談漢字識字、寫字、檢字、打字四位一體統一模式教學_風聞
夏国民-34分钟前
談漢字識字、寫字、檢字、打字四位一體統一模式教學
——拼形文字(第17篇)
夏國民
為解決語文教學中識字、編碼、檢字、打字四位一體問題,自上世紀八十年代開始,人們就一直夢寐以求不懈奮鬥。
進入新世紀以來,音碼快速迭代進步,漢字高效輸入早已不再是問題,隨着“字根數碼檢字法”問世,加上目前人工智能“有問必答”的幫助,筆者進一步提出漢字教學“識字、寫字、檢字、打字四位一體統一模式”,試圖解決上述問題。
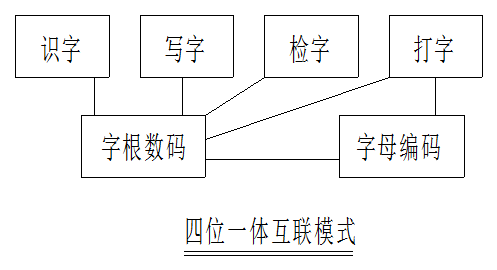
識字
“漢語拼音是給漢字作注音用的,拼音不能代替漢字。”自1956年漢語拼音實施以後,雖然解決了漢語自古以來的讀音標準問題,但如何讓學生在識字時簡捷地識記漢字形態,時至今日,教學中一直莫衷一是。
歷來只有偏旁概念中的義旁,能直觀地解釋大部分字中的一部分結構形態,是識字教學中的主要內容之一。而很多字的另一部分,除了聲旁這個籠統的説法外,實際上都沒有具體“叫法”,或者説沒有名稱,導致老師在教授識字時語焉不詳,甚至不得不敷衍塞責。
另外,長期以來,人們一直不得以而湊合着使用的“部首”概念,又經不起邏輯推敲,前面第11篇已詳細討論過,對識字教學基本無益。
因此,識字教學中的形態記憶環節,除了常見的義旁和筆畫具體名稱外,缺少簡捷的稱謂,是識字教學的痛點。
如果引入字根數碼概念配合義旁概念教識生字,各個漢字的各部分就都有名稱或代稱,形音義結合,因分塊而不零碎,會易記而難忘。比如,“稱謂”二字,對應的字根數字代號是384和473,對應的字根名稱是“禾、爾頭(撇折)、小”和“言、田、月”。也可以用字母代號稱為“T、Q、I”和“Y、L、E”。如此一來,所有現代漢字的各部分就都有“名分”歸屬。可以治古人説的“人之不識字也,病於不可分”之病。
寫字
提筆忘字是計算機時代的新問題,已成為一種社會現象,據有關調查統計,90%以上的人曾提筆忘字,勢成危機狀態。追索到基礎知識教育階段的原因,一是過往筆畫順序知識長期以來是模糊的,規則多而且不透徹。二是漢字教學過程中,多側重認讀和考試需求,以致很多課堂教學對漢字結構講解不足,學生主要是通過機械記憶掌握漢字,缺乏對字形、字義的深入理解。因而難以建立深層記憶,導致記憶容易消退。
日常應用階段也有原因,一是語音轉文字等技術的普及,極大地降低了書寫需求,人們更傾向於通過拼音輸入法完成文字表達,導致手寫漢字或形碼輸入時不斷強化記憶字形形態的機會顯著減少,其中過度依賴語音輸入是主因。二是受網絡語言衝擊,碎片化閲讀和網絡用語(如諧音梗、英文縮寫)削弱了規範漢字的使用場景,直接導致錯別字氾濫。
另外,還有動機性遺忘一説,心理學研究表明,漢字結構比較複雜,以往的書寫筆順規則又不易準確掌握,人們可能因逃避學習漢字的枯燥感或考試壓力,主動遺忘複雜字詞的書寫方法。
針對以上分析,寫字階段應該進一步採取如下措施。
一是學習前面第15篇介紹的“六先六後”筆順規則,可以簡化和補充書寫漢字的基礎知識。
二是引入字根數碼概念,配合義旁概念教寫字,因“各塊”都能夠“名副其實”,形、義結合能夠詳細理解漢字,可以提高書寫漢字的趣味性,根植深層記憶,並建立形碼檢字和輸入的基礎,為檢字和打字階段不斷強化字形和字義記憶提供必要條件。
檢字
前面的第8篇和第10篇,已經論證瞭解決漢字的快速排序檢索問題,第9篇則詳細論述了四角號碼檢字法不適應現代漢字檢索應用的需求,以及音序檢字法無法處理不知道讀音的字、筆畫序列檢字法編碼冗長而費時費力的弊端,第11篇還專題闡述了部首檢字法的繁難問題。總的來説,常用的幾種傳統檢字法都存在嚴重缺陷。
引用漢字字根數碼檢字法,上述問題都能解決,與識字、寫字一脈相承,思維上不再脱節。因為字根數碼檢字法效率高,在具體操作時,還能舉一反三,彌補識字和寫字過程中字形記憶的不足。
打字
基於字根數碼的輸入法,基本套路是四碼打字、五碼打詞和句,無重碼的五碼能自動上屏。編碼十條一列,可供選擇。由於數字碼只有1至9個能代表字根,即使編五碼,理論上也只有6萬個位置,對於動輒以十萬計的字詞條來説,字詞上屏基本上是靠挑,效率不高。
字根數碼是字根字母編碼的簡化版。反過來説,字根字母編碼是字根數碼的細化版。例如,字根數碼1對應的字母編碼是D、F、G。
基於字根字母編碼的輸入法,由於代表字根的字母是25個,編四碼輸入字詞條,理論上有39萬個位置,空間非常大,基本套路是無論字、詞、句,敲四碼都可以做到自動上屏。一碼、二碼、三碼均可以設置簡碼,編排簡碼10條一列,可供選擇。三級簡碼還可以規避數以萬計的詞句四碼重碼。
總而言之,形碼具備高效率輸入漢字的基礎,開發潛力很大。
輸入單字時,如果敲一下字母鍵,屏幕上就會出現第一碼相同、使用頻率由高到低的10個高頻常用字,一共250個。敲一鍵就能出現的字稱為一級簡碼。
下圖是部分一級簡碼。
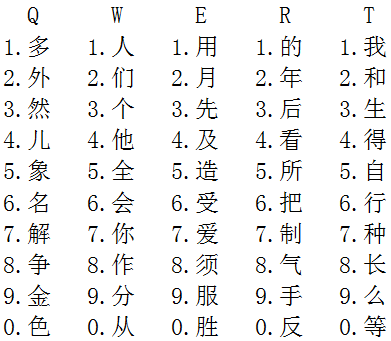
輸入單字時,如果敲兩下字母鍵,屏幕上就會出現前兩個編碼相同、使用頻率由高到低的10個漢字,儘管理論上兩鍵有6250位置,但實際上只有3200多個常用字在位,3500個一級漢字中另外200多個需要敲三鍵。不過,這超過了《國際中文教育中文水平等級標準》語言量化指標中的高等九級識字標準的3000個。簡單來説,國標九級的3000漢字,敲兩鍵就都能出現。敲兩鍵就能出現的字詞稱為二級簡碼。
輸入詞句時,數以十萬計、99%的詞句敲四鍵都可以自動上屏。目前的實驗軟件編碼條目超過了15萬,這還不包括簡碼條目。例如,“全心全意為人民服務”是WNWT四碼。“全心全意為人民”是WNWN四碼。“全心全意”是WNWU四碼。“為人民服務”是YWNT四碼。“為人民”是YWNA四碼。常用的長短句都在遴選之列。
再如,國家憲法裏有一句“縣級以上的地方各級人民代表大會常務委員會的組成人員不得擔任國家行政機關、監察機關、審判機關和檢察機關的職務”,編為MXCT四碼,50餘字敲四鍵就自動上屏。
86版五筆輸入法推向市場幾十年來,後續出現的各種五筆輸入法,基本上都是基於86版的小變動,沒有從根本上減少形碼的主要弱點,即“字根難記、字難拆”問題,更談不上形碼智能化,導致一部分人仍不得不使用幾十年前的86版五筆。
實際情況是,一方面86版五筆的字詞數量太少,另一方面又沒有加入後期發明的一些新技術,因此才落後於時代。但形碼具備移植拼音輸入法所有先進技術的基礎條件,只不過是變音碼為形碼而已,完全可以做到後來居上,未來可期。