頻領域實現了生產級別的多任務能力。

開源地址如下:
GitHub:https://github.com/Wan-Video/Wan2.1
HuggingFace:https://huggingface.co/Wan-AI
魔搭社區:https://www.modelscope.cn/organization/Wan-AI?tab=model
Wan2.1-VACE 擁有 1.3B 和 14B 兩個版本,其中 1.3B 版本適合本地部署和玩法微調,可在消費級顯卡運行( 此前已發佈 Preview 版 ),支持 480P 分辨率,14B 版本生成質量更高,支持 480P 和 720P 分辨率。
現在,開發者可在 GitHub、Huggingface 及魔搭社區下載體驗。該模型還將逐步在通義萬相官網和阿里雲百鍊上線。
Wan2.1-VACE 主打 “ 功能最全 ” 與 “ 可編輯性 ”,單一模型不僅支持最基礎的文生視頻,還同時支持多種功能。不必再為了單一功能訓練一個新的專家模型,也省去了部署多個模型的開銷。通義萬相團隊表示:Wan2.1-VACE 是第一個基於視頻 DiT 架構的同時支持如此廣泛任務的一體化模型。
文本條件大幅提升了視頻生成的可編輯性,但卻不足以精準控制視頻中的所有細節( 例如精確的佈局、對象形狀等 ),因此 Wan2.1-VACE 擴展了多任務能力以實現更加精細的可編輯性。
總體而言,Wan2.1-VACE 的多任務能力包括:
圖像參考能力,給定參考主體( 人臉或物體 )和背景,生成元素一致的視頻內容。
視頻重繪能力,包括姿態遷移、運動控制、結構控制、重新着色等( 基於深度圖、光流、佈局、灰度、線稿和姿態等控制 );
局部編輯能力,包括主體重塑、主體移除、背景延展、時長延展等。
比如圖像參考生成,在示例中,Wan2.1-VACE 基於小蛇和女孩的參考圖生成了一個視頻,女孩在視頻裏輕輕摸了摸小蛇。圖像參考生成對於添加新元素很重要,並能保證多鏡頭視頻中的元素一致性。
提示詞:在一個歡樂而充滿節日氣氛的場景中,穿着鮮豔紅色春服的小女孩正與她的可愛卡通蛇嬉戲。她的春服上繡着金色吉祥圖案,散發着喜慶的氣息,臉上洋溢着燦爛的笑容。蛇身呈現出亮眼的綠色,形狀圓潤,寬大的眼睛讓它顯得既友善又幽默。小女孩歡快地用手輕輕撫摸着蛇的頭部,共同享受着這温馨的時刻。周圍五彩斑斕的燈籠和綵帶裝飾着環境,陽光透過灑在她們身上,營造出一個充滿友愛與幸福的新年氛圍。


局部編輯是高效可編輯性也不可或缺的,能實現刪除、替換原有元素以及加入新元素的能力。在下圖中,Wan2.1-VACE 用視頻局部編輯能力將女士手裏的平板電腦不留痕跡地移除了。
提示詞:紀實攝影風格,房產自媒體博主站在一間現代化的客廳中央。博主穿着簡潔時尚的衣物,面帶微笑,兩隻手舉在身前,手上空無一物正對着鏡頭介紹房屋情況。背景是一間寬敞明亮的客廳,傢俱簡約現代,落地窗外是綠意盎然的花園。房間內光線充足,温馨舒適。中景全身人像,平視視角,輕微的運動感,如手指輕點屏幕。


此外,通過進一步結合視頻重繪,Wan2.1-VACE 能基於不同的運動控制能力來控制新元素的呈現。
比如,草圖/邊緣圖適合控制物體整體的運動軌跡,下圖展示了 Wan2.1-VACE 基於草圖運動軌跡和戰鬥機參考圖生成的戰鬥機運動以及鏡頭運動效果。
提示詞:戰鬥機視角,急速旋轉,在雲層中與敵機纏鬥,突然翻滾,急速下搖,導彈擦過機身,尾焰在雲層中劃出弧線。


灰度視頻提供了內容的明暗信息,可用於指導模型為其上色( 彩色化 )或重建細節。在下圖中,Wan2.1-VACE 還基於灰度圖生成了在運行的火車旁邊騎馬的男子的視頻。
提示詞:一個外國男人騎着一匹棕色的馬在鐵軌旁奔跑。他穿着一件灰色襯衫和黑色牛仔帽,背景是一列蒸汽火車正在行駛中,它由多個車廂組成,並且冒着煙霧。天空是橙色的日落景象。


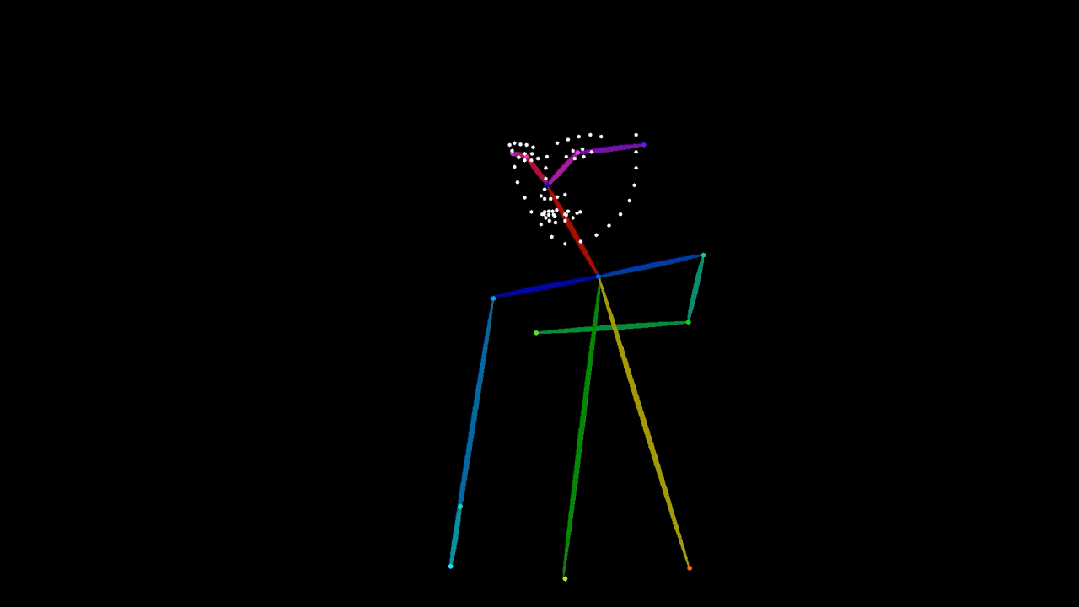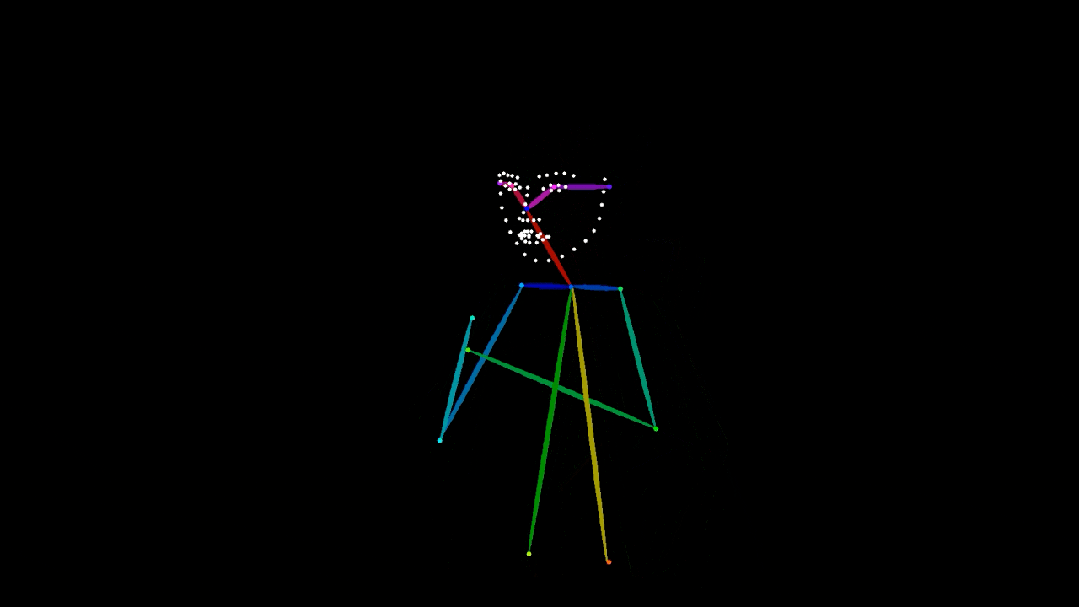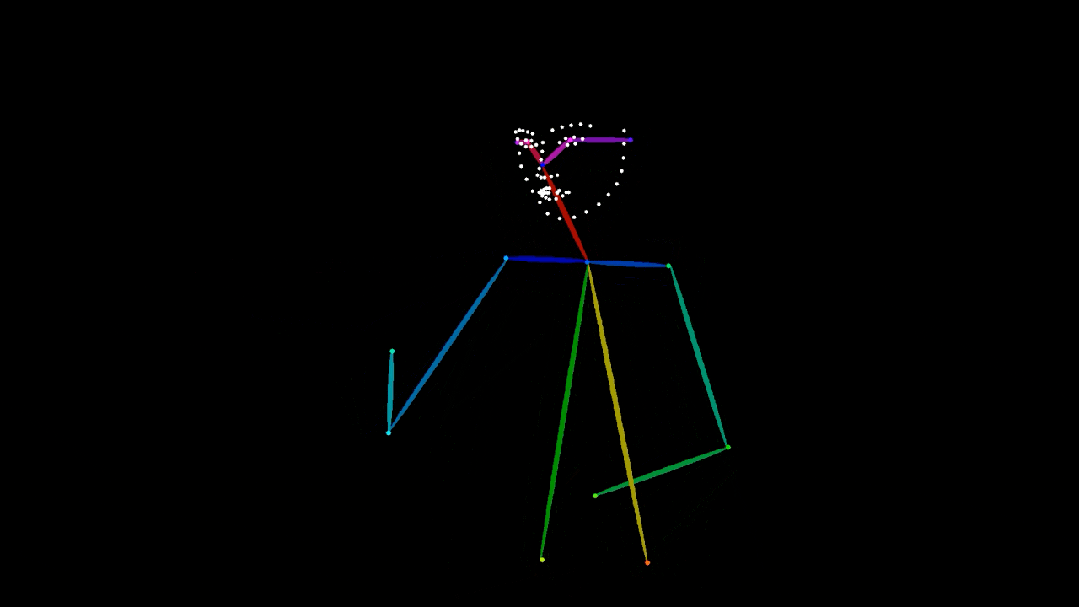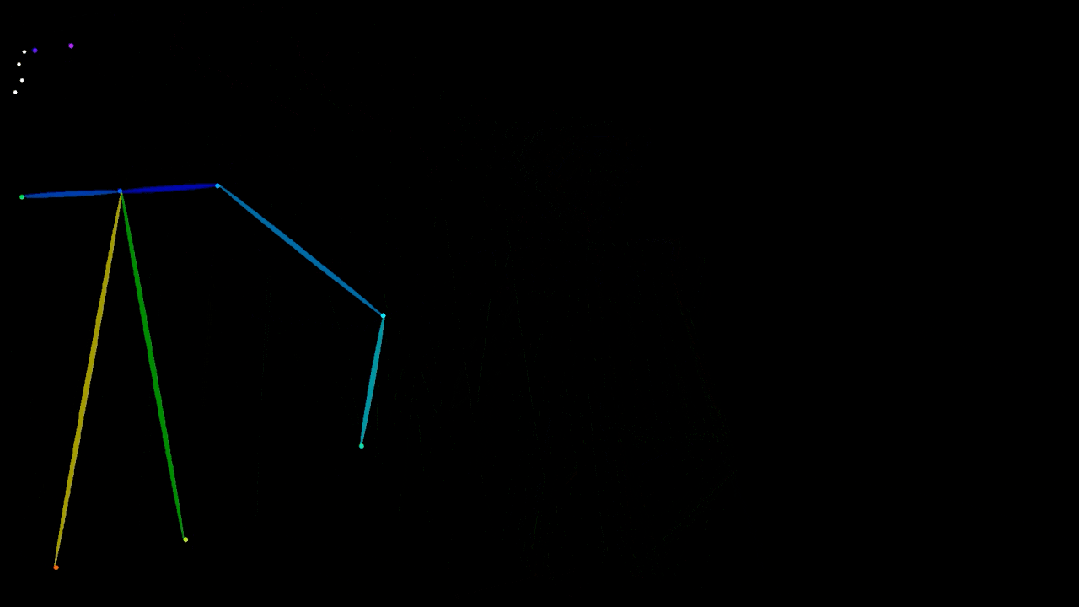
人體姿態圖( 骨架關鍵點 )提供了直觀的結構信息,非常適合用來控制視頻中角色的動作。在下圖中,Wan2.1-VACE 基於人體姿態圖生成了男孩練習空手道的視頻。
提示詞:寫實風格攝影,10 歲白人男孩身穿白色武術服,繫着黃色腰帶,在寬敞明亮的房間裏練習空手道。他專注而有紀律地出拳、擺架勢,動作流暢自如。背景模糊處理,隱約可見堆放的墊子等健身房設備。鏡頭跟隨他的動作,水平左右搖移,捕捉中近景畫面,展現他控制力強且連貫的動作。
光流描述了幀間像素的運動,是表達細粒度運動結構的重要模態。在下圖中,Wan2.1-VACE基於光流圖生成了話梅掉進水裏引發水花飛濺的畫面。
提示詞:紀實攝影風格,一顆深紫色的話梅緩緩落入透明玻璃杯中,濺起晶瑩剔透的水花。畫面以慢鏡頭捕捉這一瞬間,水花在空中綻放,形成美麗的弧線。玻璃杯中的水清澈見底,話梅的色彩與之形成鮮明對比。背景簡潔,突出主體。近景特寫,垂直俯視視角,展現細節之美。
Wan2.1-VACE 還支持視頻背景延展和視頻時長延展。在下圖中,Wan2.1-VACE通過視頻背景延展把女士拉小提琴的特寫還原為原內容已暗示的大型演奏場景。
提示詞:一位優雅的女士正在熱情地拉着小提琴,她的身後是一整個交響樂團。

通過視頻時長延展,Wan2.1-VACE 呈現了鏡頭後方的越野騎手跑到前方小坡的畫面。
提示詞:越野摩托車比賽場景,一個裝備齊全的運動員騎着摩托車登上土坡,車輪濺起高高的泥土。
綜合來看,上述案例呈現了 Wan2.1-VACE 多任務能力之間的有機關係。圖像參考和局部編輯提供基礎刪除、替換、添加新元素的能力,視頻重繪則控制新元素的具體呈現,不同模態各有所長,視頻背景延展和視頻時長延展在空間、時間上提供了更加開放的想象空間或還原完整場景。
所以要發揮 Wan2.1-VACE 的全部優勢,應該探索各種原子能力的自由組合,只有這樣才能實現生產級別的場景落地,而 Wan2.1-VACE 確實能夠很好地支持這一點。
比如在以下這個多鏡頭宣傳片中,Wan2.1-VACE 自由地組合了多種能力來實現每個鏡頭的需求,同時很好地保持了鏡頭間的人物一致性。
比如這個片段組合了畫面延展、姿態遷移、圖片參考,用畫面延展擴大窗户,用姿態延展讓女生做伸展運動,用圖片參考加入更多小鳥。
這個片段組合了局部編輯和圖片參考,用圖片參考將小象娃娃通過“任意門”瞬間穿梭到園區場景標記好的局部區域中。
這個片段組合了運動控制和圖像參考,讓小象從地上浮起然後一飛沖天。
這個片段組合了局部編輯、姿態遷移和圖片參考,用姿態遷移控制女孩的步態,通過局部編輯和圖片參考給女孩快速更換服裝。
最後,這個片段組合了姿態遷移和圖片參考,將專業滑板運動姿態賦予給女孩,結合不同的景觀圖片,使女孩踩着滑板車在城市、沙漠、大海中穿梭。
如此給力的生產級工具,開發者怎能不愛?從通義萬相目前的成績就可見一斑。
自今年 2 月以來,通義萬相已先後開源文生視頻模型、圖生視頻模型和首尾幀生視頻模型,目前在開源社區的下載量已超 330 萬,在 GitHub 上斬獲超 1.1w star,是同期最受歡迎的視頻生成模型。預計 Wan2.1-VACE 也將帶來新一波社區活躍。
將這麼多的能力有機融合到一個模型,通義萬相是怎麼做到的?為解答該問題,知危跟通義萬相團隊進行了交流。
通義萬相向知危表示,要實現這一點,其實會面臨不少挑戰:
多任務統一建模:如何在單一架構中兼容生成、編輯等多種任務,並保持高性能。
細粒度控制:如何解耦視頻中的內容( 物體 )、運動( 時序 )、風格( 外觀 )等屬性,實現獨立編輯。
數據與訓練複雜性:多任務的數據構建需要按照任務的特性分別進行處理,並組建出高質量的訓練集。
在建模部分,VCU ( Video Condition Unit ) 是 Wan2.1-VACE 實現全面可控編輯的核心模塊,“ VCU 的使用是實現任務統一的源頭,也是區別於其他專有模型僅支持特定任務的不同之處。” VCU 的關鍵性體現在:
統一表徵:將視頻生成和編輯的輸入定義為輸入視頻、輸入掩碼、參考圖像等;
多任務統一:VCU作為中間層,隔離任務差異( 如生成或編輯 ),以實現不同任務的表徵注入到生成模塊中。
細粒度控制:通過VCU的解耦設計,可實現對任務區分和精細化控制。
簡單解釋一下 VCU 的構成。實際上,Wan2.1-VACE 的多任務能力可以表示為三種模態數據的統一輸入接口,這三種模態即文本提示、參考圖以及 mask。
根據多種視頻任務能力對三種多模態輸入的要求,將其分為四類:
文本轉視頻生成 ( T2V ) ;
參考圖像生成 ( R2V ) ;
視頻到視頻編輯 ( V2V ) ,即視頻重繪;
蒙版視頻到視頻編輯 ( MV2V ) ,即視頻局部編輯。
VCU 用統一的表示方式,將以上四類任務的輸入都表示為相同的三元組形式 ( T,F,M ) ,T 為文本提示,F 為參考圖像或上下文幀,M 為 mask:
在 T2V 中,不需要上下文幀或 mask,每個幀默認為 0 輸入值,每個 mask 默認為 1 輸入值,表示所有這些 0 值幀像素都將重新生成。
對於 R2V,在默認 0 值幀序列前插入額外的參考幀( 比如人臉、物體等 ),mask 序列中,默認幀的 mask 為全 1,參考幀的 mask 為全 0,意味着默認幀應重新生成,參考幀應保持不變。
在 V2V 中,上下文幀是輸入視頻幀( 比如深度、灰度、姿態等 ),mask 默認為 1,表明輸入視頻幀都將重新生成。
對於 MV2V,上下文幀和 mask 都是必需的,mask 部分為 0、部分為 1,mask 為 1 的幀將重新生成。
由此,便將不同的任務統一到了一個模型中,如下圖所示。

VCU:四類視頻處理任務的統一輸入表示。
圖源:https://arxiv.org/pdf/2503.07598
VCU 的結構非常簡潔漂亮,但也是基於團隊長期的技術積累演化而來,通義萬相表示,“ ACE 和 ACE++ 是我們在圖像領域進行統一生成和編輯的最初嘗試,並取得了不錯的效果。而 VACE 也是 ACE 在視頻領域中的靈活運用,其中 VCU 的構建思想也是從圖像中的統一輸入模塊演變而來。”
而要實現 VCU 本身,其實也會有一些挑戰,通義萬相表示,“ VACE 採用了在輸入側進行統一的策略 ( early fusion ),不同於使用額外的編碼模塊對不同的輸入模態進行處理,我們以簡單、統一為設計原則。其核心挑戰在於要使用單一模型來實現與專有模型相比的效果。”
構建多任務模型對數據質量的要求也更高,通義萬相團隊需要對視頻進行第一幀標記,比如圖像內有哪些物體,並進行位置框選和定位,去除目標區域過小或過大的視頻,還需要在時間維度上計算目標是否長期出現在視頻中,避免目標過小或消失帶來的異常場景。
為了讓模型適應靈活的能力組合,通義萬相團隊將所有任務隨機組合進行訓練。對於所有涉及 mask 的操作,執行任意粒度的增強,以滿足各種粒度的局部生成需求。
訓練過程則採用分階段、從易到難的方法。通義萬相團隊先在預訓練文本轉視頻模型的基礎上,專注 mask 修復和擴展等任務。接下來,逐步從單輸入參考幀過渡到多輸入參考幀,以及從單一任務過渡到複合任務。最後,使用更高質量的數據和更長的序列來微調模型質量。這使得模型訓練的輸入可以適應任意分辨率、動態時長和可變幀率。
近幾年的視頻生成 AI 模型經歷了飛速演進,完成了從 “ 能生成 ” 到 “ 能駕馭生成 ” 的飛躍。這其中,多模態輸入的演進體現了從 “ 一把鑰匙開一把鎖 ” 到 “ 多線索協同指揮 ” 的轉變。
不同模態各有所長:文本給出抽象語義,圖像提供外觀細節,姿態/草圖限定結構,光流約束運動連續性,而參考幀確保身份恆定等等。這一歷程充分展現了AI視頻的潛力:通過不斷引入新的控制維度,人類將不斷增強讓AI按意圖創造視頻的能力。
融合不同控制維度,視頻生成模型開始具備綜合理解與決策的能力,能夠在複雜條件下平衡各方需求。這不僅極大提高了生成的可編輯性,也使模型更適應真實創作場景下多種素材混合作用的需求。
可以看出,Wan2.1-VACE 是完成這一轉變的關鍵成果。
展望未來,如何進一步提高生成現實度、擴展時長、增強交互性( 例如即時對生成視頻進行調整 ),以及結合物理和 3D 知識避免失真,將是持續的研究重點。但可以肯定的是,可編輯、多條件的視頻生成範式已基本確立,並將成為數字媒介生產的新範式。
而這種生產範式,或許可以在未來徹底改變視頻後期製作的工作流,顛覆掉視頻製作工作人員手中的 PR、AE 以及 Final cut 等工具。